Flow Control이 아니다
플로우 컨트롤과 다르다. congestion 컨트롤은 리시버의 응용계층이 데이터를 받아가는 속도에 맞춰서 데이터를 보내는것이다. 즉, 네트워크 상황에 맞는 전송을 한다.
congestion이 발생하면 지연이 발생하게 된다. 즉, 링크 cap을 초과하는 data가 들어오면 지연이 생긴다. 따라서 지연이 100%로 가지 않기 위해서 링크처리 스피드를 넘지 않도록 조절해줘야한다.
또한 Loss가 발생하는 경우 buffer에 계속 쌓이게 될것이고, 버퍼가 넘치면 이는 재전송을 요구하게 되는데 이 역시 비용낭비이다.
이 밖에도 Timeout이 발생했는데 loss가 아니라 지연전송인 경우면 한번 보낸걸 쓸데없이 또 보내야한다
이러한 원인들을 이유로 실제로 우리가 쓸 수 있는 쓰루풋은 예상치보다 저 줄어든다.
시나리오 1
라우터 1개, 무한 버퍼를 가지는 가장 간단한 시나리오이다.
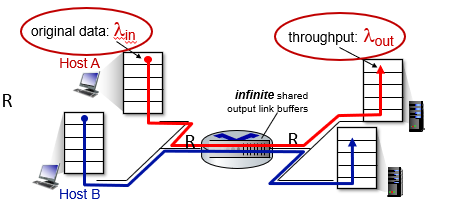
input, output link capacity = R
retransmission은 필요없다.
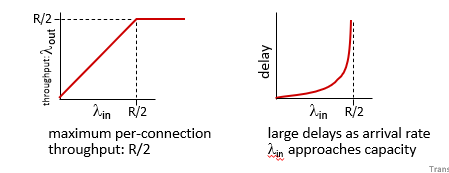
이 경우 딜레이가 arrival rate 가 capacity에 가까워질수록 급수적으로 늘어난다.
시나리오 2
시나리오 1에서 버퍼를 제한한 경우이다.
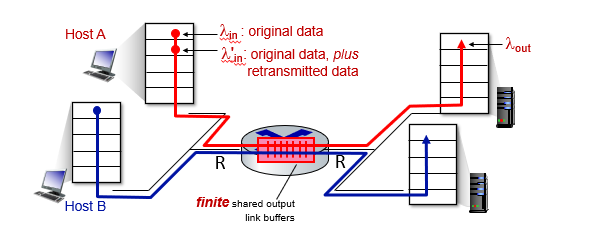
Sender가 buffer만큼만 보낼 경우
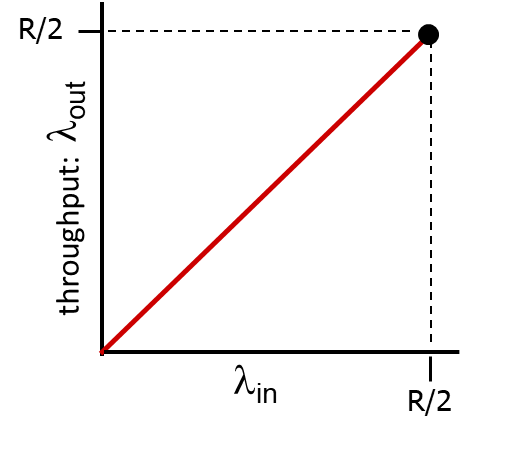
이상적으로 딜레이가 증가한다.
Retransmission 요구됨
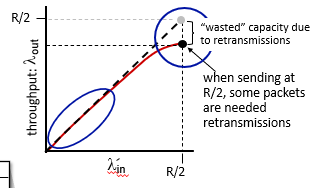
loss가 발생해서 retrans가 필요되는 경우이다.
이 경우 retransmission 해야하는 부분만큼 전체 쓰루풋에서 손해를 보게 된다.
현실적인 시나리오 : un-needed duplicate
패킷은 사라지거나, 라우터에서 드랍될 수 있다. -> 재전송 필요
이 경우 sender는 오로지 timeout에만 의존해서 또 보내게 되는데, 이 때문에 이미 전송된 패킷이 재차 전송되는 불필요가 발생한다.
