N+1 문제를 해결하면 서버성능에 도움이 될까?(feat. Jmeter)
N+1 문제를 해결하면 쿼리 수가 줄어드는 것은 확인해 보았지만 이것이 실질적으로 서버성능에 도움이 되는 지 확신이 없었고 이를 검증해보기 위해 test도구를 도입해 실험해 보기로 했다.
🤔 고민
다만 이에 따라 어떤 테스트 도구를 사용할 것인가라는 고민이 생겼다.
다만 최종적으로 JMeter를 사용하기로 결정했는데
jmeter의 경우 GUI 지원과 레퍼런스가 많고 분산부하 테스트를 기본제공한다는 점에서 테스트 도구를 처음 시작하는 나에게 잘 맞다고 생각이 들었기 때문이다.
k6의 경우 적은 메모리를 사용하여 더 많은 부하를 가할 수 있다는 장점이 있지만 이번에 내 목적은 쿼리튜닝으로 서버 응답 속도 성능이 향상되는 지 보는 것이기 때문에 채택하지 않았다.
테스트 코드
public interface SuggestionRepository extends JpaRepository<Suggestion, Long> {
@EntityGraph(attributePaths = {"user","restaurant"})
@Query("select m from Suggestion m left join fetch m.user left join fetch m.restaurant")
List<Suggestion> findAll();
}spring.jpa.properties.hibernate.default_batch_fetch_size=1000로컬환경
테스트 세팅
우선 테스트 연습 겸 실제로 향상의 효과가 있는 지 로컬환경에서 테스트 해봤다.
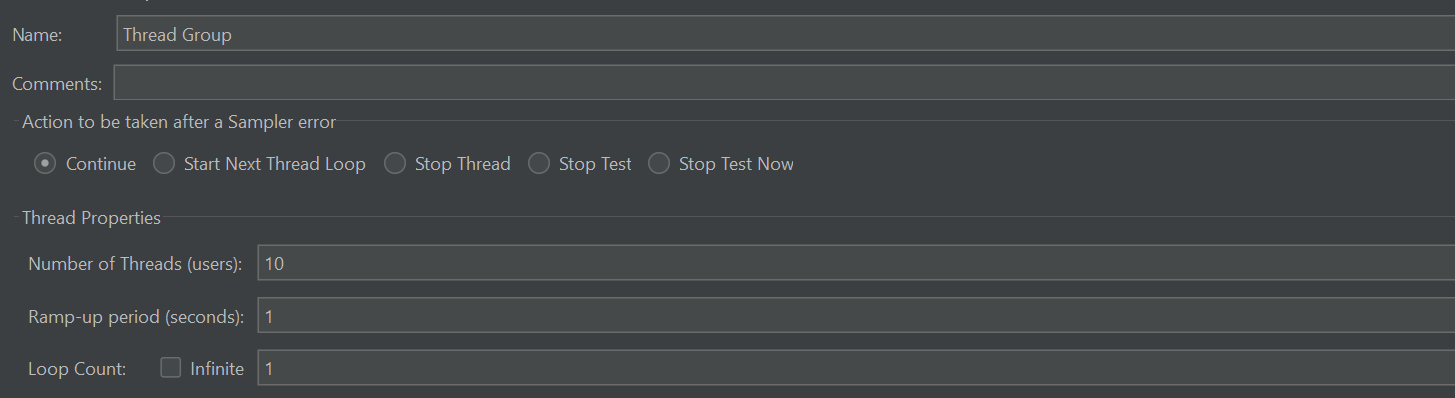
10명의 유저가 1초마다 1번의 요청을 보내 총 10번의 요청을 보내는 방식으로 테스트 하였다.
기본

HIBERNATE:
SELECT s1_0.id,
s1_0.closed,
s1_0.closed_date,
s1_0.content,
s1_0.created_date,
s1_0.restaurant_id,
s1_0.title,
s1_0.user_id
FROM suggestion s1_0
HIBERNATE:
SELECT r1_0.id,
r1_0.category,
r1_0.content,
r1_0.icon,
r1_0.NAME
FROM restaurant r1_0
WHERE r1_0.id = ?
HIBERNATE:
SELECT u1_0.id,
u1_0.created_date,
u1_0.deleted_date,
u1_0.user_email,
u1_0.enabled,
u1_0.user_name,
u1_0.user_nickname,
u1_0.user_id,
u1_0.user_password,
ur1_0.user_id,
ur1_0.user_role_id,
ur1_0.created,
r1_0.id,
r1_0.role
FROM USER u1_0
LEFT JOIN user_role ur1_0
ON u1_0.id = ur1_0.user_id
LEFT JOIN role r1_0
ON r1_0.id = ur1_0.role_id
WHERE u1_0.id = ?
HIBERNATE:
SELECT r1_0.id,
r1_0.category,
r1_0.content,
r1_0.icon,
r1_0.NAME
FROM restaurant r1_0
WHERE r1_0.id = ? EntityGraph 적용

HIBERNATE:
SELECT s1_0.id,
s1_0.closed,
s1_0.closed_date,
s1_0.content,
s1_0.created_date,
r1_0.id,
r1_0.category,
r1_0.content,
r1_0.icon,
r1_0.NAME,
s1_0.title,
u1_0.id,
u1_0.created_date,
u1_0.deleted_date,
u1_0.user_email,
u1_0.enabled,
u1_0.user_name,
u1_0.user_nickname,
u1_0.user_id,
u1_0.user_password
FROM suggestion s1_0
LEFT JOIN restaurant r1_0
ON r1_0.id = s1_0.restaurant_id
LEFT JOIN USER u1_0
ON u1_0.id = s1_0.user_id batch size 적용

HIBERNATE:
SELECT s1_0.id,
s1_0.closed,
s1_0.closed_date,
s1_0.content,
s1_0.created_date,
s1_0.restaurant_id,
s1_0.title,
s1_0.user_id
FROM suggestion s1_0
HIBERNATE:
SELECT r1_0.id,
r1_0.category,
r1_0.content,
r1_0.icon,
r1_0.NAME
FROM restaurant r1_0
WHERE r1_0.id IN ( ?, ?, ?, ?,
?, ?, ?, ?,
?, ?, ?, ?,
?, ?, ?, ?,
?, ?, ?, ?,
...
?, ?, ?, ? )
HIBERNATE:
SELECT u1_0.id,
u1_0.created_date,
u1_0.deleted_date,
u1_0.user_email,
u1_0.enabled,
u1_0.user_name,
u1_0.user_nickname,
u1_0.user_id,
u1_0.user_password,
ur1_0.user_id,
ur1_0.user_role_id,
ur1_0.created,
r1_0.id,
r1_0.role
FROM USER u1_0
LEFT JOIN user_role ur1_0
ON u1_0.id = ur1_0.user_id
LEFT JOIN role r1_0
ON r1_0.id = ur1_0.role_id
WHERE u1_0.id = ? fetch join 적용

HIBERNATE:
SELECT s1_0.id,
s1_0.closed,
s1_0.closed_date,
s1_0.content,
s1_0.created_date,
r1_0.id,
r1_0.category,
r1_0.content,
r1_0.icon,
r1_0.NAME,
s1_0.title,
u1_0.id,
u1_0.created_date,
u1_0.deleted_date,
u1_0.user_email,
u1_0.enabled,
u1_0.user_name,
u1_0.user_nickname,
u1_0.user_id,
u1_0.user_password
FROM suggestion s1_0
LEFT JOIN restaurant r1_0
ON r1_0.id = s1_0.restaurant_id
LEFT JOIN USER u1_0
ON u1_0.id = s1_0.user_id
HIBERNATE:
SELECT ur1_0.user_id,
ur1_0.user_role_id,
ur1_0.created,
r1_0.id,
r1_0.role
FROM user_role ur1_0
LEFT JOIN role r1_0
ON r1_0.id = ur1_0.role_id
WHERE ur1_0.user_id = ? - 쿼리 개수 : 기본> batch size > fetch join > entityGraph
- 평균응답시간 : 기본 = batch size > fetch join = entityGraph
- 최소응답시간 : 기본 > batch size = fetch join = entityGraph
- 최대응답시간 : 기본 > barch size = fetch join > entityGraph
- 표준 편차 : batch size > 기본 > fetch join > entityGraph
결과값을 보면 전체적으로 아무것도 적용하지 않았을 때에 비해 응답시간이 개선되는 경향이 관찰되었다.
특히 가장 개선 효과가 컸던 EntityGraph의 경우 평균 응답속도가 30%정도 향상되는 것이 관찰되었다.
해당 결과를 통해 N+1 문제를 해결하는 것이 성능개선에 효과가 있음을 우선 알 수 있었다.
다만, 로컬 환경에 표본도 적었기에 이를 개선하여 배포 환경에서 제대로 테스트해보기로 했다.
배포환경
로컬에서 개선되는 부분을 확인하였으니 본격적으로 배포환경에서 테스트를 해보겠다.
참고 : 로컬의 경우 jmeter와 메모리를 공유하니 정확한 결과가 안나온다.
aws 프리티어를 사용중이라 시간을 아끼기 위해 로컬에서 bootjar을 이용해 미리 빌드한 파일을 클론해서 실행하였다.
테스트 환경

entityGraph를 적용한 plate_api_graph 와 적용하지 않은 plate_api_normal과 성능비교를 했다.


그리고 다양한 요청환경에서도 유효한 지 확인해보기 위해
- 10명의 유저가 1번씩 요청한 경우
- 10명의 유저가 1번씩 요청한 경우를 5번
- 50명의 유저가 1번씩 요청한 경우
로 테스트 해보았다.
참고로 테스트 개수는 중심 극한 정리를 이용하여 넉넉하게 50으로 잡았다.
💯 중심극한정리?
- 표본 크기가 충분히 큰 경우 표본집단의 평균은 모집단의 표본 평균 분포에 근사한다는 정리
- 대개 30이상이면 잘 적용된다.
테스트
10명의 유저가 1번씩 요청
기본

EntityGraph 적용

batch size 적용

fetch 적용

10명의 유저가 1번씩 요청을 5번 했을 경우
기본

EntityGraph 적용

batch size 적용

fetch 적용

50명의 유저가 1번씩 요청을 했을 경우
기본

EntityGraph 적용

batch size 적용

fetch 적용

요청이 적을 때는 batch size가 다른 방식에 비해 효과가 좋은 것을 관찰할 수 있었다.
다만, 요청이 많아 질수록 batch size보다 entityGraph나 fetch방식이 훨씬 효과가 좋은 것을 관찰 할 수 있었다.
보다시피 3가지 케이스 모두 평균 응답시간이 30퍼센트이상 감소하는 효과를 얻을 수 있었다.
이로써 N+1문제를 해결하는 것이 서버 성능 향상에 도움이 된다는 것을 확인할 수 있었다.
실제환경에서는 동시에 요청하는 숫자가 많은 만큼 entityGraph나 fetch를 적용하여 개선할 듯하다.
결론
-
entityGraph와 같은 도구를 도입한 결과 평균 30퍼센트 정도의 응답속도 개선이 있음을 확인 할 수 있었다.
-
다만, 단일 조회 쿼리에서도 위와 같은 개선효과가 있을 지는 추후에 실험해 볼 여지가 있을 것이다.
참고
https://hamait.tistory.com/479
https://rfriend.tistory.com/810
https://m.blog.naver.com/mykepzzang/220851280035
https://effortguy.tistory.com/164
https://velog.io/@xogml951/EntityGraph%EC%99%80-fetch-join-%EC%B0%A8%EC%9D%B4
