이번 글은 다음 강의을 바탕으로 정리한 글입니다.
Node.js 웹 크롤링 강의를 선택한 이유
데이터사이언스를 전공하고 있는 친구와 스터디를 하게 됐는데, 원래는 알고리즘이랑 python 데이터분석 및 수집(pandas, matplotlib, beautifulSoup)을 공부하다가 책 한 권을 끝냈다! 🙌
참고로 공부한 책은 이 책이다!

그 이후 스터디를 이어나가기 위해 각자 원하는 인터넷 강의를 찾아보던 중, 웹에서 데이터 분석과 관련있는 것이 무엇일까 하면서 해당 강의를 찾게되었다!
python의 selenium에 관심이 생겨 자동화할 수 있는 웹 크롤링을 공부하려다가, 웹 연동성이 높은 스택(node.js)으로 해도 나쁘지 않을 것 같다는 생각이 들어 선택한 이유도 있다.
node,js 웹 크롤링에 대한 강의가 부족해서 과연 경쟁력이 있을까 싶었지만은, 강사가 조현영님(aka. 제로초)이어서 큰 고민없이 선택했다.
블로깅 방향
챕터 별로 발생한 오류를 정리하고,
(우선 해당 강의가 2019년 마지막 업데이트여서 버전 변경 지점도 함께 이야기할 수 있을 것 같다)
웹 크롤링뿐만 아니라 node.js에 대해 새롭게 알게된 것들을 공유할 수 있을 것 같다.
