JoongHyun.log
로그인
JoongHyun.log
로그인
시리즈
논문리뷰
오름차순
1.
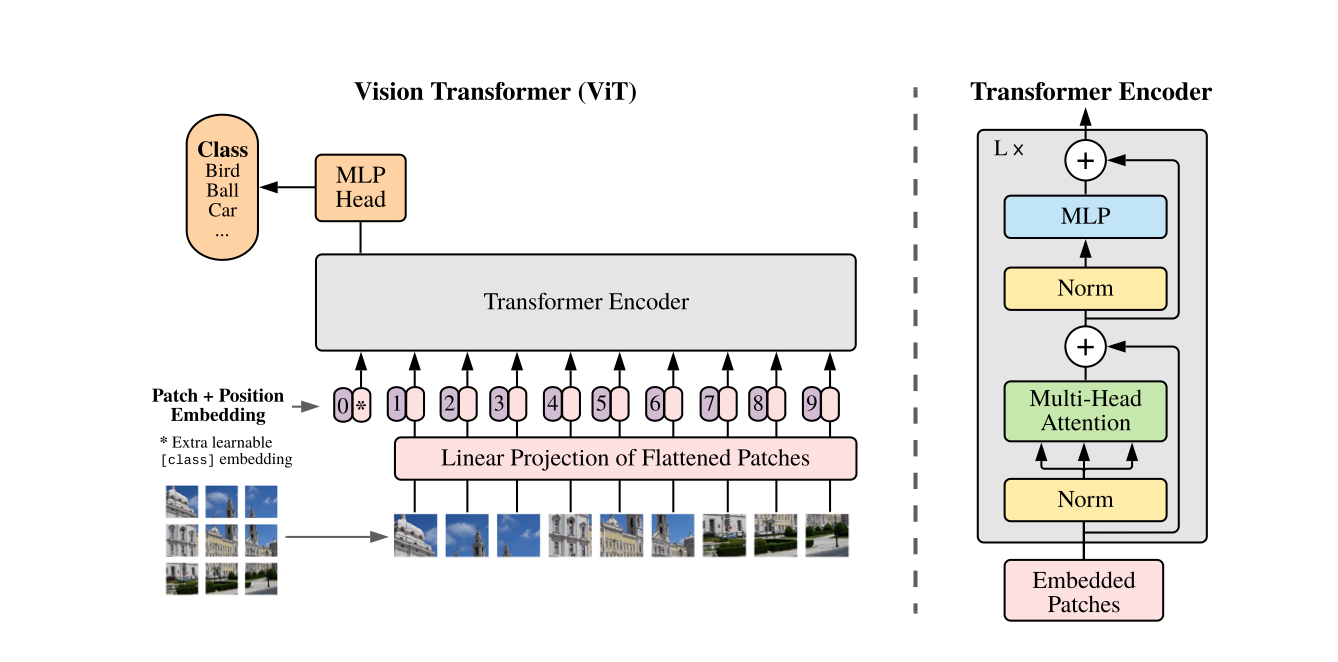
[논문리뷰]Vision Tranformer
CNN 대신 self-attention layer만을 이용해서 sota모델을 달성한 vision encoder 모델이다.
2023년 9월 21일