EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Task
✍논문리뷰

- 리뷰일시 : 2023.07.16
- paper / 코드구현 (한국어 기반)

EDA
: Easy Data Augmentation Techniques for Boodting performance on Text Classification Tasks
= 자연어 처리에서의 데이터 증강 기법
보통 컴퓨터 비전에서는 활발하게 사용하지만,
자연어 처리 분야에서는 단어 하나만 바뀌어도 문장의 의미가 전혀 달라지기 때문에 활용하기 쉽지 않다. 그래서 제시된 데이터 증강 기법을 해당 논문에서는 EDA라고 표현한다.
우리가 흔히 아는 EDA(Exploratory Data Analysis)와는 다르다.
증강 기법 4가지

- 유의어로 교체(Synonym Replacement, SR)
: 문장에서 랜덤으로 stop words가 아닌 n 개의 단어들을 선택해 임의로 선택한 동의어들 중 하나로 바꾸는 기법. - 랜덤 삽입(Random Insertion, RI)
: 문장 내에서 stop word를 제외한 나머지 단어들 중에서, 랜덤으로 선택한 단어의 동의어를 임의로 정한다. 그리고 동의어를 문장 내 임의의 자리에 넣는걸 n번 반복한다. - 랜덤 교체(Random Swap, RS)
: 무작위로 문장 내에서 두 단어를 선택하고 위치를 바꾼다. 이것도 n번 반복 - 랜덤 삭제(Random Deletion, RD)
: 확률 p를 통해 문장 내에 있는 각 단어들을 랜덤하게 삭제한다.
EDA result
EDA를 CNN 과 RNN을 가지고 테스트하고, 다섯개의 랜덤 시드로부터 나온 결과의 평균을 냈다.
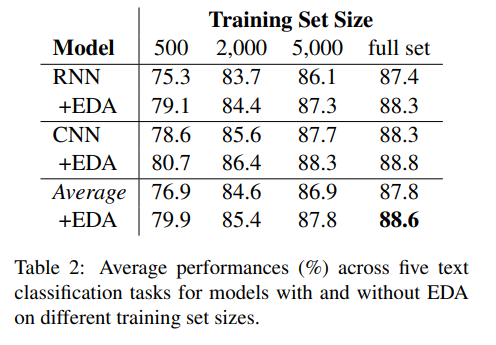
- 평균적으로 전체 데이터 셋을 사용할 경우 0.8%의 성능 향상이 일어났다.
- 특히 training data가 500정도(전체 train dataset의 일부) 일때 3.0%의 성능 향상이 일어났다!
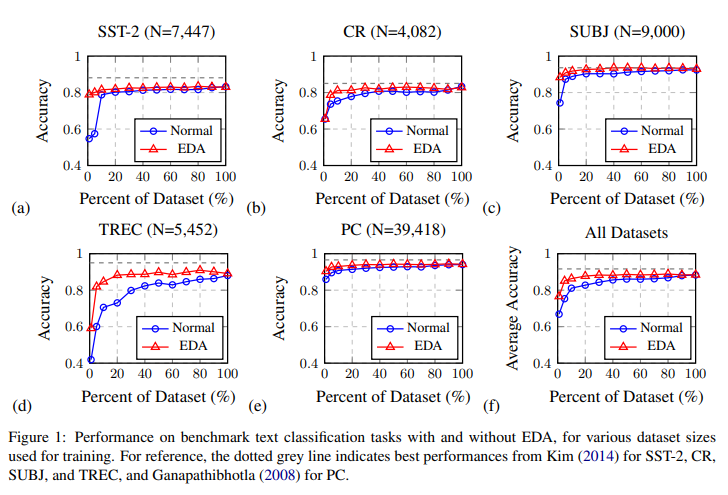
SST-2, CR ... 등 여러 데이터 셋들에 대하여
기존 데이터 셋을 적용 했을때 -> 파랑
EDA 증강 기법을 사용했을 때 -> 빨강
정확성이 어느정도 차이가 나는지의 그래프를 나타낸 것이다.
기존 데이터셋의 비율이 적으면 EDA로 늘린 데이터셋과의 정확도 차이가 커지고