해당 강의의 선수 교재로 마침 이 책이 있어서 함께 찾아서 공부할 예정이다.
(우연의 일치로 이 강의를 선택하기 전에 미리 책을 구매했었다!)
또한 강의 후반의 실무 위주 크롤링을 하면서 도출한 결과를 보고, 웹 사이트와의 연동도 고민할 수 있을 것 같다.
공부한 것
이번 단원에서는 csv파일, xlsx파일 내부의 내용(웹사이트)으로 웹 사이트를 호출하여 필요한 정보를 가져오는 것을 위주로 실습했다.
html 태그로 원하는 정보를 가져오기
한 가지 기억나는 당혹스러웠던 점은, 첫 번째 실습으로 네이버 영화 페이지에 있는 정보를 가져오는 것이었는데, 네이버 영화가 올해 3월을 기점으로 서비스 종료를 하게된 점이다...!
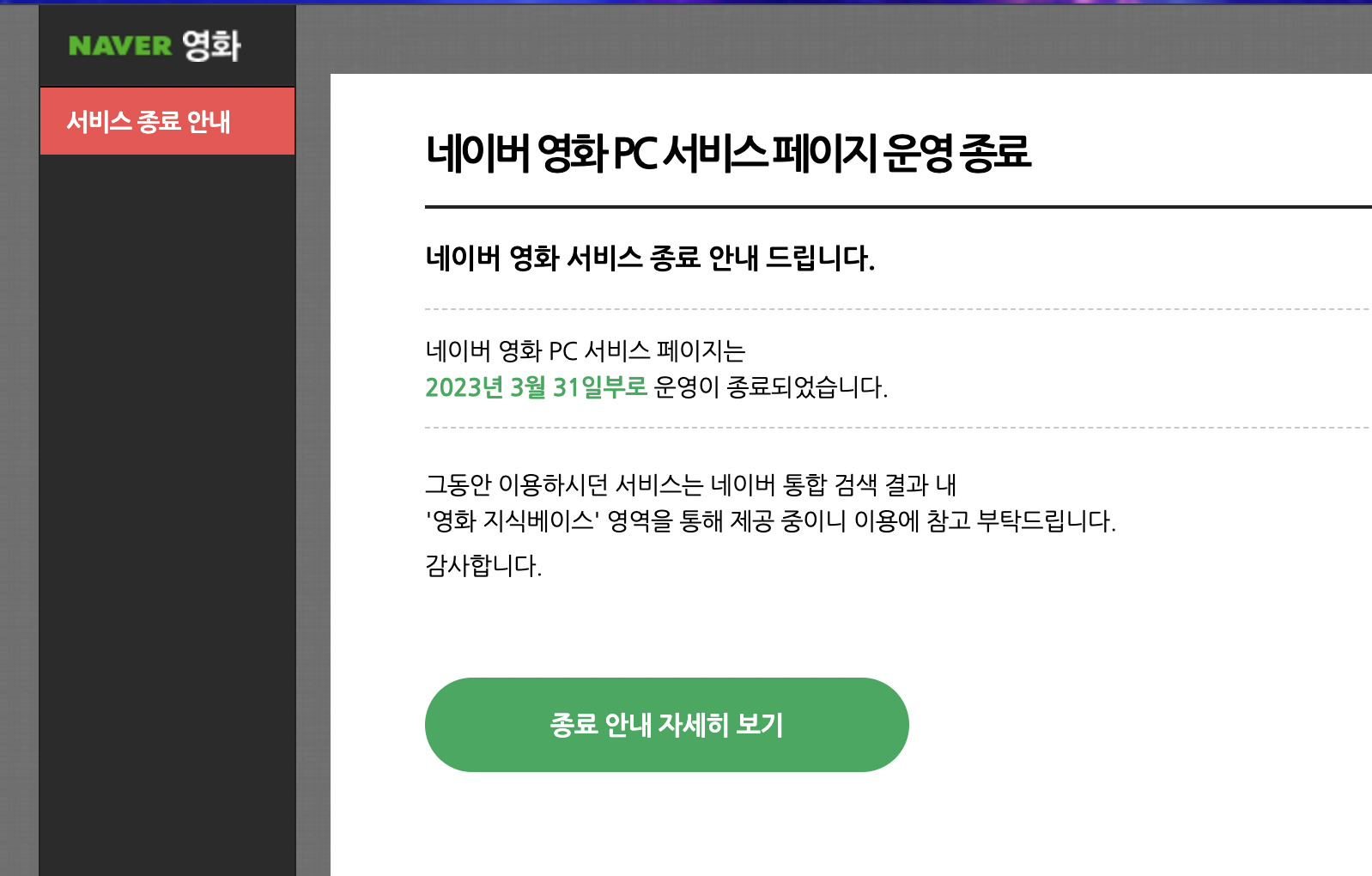
이전에 개인 블로그에 영화 리뷰 썸네일 만들 때, 네이버 영화 애용했었는데... 갑작스럽게 서비스 종료가 된 점이... 아쉬우면서도... 강의가 무용지물이 되는 것일까 싶었다.
하지만 나는 포기하지 않지, 다행히 이전 네이버 영화 링크가 네이버 통합 검색 결과 페이지로 알아서 던져줬고 (예시 링크) 필요한 정보는 유사했기에, 태그 클래스명만 잘 찾아서 변경만 하면 됐다.
