기존의 성능 좋은 모델들은 대부분 Encoder와 Decoder 구조를 갖는 CNN이나 RNN 모델이었다. 여기서 저자는 CNN이나 RNN 구조를 없애고 attention mechanism만을 적용한 구조를 제안하였다. 이를 통해 성능 향상 뿐만 아니라 병렬화가 가능해져 학습에 더 적은 시간을 필요로 하게 되었다.
해당 논문 이전까지, Language modeling이나 Machine translation 분야에서는 RNN 모델에 encoder + decoder 구조를 적용한 게 SOTA 성능을 기록하였고, recurrent 구조와 encoder + decoder 구조의 한계를 해결하기 위한 연구가 진행되고 있었다.
Recurrent 구조의 근본적인 문제는 Sequential하다는 점인데, 이로 인해 병렬화가 힘들기 때문이다.
이 연구에서 recurrent 구조를 없애고 attention 매커니즘만 사용하는 Transformer 구조를 제안하였다. 이를 통해 병렬화가 가능하고 8대의 P100 GPU로 12시간만 학습해도 SOTA 성능을 달성할 수 있다.
Transformer는 아래 그림과 같이 여러 개의 Self-attention layer를 쌓아 올리고 마지막에 fully connected layer가 있는 식으로 구성된다.
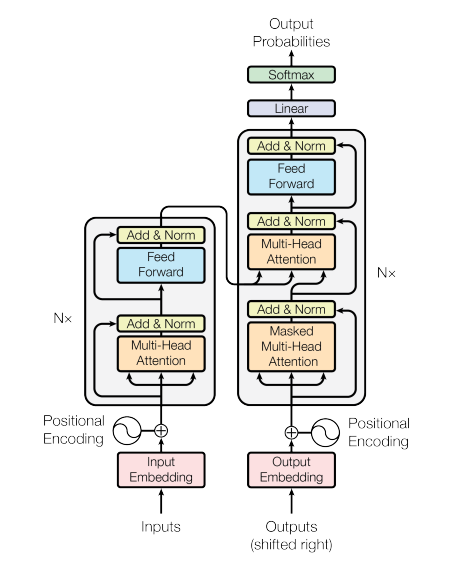
Encoder는 6개의 동일한 layer를 쌓아올린 형태이다. 각 layer는 2개의 sub-layer로 나눌 수 있는데, 첫 번째는 Multi-head self-attention mechanism이고, 두 번째는 Fully connected Feed Forward layer이다.
Decoder 또한 6개의 동일한 layer로 구성되어 있는데, Encoder와 차이점은 Encoder와 같은 구조의 두 sub layer 사이에 encoder의 output에 대해 multi-head self-attention을 수행하는 sub layer를 추가한 점이다.
Attention은 벡터인 query, key, value, output이 있을 때, query와 key-value를 output에 mapping 하는 것을 의미한다.
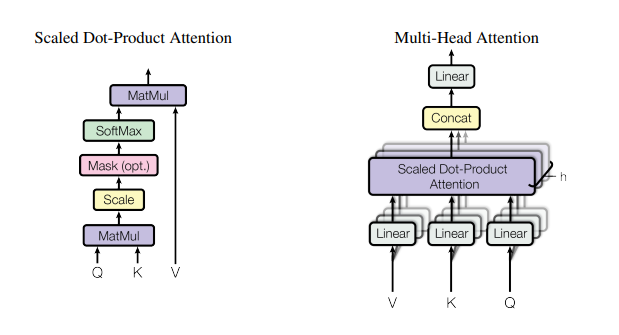
Single attention을 사용하는 대신에 Multi-head attention을 사용하여, 서로 다른 위치의 representational subspace로부터 정보를 attend할 수 있다.

Transformer는 다양한 층에서 Multi-head attention을 적용하여 모든 position에 대해 접근이 가능하도록 하였다.
해당 Transformer 모델을 통해 기계번역과 English constituency parsing과 같은 다른 task에서도 뛰어난 성능을 보였으며, 병렬화를 통해 요구되는 training 시간은 획기적으로 줄이는 데 성공하였다.
