이진 트리
각각의 노드가 최대 두 개의 자식 노드를 가지는 트리 자료구조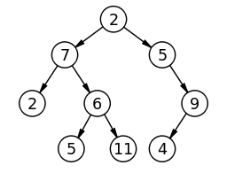
이진 트리의 종류
- 정이진트리
트리의 모든 mode가 0개 혹은 2개의 자식을 가지는 경우- 포화이진트리
leaf node가 끝까지 정말 꽉 찬 트리- 완전이진트리
마지막 레벨을 제외한 모든 레벨에서 순서대로 node가 꽉 채워진 트리- 균형이진트리
leaf node들의 레벨 차이가 최대 1레벨까지만 나는 트리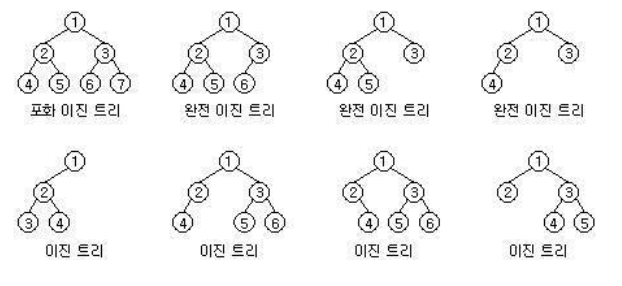
B-Tree
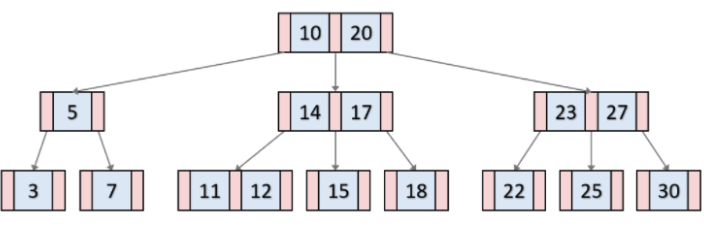
균형이진 탐색트리의 일종
이진 트리와는 다르게 하나의 노드에 많은 정보를 가질 수 있음이렇게 하나의 노드에 여러 정보를 담게 되면서 차수하는 개념이 등장
하나의 노드에 여러 자료를 배치하게 되면서 이진 트리보다 훨씬 많은 데이터를 더 효율적으로 저장소에 담을 수 있음
특징
- 각 노드의 자료는 정렬되어 있음
- 자료는 중복되지 않음
- 모든 leaf node는 같은 레벨에 있음
- root node는 자신이 leaf node가 되지 않는 이상 적어도 2개 이상의 자식을 가짐
- root node가 아닌 노드들은 적어도 M/2개의 자식 노드를 가지고 있음(최대 M개)
B*Tree
노드의 추가적인 생성과 추가적인 연산의 최소화를 위해 B-Tree에서 몇가지 규칙이 추가구조를 유지하기 위해 추가적인 연산이 수행 되거나 새로운 노드가 생성되는 B-Tree 단점을 개선하기 위해 등장
특징
- 각 노드의 자료는 정렬되어 있음
- 자료는 중복되지 않음
- 모든 leaf node는 같은 레벨에 있음
- root node는 자신이 leaf node가 되지 않는 이상 적어도 2개 이상의 자식 노드를 가짐
- root node가 아닌 노드들은 적어도 2 * [(M - 2) / 3 ] + 1개의 자식 노드를 가지고 있음(최대 M개)
B-Tree와 B*Tree의 차이점
- 최소 M/2개의 키 값을 가져야 했던 기존 노드의 자식 노드 수 최소 제약조건이 2M/3개로 늘어남
- 노드가 가득차면 분열 대신 이웃한 형제 노드로 재배치
B+Tree
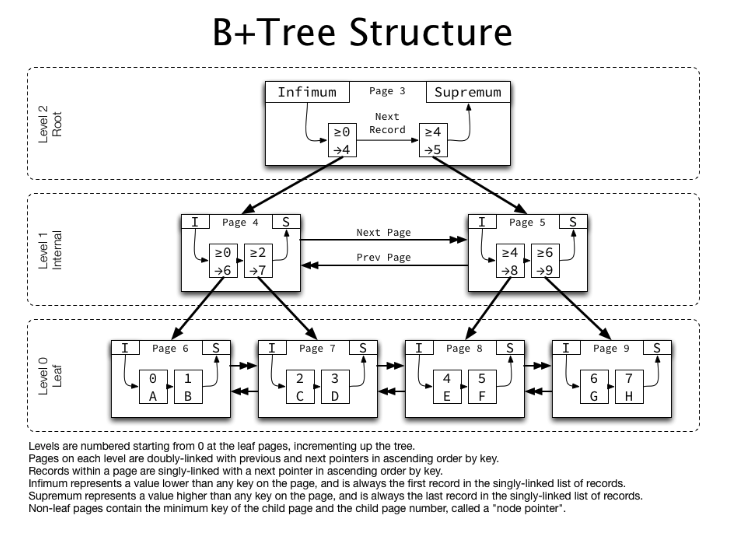
같은 레벨의 모든 키 값들이 정렬되어있고,
같은 레벨의 Sibling node는 연결 리스트 형태로 이어져 있음노드를 찾아 이동해야 한다는 단점을 가진 B-Tree의 단점을 개선하기 위해 등장
만약 특정 값을 찾아야 하는 상황이 된다면 leaf node에 모든 자료들이 존재하고, 그 자료들이 연결리스트로 연결되어 있으므로 탐색에 있어 매우 유리
leaf node가 아닌 자료는 인덱스 노드라고 부르고, leaf node 자료는 데이터 노드라고 부릅니다.
- 인덱스 노드의 Value 값에는 다음 노드를 가리킬 수 있는 포인터 주소 존재
- 데이터 노드의 Value 값에 데이터가 존재
특징
- 키값은 중복될 수 있음
인덱스 노드와 데이터 노드에서 동시에 등장 가능- 데이터 검색을 위해서는 반드시 leaf node까지 내려가야 함
- 데이터 노드의 자료는 정렬되어 있음
- 데이터 노드에서는 데이터가 중복되지 않음
- 모든 leaf node는 같은 레벨에 있음
- leaf node가 아닌 node의 키 값의 수는 그 노드의 서브트리 수보다 하나가 적음
- 모든 leaf node는 연결리스트로 연결
오늘 날 데이터베이스에서 가장 중요한 것은 검색속도이기 때문에 대부분의 데이터베이스 시스템은 B+Tree구조를 채택
참고한 블로그 링크

끝없이 탐구하는 iOS 개발자 유재우입니다!