1. 워드 임베딩(word embedding)
: 단어 간의 관계를 학습해 vector에 저장하는 기법
- 대표적 모델
Google에서 나온 word2vec
Stanford에서 나온 GloVe
둘다 차원을 최대한 낮추고, 더 적은 숫자들로 하나의 단어에 정보를 담는 것이 목표!
2. Word2Vec
: 단어들의 임베딩 값을 구해서 단어들 간의 유사성 파악
-> 유사성 있는 단어를 예측
(문장 생성은 X -> 다른 모델 필요!)
예시) 원수는 외나무다리에서 만난다
'원수', '외나무다리' : 비슷한 단어는 아니지만 위의 문장에서는 어느정도 유사성(관계성)이 있는 단어
Word2Vec은 워드임베딩 '모델'이다.
-
아래의 예시들은 word2vec의 학습과정을 나타내기 위한 것.
(예시 문장이 하나라고 가정했을때 word2vec의 학습과정)
실제로는 엄청난 양의 데이터를 아래와 같은 과정으로 학습된 것이 word2vec 모델인 것이다.
(대량의 문장으로 이루어진 문서를 전처리하여 토큰화 한 후 모든 단어에 대한 학습) -
python의 gensim 라이브러리를 통해 사전에 학습된 모델인 word2vec을 바로 데이터에 적용 가능함(학습된 데이터에 한해서 단어에 대한 임베딩 벡터값 바로 출력 가능)