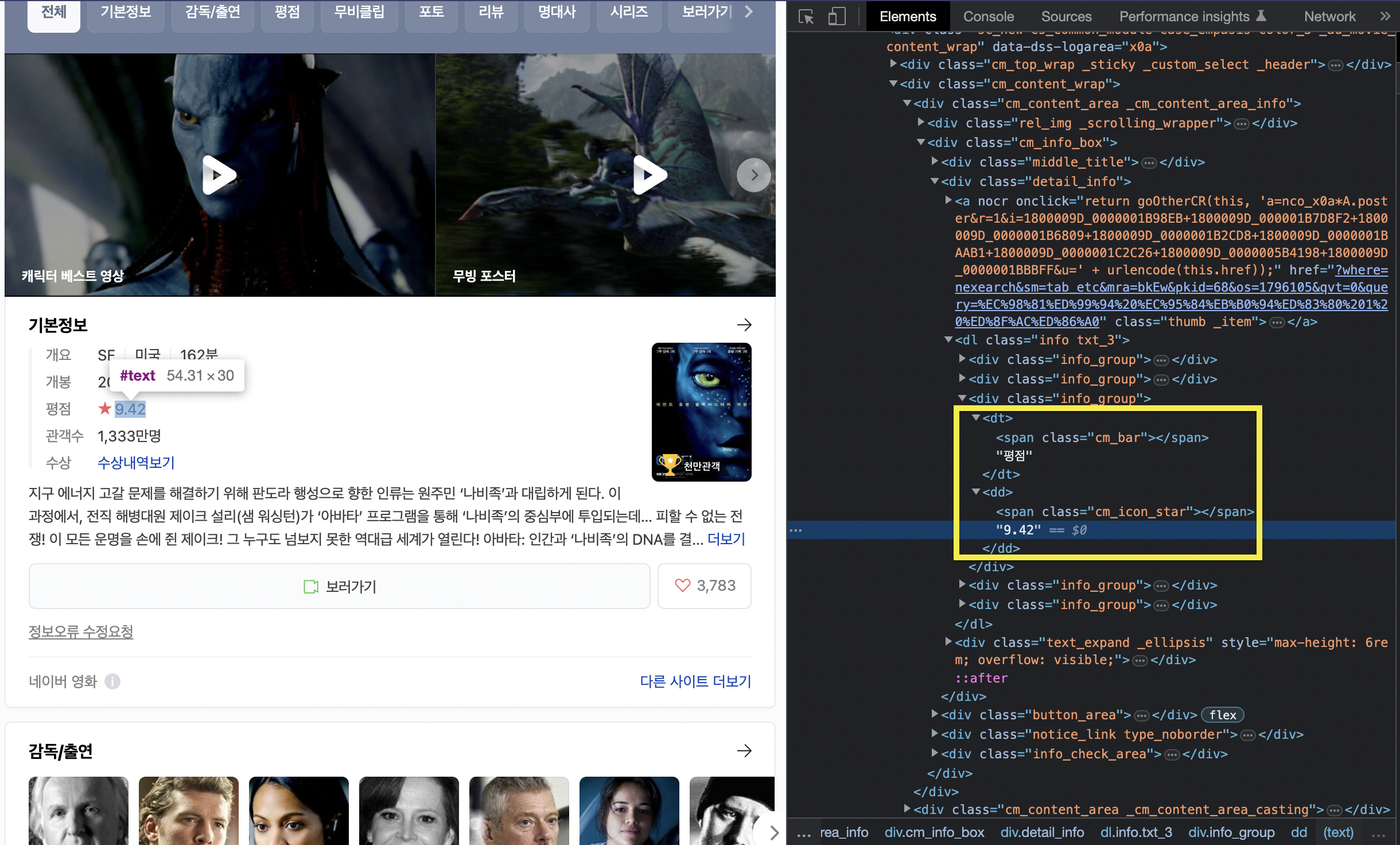
그런데 클래스명이 강의에서는 .score.score_left .star_score 여서 확실하게 가져올 수 있었는데... 통합 검색은 무슨 일인지 너무 불친절하게 되어있었다. 통합 검색이 네이버 영화보다 더 오래 전에 만들어져서 그런가?
그래서 최대한 좁힐 수 있을만큼 클래스명을 잡고 (.info .info_group) 아래 전체 결과를 뽑아냈다.
