정렬 알고리즘
정렬 알고리즘은 목록의 요소를 특정 순서대로 넣는 알고리즘이다. 숫자식 순서와 사전식 순서로 정렬한다. 정렬 알고리즘은 간단하고 익숙하면서 유용하지만 효율적으로 해결하기 쉽지 않다. 알고리즘을 입문하기 좋은 주제라고 한다. 알고리즘의 꽃이라고 한다. 실무적으로 구현하는 경우는 거의 없지만 공부를 위한 공부를 하기 위해 배운다고 한다. 이것을 구현해나가면서 얻는 것이 굉장히 크다고 한다. 기본기를 익힌다고 생각하면 좋을 듯하다.
버블 정렬
코드로 먼저 살펴보면 다음과 같다.
def bubblesort(A):
for i in range(1, len(A)):
for j in range(0, len(A)-1):
if A[j] > A[j+1]:
A[j], A[j+1] = A[j+1], A[j]버블 정렬은 전혀 중요하지 않다고 한다. 위 코드만 보아도 시간 복잡도가 항상 O(n^2)으로 굉장히 비효율적인 정렬 방식이란 것을 알 수 있다.
병합 정렬
병합 정렬은 존 폰 노이만이 1945년에 고안한 알고리즘이다. 대부분의 경우 퀵 정렬보다는 느리지만 일정한 실행 속도뿐만 아니라 안정 정렬이라는 점에서 상용 라이브러리에서 많이 쓰이고 있다고 한다. 분할 정복의 진수를 보여주는 알고리즘이라고도 한다.
예를 들어 다음과 같이 정렬하는 알고리즘이다.
[42, 1, 62, 34 7, 65, 14]
> [42, 1, 62, 34], [7, 65, 14]
> [42, 1], [62, 34], [7, 65], [14]
> [42], [1], [62], [34], [7], [65], [14]
> [1, 42], [34, 62], [7, 65], [14]
> [1, 34, 42, 62], [7, 14, 65]
> [1, 7, 14, 34, 42, 62, 65]분할 정복(Divide and Conquer)
말 그대로 통째로 해결할 수 없기 때문에 분할해서 문제를 해결하는 방법이다. 예를 들면 리스트의 크기가 너무 크기 때문에 주어진 리스트 그대로 해결할 수 없는 경우가 있다. 그러한 경우 해당 리스트를 분할하여 문제를 해결하는 방법이다.
퀵 정렬
퀵 정렬은 토니 호어가 1959년 고안한 알고리즘이다. 피벗을 기준으로 좌우를 나누는 특징 때문에 파티션 교환 정렬이라고도 불린다. 즉 피벗을 기준으로 작으면 왼쪽으로, 크면 오른쪽으로 이동하는 방식이다. 앞서 설명한 병합 정렬과 마찬가지로 분할 정복 알고리즘이다. 그러나 퀵 정렬은 병합 정렬과 달리 입력값에 따라 성능 편차가 존재한다. 시간 복잡도로 예를 들면 최악의 경우 O(n^2)에 해당한다. 그러나 평균적으로 O(nlog n)의 시간 복잡도에 해당한다고 한다.
피벗
여기서 피벗은 정렬 대상인 리스트의 데이터 중에서 고른 하나의 요소이다. 이렇게 피벗을 고를 때 항상 맨 오른쪽 요소를 고르는 것을 로무토 파티션이라고 한다.
예를 들면 다음과 같이 정렬하는 알고리즘이다.
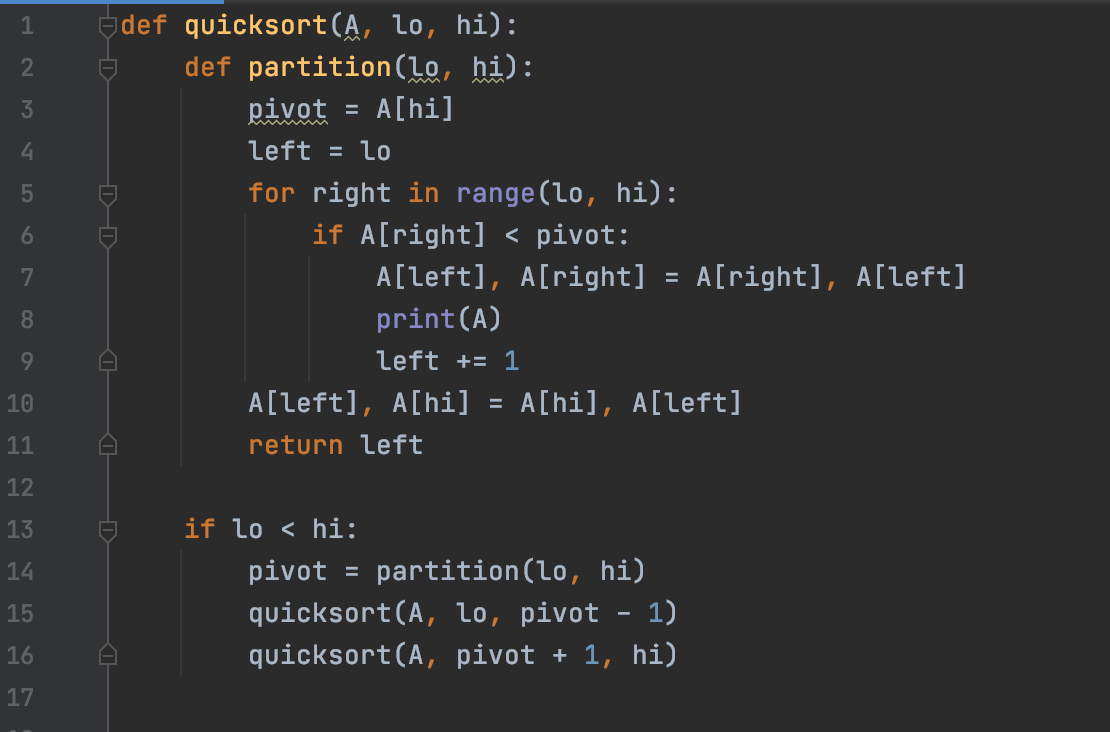
다음이 위 코드의 실행결과이다.
