단순 회귀분석
-
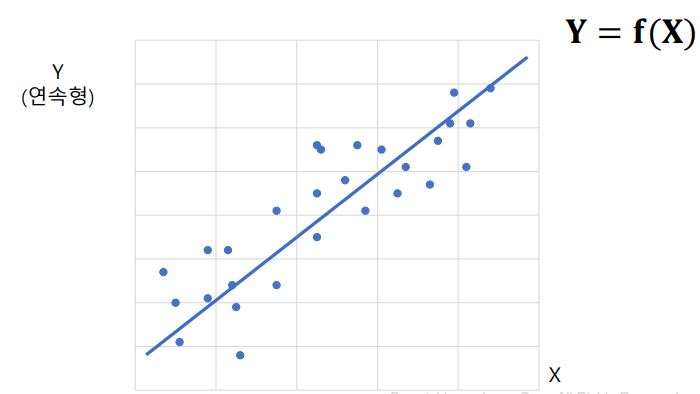
회귀 분석(regression analysis): 변수들간의 함수적 관계를 선형으로 추론하는 통계적 분석 방법으로 독립변수를 통해 종속변수를 예측하는 방법
-
비선형인 함수적 관계일 경우 비선형회구(nonlinear regression)를 사용 (ex. 마케팅 비용에 따른 매출액을 예측)
-
종속 변수(dependent variable): 다른 변수의 영향을 받는 변수로 반응변수라 표현하기도 하며, 예측하고자 하는 변수(ex. 매출액, 수율, 불량율 등)
-
독립 변수(independent varibale): 종속변수에 영향을 주는 변수로 설명변수라 표현하기도 하며, 예측하는 값을 설명해주는 변수
-
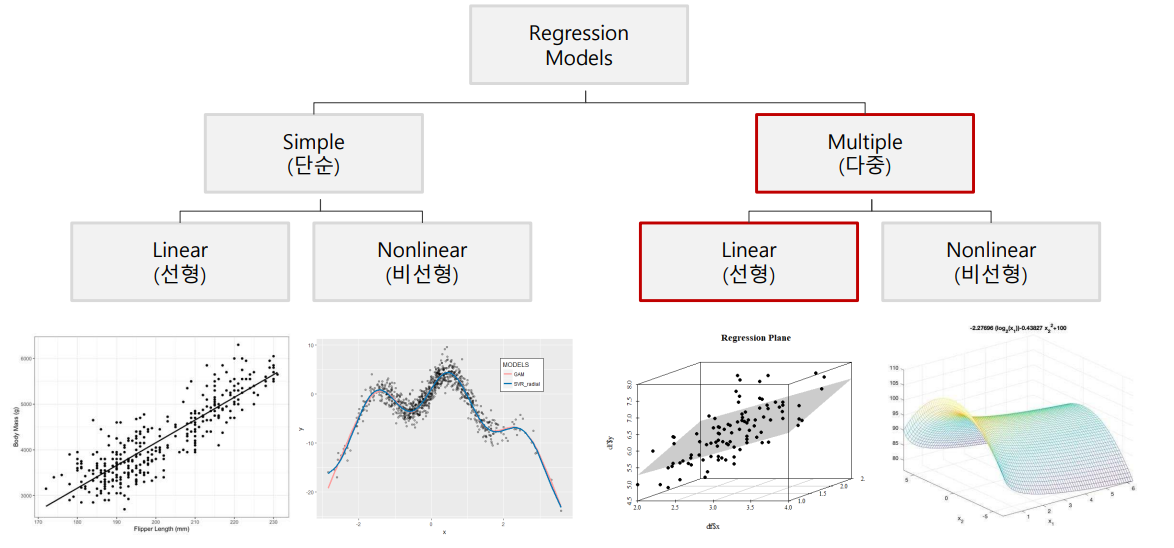
단순 회귀분석(simpole regression analysis): 하나의 독립변수로 종속변수를 예측하는 회귀 모형을 만드는 방법을 단순 회귀 분석이라고 함
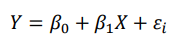
- 다중 회귀분석(multiple regression analysis): 2개 이상의 독립변수로 종속 변수를 예측하는 회귀 모형을 만드는 방법을 다중 회귀분석이라고 함
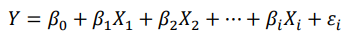
회귀모델링 분류
- X변수의 수, X변수와 Y변수의 선형성 여부에 따라 구분
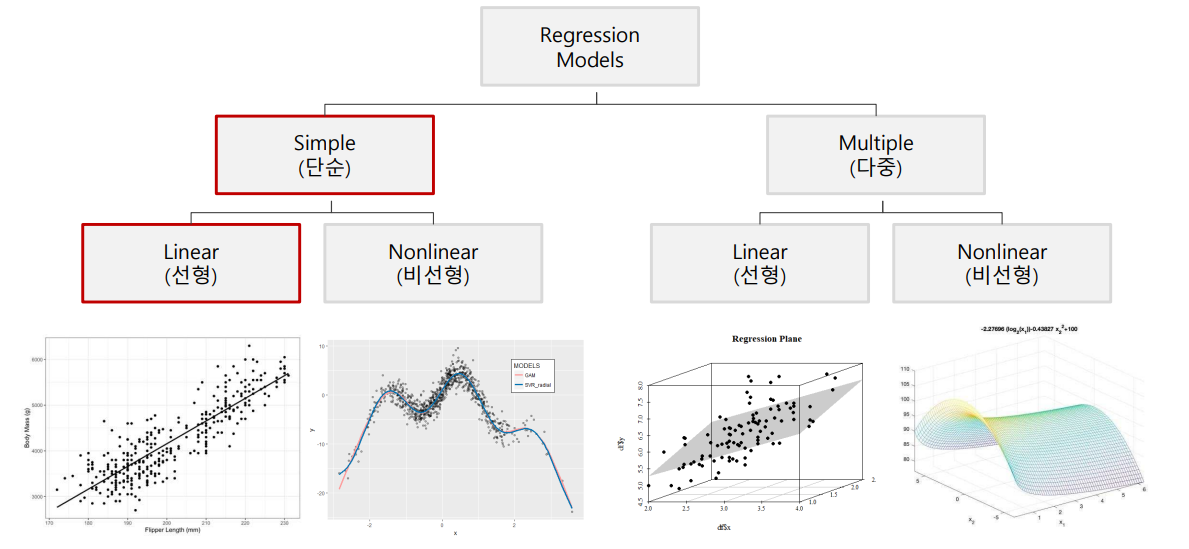
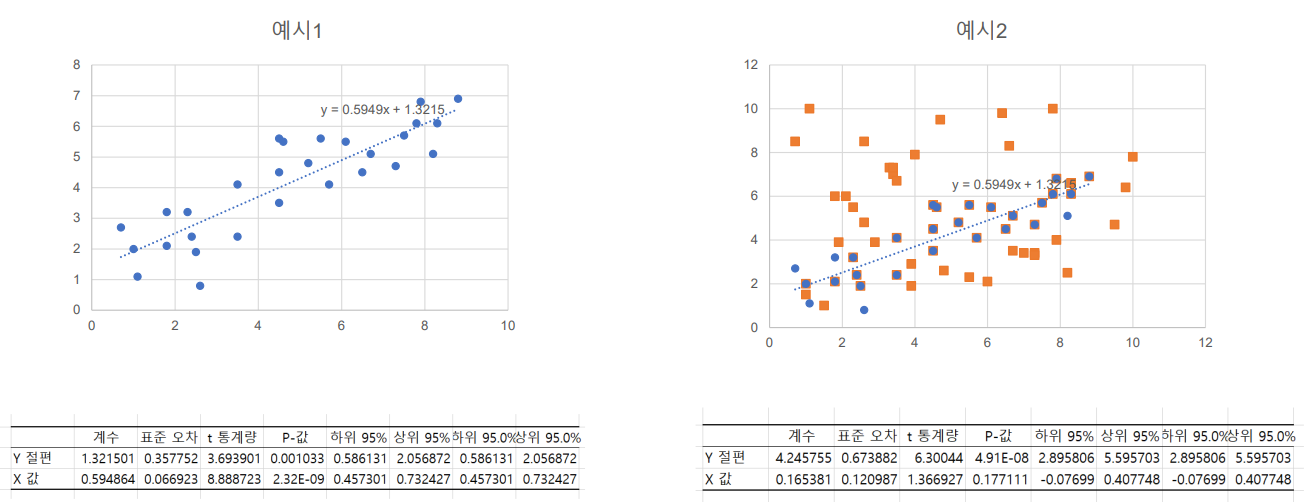
단순 회귀분석 예시
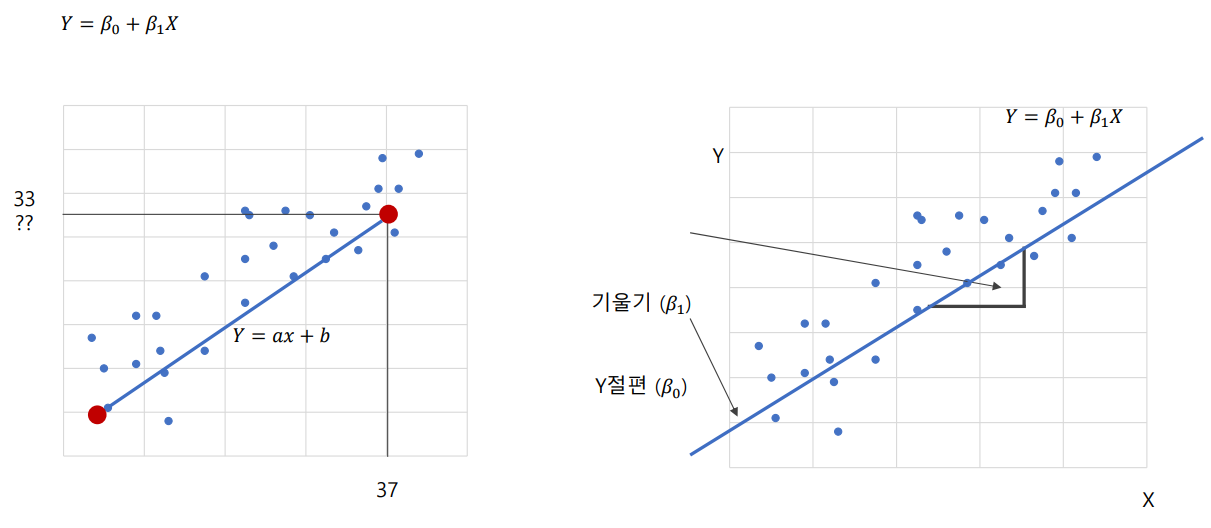
- 회귀선으로부터 각 관측치의 오차를 최소로하는 선을 찾는 것이 핵심
- 오차를 최소로 하여 β0, β1을 추정하는 방법을 최소제곱법(method of least squeares)라고 함
최소 제곱법
-
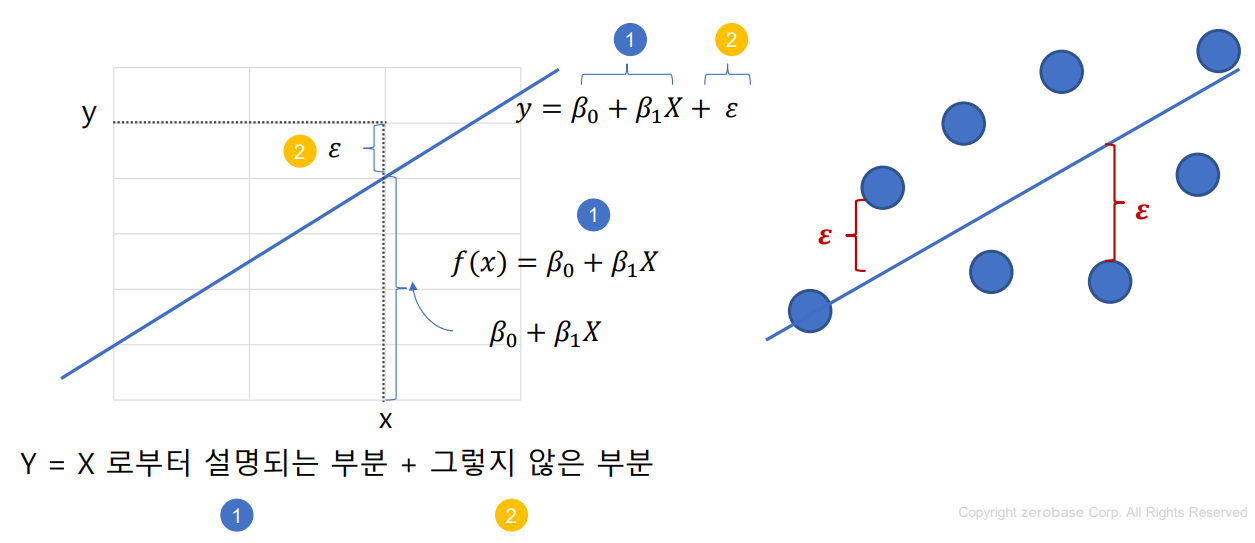
최소 제곱법: 회귀 모형의 모수 β0, β1 을 추정하는 방법중 하나를 최소 제곱법이라고 하며, 회귀 모형의 모수를 회귀 계수라고 함
-
최소 제곱법을 통해 구한 추정량을 최소제곱추정량(LSE)라고 하며, 최소제곱법을 통해 회귀모형의 모수를 추정하는 것을 OLS(Ordinary Least Square) 라고 함
-
회귀 모형의 오차에 대한 기본 가정
1) 정규성 가정: 오차항은 평균이 0인 정규 분포를 따름
2) 등분산성 가정: 오차항의 분산은 모든 관측값 rX에 상관없이 일정함
3) 독립성 가정: 모든 오차항은 서로 독립임
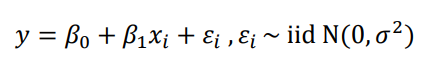
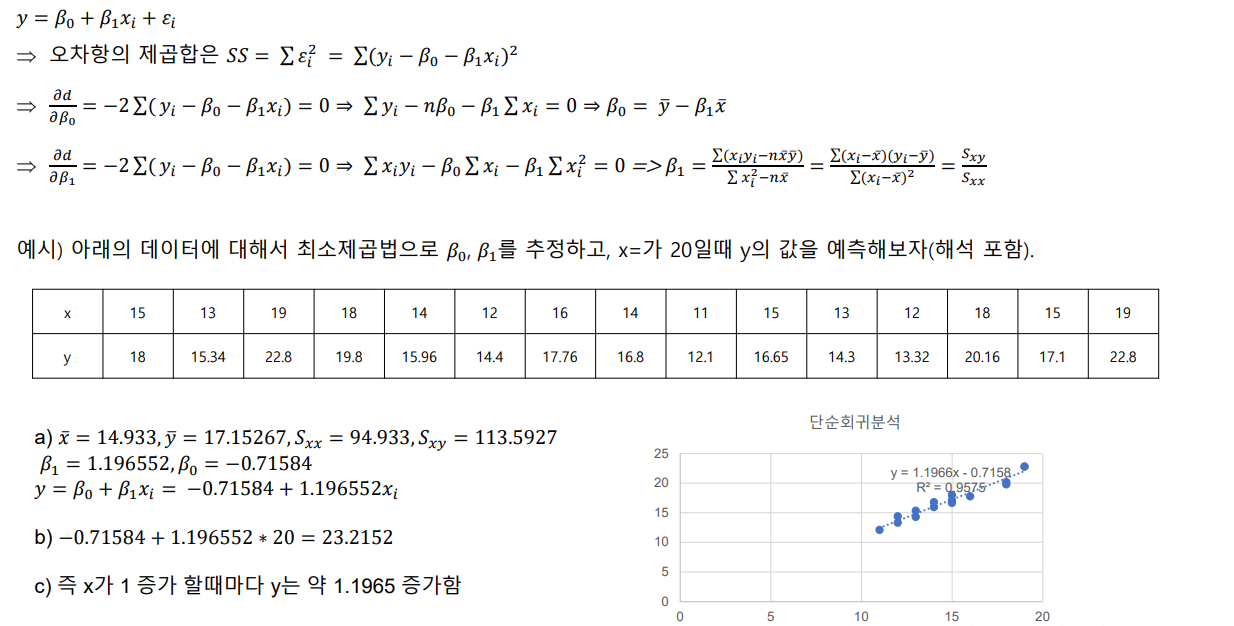

