Peer to Peer, 즉 사용자간의 정보공유 기술이다.
피어의 특징
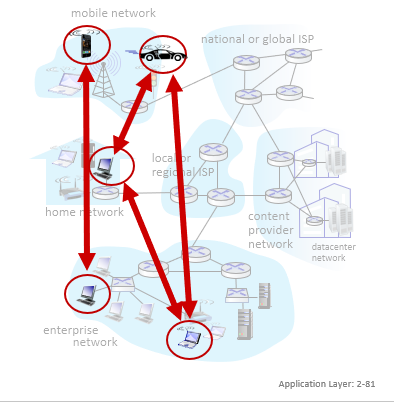
피어는 서버가 필요없다고 하지만 일단 필요하기는 하다.
피어는 간혈적인 연결이다. 즉, 특정 피어 그룹에 조인해서 누가 오는지 알기 위해서는 서버 시스템(트래커 접속해서 주변 피어로부터 정보를 받아와야함)이 필요하다.
피어의 효율성
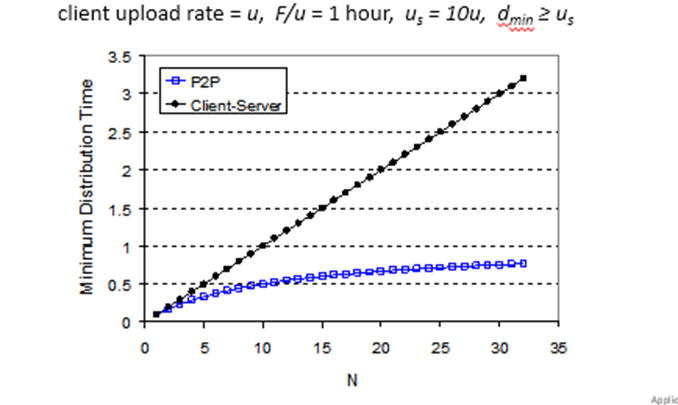
파일분배에서 P2P와 클라이언트 서버 구조중 누가 더 효율적인가?
조건
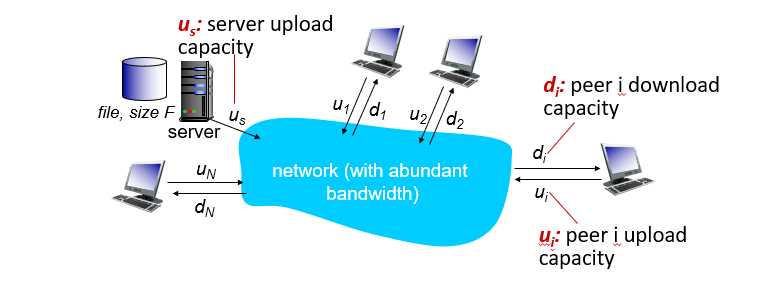
- 파일사이즈 f(서버에만 있음)
- 유저가 n 명이 있는데 이 사이즈 f의 파일을 n명의 모든 유저에게 다운로드 시키는데 걸리는 시간
- 서버의 업로드 스피드 us bit/sec
- 각 유저의 업로드 스피드 ui bit/sec
- 다운로드 스피드 di bit/sec
클라이언트 - 서버 구조
클라이언트 서버에서는 서버만이 자료제공을 한다.
하나의 파일을 네트워크에 올리는 시간은 F/us. N개의 파일은 N * F/us 따라서 NF/us.
다운은 F/di (올라오자마자 받고, 딜레이가 없다 가정)
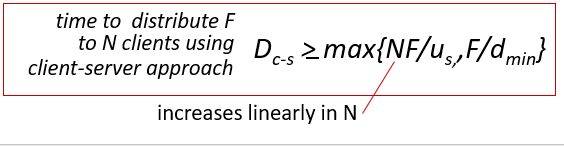
전체 업로드 시간과, 가장 느린 다운로드 시간중 최대값이 소요시간의 최소값이 된다.
D(c-s) >= Max({NF/us, F/dmin})유저가 늘어날수록 딜레이의 하한값이 늘어난다. (N이 늘어나기 떄문)
P2P
P2P에서는 최소한 하나라도 올려야한다 따라서 F/us
클라이언트가 받는건 똑같이 F/di
하지만 이는 불충분하다. NF만큼의 파일이 돌아다녀야 결국 N명이 받을 수 있다.
P2P에서는 서버만 올리는게 아니라 클라이언트도 올릴 수 있다.
이를 정리하면 아래와 같다.
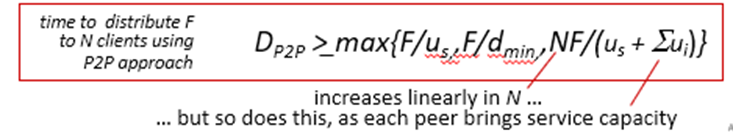
여기서는 N이 커지면 분자가 커지기는 하지만 동시에 분모도 커진다.