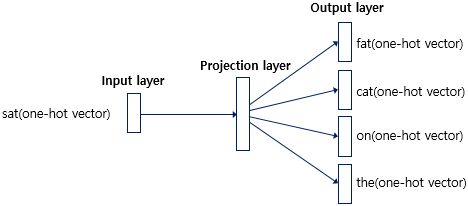
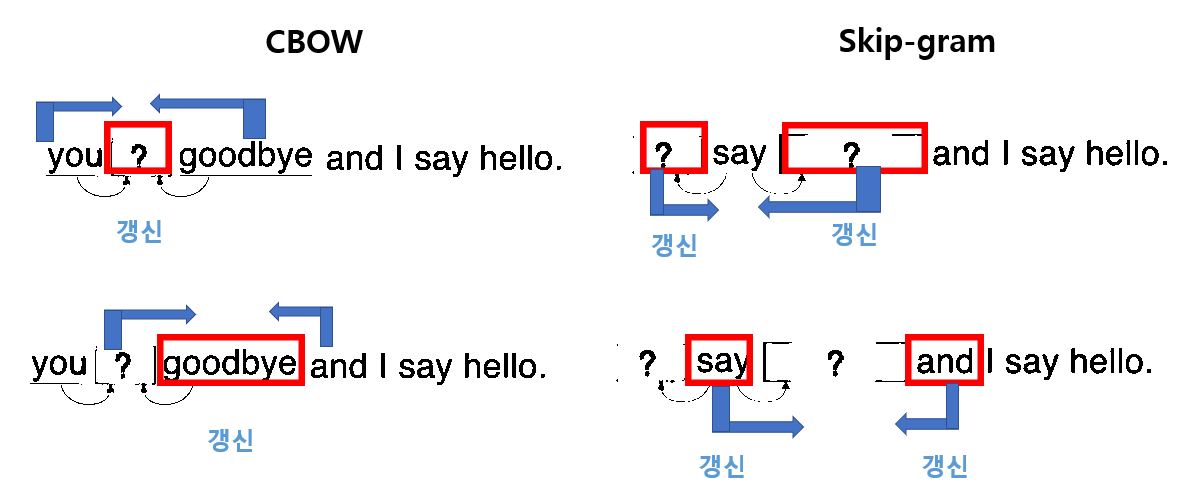
CBOW : 주변단어로 중심단어 예측
Skip-gram : 중심단어로 주변단어 예측
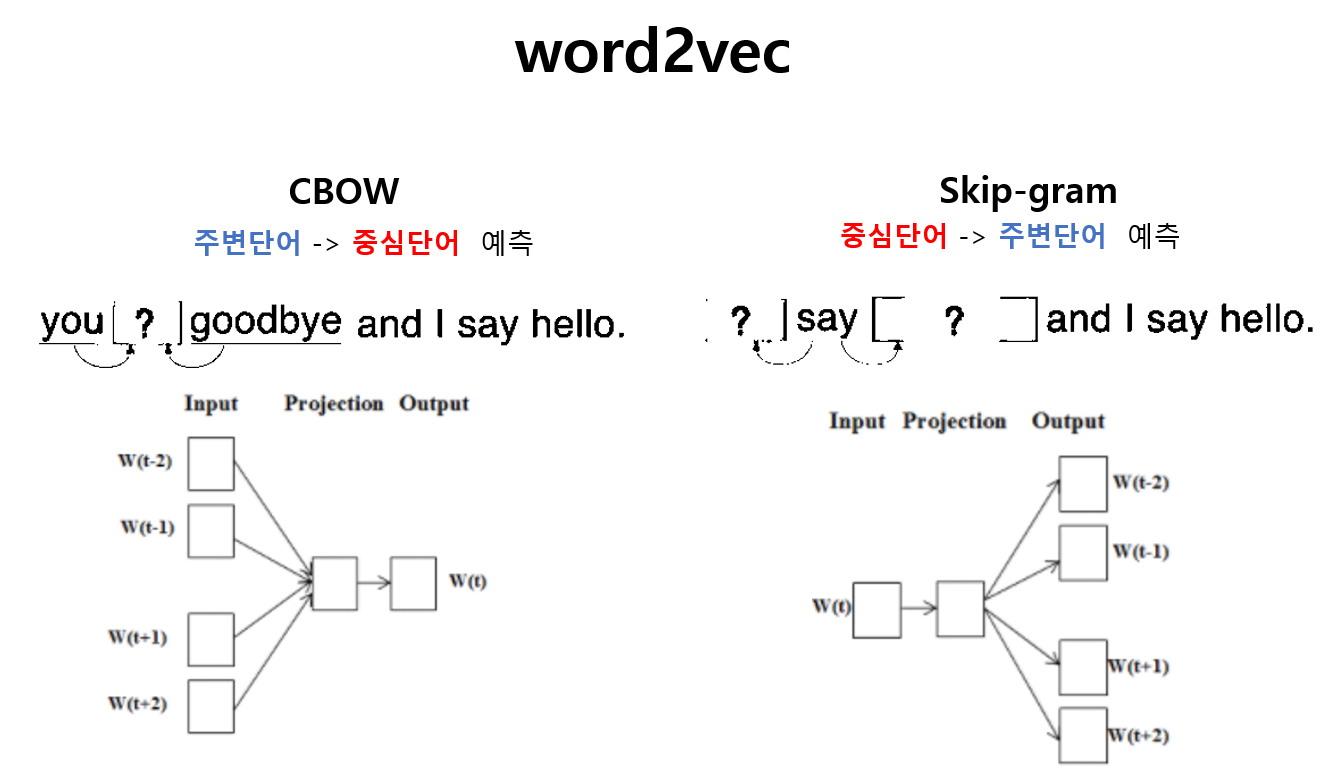
👓 CBOW
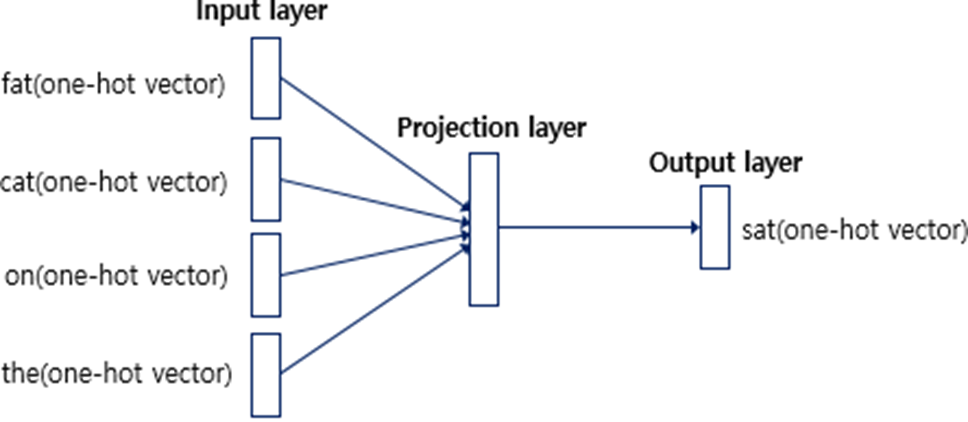
Input : 주변단어(원-핫벡터)
Output : 중심단어(원-핫벡터)