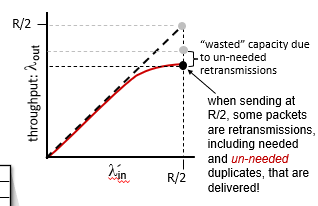
Cost of Congestion
Congestion으로 인해
1. 주어진 receiver throughput에 비해 더 많은retranmission 필요
2. 불필요한 재전송으로 쓰루풋의 전체 용량이 줄어들음
시나리오 3
이 시나리오에서는 모든 트래픽이 2개의 라우터를 지난다.
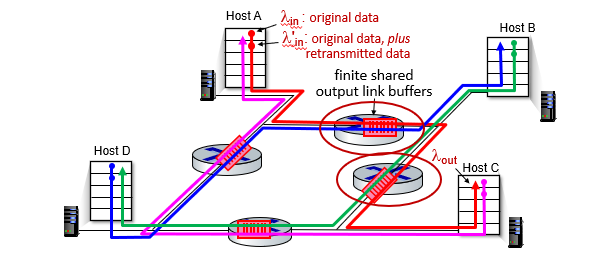
만약 여기서 같은 링크를 이용하는 다른 트래픽이 즉, 빨간 트래픽의 2번 라우터 (초록트래픽의 1번)가 초록색으로 독점되면 빨간트래픽은 자신의 1번 라우터에 의해 통제될 것이고, 이는 불공정한 상태이다.
또한 컨제스쳔으로 미리 1번 라우터에 오기도 전에 조절해서 보냈으면 남는 자원을 다른데 쓸 수 있었는데 1번에서 2번을 보고 조절해서 헛수고가 되었다.
즉, bottleneck이 발생해서 이전 라우터들의 노력이 waste 되는 상황이다.
Congestion Control의 방법
End to End
- TCP들 간에만 congestion이 있고, 네트워크 상황에 대해서 도움받지 않는다.
- 이러면 TCP는 추측을 해야하는데, 이는 loss, delay로 파악한다. (ACK도착을 보고)
- Wireless 에서는 아무래도 wire보다는 오류가 많아서 이 방식으로 하면 congestion이 아닌데 congestion으로 오해를 해서 쓸데없는 control이 일어나기도 한다.
- 이처럼 TCP는 사용환경에 따라서 다양한 개발이 이루어지고있다.
Network – Assisted Control
- 네트워크로부터 정보를 받아서 처리한다.
- 라우터가 네트워크 정보를 가장 잘 알고있다. 따라서 이 라우터로부터 정보 (딜레이 로스 등등)를 얻어내서 header에 필드를 이용해서 정보를 담는다.
결국 패킷이 수신자쪽으로 가서 마킹이 되어서 오면 OS가 네트워크 레이어의 정보를 들여다보고 TCP가 받아서 이를 또 다시 헤더에 마킹을 해서 ACK로 송신에게 전달해준다. - 이렇게 송신자가 라우터가 알려준 정보를 전달받을 수 있다.
- 네트워크와 TCP의 협업을 통한 congestion control이다.
AIMD
가장 기본적인 Congestion이다.
Additive Increase, Multiplicative Decrease이다.
이는 결국 윈도우 사이즈의 문제인데, TCP의 윈도우 사이즈는 가변적이고, 이는 Congestion Control이 조절 가능하고, 이는 지금 각 버전마다 다르다.
올릴때는 선형으로 하니씩 올리다가(AI)
sender가 loss를 감지(congestion)하면 발동한다(MD). 감소는 multiple decrease한다.
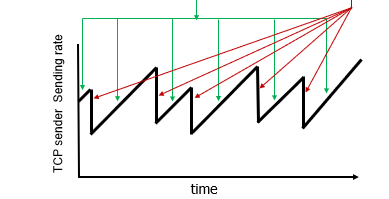
라우팅타임은 고정이고 window만 조정하면 그래프가 천천히 올라가다가 팍 내려오는 그래프가 나온다.
정리
Additive Increase: 만약 이 상황에서 RTT동안 3개를 처리했는데 오류가 없이 잘 되었으면 하나 증가해서 보낸다. (선형 증가)
Multiple Decrease : Congestion이 발생한 그 순간에 줄일때는 곱셈식으로 줄이는데 반으로 줄인다.
즉 조심성있게 올리고 내릴때는 과감하게 내린다.
이를 AIMD라고 부른다.
TCP Rate
실제로 데이터를 보낼 때는 CWND의 RTT 만큼의 시간에 보낼 수 있는 데이터 량이기에 보통 Rate라고 한다.

AIMD의 두가지 버전
AIMD Reno
같은 ACK가 3번 오는 FastRetransmission 상황이 발생하면 loss를 감지하고 cwnd를 반으로 줄여버린다.
TCP Taohe
만약 T.O 상황으로 Loss가 나면 (이 상황이 네트워크가 더 좋지 못한 상황이다) 이 상황에서는 Maximun Segment Size를 1로 줄인다.
결국 이는 ACK의 속도조절 문제이다.
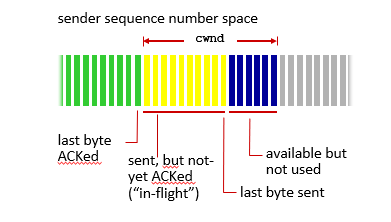
LastByteSent - LastByteAcked는 cwnd를 넘을 수 없게 된다.
TCP Slow Start
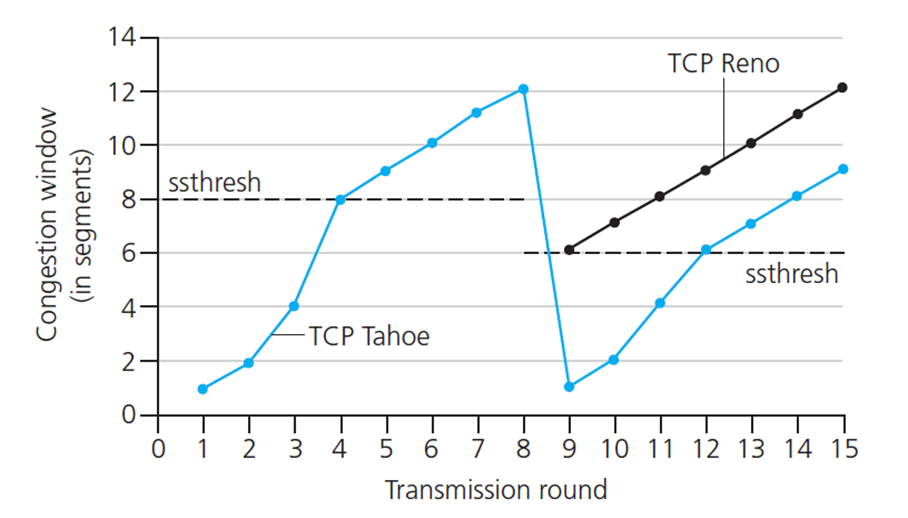
Initial cwnd = 1 상태에서 돌아오는 ACK마나 하나씩 윈도우를 증가시킨다.
따라서 1, 2, 4, 8, 16, 32, 64, 128 … 의 구조가 된다.
즉 2배씩 올려주는것이다. 이는 Additive Increase에 비하면 굉장히 강한 증가인데 이 증가는 sstreshHold 지점에서 AI로 전환된다. Additive로 전환되면 Congestion Avoidance 상태로 전환하는 것이다.
이렇게 초기에 2배씩 올리는 부분을 slow start단계라고 부른다.
이떄 Loss가 발생해서 다시 시작하게 되면, sstreshHold값은 loss 발생 값의 절반으로 설정된다.
Reno의 경우 반만 깍아서 sstresh에서 다시 출발하고, Tahoe는 1부터 출발한다
Congestion Avoidance 상태에서는 Additive 증가량을 할 때 다음과 같은 계산을 한다.
FSM
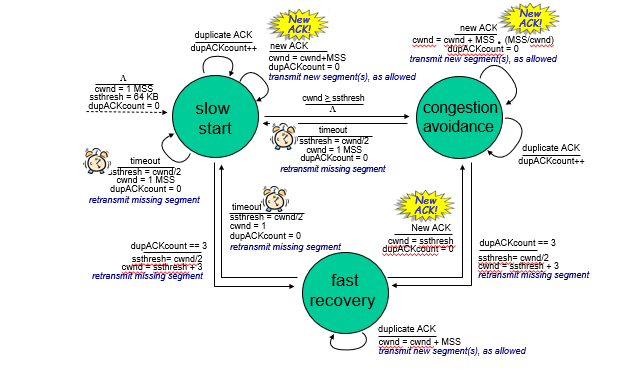
Slow Start에서 T.O Loss 발생하면 cwmd = 1로 간다.
Dup Ack 3이면 Fast Recovery상태로 돌아간다.
하지만 실제로 FR 발생하면 그냥 반을 자르는게 아니라, ssthresh + 3이다.
Fast Recovery 상태에서는 New ACK가 오면 빠져나간다.
Reno의 경우 반만 깍아서 sstresh에서 다시 출발하고, Tahoe는 1부터 출발한다
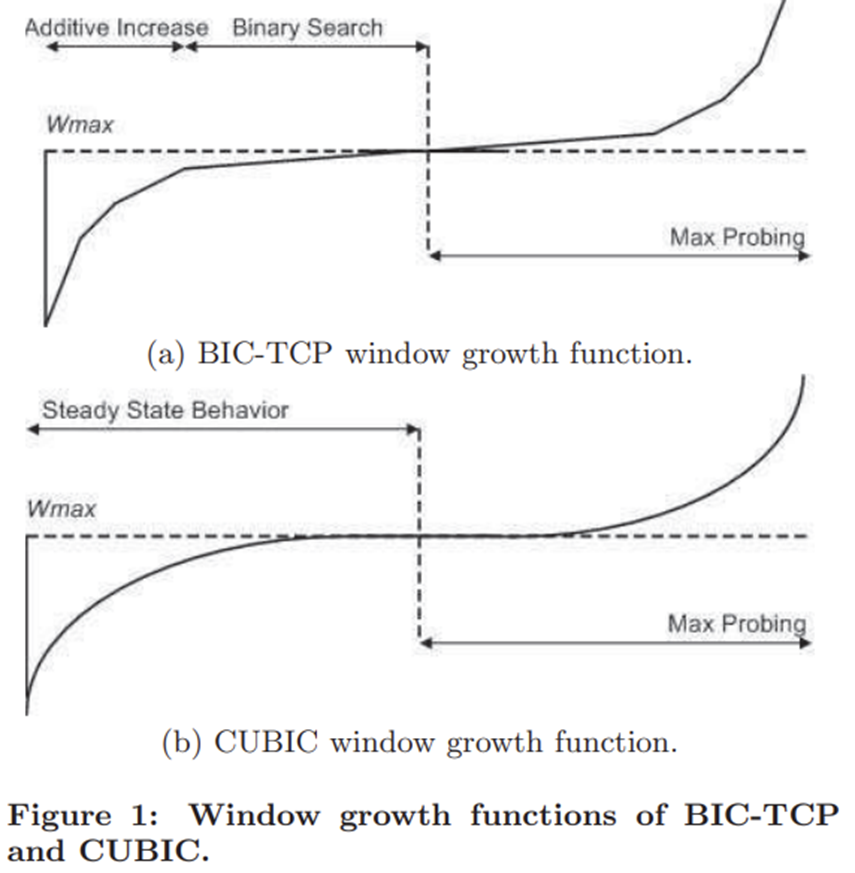
TCP CUBIC
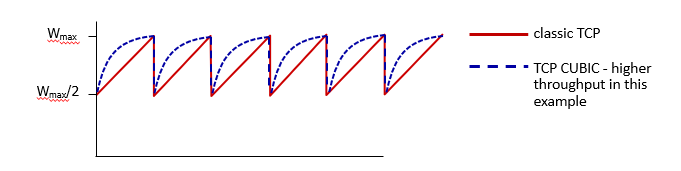
윈도우를 줄였다고 가정하자. 그러면 로스가 발생했다는 뜻이다. 그러면, 그 다음은 천천히 올릴 필요가 있을까? 너무 보수적인 증가가 아닐까?
다시 올라가는 방식을 additivce, slow start하는게 아니라, 그냥 이전 지점까지 빠르게 복구하고 거기서 관망을 해보자는 아이디어이다.
Congestion 이 발생하면 그 로스는 한 라우터에서 발생했을건데, bottlenectLink에 초점을 맞춰서 congestion control하는게 합당하다. 근데 사실 bottleneck이 누군지는 모르고, 이 링크는 조금만 시간이 지나도 바뀔 수가 있기에 굳이 천천히 올라갈 필요가 없다.
따라서 CWND를 빠르게 올리다가 Loss발생 지점 근처에 오면 천천히 올리자는 의견이다.
사례
BandWidth를 100% 활용하면 RTT동안 보낼 수 있는 최대량을 보내는것이다. 이는 ACK가 오기 전에 보낼 수 있는 최대량이고, 이는 곳 CWND의 MAX 값이다.
링크 10gbps, rtt 100ms인 링크가 있을 때, BDP는 1Gigabit이다.
총 1기가비트를 보낼 수 있는데 패킷으로 따지면 10만개를 보낼 수 있는 링크가 된다.
즉 이를 다 쓰려면 윈도우 사이즈가 10만이 되어야한다. 절반인 오만에서 시작해도 이를 직접 하나씩 올라가려면 1.4 시간이나 걸린다.
근데 트래픽이 1.4시간동안 데이터를 내보낼 일이 없다. 대부분의 응용은 조금 보내다가 끝난다. 즉, 너무 보수적이라 성능낭비가 심하다는거다.
이 방식으로 새로운 curve가 제시되었는데 x^3 같은 커브이다.
K = TCP가 W에 도달하는 시간 (조절가능)

DelayBased Congestion Control
기존 Congestion에 대한 문제점
Loss에서 Congestion Control을 한다. 즉, LOSS 발생까지 CWMD를 올린다. 이러면 Bottleneck Link의 부담이 너무 크다.
이에 대한 아이디어가 BBR이라는 논문이다.
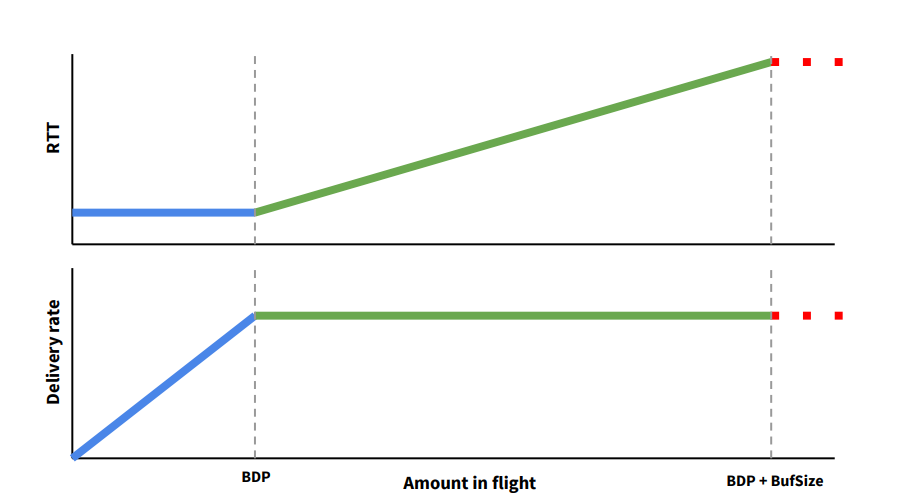
위 그림에서 보이는것처럼 BDP에 도달하고나면, 실제로 in flight데이터는 늘어나지 않는데, RTT만 계속 증가하는것을 볼 수 있다.
따라서 꽉 채우는건 좋은데 특정 지점에서 더 이상 가지 말고 미리 Delay가 늘어나는 시점에서 Congestion Control하자는 방식이다.
결과적으로는 로스는 안보고 로스가 나기전에 딜레이만 보고 컨트롤을 한다
방법
RTT를 어느정도 측정해서 상태가 좋은 minimum값을 뽑아낸다. Data sent during rtt / rtt
즉, minimum rtt동안 보낸 양이 기준 rate가 되고, 그 rate에 근접해있으면 상황이 아주 좋은것이고, 이 기준 rate보다 후달리면 좋은 상태에 도달하지 못했으니 congest를 해야한다.
즉, 기준이 되는 딜레이를 보고 그거보다 높으면 줄이고 낮으면 놔두는 그런 원리다.