기존 데이터셋의 비율이 커질수록 그 차이가 줄어든다.
즉, 작은 훈련 데이터셋에서 과적합이 발생할 가능성이 더 높기 때문에 EDA를 적용한 기법이 더 큰 성능을 얻는 것이다.
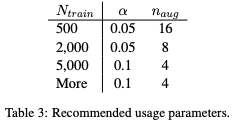 더 큰 훈련 데이터셋의 경우, 모델이 일반화 되는 경우가 있기 때문에 원래 문장 당 4개 이상의 EDA 문장을 추가하는 것은 도움이 되지 않는다.
더 큰 훈련 데이터셋의 경우, 모델이 일반화 되는 경우가 있기 때문에 원래 문장 당 4개 이상의 EDA 문장을 추가하는 것은 도움이 되지 않는다.
Ablation Study: EDA Decomposed
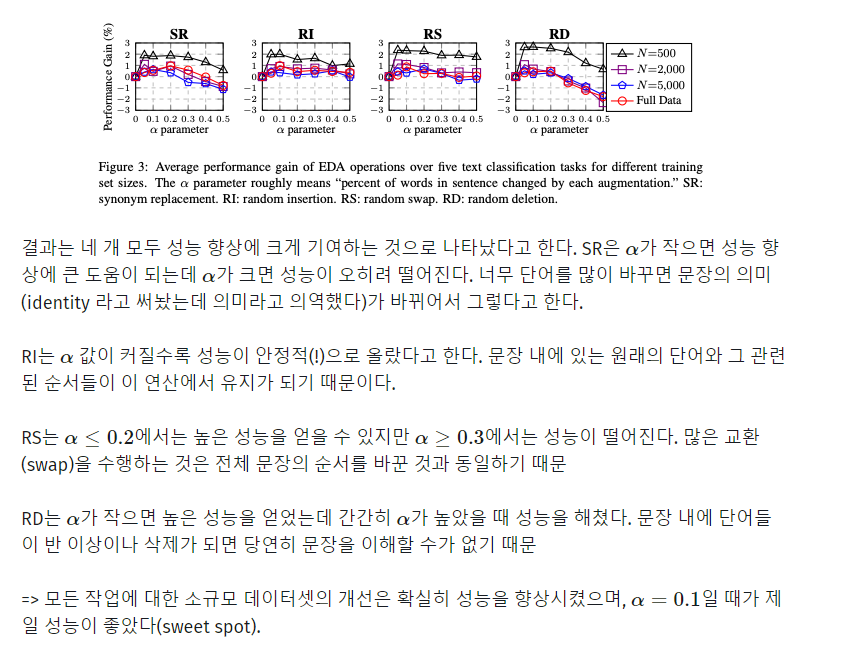
Does EDA conserve true labels?
Dataset을 늘리면 라벨이 훼손되는 가?(기존의 라벨과 값이 다른가?)
기존에 라벨이 적용된 상태에서 늘렸는데, 라벨이 훼손되면 그것은 의미없는 데이터 셋이기 때문.
 EDA를 통해 증폭시킨 데이터셋을 RNN을 통한 분류 모델에 훈련시킨뒤,
EDA를 통해 증폭시킨 데이터셋을 RNN을 통한 분류 모델에 훈련시킨뒤,
모델의 마지막 레이어에서 인스턴스의 분포를 t-SNE를 통해 시각화해보니
새로 생성된 문장들이 원문의 라벨 성질을 대체로 잘 따른다는 것을 확인할 수 있음.
> 결론
즉, 오버피팅이 쉽게 발생할 수 있는, 훈련 데이터가 충분치 않은 상황에서 성능 향상에 유의미한 도움을 줄 수 있다.
작은 데이터셋에서 더 좋은 성능을 얻는 건 명백한데, 사전 훈련된 모델을 사용하는 경우에는 상당한 개선 효과를 거두지 못할 수도 있다
한계
WordNet만을 단순히 바꿔서 결괏값을 내기 때문에 의미가 변형되어버리는 경우가 생깁니다. 특히 SR과 RI를 사용할 때 많이 발생하는데 제가 잘못한 건 아닌 것 같아요 를 제가 잘못한 총 아닌 것 같아요 (건 -> 총) 으로 바뀌기도 한다. 본 논문에서는 이렇게 바꿔도 꽤나 원문 데이터의 성질을 따라간다고 하지만.. 한국어의 특성상 완전히 따라가기에는 쉽지 않은 것 같다.
안전하게 데이터 증강을 하고 싶다면 RD, RS만을 사용하고, 데이터가 많이 필요하다싶으면 SR과 RI까지 사용하고 인간지능으로 데이터를 걸러내는 작업이 필요할 것이다.
참고
EDA 논문 설명
EDA-영어.ver code
: augment.py 사용
EDA-한국어.ver code
: eda.py 사용
