관계 데이터 모델(Relational Data Model)
IMS 계층형 네트워크 DB -> relation
절차적 질의를 함
관계 데이터 모델은 비절차적 질의하는 것
특성
- 수학에서의 relation과 집합(set)이론에 기초
- 일반사용자는 테이블 형태로 생각
하지만 통상의 테이블 개념과는 다름
•테이블의 열(column) = 필드(field) 혹은 아이템(item)
≒ 관계 데이터 모델의 애트리뷰트(attribute)
•테이블의 행(row) = 레코드(record)
≒ 관계 데이터 모델의 투플(tuple)
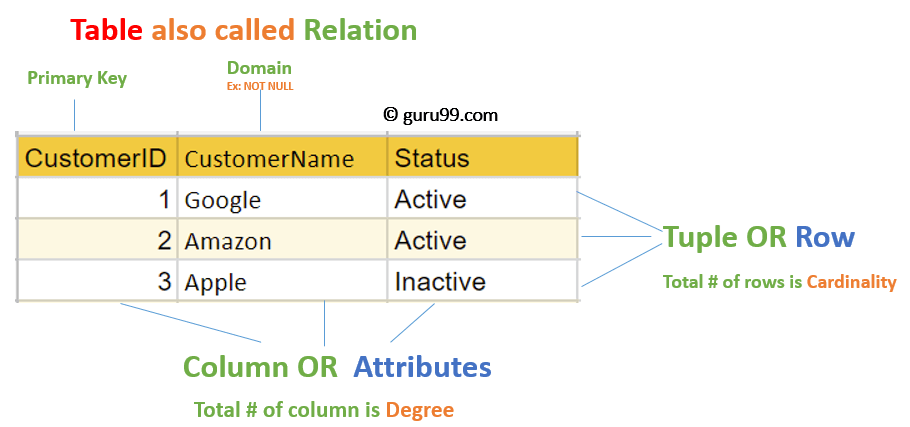
위에서 보다싶이 데이터를 저장해둔 전체 테이블을 relation이라 부른다. 행은 attribute라고도 부르며 열은 tuple이다.
테이블 : 릴레이션
attribute의 순서
relation에서는 이 순서가 의미가 없음
집합
1) 중복 x
2) 순서 x
모든 데이터가 릴레이션으로만 저장된다. 이것이 관계형 데이터베이스의 특징
Attribute & Domain
- 도메인 : attribute가 취할 수 있는 value들의 집합
- attribute : 도메인의 역할 이름
하나의 relation 안에서 attribute의 이름은 모두 달라야 함
- 단순 도매인 (simple domain)-> 단순 애트리뷰트 : 원자값 (더 이상 분해될 수 없음)
- 복합 도메인 composite domain)
복합 애트리뷰트 : 복합값 (분해 될 수있음)
ex) 연월일 -> 날짜 : <연월일>
- 하지만 이것은 사용자가 어떤식으로 질의하냐에 달린것이지 도메인 자체가 어떤것이다 이런건 아님
Schema
Data 를 저장하는 학생명단
-> 어떠한 틀(Schema)에 저장해야함
- 스키마는 구성, 정의를 말함
- relation에 대한 정의가 필요하다 이를 우리는 relation schema라고 부른다. 이 스키마에는 '(학번 이름 학년 학과로 정의되는 Student라는 데이터가 있다)' 라는 metadata 가 저장되어있음
학생 relation은 릴레이션 스키마 + 인스턴스(튜플들)을 포함해서 부름
Relation Schema
- 릴레이션에 데이터 값을 넣을 수 있도록 하는 틀
- 릴레이션 이름 + 어트리뷰트 이름 (대소문자 구분 안함)
- R (A1, A2) <- Relation (Attribute)
- 정적 성질을 가짐
- 시간에 무관 (시간에 따라 변경되지 않음)
- 릴레이션 타입과 같은 의미
Relation instance
- 릴레이션 외연 (realtion extension)이라고 함
릴레이션 R의 인스턴스 - 어느 한 시점에 릴레이션 R이 포함하고 있는 투플들의 집합 릴레이션의 내용, 상태, snapshot
- 동적 성질
- 삽입, 삭제, 갱신으로 시간에 따라 변함
- 릴레이션 값(보통 릴레이션)
트랜잭션 (transaction)
원자적으로 이루어저야 함
사용자가 보는 데이터는 연산 시작전 혹은 시작 후를 보는것이지 중간에 있는 데이터를 보지는 않음
Relation R의 수학적 정의
• 릴레이션
R : 카티션 프로덕트(Cartesian product)의 부분집합
학번 도메인과 과목번호 도메인을 카디션 프로덕트 한 것 -> 모든 조합가능한것들
-
릴레이션 R 모든 도메인의 카디션 프로덕트의 부분집합
-
개념적 정의 : 릴레이션 스키마 + 릴레이션 인스턴스
R 의 차수 (도메인의 개수)
튜플의 개수 (카디널리티)
튜플의 유일성
Relation = 투플들의 집합
튜플의 무순서성
릴레이션 : 추상적 개념 <= 튜플의 집합
테이블 : 구체적 개념
애트리뷰트의 무순서성
릴레이션 스키마 -> 에트리뷰트들의 집합
튜플 쌍의 집합
즉, Attribute에는 순서가 없다
에트리뷰트의 원자성
에트리뷰트값은 원자값, 논리적으로 분해 불가능
정규화 릴레이션
애트리뷰트 값으로 원자 값만 허용되는 릴레이션
비정규화 릴레이션은 분해를 통해 정규화
동등한 의미를 유지
널 값도 원자로 취급
Null = Unknown / inapplicable
관계 DB (relational database)
- 테이블들의 집합
- 데이터베이스를 시간에 따라 그 내용이 변할 수 있는 테이블 형태로 표현
Relational database schema
= {relation schema} + {무결성 제약조건}
-
관계 데이터 모델 프로그래밍 시스템
- 릴레이션 파일
- 튜플 레코드(레코드 어커런스)
- 애트리뷰트 필드(필드 타입)
키
각 튜플을 유일하게 식별할 수 있는 에트리뷰트 집합 (set of attributes)
• 후보 키(candidate key)
• 릴레이션 R(A1, A2, ..., An)에 대한 애트리뷰트 집합,
K({Ai, Aj, ..., Ak})로서 다음 두 성질을 만족
① 유일성(uniqueness)
각 투플에 대해 K({Ai, Aj, ... , Ak})의 값(< vi, vj, ... ,vk >)은 유일'
② 최소성(minimality)
K는 각 투플을 유일하게 식별하는데 필요한
애트리뷰트만 포함 학번, 주민번호
Various Keys
슈퍼 키 (super key)
• 유일성(uniqueness)은 만족하지만 최소성(minimality)은
만족하지 않는 애트리뷰트의 집합
기본 키 (primary key)
• 후보 키(candidate key) 중에서 지정된 하나의 키
• 데이터베이스 설계자가 지정
• 각 투플에 대한 기본 키 값은 항상 유효한 값이어야 함
• null 값이 허용되지 않음
대체 키 (alternate key)
• 후보 키 중에서 기본 키를 제외한 나머지 후보 키
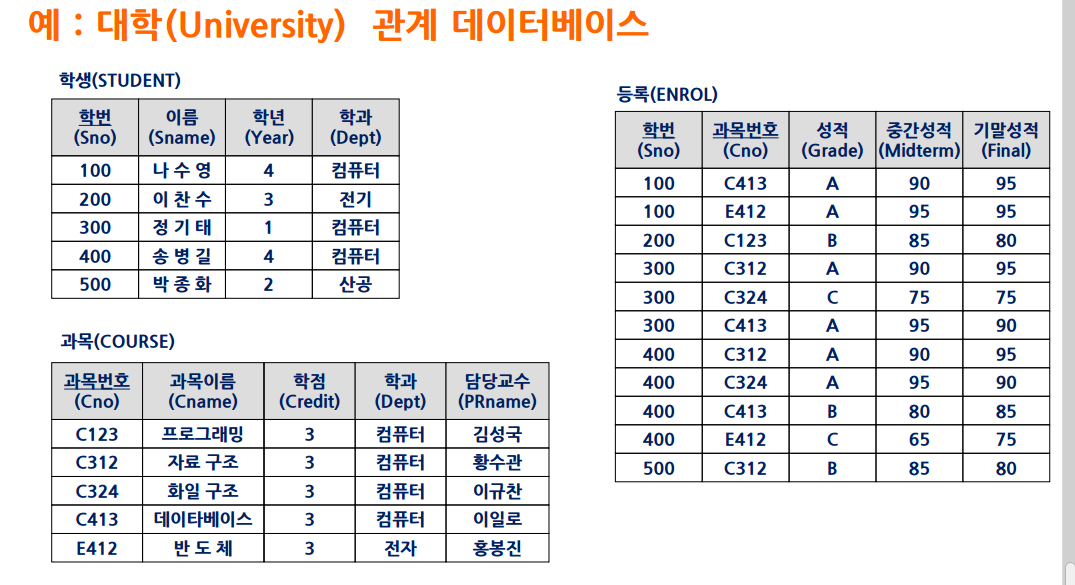
외래 키
요약 : 다른 두 릴레이션을 연결해주는 키
학생 relation, 등록 relation 이 있음
등록에서 sno는 학생에서 특정 학생을 지칭함
등록에서는 그 자체로는 키가 될 수 없음 (2개가 있을수도 있음)
하지만 다른 relation에서는 키로 사용되기도 함.
이를 외래키라고 함
ex) 학생에서는 sno가 key가 아니지만, 등록에서는 sno가 key로 성립함
하지만 외래키는 존재하는 값, 혹은 null값이면 안된다. S에 존재햐야만 함
• 릴레이션 R의 애트리뷰트 집합 FK가 릴레이션 S의 기본키일 때 이 FK는 R의 외래 키(foreign key) 이다.
• (FK의 도메인) = (S의 기본 키의 도메인)
• FK의 값은 S에 존재하는 값이거나 null
• R과 S가 같은 릴레이션일 수도 있음
• R을 참조 릴레이션 (referencing relation), S를 피참조
릴레이션 (referenced relation) 이라 함
• 릴레이션 R은 FK를 통해 릴레이션 S를 참조

데이터베이스의 상태
어느 한 시점에 DB에 저장되어 있는 모든 DB값 (튜플)
DB instance
DB 스키마에 포함되어 있는 모든 Relation 들의 instance set
- 데이터베이스 상태의 계속적인 변화
- 삽입 삭제 변경 연산
DBMS는 DB의 상태변화에도 항상 무결성 제약을 만족히시키도록 해야함
무결성 제약
개체 무결성
기본 키 값은 언제 어느떄고 null을 가질 수 없다
null 값
• 정보 부재를 명시적으로 표현하는 특수한 데이타 값
① 알려지지 않은 값(unknown value)
② 해당 없음(inapplicable)참조 무결성
외래 키 값은 반드시 피참조 릴레이션의 기본 키값이거나 null 이다
무결성 제약조건은 DB State가 항상 만족시켜야 될 제약조건임
