Analytics의 5가지 분석 유형
Descriptive Analytics (기술 분석)
- 정의: 과거 데이터를 요약해 “무슨 일이 일어났는가?”를 설명
- 특징: 대시보드, 리포트 등을 통해 경향과 패턴을 파악
- 사용 예: 웹 트래픽, 매출 리포트, KPI 모니터링 등
Diagnostic Analytics (진단 분석)
- 정의: “왜 그렇게 되었는가?”를 탐구
- 특징: 이상 징후나 경향의 근본 원인을 통계적으로 분석
- 사용 예: 판매 급감의 원인 분석, 품질 이슈 원인 추적 등
Predictive Analytics (예측 분석)
- 정의: 과거 및 현재 데이터를 기반으로 “무슨 일이 일어날 것인가?”를 예측
- 특징: 회귀, 머신러닝, 시계열 모델 등 다양한 기법이 사용
- 사용 예: 수요 예측, 장비 고장 예측, 고객 이탈 예측 등
Prescriptive Analytics (처방 분석)
- 정의: “무엇을 해야 하는가?”를 제안
- 특징: 다양한 시나리오를 시뮬레이션하고 최적 의사결정을 지원
- 사용 예: 가격 최적화, 자원 할당, 치료 전략 결정 등
Cognitive Analytics (인지 분석)
- 정의: AI/ML 기반으로 인간의 사고방식을 모방해 “이해하고 학습하는 분석”
- 특징: 텍스트, 음성, 이미지 등의 비정형 데이터를 처리하며, 패턴 인식과 추론까지 수행
- 사용 예: 감정 분석, 이미지 인식, 자연어 처리 기반 인사이트 도출 등
사용 예제
- Descriptive/Diagnostic
- Azure Monitor + Log Analytics (KQL 기반)로 로그나 운영 데이터를 시각화하고 분석
- Predictive/Prescriptive
- Azure Machine Learning, Synapse Analytics, Databricks 등을 활용해 모델링, 시뮬레이션, 의사결정 최적화
- Cognitive Analytics
- Azure Cognitive Services: Vision, Speech, Language, Decision, Web Search 등의 형식으로 인간적인 인지 기능을 서비스로 제공
요약
| 분석 유형 | 핵심 질문 | 주요 목적 | Azure 연계 서비스 예시 |
|---|---|---|---|
| Descriptive | 무슨 일이 있었나? | 과거 데이터 요약 및 패턴 이해 | Log Analytics, