- project04.py
import requests
from bs4 import BeautifulSoup
from datetime import datetime
from openpyxl import Workbook
import pandas
import sys
url = 'https://news.naver.com'
html = requests.get(url)
bsObject = BeautifulSoup(html.text, 'html.parser')
tap = input("Choice - headline, politics, economy, society, life, world, it: ")
newsdict = {
"TITLE" : [],
"LINK" : []
}
nnews = list()
nlink = list()
if tap == "headline":
my_news = bsObject.select(
'div#today_main_news > div.hdline_news > ul > li > div.hdline_article_tit'
)
my_news_link = bsObject.select(
'div[id=today_main_news] > div.hdline_news > ul > li > div.hdline_article_tit > a'
)
for link in my_news_link:
nlink.append("https://news.naver.com" + link.get('href'))
elif tap == "politics" or tap == "economy" or tap == "society" or tap == "life" or tap == "world" or tap == "it":
test_title = 'div#section_'+ tap +' > div.com_list > div > ul > li > a > strong'
test_link = 'div#section_'+ tap +' > div.com_list > div > ul > li > a'
my_news = bsObject.select(test_title)
my_news_link = bsObject.select(test_link)
for link in my_news_link:
nlink.append(link.get('href'))
else:
print("You entered the wrong word.")
sys.exit()
for news in my_news:
nnews.append(news.text.strip())
for i in range(len(nnews)):
newsdict["TITLE"].append(nnews[i])
newsdict["LINK"].append(nlink[i])
pd = pandas.DataFrame(newsdict)
wb = Workbook()
ws = wb.active
ws.title = "NEWS"
time = datetime.today().strftime("%Y/%m/%d %H:%M:%S")
print(pd)
ask = input("Do you want to save? y/n: ")
for i in range(len(nnews)):
j=i+1
ws.cell(row=j, column=1).value = time
ws.cell(row=j, column=2).value = newsdict["TITLE"][j-1]
ws.cell(row=j, column=3).value = newsdict["LINK"][j-1]
ws.column_dimensions['A'].width = 20
ws.column_dimensions['B'].width = 65
ws.column_dimensions['C'].width = 88
if ask == "y":
fileName = input("Filename? : ") + '.xlsx'
wb.save(fileName)
elif ask == "":
fileName = 'project04.xlsx'
wb.save(fileName)
else:
print("End")-
터미널에서 해당 python파일 실행시 화면
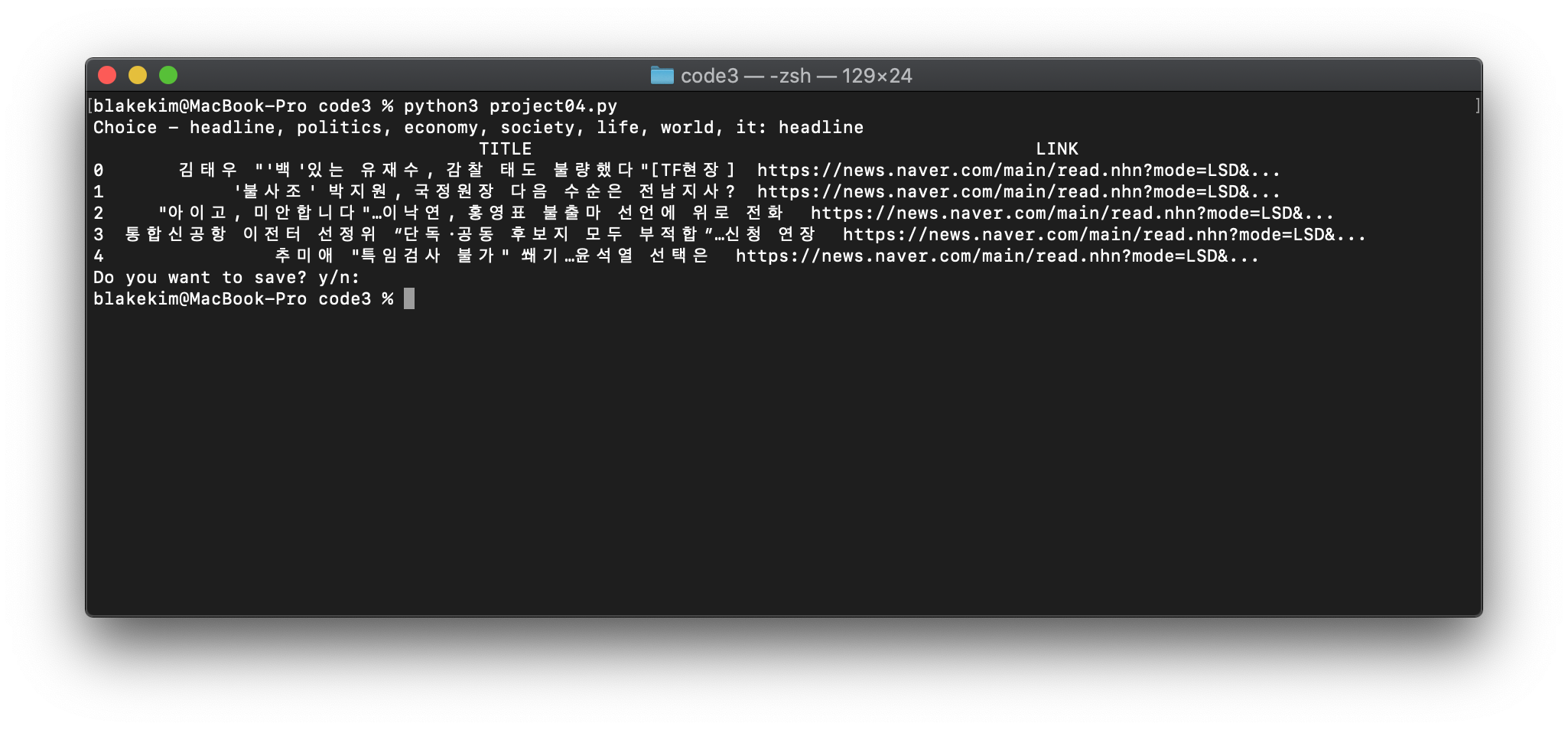
-
해당 python파일 실행 후 저장된 xlsx파일 화면
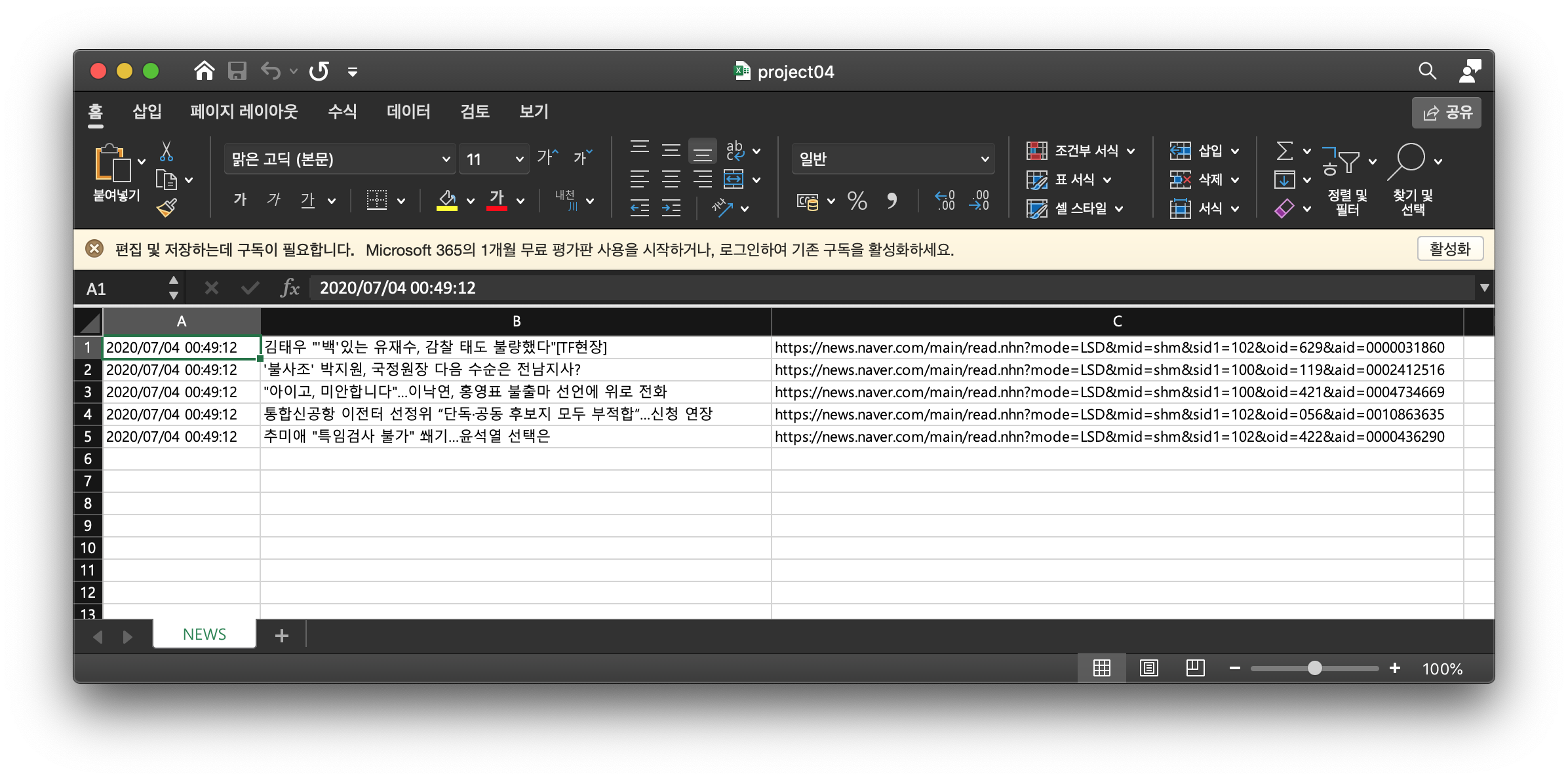

BackEnd