목적 : 가중치 행렬 W의 학습을 통한 임베딩 벡터(W) 구하기
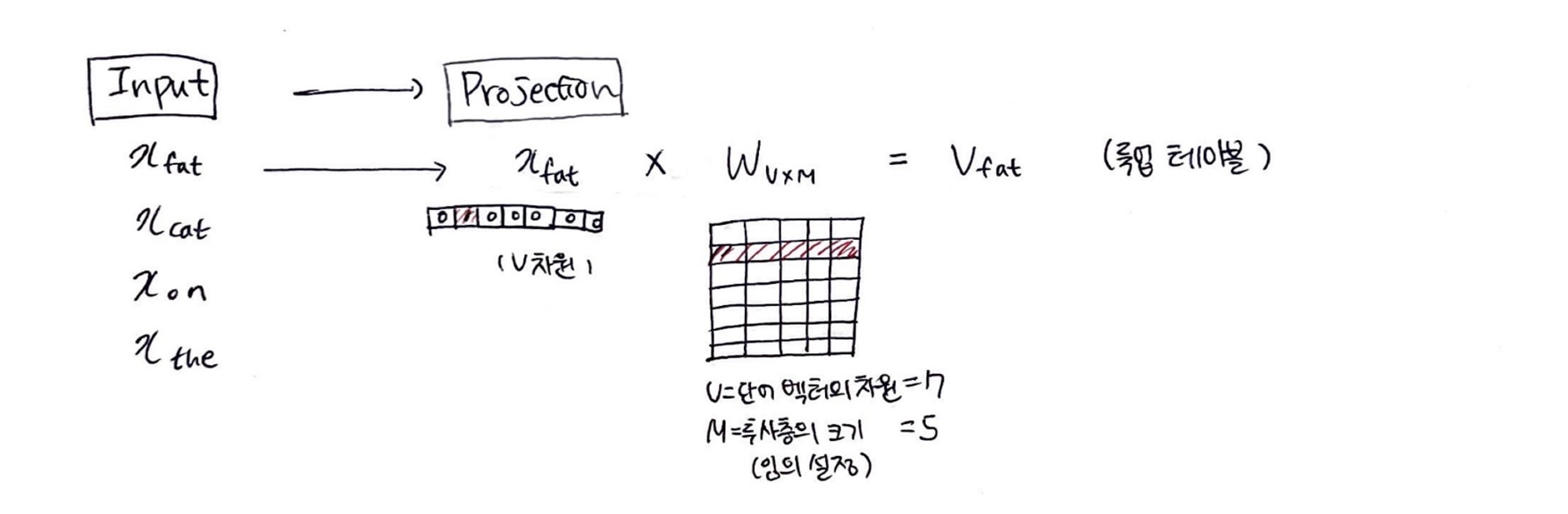
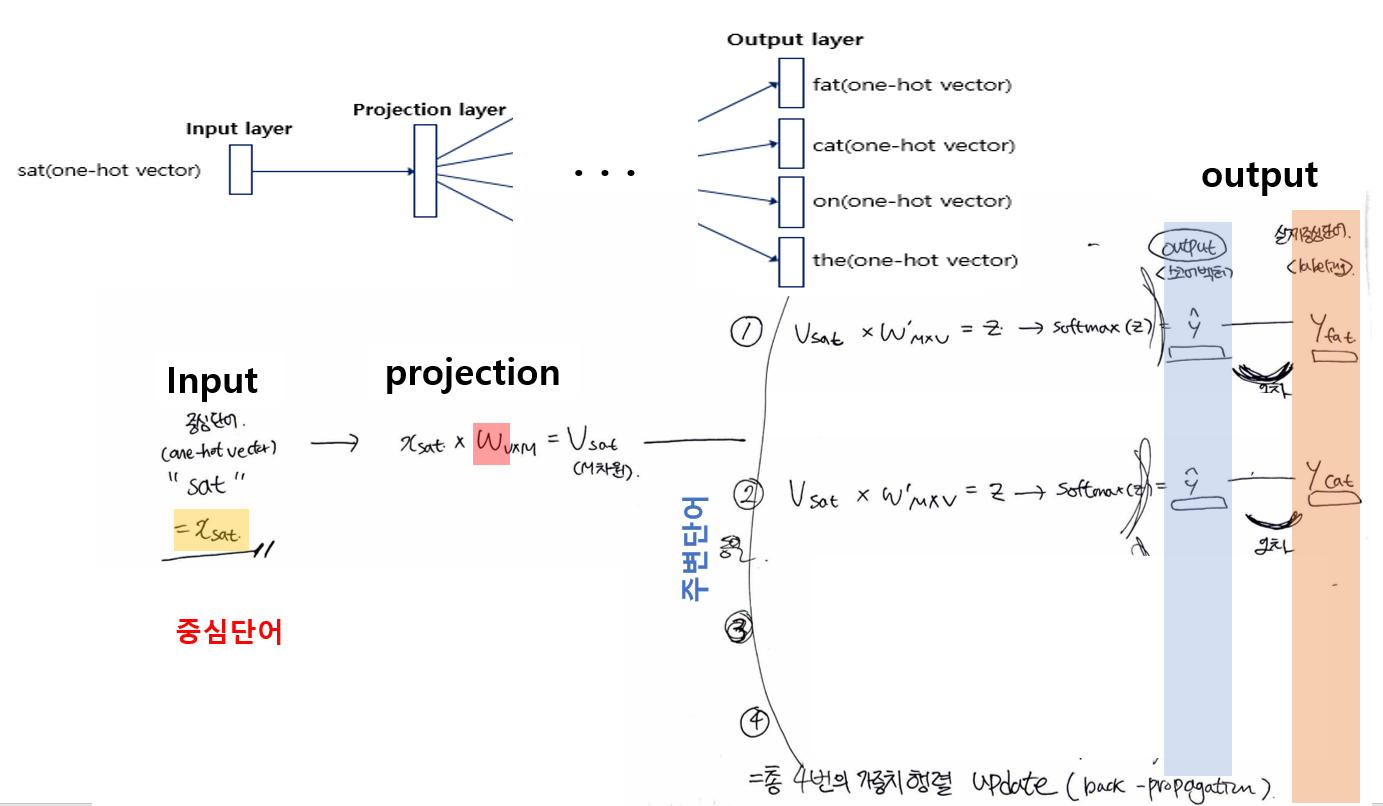
1. 모든 단어에 대해 one-hot encoding 벡터화
x_k = [0,0,0,1,0...]
------Input layer----------------------------------------------------------
2. 하나의 center에 대해 2m개의 단어벡터를 Input으로 가짐