분산분석표
- 분산분석표: 추정된 회귀식에 대한 유의성 여부는 분산분석을 통해서 회귀식의 유의성을 판단할 수 있음
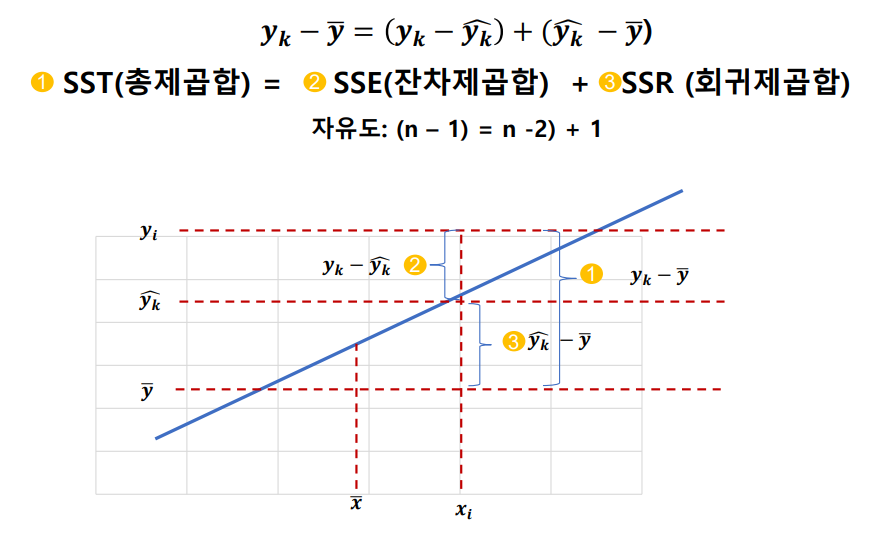
- 제곱합을 각각의 자유도 나눈 값을 평균제곱(mean square)라고 함