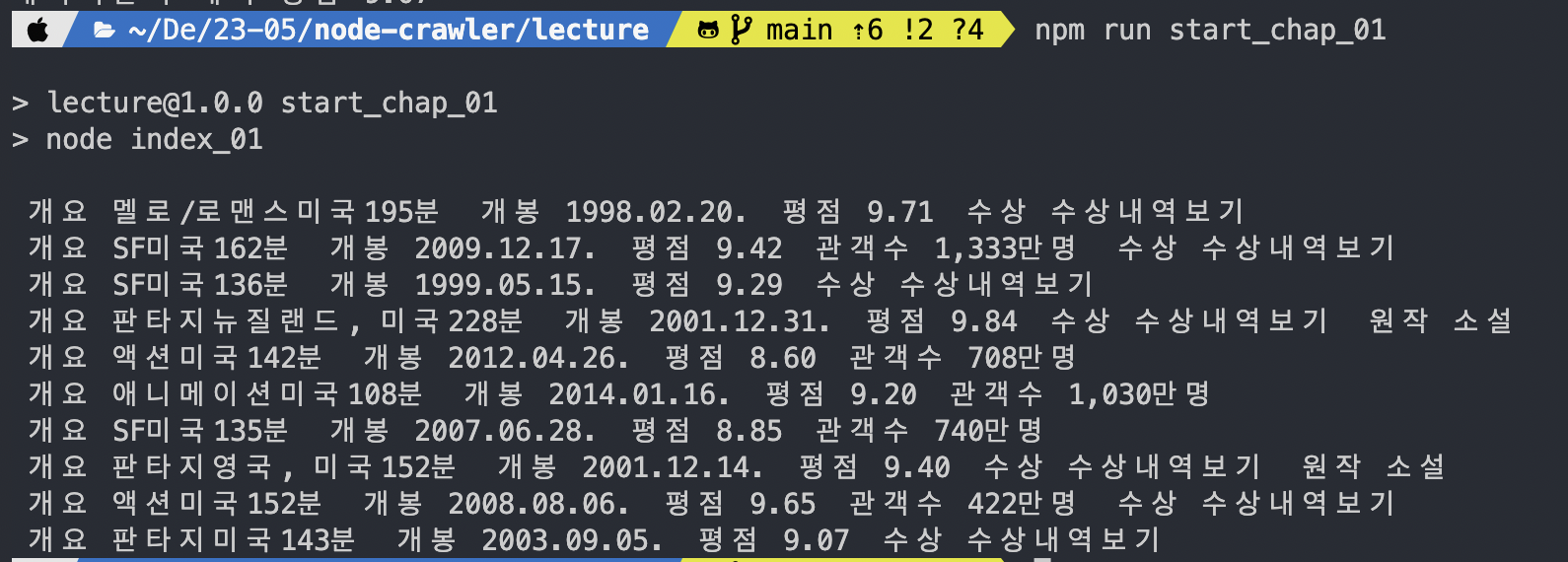
이후 개행문자로 split한 뒤, '평점'으로 한 번 더 split해서 원하는 숫자를 별도로 파싱했다.
이렇게!
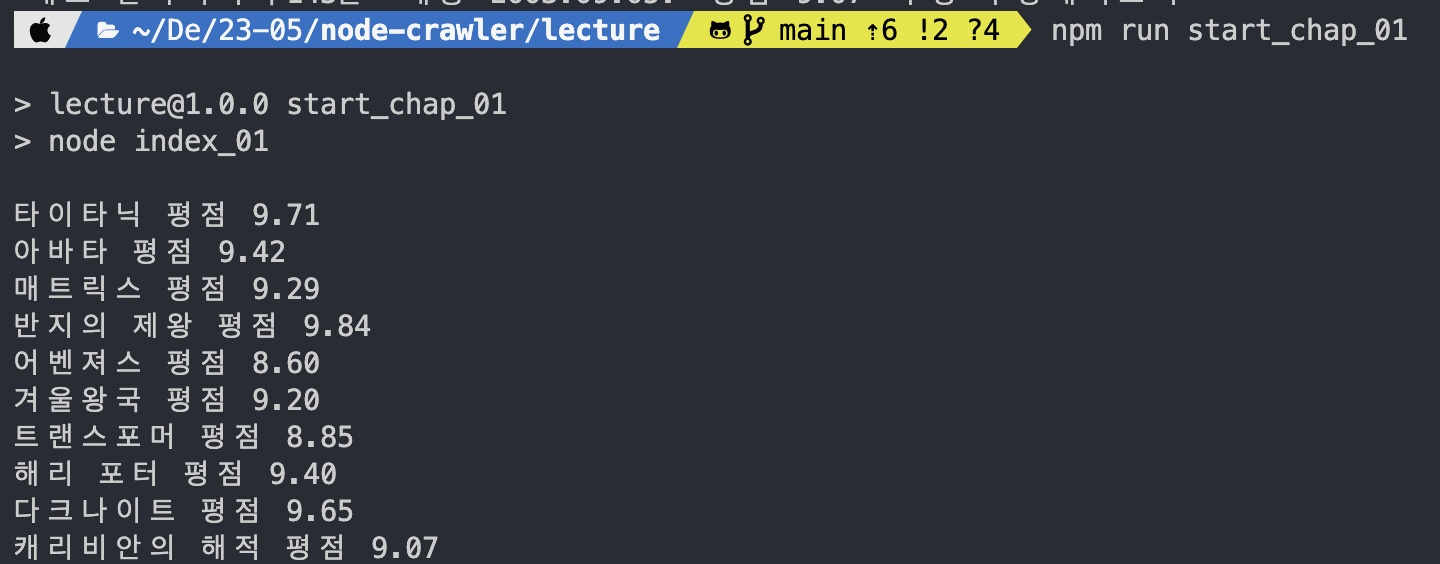
githru 때도 그렇고, 이전 직장에서도 해시태그 기능을 구현하다가 파싱을 종종했어서 이제는 원하는 정보만 쏙쏙 뽑아가는 게 재밌다! 유후!
