
생성형 언어모델 성능 평가하기
- 정성적 평가
: 사람이 직접 번역된 문장을 채점하는 주관적 평가 - 정량적 평가
: 수치를 이용한 객관적인 평가
- BLEU score : 주로 기계 번역에 사용
- ROUGE : 텍스트 요약에 사용
- PPL(Perplexity) : 대부분의 언어모델 성능 평가에 사용
◆ BLEU score 란?
(bilingual evaluation understudy)
: 기계 번역 결과와 사람이 직접 번역한 결과가 얼마나 유사한지 비교하여, 번역에 대한 성능을 측정하는 방법

만약 한글 문장으로 번역했을 때,
generated sentence(번역된 문장, 모델의 출력값)과
reference sentence(참조 문장, 정답(후보) 문장)과의
유사성을 점수로 나타낸 것이 BLEU score이다.
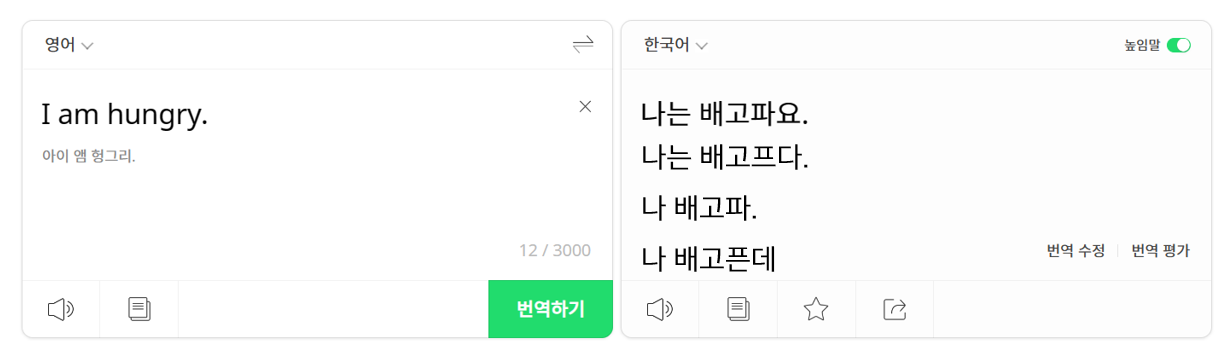 위의 예시에서 보듯이, 어떠한 문장을 번역했을 때 후보로 나올 수 있는 문장은 정말 많다. 그래서 이
위의 예시에서 보듯이, 어떠한 문장을 번역했을 때 후보로 나올 수 있는 문장은 정말 많다. 그래서 이 reference sentence은 generated sentence와 다르게 여러 개를 정답 문장으로 사용할 수 있다.
즉, 한 개의 generated sentence에 대하여
여러 개의 reference sentence을 가질 수 있다.
(reference sentence에는 여러 후보가 있을 수 있기 때문에, 정답 문장이라 명확히 정의하기는 어렵다.)
◆ BLEU score 계산과정
BLEU Score 계산과정은 크게 4가지로 나눌 수 있다.

0. 단어 개수를 count하기

- 단순히
generated sentence에reference sentence의 단어가 있는지 여부만 판단하여 그 개수를 count 해준다.

그러나 여기서 2가지 문제가 발생한다.
> 해당 방법의 문제점

1)번 같은 경우는 너무나 자명한 이야기이다. 단어 사이의 관게를 정의할 수가 없다.
2)번 같은 경우는 극단적인 예시로, generated sentence에 동일한 단어가 나오게되면 확률이 1로 예측 문장이 100% 정답이 되는 말도 안되는 상황이 발생한다.
따라서, 이러한 문제점을 개선하기 위해 여러가지 방법을 적용한다.
1. 단어 개수를 count하기
먼저, 문제 1) 단어의 순서를 고려하지 않음을 개선하기 위한 방법이다.


위의 예시를 바탕으로 다음과 같이 n-gram에 대한 확률을 기하평균(모두 곱해준 값을, 그 값의 개수에 해당하는 제곱근으로 나누는 것) 해준다.
- n-gram에서 n은 보통 1~4까지의 값을 갖는다.
- (gram : 단어, 말뭉치 느낌)
⭐ 4-gram이 성능이 더 뛰어날텐데 이것만 사용하면 안되는가?
당연히 4-gram 성능이 뛰어날거다.
이에 각 gram별 가중치를 다르게 설정할 수 있다.
모든 가중치의 합은 1이다.
가장 기본적으로 0.25씩 줄 수 있다. 만일, 4-gram에 높은 가중치를 부여하고 싶으면, 이 값을 조정해주면 된다.
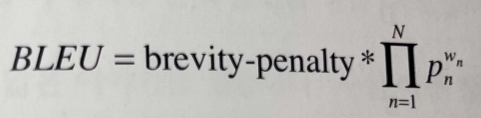 >> 가장 우측의 W_n이 가중치에 해당한다.
>> 가장 우측의 W_n이 가중치에 해당한다.
2. 중복단어로 인한 과적합 보정
- 같은 단어가 연속적으로 나올 때 과적합되는 현상 보정
- Clipping
문제 2) 같은 단어가 연속적으로 나올 때의 문제를 개선하기 위한 방법이다.

- 다음과 같이 기존에
generated sentence의 단어를 count 하던 것을,reference sentence의 단어들로 count 해준다. - 모든 n-gram에 해당 과정을 적용해 과적합을 방지한다.
이 문장 맞는지 다시한번 확인!!!!!!!!!!!!!!!!!!!!!!!!!!
이로써 약한 유사설을 보이는 번역문장임에도 5/9로 과적합 되던 확률이,
3/9로 하향 조정되는 것을 확인 할 수 있다.
3. 문장길이에 대한 보정(BP)
- Brevity Penalty (BP)

- 1~2까지의 n-gram을 계산한 값에 해당 값
BP를 곱해준다. BP는1과예측단어/전체단어중 더 작은 값을 선택하도록 한다.
4. 종합 BLEU score 계산
- 전체 테스트 데이터셋을 하나의 큰 문장으로 취급하고 계산한다.
1) n-gram 일치도 계산
2) 1)을 기하 평균하여 종합 점수를 도출
3) BP 적용
4) BLEU score이 0~1사이의 값으로 나타남(or 백분율 표시)
참고자료
- https://donghwa-kim.github.io/BLEU.html (강추 블로그!!)
- 김기현의 자연어 처리 딥러닝 캠프 파이토치 편
실제 BLEU score 계산 모습