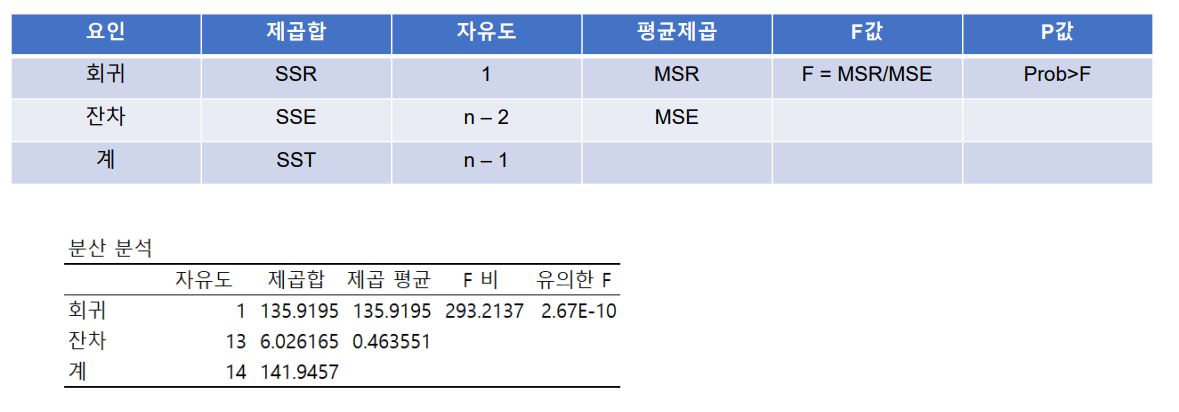
- 회귀분석 결과 해석

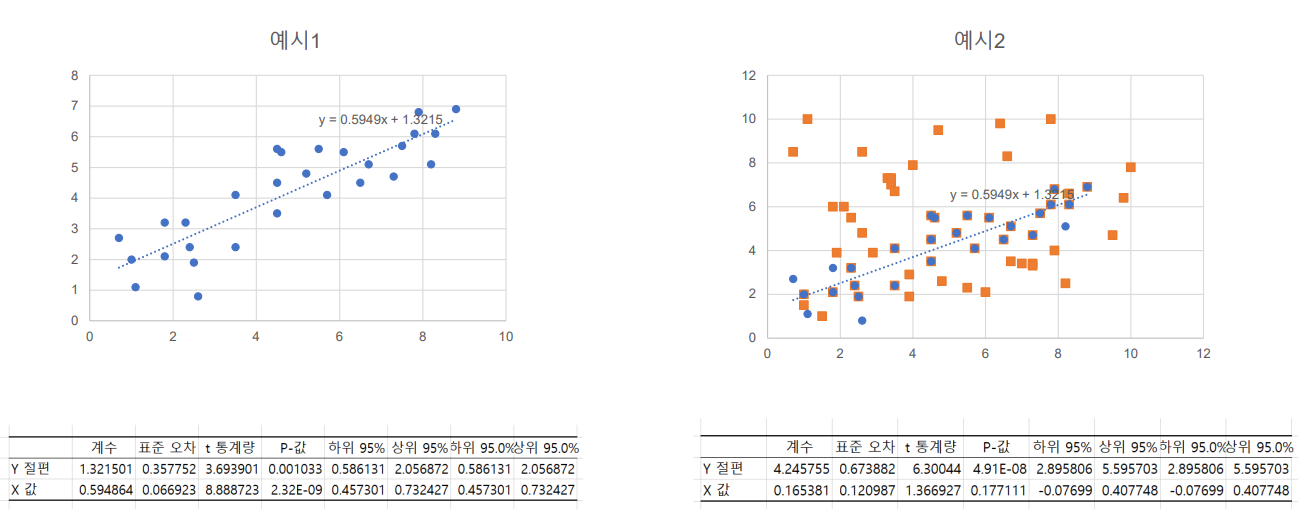
- 회귀분석의 β0, β1의 추론과 가설 검정

- 회귀분석 결과 해석
결정계수
- 결정계수(Coefficient of determination:R²): 추정된 회귀식이 얼마나 전체 데이터에 대해서 적합한지(설명력이 있는지)를 수치로 제공하는 값
- 0과 1사이에 값으로 1에 가까울수록 추정된 모형이 설명력이 높다고 할 수 있음
- 0이라는 것은 추정된 모형이 설명력이 전혀 없다고 할 수 있음
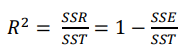

수정 결정 계수
- 수정 결정 계수(Adjust R²): R²은 유의하지 않은 변수가 추가되어도 항상 증가됨(다중회귀)
- Adjust R²은 특정 계수를 곱해 줌으로서 R²가 항상 증가되지 않도록 함
보통 모형 간의 성능을 비교할 때 사용함


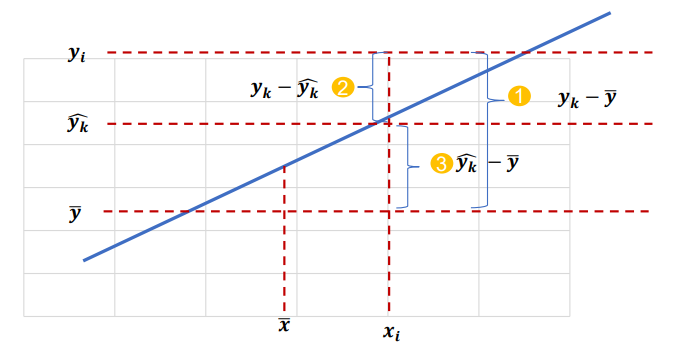
잔차 분석
a) 선형성을 벗어나는 경우: 종속변수와 독립변수가 선형 관계가 아님
b) 등분산성이 벗어난 경우: 일반적인 회귀모형 사용 불가능, 등분산성 가정 위배
c) 독립성에 벗어나는 경우: 시계열 데이터 또는 관측 순서에 영향을 받는 데이터에서는 독립성을 담보할 수 없음(Durbin-Watson test 실행)
d) 정규성을 벗어나는 경우: Normal Q-Q plot으로도 확인, 잔차가 -2 ~ +2 사이에 분포해야 함, 벗어나는 자료가 많으면 독립성 가정 위배
단순 회귀분석 실습을 위한 예시
- CRIM: 자치시(town) 별 1인당 범죄율
- ZN: 25,000 평방피트를 초과하는 거주지역의 비율
- INDUS:비소매상업지역이 점유하고 있는 토지의 비율
- CHAS: 찰스강에 대한 더미변수(강의 경계에 위치한 경우는 1, 아니면 0)
- NOX: 10ppm 당 농축 일산화질소
- RM: 주택 1가구당 평균 방의 개수
- AGE: 1940년 이전에 건축된 소유주택의 비율
- DIS: 5개의 보스턴 직업센터까지의 접근성 지수
- RAD: 방사형 도로까지의 접근성 지수
- TAX: 10,000 달러 당 재산세율
- PTRATIO: 자치시(town)별 학생/교사 비율
- B: 1000(Bk-0.63)^2, 여기서 Bk는 자치시별 흑인의 비율을 말함
- LSTAT: 모집단의 하위계층의 비율(%)
- MEDV: 본인 소유의 주택가격(중앙값) (단위: $1,000)
다중 회귀분석
- X변수의 수, X변수와 Y변수의 선형성 여부에 따라 구분
- 다중 회귀분석(multiple regression analysis): 2개 이상의 독립변수로 종속 변수를 예측하는 회귀 모형을 만드는 방법을 다중 회귀분석이라고 함
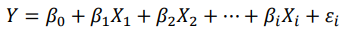
회귀모델링 분류
로지스틱 회귀분석
- 로지스틱 회귀분석(Logistic regression analysis): 반응 변수가 범주형(이진수)인 경우 사용하는 모형
다항 회귀분석(polynomial regression)
-
다항 회귀분석(polynomial regression): 독립 변수가 k개이고 반응 변수와 독립변수가 1차 함수 이상인 회귀분석
-
예시) 주택 가격 = 범죄율 + 주택1가구당 폋균 방의 개수 + ... + 모집단의 하위계층의 비율

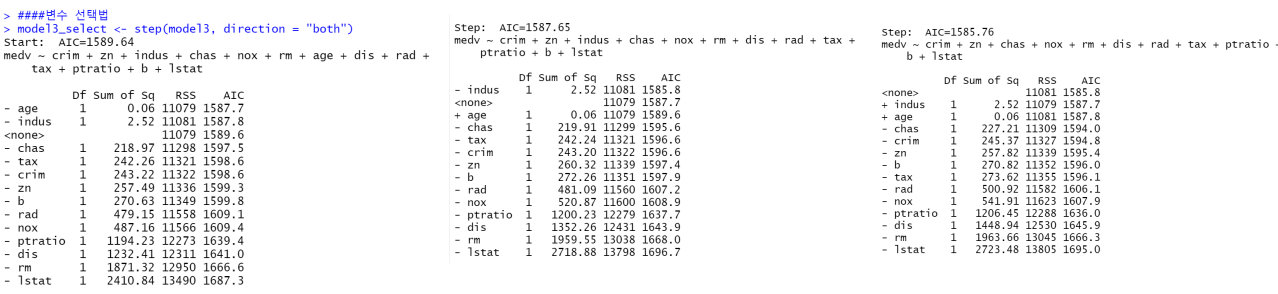
변수선택법
- 전진선택법(forward selection) : 독립변수를 1개부터 시작하여 가장 유의한 변수들부터 하나씩 추가하면서 모형의 유의성을 판단하는 방법
- 후진 제거법(backward selection) : 모든 독립변수를 넣고 모형을 생성한 후, 하나씩 제거하면서 판단하는 방법
- 단계접 방법(stepwise selection) : 위의 두가지 방법을 모두 사용하여 변수를 넣고 빼면서 판단하는 방법
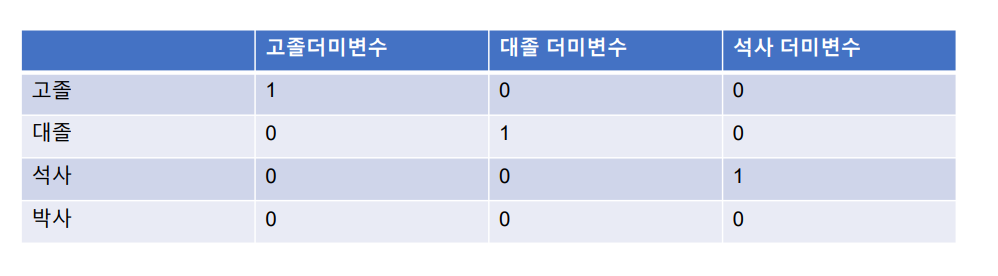
더미변수
- 더미변수(dummy variable): 값이 '0' 또는 '1'로 이루어진 변수
- 지금까지 회귀분석에서는 연속형 변수를 사용하는 예를 들었지만, 범주형 변수를 사용하기 위해서는 더미변수가 필요함
- 예를 들어 사는 지역을 '1','2','3'으로 사용하면 연속형 변수여서 정확한 변수로 사용할 수 없음
- 범주형 변수를 0과 1의조합으로 표현할 수 있도록 더미 변수를 생성함
- 예) 최종 학력 : 고졸, 대졸, 석사, 박사 4가지로 표현한다면 필요한 더미의 개수는 4-1 = 3개임
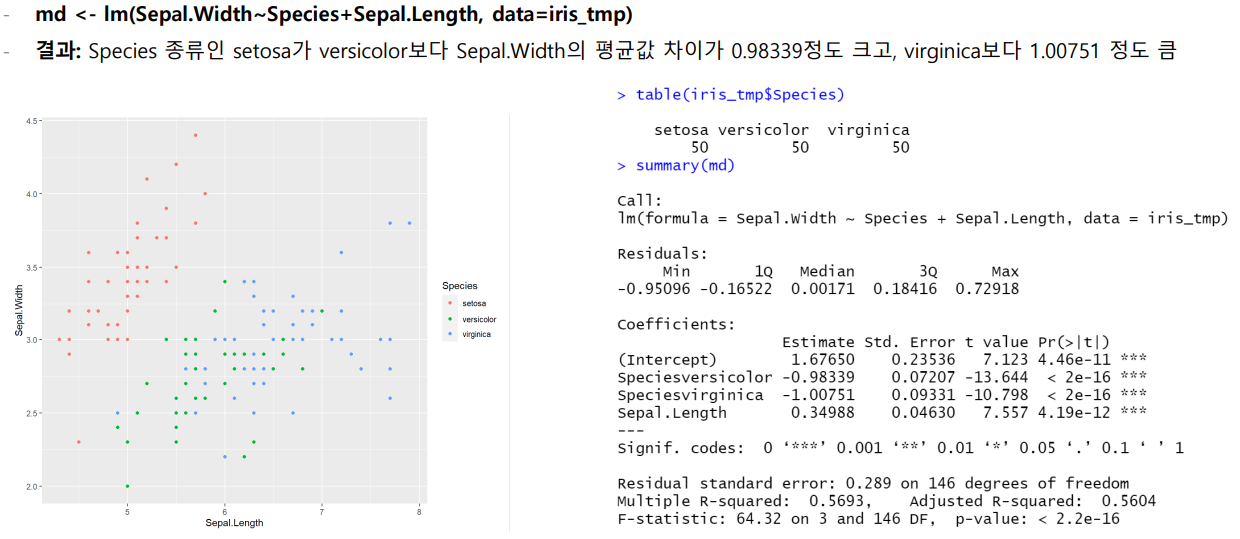
- R에서 iris data 를 가지고 회귀분석 실행
다중공선성
- 다중공선성(Multicollinearity): 상관관계가 높은 독립견수들이 동시에 사용될 때 문제가 발생
- 결정계수 R²값은 높아 회귀식의 설명력은 높지만 독립변수의 P-value 커서 개별 인자들이 유의하지 않는 경우 의심할 수 있음
- 일반적으로 분상팽창요인(Variance Inflation Factor: VIF)이 10 이상이면 다중공선성이 존재함

- 해결방안
1) 다중공선성이 존재하지만 유의한 변수인 경우 목적에 따라서 사용할 수 있음
2) 변수 제거
3) 주성분분석으로 변수를 재조합
분산분석
분산분석
-
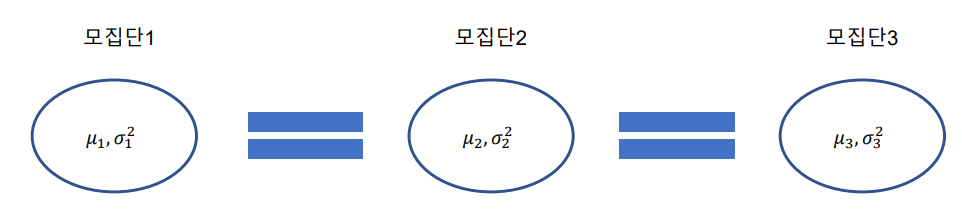
분산분석: 셋 이상의 모집단으로부터 추출한 양적 데이터를 비교하는 통계적 분석 방법
-
t-test: 두개의 모집단의 평균 차이를 검정
-
만약 아래의 평균 차이 검정을 t-test로 한다면

-
실험계획법(experimental design): 모집단의 특성에 대하여 추론하기 위해 특별한 목적성을 가지고 데이터를 수집하기 위한 실험설계
-
반응변수 : 관심의 대상이 되는 변수
-
요인/인지(Factor): 실험 환경 또는 조건을 구분하는 변수로 실험에 영향을 주는 변수
-
인자수준: 인자가 취하는 개별 값(처리:treatment)
-
분산분석인 이유: 모집단의 평균들을 비교하기 위하여 특성값의 분산 또는 변동을 분석하는 방법, 실험을 통해 얻은 편차의 제곱합을 통해 평균의 차이를 검정
-
분산분석의 기본 가정
1) 각 모집단의 정규 분포를 따른다
2) 각 모집단의 동일한 분산을 갖는다
3) 각 표본은 독립적으로 추출되었다 -
분산분석의 가설: H0: 각 집단의 평균은 동일하다 vs H1: 각 집단의 평균에 차이가 있다
-
실험의 가정
- 반복의 원리: 실험을 반복해서 실행해야 함
- 랜덤화의 원리: 각 실험의 순서를 무작위로 해야함
- 블록화의 원리: 제어해야 할 변수가 있다면 인자에 영향을 받지 않도록 조건을 묶어서 실험해야 함
- 일원 분산분석: 한 가지 요인을 기준으로 집단 간의 차이를 조사하는 것
- 이원 분산분석: 두 가지 요인을 기준으로 집단 간의 차이를 조사하는 것
- 다원 분산분석: 세 가지 이상의 요인을 기준으로 집단 간의 차이를 조사하는 것
One-way ANOVA
-
One-way ANOVA: 한 개의 반응 변수와 한 개의 독립 인자
-
반응 변수: 연속형 변수만 가능
-
독립 인자(변수): 이산형 또는 볌주형 변수만 가능
-
예시) A,B,C 3개의 편의점에서 만족도를 조사한 결과 만족도의 차이가 있는가?
생산라인 A,B,C에서 생산되는 웨이퍼의 불량률은 차이가 있는가?



