Data Structure Introduction
자료구조란
자료구조란 데이터에 편리하게 접근하고 조작하기 위한 데이터를 저장하거나 조직하는 방법이다. 자료구조의 종류에는 여러가지가 있다. 하지만 모든 목적에 부합하는 자료구조는 없기 때문에 각각의 자료구조가 갖는 장점과 한계를 잘 이해하고 상황에 맞게 올바른 자료구조를 선택하고 사용하는 것이 중요하다.
자료구조는 언어별로 지원하는 양상이 다르다.
각 언어가 가진 자료구조의 종류와 그것에 대한 사용 방법을 익히는 것이 중요하지만 무엇보다 각 자료구조의 본지로가 컨셉을 이해하고 상황에 맞는 적절한 자료구조를 선택하는 것이 중요합니다.
언어별로 지원하는 자료구조의 양상이 다르더라도 개념을 올바르게 이해한다면 해당 언어에 맞추어서 사용하기만 하면 됩니다.
자료구조가 중요한 이유
자료구조란, 상황과 문맥에 맞게 데이터를 담을 수 있는 적절한 구조를 말합니다. 데이터에 맞는 적절한 자료 구조를 사용하는 것은 전체 개발 시스템에 굉장히 큰 영향을 끼칩니다.
자료구조의 분류
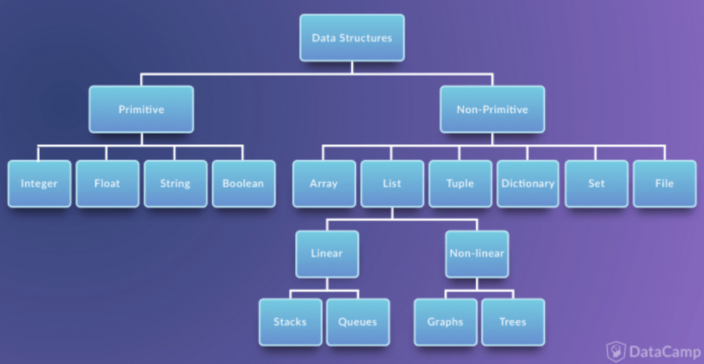
- Primitive Data Structure(단순 구조): 프로그래밍에서 사용되는 기본 데이터 타입
- Non-Primitive Data Structure(비단순 구조): 단순한 데이터를 저장하는 구조가 아니라 여러 데이터를 목적에 맞게 효과적으로 저장하는 자료 구조
- Linear Data Structure(선형 구조): 저장되는 자료의 전후 관계가 1:1 (예. List, Stacks, Queues)
- Non-Linear Data Structure(비선형 구조): 데이터 항목 사이의 관계가 1:n 또는 n:m (예.Graphs, Trees)
일반적으로 가장 자주 사용되는 자료구조
- Array(List)
- Tuple
- Set
- Dictionary
- Stack & Queue
- Tree
Array(List)
순차적으로 데이터를 저장하는 자료 구조
Array의 가장 큰 특징은 순차적(ordered)으로 데이터를 저장한다는 점입니다. 자료구조에 저장하는 데이터는 일반적으로 요소(element)라고 합니다. Array는 주로 서로 연결된 데이터들을 순차적으로 저장할 때 사용합니다. 순서가 상관 없더라도 서로 연결된 데이터들을 저장할 때 일반적으로 사용됩니다. 그래서 array가 가장 자주 사용되는 자료구조 중 하나가 되는 것입니다.
기타 특징
삽입(insertion) 순서대로 저장됩니다. 즉, 새로 삽입되는 요소는 array의 새로운 꼬리가 됩니다. 이미 생성된 리스트도 수정 가능합니다(mutable). 동일한 값도 여러번 삽입 가능합니다.
Multi-dimensional Array(다중차원 배열): Array의 요소가 array가 될 수 있습니다. 이러한 array를 다중차원(multi-dimensional) array 라고 합니다. 일반적으로 2D (2차원) array가 많이 사용됩니다.
Array 내부 구조
Array의 가장 큰 특징은 순차적으로 데이터를 저장하는 것이었습니다. 이렇게 순서가 있다보니 당연히 순차적으로 번호를 지정할 수 있습니다. 마치 학교에서 이름을 부르지 않고 번호를 불르는 것과 동일한 개념입니다. 이 번호를 index 라고 합니다. Index는 0부터 시작됩니다. Index는 마이너스 부호를 가질 수 도 있습니다. 마이너스 index는 맨 마지막 요소 부터 시작합니다. 예를 들어, -1 은 맨 마지막 요소입니다.
그렇다면 왜 Array가 순차적으로 데이터를 저장할 수 밖에 없을까요?
실제 메모리 상에서, 즉 물리적으로 데이터가 순차적으로 저장되기 때문입니다.
데이터에 순서가 있기 때문에 index가 존재하며 0부터 시작하는 Index를 사용해 특정 요소를 array(list)로 부터 읽어 들이는 것이 가능하고 Slicing: 요소의 특정 부분, 즉 n번째 index부터 m번째 index까지 따로 분리해 조작하는 것이 가능합니다.
단점
Removing or Adding Elements
순차적으로 담겨있는 데이터 중 특정 위치에 있는 중간의 요소가 삭제 되는 경우에, 항상 메모리가 순차적으로 이어져있어야 하기 때문에, 삭제된 요소로 부터 뒤에 있는 모든 요소들을 앞으로 한칸씩 이동시켜주어야 합니다. 이 뜻은 배열에서 요소를 삭제하는 것은 다른 자료 구조에 비해 느릴 수 있다는 뜻입니다. 요소를 삭제하는 과정이 코드 상에서는 한 줄 이지만 실제 메모리 상에서 이루어지는 작업(operation)은 훨씬 커집니다.(expensive operation) 중간에 요소가 추가 되는 경우도 마찬가지 입니다. 특정 위치에 새롭게 요소가 추가되는 경우에는 그 뒤의 요소들이 하나씩 밀리게 됩니다.
그렇기 때문에 Array는 정보가 자주 삭제 되거나 추가되는 데이터를 담기에는 적절치 않습니다.
Array Resizing
Resizing 이란, 말 그대로 사이즈를 다시 조정한다는 뜻입니다. 배열은 메모리가 순차적으로 채워지기 때문에 배열이 처음 생성될 때 어느 정도 메모리를 미리 할당합니다. 이를 전문 용어로 pre-allocation 이라고 합니다. 메모리를 pre-allocation 함으로써 새로 추가되는 요소들도 순차적으로 메모리에 저장될 수 있습니다. 하지만 요소들이 처음 할당한 메모리 이상으로 많아진다면 resizing이 필요합니다. 즉, 메모리를 더 할당해야 합니다. 그리고 추가적으로 할당된 메모리 또한 순차적이어야 합니다. 그럼으로 배열의 resizing은 상대적으로 오래걸리는 operation 입니다.
- 100개의 메모리 공간 다 차서 100개를 추가해야 되는 경우
1) 200개 크기의 메모리를 생성 후
2) 기존 100개를 복사하고
3) 그 다음 101번 부터 데이터가 순차적으로 추가됩니다.
그렇기 때문에 Array 는 사이즈 예측이 잘 안 되는 데이터를 다루기에는 적절치 않습니다. 일반적으로 대부분의 언어에서는 배열의 메모리 pre-allocation과 resizing을 자동으로 실행합니다. 하지만 이러한 점을 알고 있어야 사이즈가 급격하게 자주 늘어날 확률이 있는 데이터는 array 말고 더 적합한 자료구조를 선택해야 한다는 것을 알 수 있습니다.
언제 사용하면 좋을까?
-
순차열적인 데이터를 저장할 때
예) 주식 가격. 어제의 2만원과 오늘의 2만원이 다름 즉, 값보다는 순서가 중요한 데이터 -
다차원 데이터를 다룰 때 >>> Multi-dimensional Array
-
어떠한 특정 요소를 빠르게 읽어야 할 때 >> index를 통해 곧바로 읽을 수 있기 때문
-
데이터의 사이즈가 급변하게 자주 변하지 않을 때
-
요소가 자주 삭제 되거나 추가되지 않을 때
Tuple
List와 마찬가지로 데이터를 순차적으로 저장할 수 있는 순열 자료구조입니다. 하지만 list와 다르게 한 번 정의되고 나면 수정할 수 없습니다.(immutable) 2-3개 정도의 적은 수의 소규모 데이터를 저장할 때 많이 사용합니다. 함수에서 리턴 값을 한 개 이상 리턴하고 싶을 때 자주 쓰입니다.
Tuple Is Not For Every Language!
Python은 tuple이 있고 JavaScript는 없다. 그렇다고 Python > JavaScript는 아니다. 다만 JavaScript에서는 tuple을 굳이 따로 안 만든 것 뿐입니다. Tuple은 list와 너무 비슷하기 때문에 굳이 제공하지 않는 언어도 많습니다. JavaScript에서는 그냥 array를 사용해도 상관없다.
Tuple의 장점
Tuple은 간단한 값을 빨리 표현하고 싶을 때 많이 사용합니다. 예를 들면 함수에서 리턴 값을 한 개 이상 리턴하고 싶을 경우 (ex. 지도 좌표)
Tuple의 단점
Tuple의 단점은 데이터가 무슨 의미인지 명확하지 않다는 것입니다. 데이터의 의미를 문맥을 보고 가정해야 합니다. 예를 들면 객체의 경우 key-value 쌍으로 이루어진 데이터이기 때문에 무슨 데이터인지 파악이 쉽지만, Tuple의 경우 괄호 안에 데이터만 담겨있기 때문에 문맥에 맞게 의미를 추측해야 합니다. 그렇기 때문에 Tuple은 소규모 데이터를 다루기에 적합합니다.
cf) 이러한 단점을 극복하기 위해 Named Tuple 이란 것도 존재합니다.(Python)
언제 사용하면 좋을까?
Array(List)를 쓰기에는 간단한 데이터들을 표현할 때 사용합니다. Tuple이 Array(List) 보다 더 가볍고 메모리도 적게 먹는다.. 예) 좌표 데이터