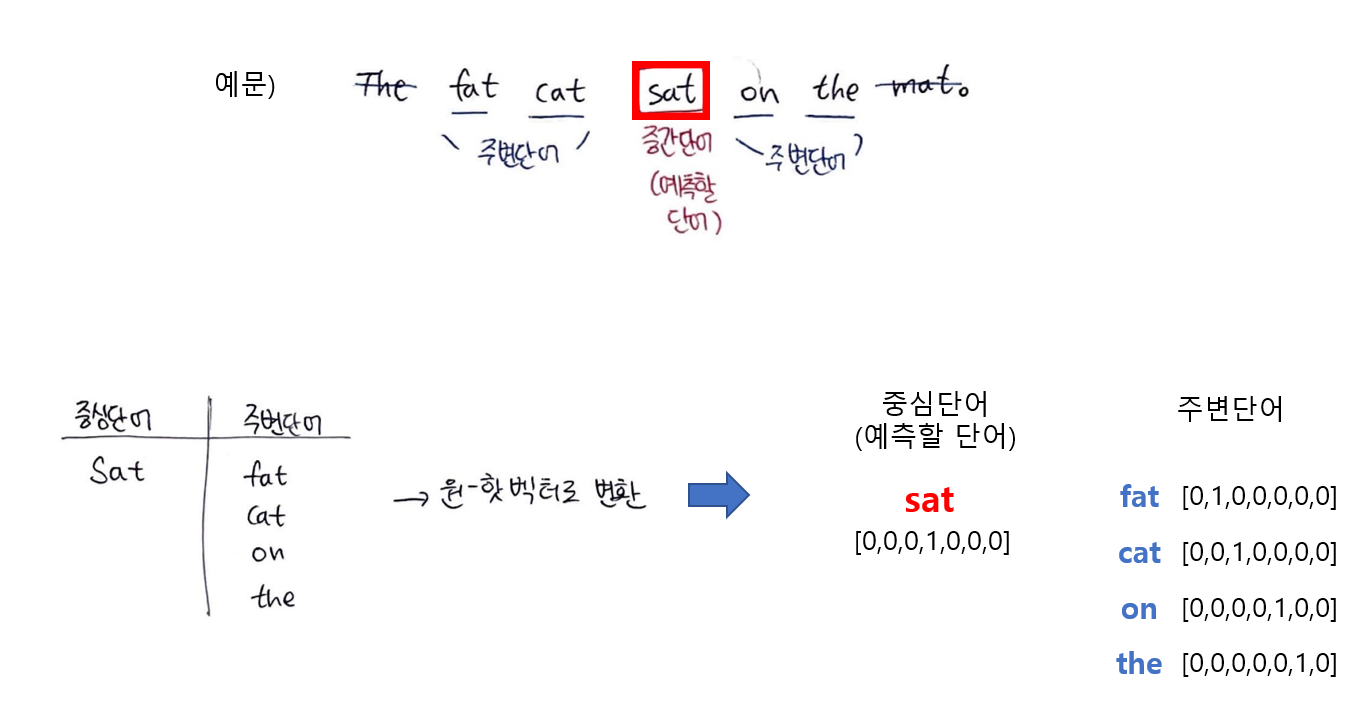
------Projection layer----------------------------------------------------------
3. CBOW의 파라미터
Input->projection = W (VXM)
projection-> output = W' (MXV)
(V=단어 집합의 크기, M=projection의 크기
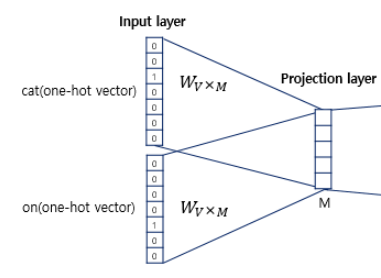
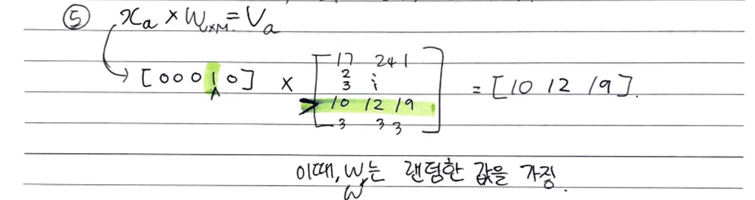
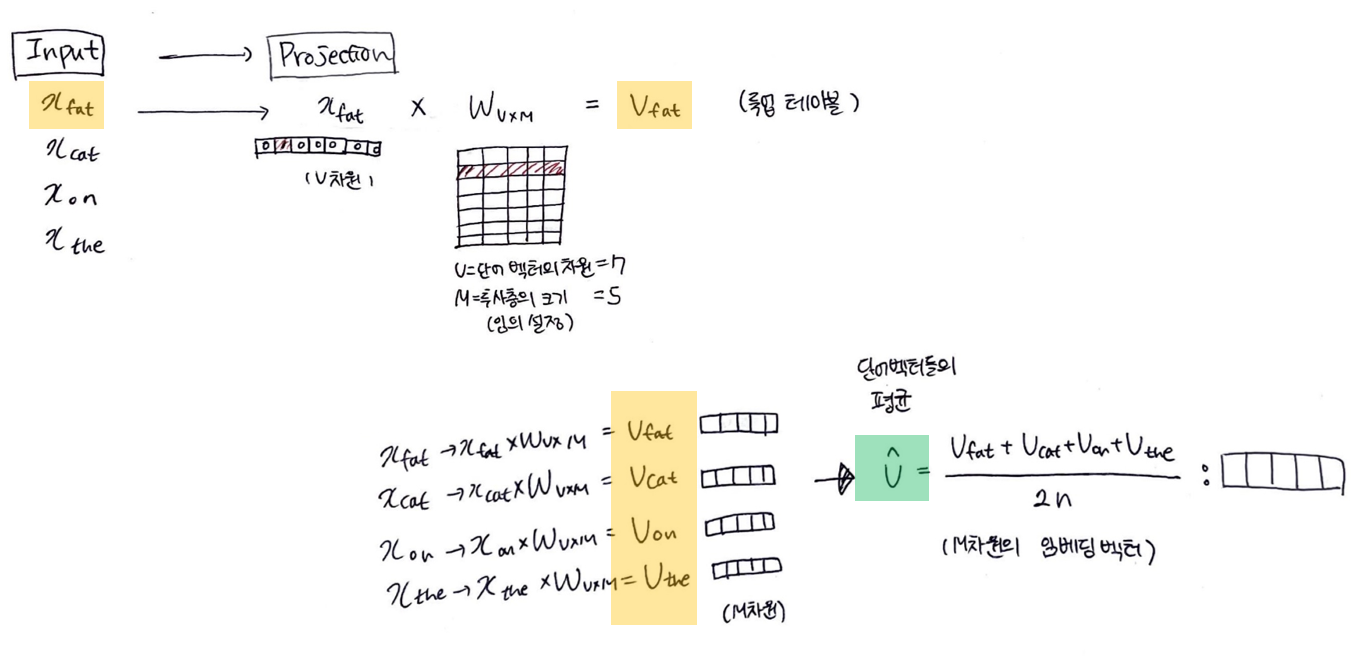
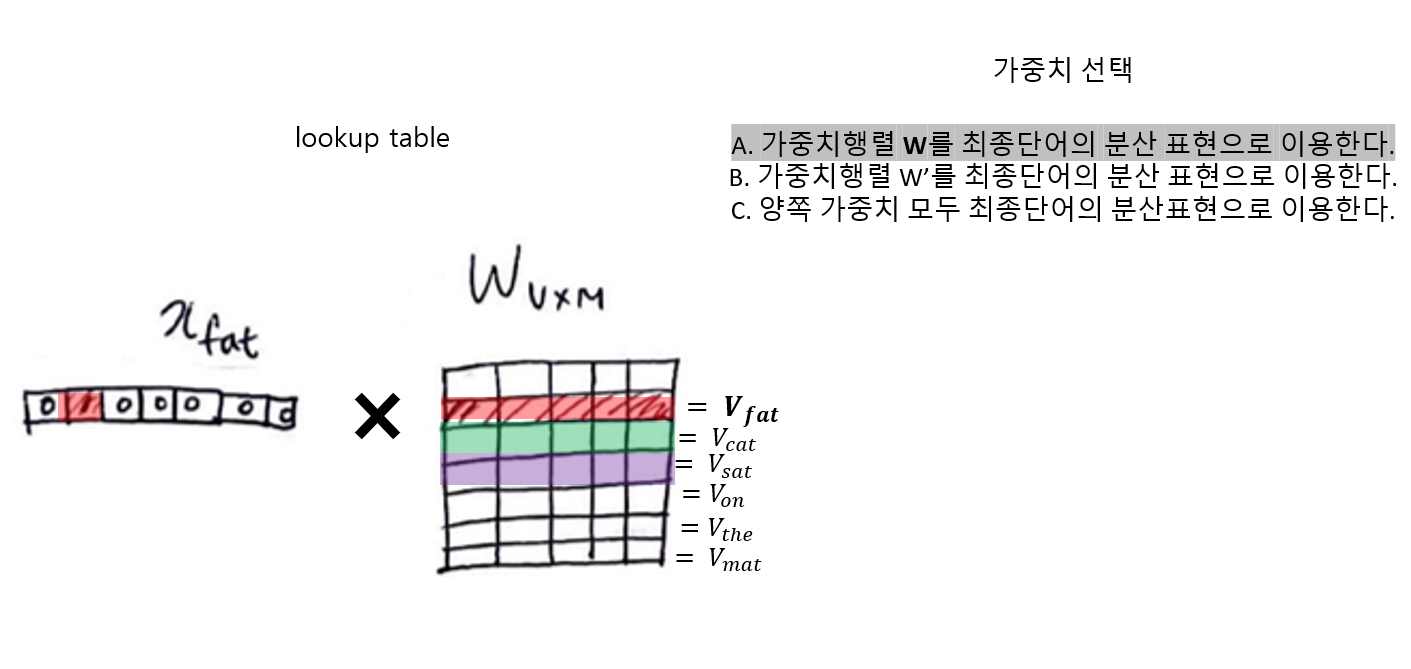
4. 가중치 W 룩업테이블 -> 단어벡터 V로 전환
단어: x_fat (V차원) -> 단어벡터: V_fat (M차원)
5. 단어벡터들의 평균벡터(V^) 구하기
-> 주변단어들이 projection layer에서 만나, 이 벡터들의 평균 벡터를 구함
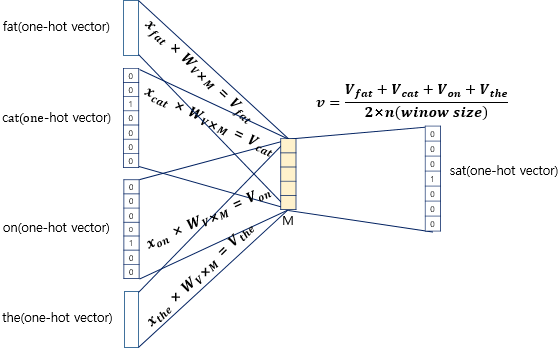
(skip-gram은 벡터의 평균을 구하지 않는다.)
6. 평균벡터(V^)에 가중치행렬' 곱하기
평균벡터(M차원) x W'(MxV차원) = Z(V차원 = 원-핫 벡터와 차원 동일)
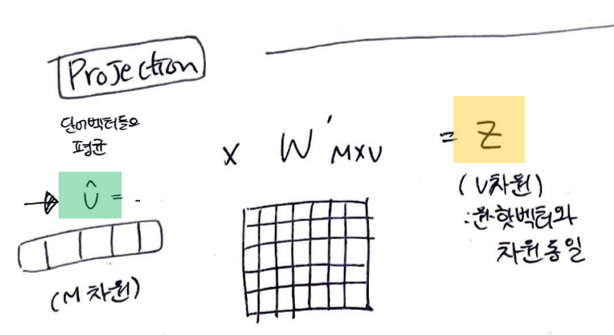
- Z -> 스코어 벡터
------Output layer----------------------------------------------------------
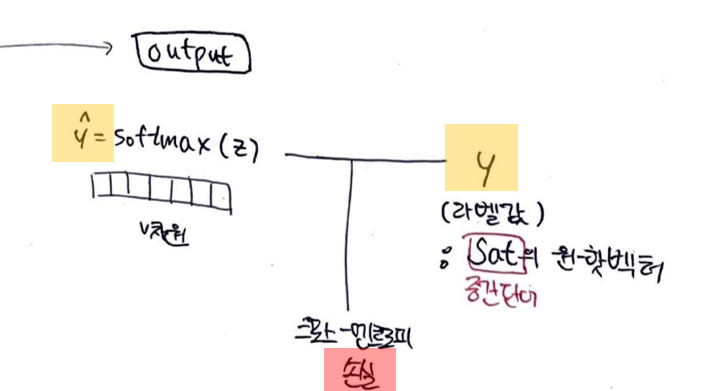
7. softmax 함수
소프트 맥스 함수를 지나면서 벡터의 원소들의 값은 0~1사이의 실수가 된다.

8. cross-entropy 손실함수
두 벡터값의 오차를 줄이기 위해 CBOW는 손실함수로 cross-entropy를 사용한다.
cross-entropy 함수에 중심단어(정답)의 원-핫 벡터와 스코어 벡터를 입력값으로 넣는다.
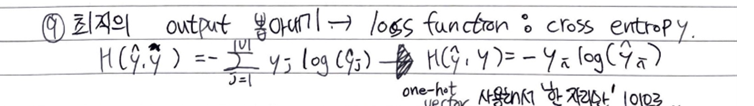
9.

10. 역전파 수행
역전파를 수행하면 W와 W'가 계속해서 학습된다.
🎃 가중치 행렬 W와 W에 대하여
가중치 행렬 W
( V × M 행렬 )
가중치 행렬 W'
( M x V 행렬 )
- w' 차원은 w의 차원을 전치한 것과 같다.(차원만!!)
하지만 완전히 동일한 행렬은 아니다.(내용 자체도 전치된 것은 아님)
(때에 따라서 두개를 하나의 행렬로 취급해서 학습할 수도 있다.)
- Word2Vec은 중심단어를 맞추기 위해 W와 W’를 조금씩 업데이트 하며 학습하는 것
W는 가중치 행렬이자 word2vec의 최종 결과물인 임베딩 단어벡터의 모음이다.
🍙 가중치 선택하기
- W은 각 단어의 결괏값으로 나오는 가중치들의 집합이다.
- 가중치는 A, B, C 의 조건에 따라 선택할 수 있으나, 보통 A의 방법인 W를 가중치로 사용하는 방법을 사용한다.
💥 즉, W 두번곱하는 이유는
모델이 단어의 의미적 유사성과 문맥 관계를 동시에 학습할 수 있도록 도와주는 것!!!!!!!!!
<첫 번째 가중치와의 곱셈>
단어 간의 의미적 유사성을 고려한 단어 임베딩이 형성
<두 번째 가중치와의 곱셈>
잠재 벡터로부터 context word를 예측
❓ 평균벡터에 두번째 가중치를 곱하는 것으로 어떻게 문맥과의 관련성을 파악할 수 있어?
이 평균 벡터는 문맥에 포함된 단어들의 의미적 특성을 요약한 형태이기 때문에 문맥 정보를 담고 있기 때문!
W와 W' 모두 projection layer에서 이루어짐!!!!!!
projection layer의 출력은 첫 번째 가중치와의 행렬 곱셈 결과인 잠재 벡터(latent vector)입니다. 이 잠재 벡터는 단어를 저차원의 실수 벡터로 표현한 것으로, 단어 간의 의미적 유사성을 포착하는 역할을 합니다.
그 후, 잠재 벡터에 두 번째 가중치 행렬을 곱하여 출력 벡터를 얻습니다. 이 출력 벡터는 중심 단어와 관련된 문맥 단어를 예측하는 데 사용되는 값입니다. 이 때, 두 번째 가중치 행렬은 projection layer의 출력 벡터로부터 context word를 예측하기 위해 사용됩니다.
🚍 Skip-gram
🍔 Input에는 중심단어 1개

🍔 전체적인 과정은 CBOW와 동일함
- 중심단어로 주변단어를 예측하므로 projection layer에서 벡터들의 평균을 구하는 과정이 없다.