- 가설


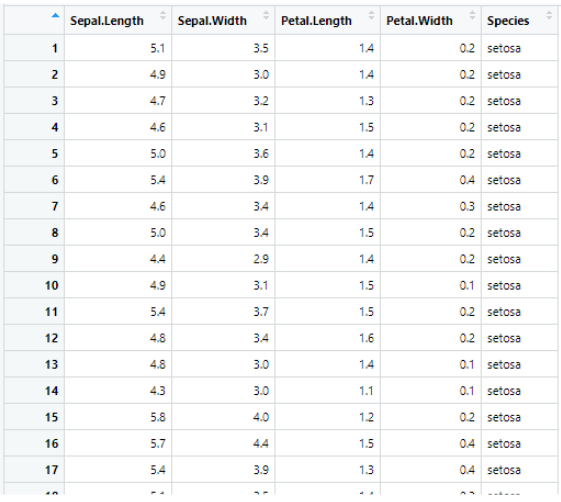
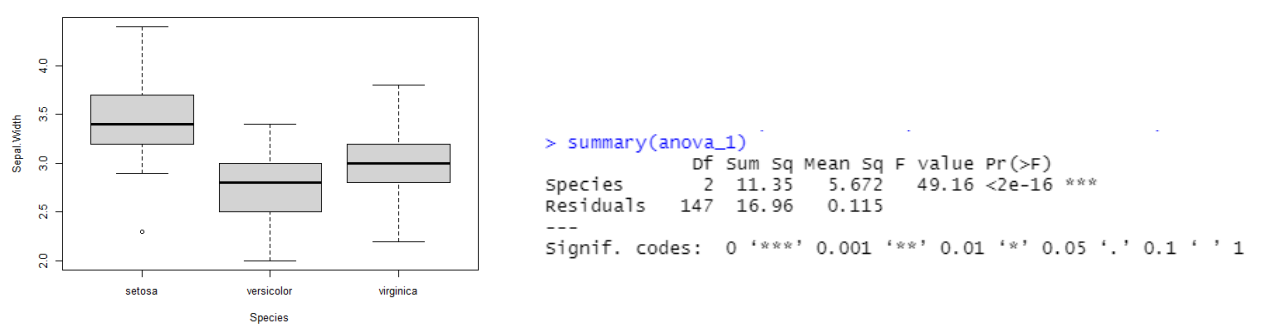
- 예제) R에서 얻은 iris 데이터를 활용하여 Species 별로 Sepal.Length의 평균의 차이가 있는지 유의수준 0.05에서 검정해보자
- H0∶ Species 별로 Sepal.Length 의 크기의 평균은 같다 vs H1: Species 별로 Sepal.Length 의 크기의 평균은 같지 않다
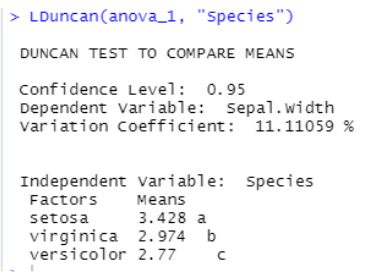
- 사후 검정
평균이 다른건 알지만 어떤 처리 조건이 평균 차이가 있는지?
(Bonferroni, scheffe, Duncan, Dunnett 등의 방법으로 사후 검정이 가능함)
Two-way ANOVA
-
Two-way ANOVA: 한 개의 방응 변수와 두 개의 독립 인자로 분석하는 방법
-
독립인자: one-way와 마찬가지로 이산형 또는 범주형 변수만 가능
-
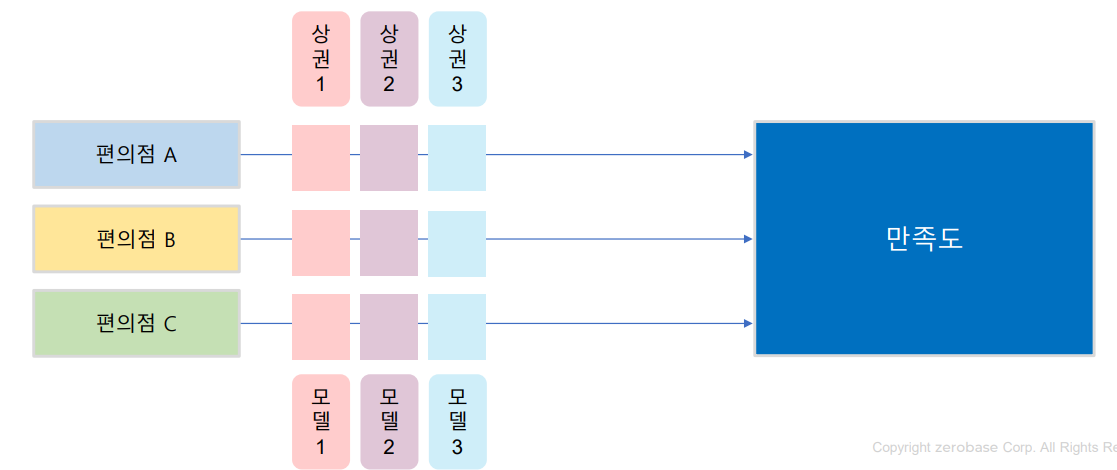
예) 만족도에 영향을 주는 인자가 편의점 브랜드와 상권이라고 할 때, 편의점 브랜드별로 상권을 변경하면서 만족도가 다른지 측정하고 분석하는 방법
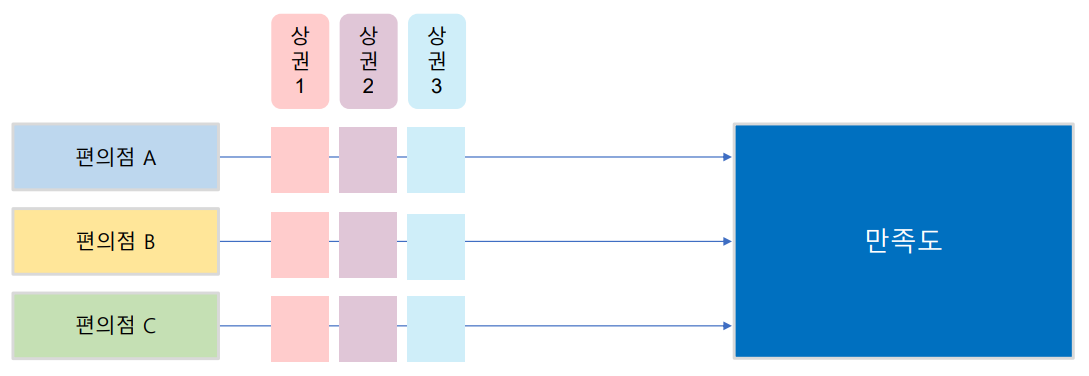
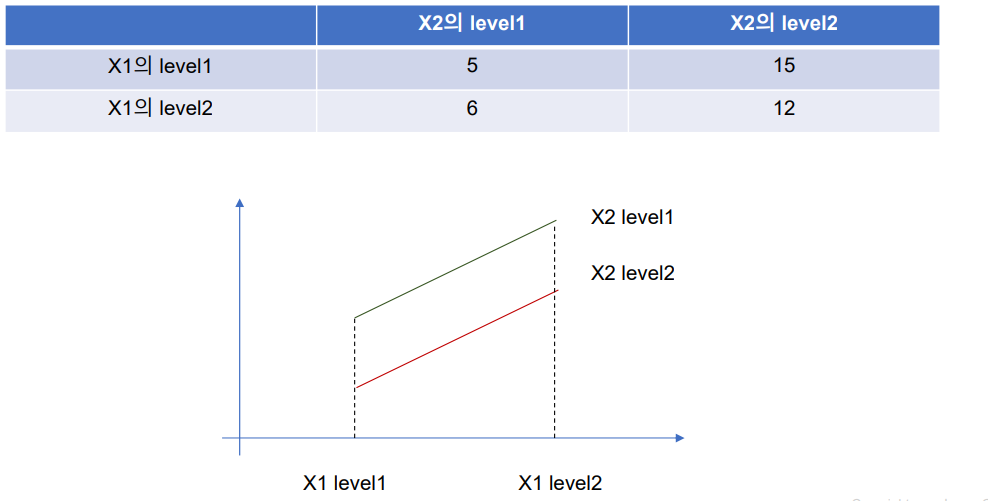
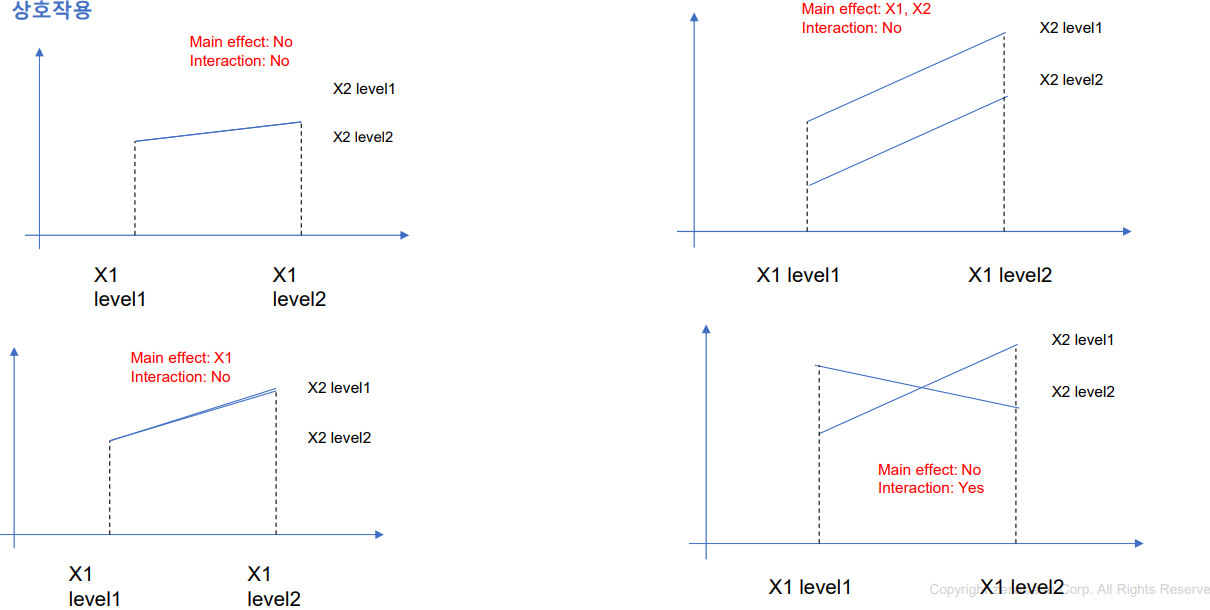
- 상호작용(Interaction effect): 한 독립변수의 main effect가 다른 독립변수의 level에 따라서 원래의 선형관계를 비선형관계롤 변하는 경우
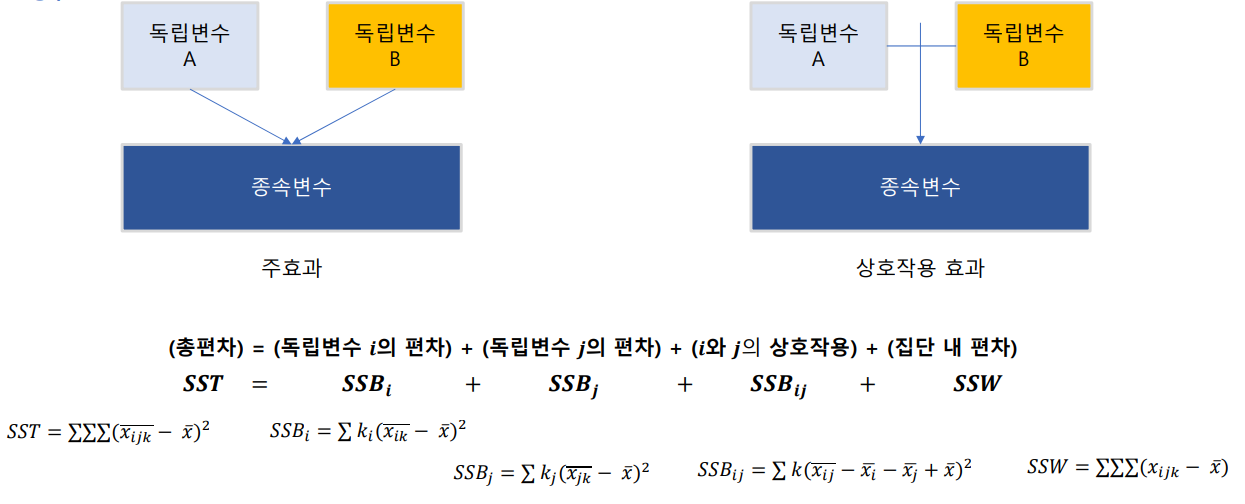
- 가설

