운 좋게 지원했던 오픈소스 컨트리뷰션에 참여하게 되어, 파이토치 허브 번역 팀에 멘티로 합류하게 되었다. 팀 활동을 위해 미 번역된 모델들을 보던 중 YOLOv5가 아직 번역이 되지 않은 것을 보게 되었다. 현재 회사에서 관련 모델을 사용하고 있어 마침 공부가 필요하던 참에, 개인적인 모델 공부 및 이해와 번역을 동시에 진행할 수 있다면 좋을 것 같아 YOLOv5 번역을 목표로 하기로 했다. 오늘은 이론적인 내용은 전혀 포함하지 않고, Pytorch Hub 및 Github에 올라온 코드를 그대로 실행해 작동 결과를 확인해보는 작업을 하였다.
Baseline 따라가며 맛만 보기
Pytorch Hub YOLOv5 : https://pytorch.kr/hub/ultralytics_yolov5/
Github : https://github.com/ultralytics/yolov5
두 페이지 모두 간단한 YOLOv5 모델 불러오기 및 Inference 예시 코드가 들어있으며, 똑같진 않지만 내용적으로 동일하다. 필자는 둘 중 Github 코드를 사용해보았다.
우선 clone 후 requirements.txt에 따라 환경설정을 진행하였다.
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install이후 model을 불러오고, 예시 Image를 가져와 Inference후 결과를 보는 코드를 구성해놓았다.
import torch
# Model load
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5n - yolov5x6, custom
# Inference를 위한 예시 Images 불러오기
img = 'https://ultralytics.com/images/zidane.jpg' # or file, Path, PIL, OpenCV, numpy, list
# Inference
results = model(img)
# Results
results.print() # or .show(), .save(), .crop(), .pandas(), etc.Image 1장을 가지고 Inference한 결과인 results를 print함으로서, 전처리 시간, Inference 시간, NMS 시간 등 전체적인 처리 시간을 확인할 수 있도록 설계된 것을 볼 수 있다.
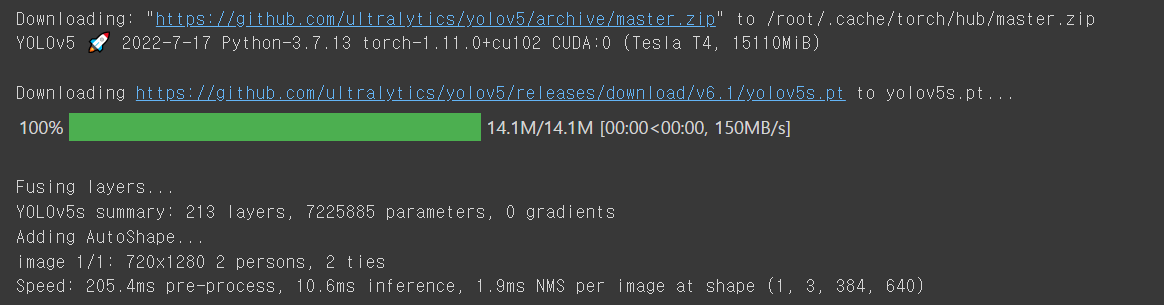
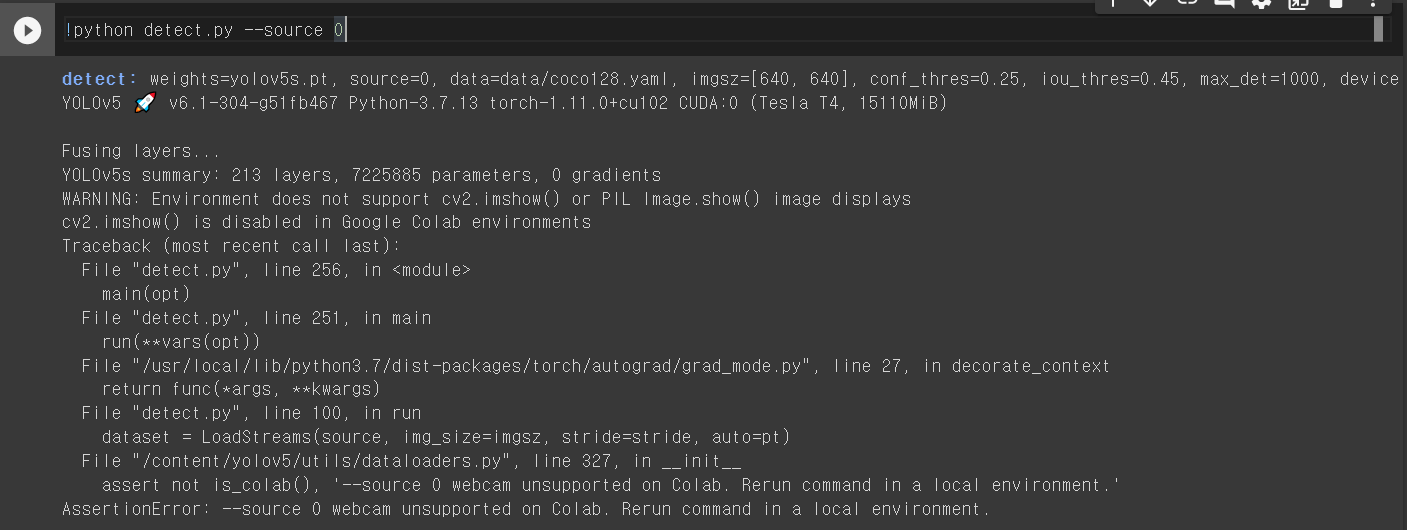
또한 기존에 구현해놓은 detect.py 파일을 이용해 커맨드라인으로 Inference를 진행해 볼 수 있다.
python detect.py --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream하지만 내 실험 환경인 Colab에서는 이를 사용할 수 없었고, local environment에서만 진행 가능한 것으로 보였다. 이는 나중에 모델을 사용할 때 참고해야 할 것 같다.
후기
가이드라인을 직접 따라가서 느낀 점으론,
- YOLOv5 모델을 쉽게 불러올 수 있고, Inference 후 결과를 보기 쉽게 해놓아 사용자가 필요할 때 모델을 사용하기 편리할 것 같다고 생각했다.
- 불러온 모델을 사용자가 직접 학습할 수 있는 가이드라인은 주어지지 않아 아쉬웠고, 가능하다면 이를 추가할 수 있다면 좋을 것 같다.
특정 모델에 대해 직접 코드를 구현하거나 신뢰할 만한 소스코드를 찾아 헤매는 대신, Pytorch Hub라는 신뢰할 만한 사이트에서 빠르게 모델 사용법을 익힐 수 있다는 점에서 Pytorch Hub는 매력적이고 필요한 페이지인 것 같다.