A = [2, 8, 7, 1, 3, 5, 6, 4]
lo = 0, hi = 7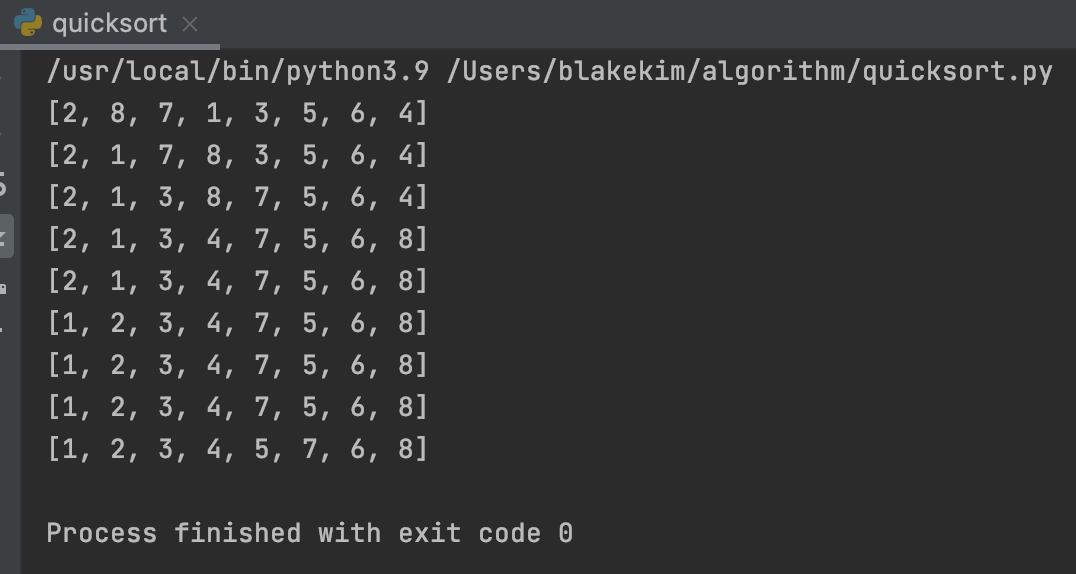
위 결과를 설명하자면 다음과 같다.
left = 0, right = 0
A[left] = 2, A[right] = 2, pivot = 4
A[right] < pivot == true
A[left], A[right] = A[right], A[left]
하지만 left = right 이기 때문에 변화 없음. 첫 번째 print 결과
left += 1 > left = 1
A[left] = 8, A[right] = 8, pivot = 4
A[left] = 8, A[right] = 7, pivot = 4
A[left] = 8, A[right] = 1, pivot = 4
A[right] < pivot == true
A[left], A[right] = A[right], A[left]
1과 8의 위치 변경, 이렇게 pivot 보다 큰 경우 오른쪽으로 이동시킨다.
left += 1 > left = 1이러한 로직의 반복에 의해 정렬된다.
위에서 설명했듯이 최악의 경우 시간 복잡도는 O(n^2)가 될 수 있다. 이미 정렬된 리스트가 입력값으로 주어졌을 경우 피벗은 항상 오른쪽에 위치하게 되고 전체 리스트를 돌게 된다. 항상 일정한 성능을 보이는 병합 정렬과는 달리 입력값에 따라 성능의 편차가 존재한다.
안정 정렬 vs 불안정 정렬
안정 정렬은 앞서 설명한 버블 정렬, 병합 정렬이 해당되고 불안정 정렬은 퀵 정렬이 해당된다. 안정 정렬 알고리즘은 중복된 값을 입력 순서와 동일하게 정렬한다. 예를 들어서 지역과 시간이라는 데이터 두 가지가 존재한다고 가정하였을 때, 시간 순으로 먼저 정렬하고 그 후에 지역별로 정렬하게 될 때 안정 정렬과 불안정 정렬의 차이가 나타난다.
안정 정렬은 시간 순으로 정렬한 순서가 유지된 채로 지역별 정렬이 진행되는 반면 불안정 정렬은 시간 순으로 정렬한 순서는 무시된 채 지역별로 새롭게 정렬된다. 즉 안정 정렬의 경우 시간 > 지역 순으로 정렬할 경우 해당 지역 내에서 시간 순으로 정렬이 되어 있는 반면 불안정 정렬은 시간 > 지역 순으로 정렬했다 할 지라도 지역 순으로만 정렬될 뿐 그 안에 시간 순으로 정렬되어 있지 않다.
추가적으로 공부할 점
- 삽입 정렬
- 팀소트
- 힙 정렬
- 선택 정렬
등등의 여러 정렬 알고리즘을 추가로 공부해야 한다.