- 예제) 아래 데이터와 같이 데이터가 주어지고 mpg(연비)의 평균이 am(변속기 종류), cyl(실린더 종류) 따라서 차이가 있는지 유의 수준 0.05에서 검증해보자
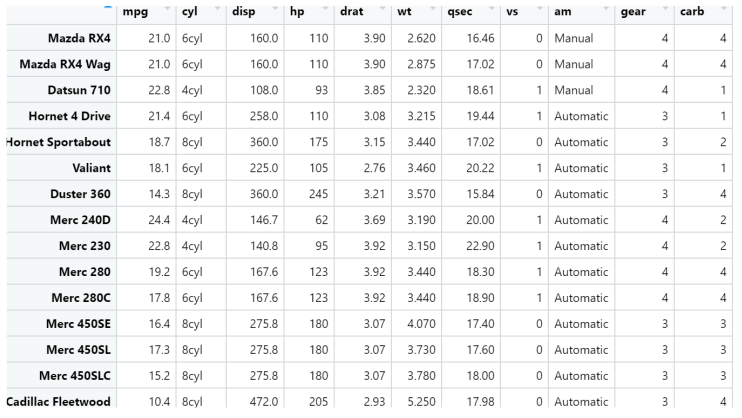
- 해석) 변속기의 종류와 실린더의 종류에 따라서 연비의 평균의 차이는 유의미함, 그러나 상호작용효과는 없음

시계열
시계열 분석
-
시계열분석(time series analysis): 시계열(시간의 흐름에 따라 기록된 것) 자료(data)를 분석하고 여러 변수들간의 인과관계를 분석하는 방법
-
시계열 데이터: 시간을 기준으로 관측된 데이터로, 보통 일->주->월->분기->년 또는 Hour 등 시간의 경과에 따라서 관측한 데이터
예) GDP, 주가, 거래액, 매출액, 승인금액 등을 시간의 흐름에 따라 정의한 데이터 -
시계열 데이터는 연속 시계열과 이산 시계열 데이터로 구분할 수 있음
-
연속 시계열: 자료가 연속적으로 생성, 대부분의 데이터 형태가 연속형이나 이산형 정의하여 분석
-
이산형 시계열: 일정 시차(간격)을 주고 관측되는 형태의 데이터
대부분 이산형 데이터를 분석 -
시계열 분석의 목적
예측: 금융시장 예측, 수요 예측 등 미래의 측정 시점에 대한 관심의 대상(반응변수)을 예측
시계열 특성 파악: 경향(Trend), 주기, 계절성, 변동성(패턴) 등 관측치의 시계열 특성 파악 -
전통적인 시계열 분석 방법
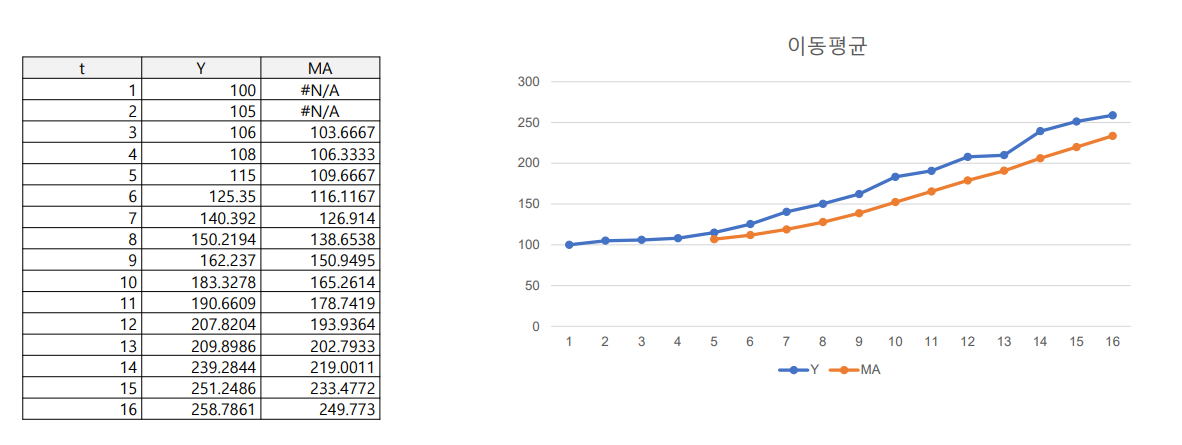
이동 평균 모형(moving average) : 최근 데이터의 평균을 예측치로 사용하는 방법
자기 상관 모형(Autocorrelation): 변수의 과거 값의 선형 조합을 이용하여 예측하는 방법
ARIMA(Autoregressive Integrated Moving Average): 관측값과 오차를 사용해서 모형을 만들어서 미래를 예측하는 방법
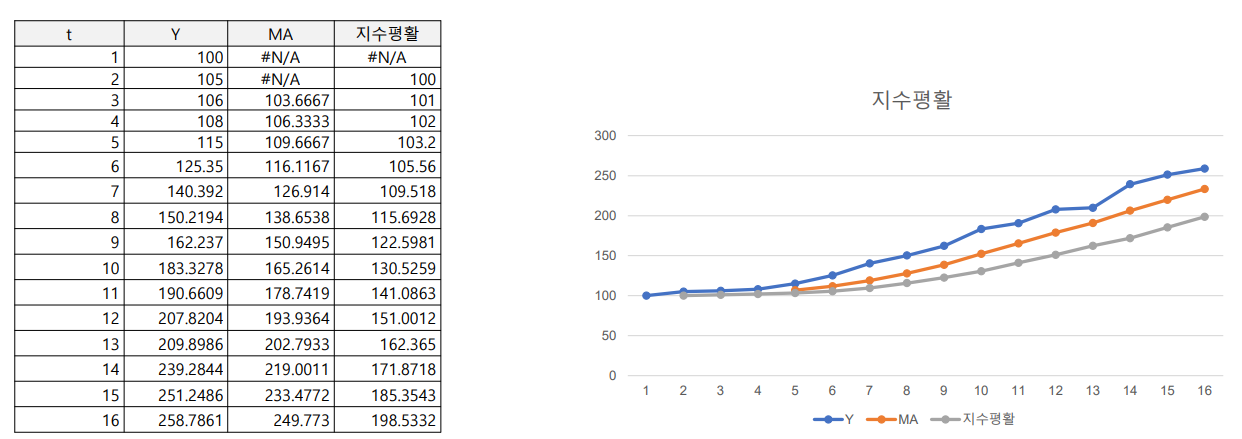
지수평활법: 현재에 가까운 시점에 가장 많은 가중치 주고 멀어질수록 낮은 가중치를 주어서 미래를 예측하는 방법
시계열 요소
-
경향/추세(trend): 시계열 데이터가 장기적으로 증가(감소)할 때, 추세가 존재함
-
계절성(seasonality): 특정기간(1년마다) 어떤 특정한 때나 1주일마다 특정 요일에 나타나는 것 같은 계절성 요인이 시계열에 영향을 줄 때 계절성(seasonality)이라고 함
예) 패션업종 매출, 요일 별 온라인 쇼핑몰 매출 등이 계절성의 대표적
- 주기성(cycle): 일정한 주기(진폭)마다 유사한 변동이 반복되는 현상, 보통 경기 순환(business cycle)과 관련이 있으며 지속기간은 2년
예) 주가 업종별 개별 주가
- 불규칙요인(Irregular movements): 예측하거나 제어할 수 없는 요소
예) 회귀분석의 오차와 같은 항목
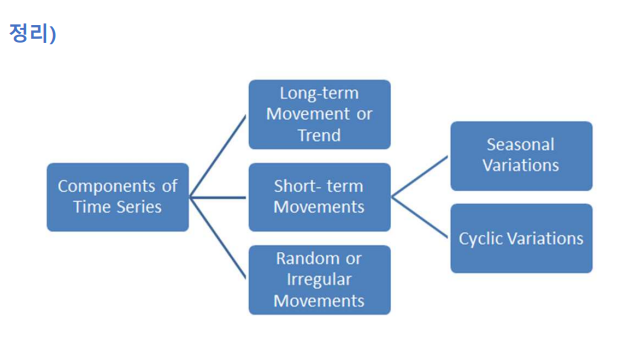
시계열 분석 방법

- 이동 평균법
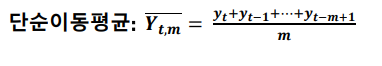
- 지수평활법
모든 관측값을 이용하면서 예측하는 시점에 가까울수록 비중을 두어 최근값이 예측 시 더 많은 기여를 하도록 만드는 방법
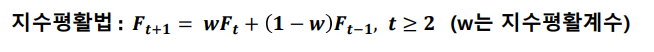
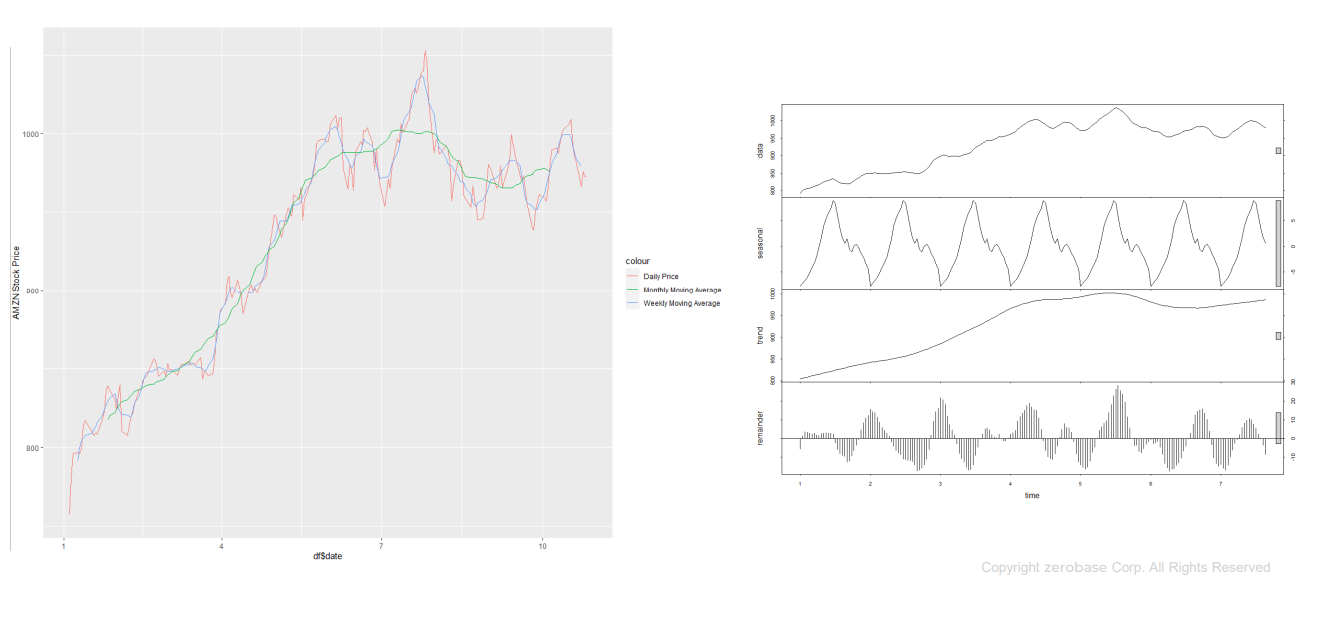
- 시계열 분석 예시
Machine Learning 알고리즘과 실제 활용 소개
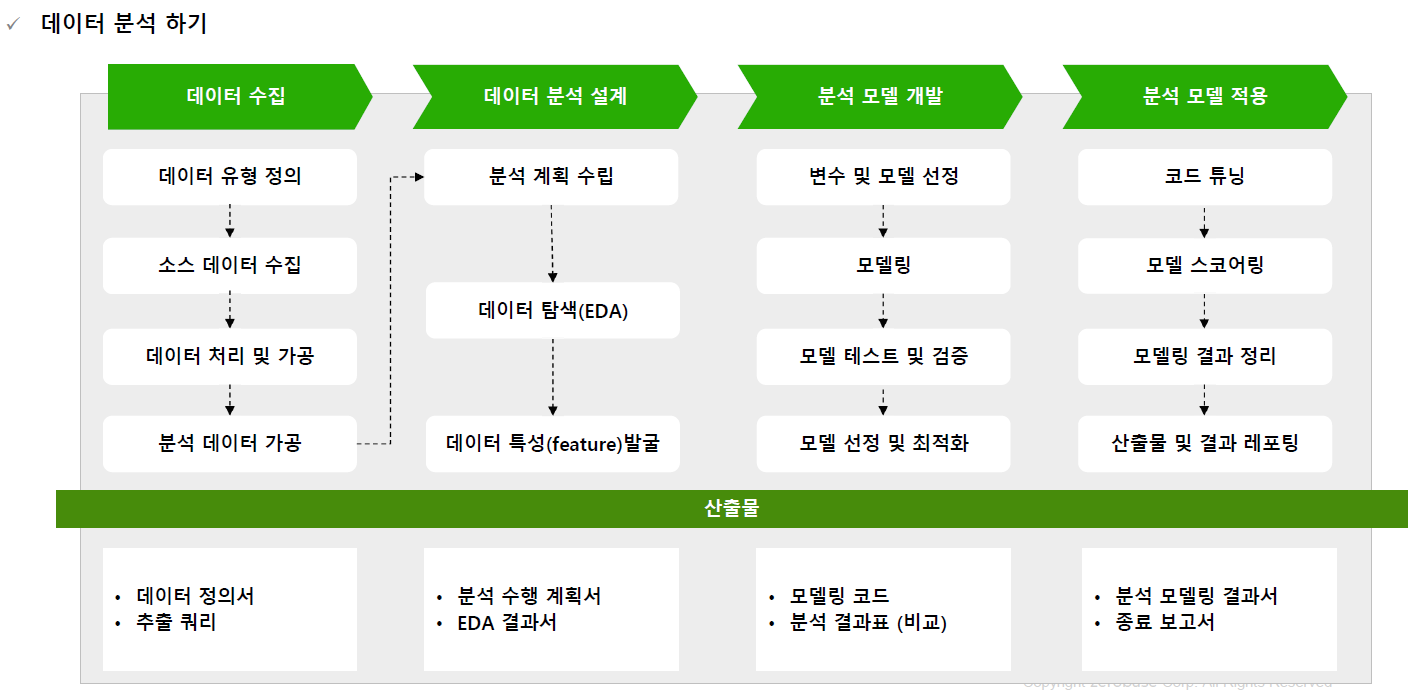
기초통계 활용하기
- 문제) 1~100 사이에 숫자로 이루어진 데이터가 있을 때 어떤 분석을 할 수 있을까요?

- 데이터 분석 하기
Machine Learning
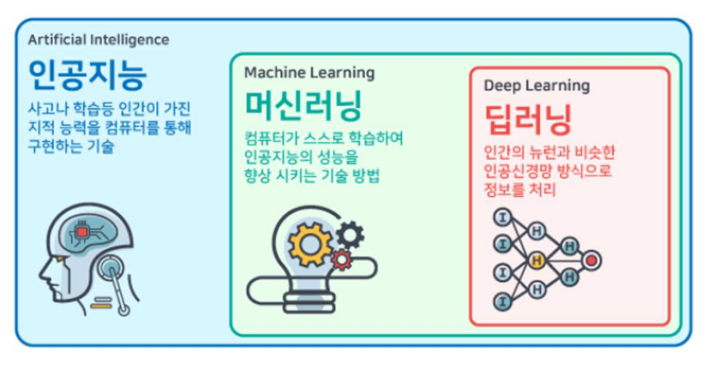
- Machine Learning: 인공 지능의 한 분야로, 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야, 컴퓨터가 학습 모형을 기반으로 주어진 데이터를 통해 스스로 학습하는 것
- 머신러닝은 Task, Experience, Performance의 세가지 요소를 가지고 있음
Task를 달성하기 위해 경험을 통해 성능을 개선시킴
즉, 1) 분석하고자 하는 목표(T)를 정의, 2) Experience를 정의하기 위한 데이터를 수집, 3) Performance를 향상시키기 위한 Measure를 정의함

