음식이미지 객체인식을 위한 AI모델 개발 과정 중 했던 고민입니다.
이미지에서 음식을 객체인식 해야겠다고 생각했을 때 가장 먼저 선택했어야 했던 부분이 바로 객체인식 모델을 선택하는 부분이었습니다. 이 때 고민했던 부분을 여러분들에게 공유해드리도록 하겠습니다.
1-stage? 2-stage?
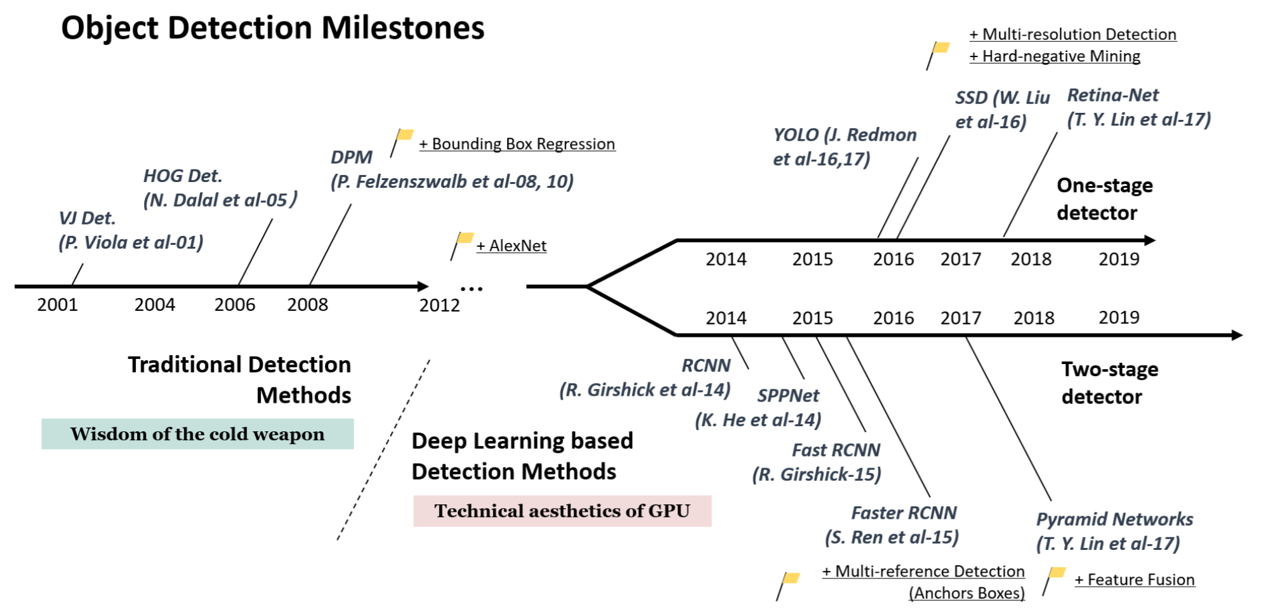
객체인식 모델에 딥러닝이 적용되기 시작하면서 모델은 2종류로 나눠졌습니다. 바로 1-stage detector와 2-stage detector입니다. 이 두 모델들의 차이점은 객체인식을 위해서 어떤 과정을 거치는가 입니다. (DETR, DINO 같은 새로운 분류도 있습니다.)
1-stage detector
1-stage 모델은 객체의 위치와 클래스를 한번의 단계에서 예측합니다. 그리드 방식을 이용하여 다양한 스케일과 위치에서 동시에 객체를 인식합니다.
특징
- 한번의 과정에서 예측을 진행하기 때문에 빠른 속도를 자랑합니다.
- 구현이 비교적 간단합니다.
대표모델
- YOLO(you only look once): 이미지를 그리드로 나눠서 각 역에 대한 바운딩 박스를 예측합니다.
- SSD(single shot multibox detector): CNN 특징 계층 구조를 이용해 다양한 크기의 객체를 효과적으로 예측합니다.
2-stage detector
2-stage 모델은 첫번째 단계에서 객체가 있을만한 영역을 추천받는 region proposal, 두번째 단계는 첫번째 단게에서 추천받은 영역을 세부적으로 분석하여 객체의 위치와 클래스를 예측하는 과정을 통해서 객체를 인식합니다.
특징
- 두번의 과정을 각각 나눠서 진행하다보니 계산 비용이 크고 속도가 느릴 수 있습니다.
- 좀 더 세부적인 예측을 진행하여 1-stage 모델보다 정확도가 높을 수 있습니다.
대표모델
- R-CNN(Region-based CNN): 선택적 검색 알고리즘을 통해 영역 제안을 받고 해당 부분에 CNN을 적용하여 특징 벡터를 추출합니다.
- Faster R-CNN: 전체 이미지를 한번에 CNN에 입력받고 Rol pooling을 사용하여 특징을 추출합니다.
고민해볼 부분
음식 이미지를 추출할 때는 정확도와 속도 중에서 어떤걸 선택할지가 고민이 많았습니다. 아무래도 어플리케이션이다보니 UX를 위해서는 빠른 결과가 나와야했고 2번 촬영하는 일이 없도록 정확성또한 어느정도는 충족해줘야했습니다. 그래서 둘 다 트레이닝과 테스트를 해보기로 했습니다.

언제나 탐구하는 개발자입니다.