- 두번째 가중치( W'_output)를 구하는 과정에서
V_sat에 대하여 주변 단어들의 가중치를 '각각' 구하는 과정을 거쳐준다.(위의 경우에는 총 4개)
V_sat x W' ----비교---- y_fat
V_sat x W' ----비교---- y_cat
V_sat x W' ----비교---- y_on
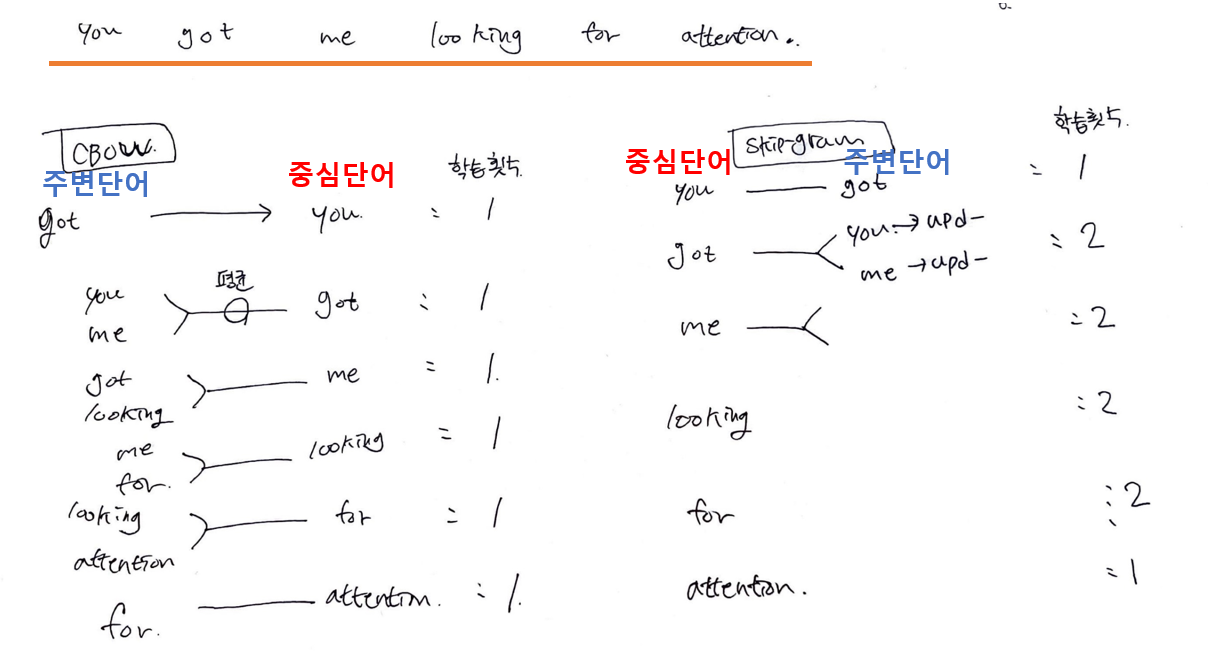
🚲 Skip-gram이 CBOW에 비해 더 높은 성능을 보인다.
CBOW : 중심단어(벡터)는 단 1번의 업데이트 기회를 가진다.
학습 마지막에 한번씩만 업데이트됨
Skip-gram : 중심단어의 업데이트 기회를 여러번 확보할 수 있다.
skip-gram은 슬라이딩 하면서 계속해서 중신단어와 주변단어 간의 관계를 파악
즉, Skip-gram이 훨씬 더 많은 학습량을 가진다.
🚦 NNLM vs Word2Vec
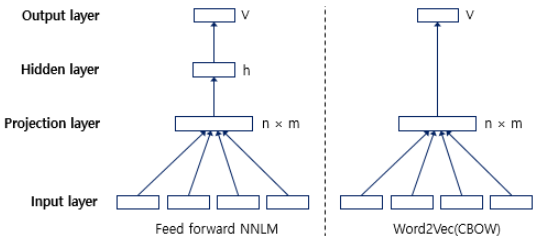
👉 NNLM(피드 포워드 신경망 언어 모델)의 느린 학습 속도와 정확도를 개선한 것이 Word2Vec
1) 예측하는 대상이 다르다
NNLM은 다음 단어를 예측
Word2vec은 중심 단어를 예측(워드 임베딩 자체가 목적)2) 구조도가 달라졌다
Word2vec은 NNLM에 존재하던 은닉층을 제거하였다3) Word2vec은 몇몇 기법들을 추가하였다.
- 계층적 소프트맥스(hierarchical softmax)
- 네거티브 샘플링(negative sampling)