- Supervised Learning: Label이 있는 데이터에 대해서 분석하는 방법으로 과거의 데이터로 미래를 예측하는 방법
- Classification은 Y의 값이 Category일때 Regression은 Y의 값이 연속된 값일 경우 사용함
- Unsupervised Learning : Label이 없는 데이터에 대해서 분석하는 방법으로 데이터 나누거나 속성별로 분류할 때 사용
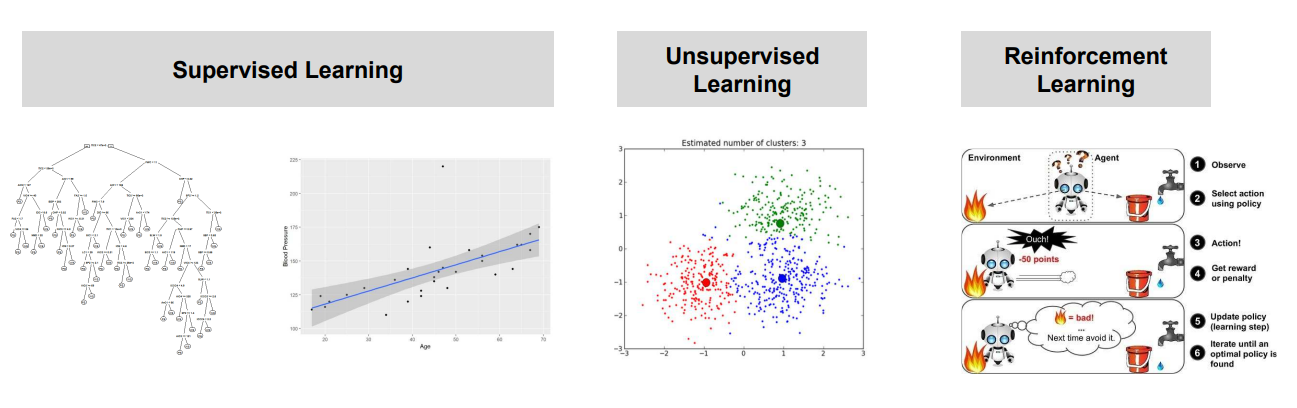
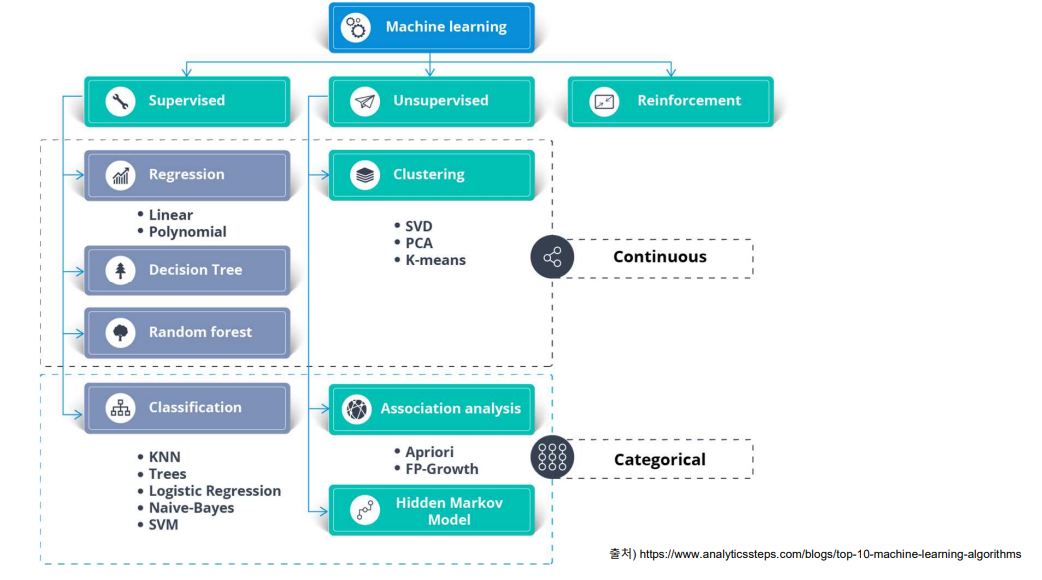
- Machine Learning 알고리즘
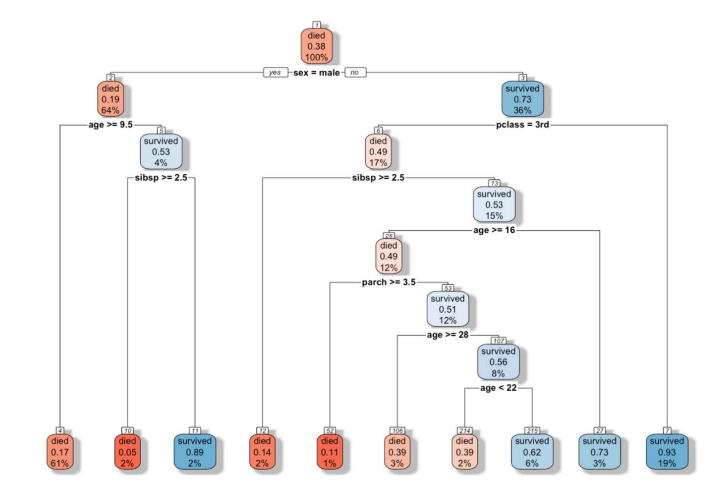
- Decision Tree: 설명변수(X) 간의 관계나 척도에 따라 목표변수(Y)를 예측하거나 분류하는 문제에 활용되는 나무 구조의 모델
장점: 결과 해석이 쉽고 빠름, 선형/비선형에 적용 가능
단점: 과도적합의 문제 조심, 분기점에서 오차 발생확률이 올라감
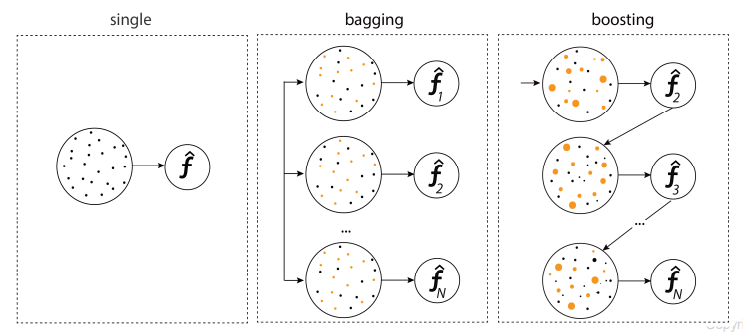
- 앙상블 모형
-
Bagging: boostrap aggregating의 약어로 데이터를 가방(bag)에 쓸어 담아 복원추출하여 여러 개의 표본을 만들어 이를 기반으로 각각의 모델을 개발한 후에 결과를 하나로 합쳐 하나의 모델을 만들어 내는 것
예) Randomforest -
Boosting: Boosting도 Bagging과 동일하게 복원 랜덤 샐플링을 하지만, 가중치를 부여한다는 차이점
Bagging이 병렬로 학습하는 반면, Boosting은 순차적으로 학습시킵니다. 학습이 끝나면 나온 결과에 따라 가중치가 재분배
예) AdaBoost, XGBoost, GradientBoost
- 추천모형: Association, CF모형
Deep Learning
- Deep Learning: Deep Learning(딥러닝) 또는 Deep Neural Network라고 불리는 기술은 인공신경망의 발전한 형태로 볼 수 있음
인간의 뇌처럼 수많은 노드를 연결하여 이들의 노드 값을 훈련시켜 데이터를 학습시킴
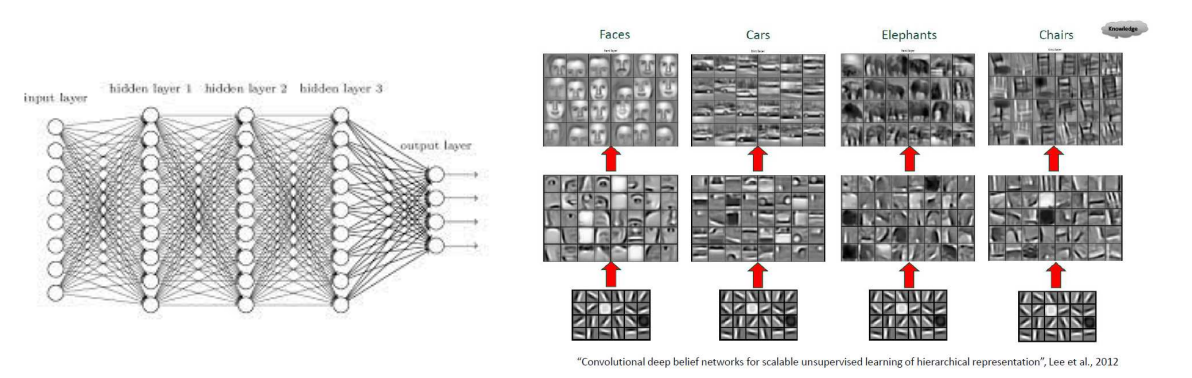
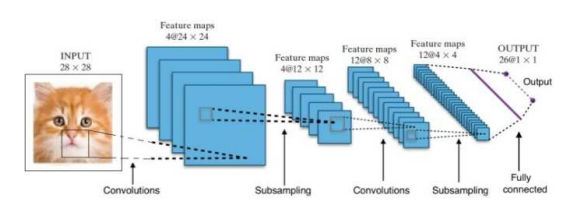
- Convolutional Neural Network(CNN)
기존의 방법은 데이터 -> 지식의 단계로 학습
데이터 -> 특징(feature) -> 지식의 단계로 학습을 시킴
예를 들어 사물인식에 있어서 특징적인 선이나 색을 먼저 추출하여 판단)
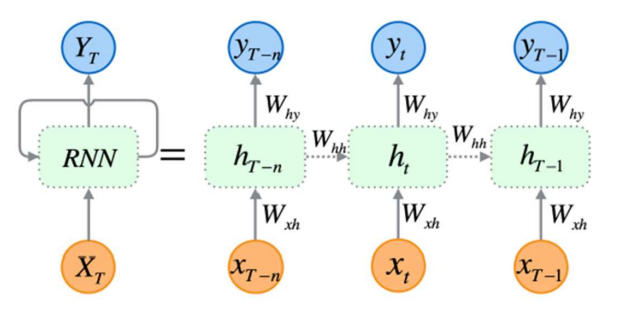
- 시계열 데이터를 위한 Recurrent Neural Network
시계열 데이터 분석에 사용함, 매 순간마다 인공신경망 구조를 쌓아 올린 형태