// crawler 함수 내부
// ...
const infoText = $(".info .info_group").text();
const newCell = "C" + (i + 2);
infoText.split("\n").forEach((text) => {
add_to_sheet(
ws,
newCell,
"n",
parseFloat(text.split("평점")[1].split(" ")[1])
);
});
// ...enter가 안돼!
강의 듣고 공부하는 시간이 100이라고 치면, 그 중 40을 여기에 할애한 것 같다.
문제 상황은 그저 언젠가부터 vscode에서 enter로 줄바꿈이 되지 않는 것.
오로지 command+enter로만 줄바꿈이 되는 것이었다.
이참에 습관을 바꿔야 하나 생각했지만, 커서가 코드 중간에 있는 경우 줄바꿈이 전혀 되지 않아서 해결 방법을 모색했다.
처음에는 vscode update가 잘못 됐나 싶어서 구글링도 해보고, vscode 공식 홈페이지에 들어가서 확인도 해보고, shortcut setting도 확인해봤는데, 딱히 큰 수확은 없었고,

줄바꿈하는 키가 원래 command+enter뿐이었나...?
지금 세상이 날 속이고 있나...?
싶은 생각까지 이르렀다.
그래서 거의 며칠을 불편한 채로 살다가...
이렇게 삶의 질을 떨어뜨릴 순 없다 싶어서
오픈 채팅방에 물어봤고, 이것저것 찾아보다가 extension 문제인 것을 확인하고, 허무하게 해결했다.
두둥탁!
궁금한 것
xlsx로 엑셀 파일 수정하기
import xlsx from "xlsx";
const range_add_cell = (range, cell) => {
let rng = xlsx.utils.decode_range(range);
let c = typeof cell === "string" ? xlsx.utils.decode_cell(cell) : cell;
if (rng.s.r > c.r) rng.s.r = c.r;
if (rng.s.c > c.c) rng.s.c = c.c;
if (rng.e.r < c.r) rng.e.r = c.r;
if (rng.e.c < c.c) rng.e.c = c.c;
return xlsx.utils.encode_range(rng);
};
const add_to_sheet = (sheet, cell, type, raw) => {
sheet["!ref"] = range_add_cell(sheet["!ref"], cell);
sheet[cell] = { t: type, v: raw };
};
export default add_to_sheet;
해당 코드가 어떻게 동작하는지 구체적으로 설명해주진 않았는데,
시간이 남는다면 한 번 이리저리 뜯어보고,
셀을 중간에 하나 추가하거나 삭제하는 함수도 짜볼 수 있지 않을까하는 생각이 들었다.
느낀 것
javascript는 python보다 2차원 배열 형태(csv, xlsx)의 데이터를 다루기 불편하다.
아무래도 python이 numpy, pandas와 같은 프레임워크로 데이터 분석에 특화되어 있어서 느낀 점이긴 하다.