그래서 누가 더 효율적인가?
다운받는 시간은 똑같고 결국 NF시간이 이를 결정하는데, 서버하나가 올릴 때 보다는 유저들이 같이 올릴 때 분모가 더 커진다
소켓 프로그래밍
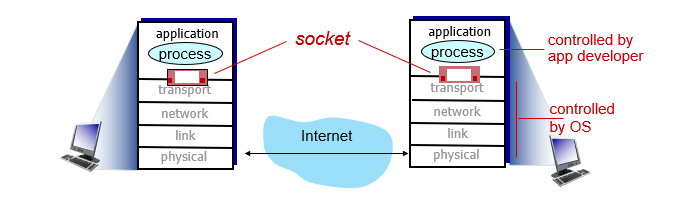
소켓은 UDP 혹은 TCP로 구성한다.
TCP는 byte stream oriented이다. 바이트 단위로 데이터를 주르륵 내려보내버리고, 그러면 TCP가 알아서 자기 편의에 따라서 나눠서 보낸다. UDP는 정해진 사이즈대로 그대로 보낸다.
UDP 소켓프로그래밍
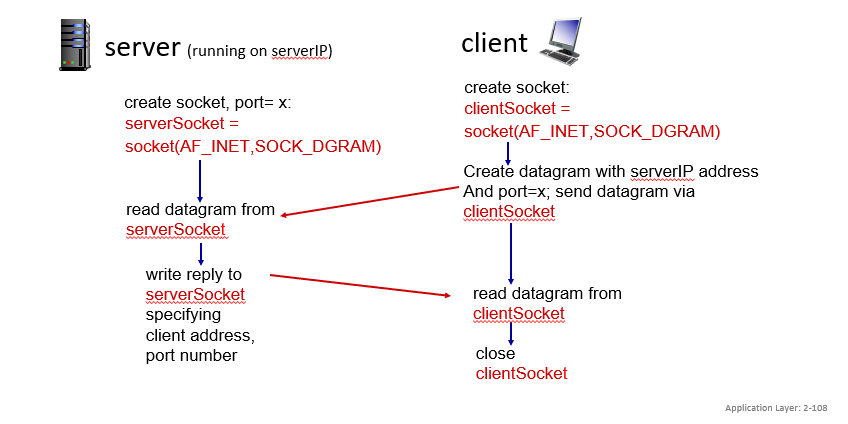
UDP는 데이터 주고받기전에 커넥션 설정을 위한 핸드섀이킹이 없고 이 개념이 없기 때문에 모든 소켓이 목적지 ip와 포트번호를 가지고 가야 한다. 따라서 수신자가 받은 소켓안에는 보낸쪽의 ip랑 포트번호가 필요하다.
UDP는 패킷이 없어질 수 있고 순서가 변할 수 있지만, 보증은 안된다
TCP 소켓프로그래밍
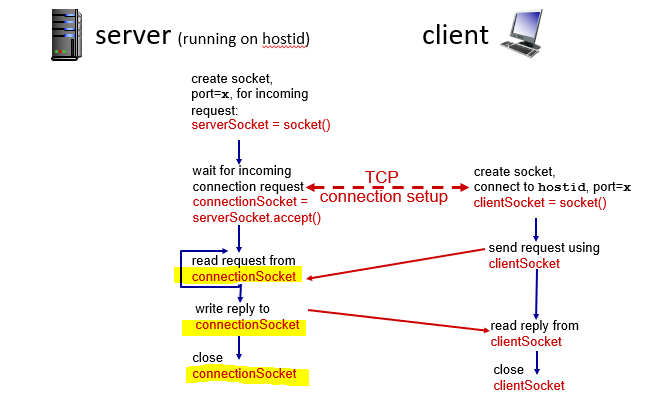
TCP는 소켓이 만들어짐과 동시에 내가 따로 연결하는거 없이 알아서 연결이 된다.
HTTP80 포트로 첫 요청을 보내면, 그 뒤부터는 TCP가 자체적으로 커넥션 소캣을 만들어서 이 소켓으로 자체적으로 처리하낟. 이에 클라이언트 개수만큼 소켓을 만드는 일을 서버가 수행하는것이다.
TCP도 구별이 필요하긴하다. 만약 내가 한 컴퓨터에서 두개의 프로그램을 돌린다고 하면, 서버는 여기서 IP가 똑같기 때문에 포트넘버를 보고 구분해야 한다. 대신 서버는 소켓을 두개 만들어준다.
결국 응답을 위해서는 클라이언트의 IP주소와 함께 포트 번호도 봐야하는것이다.
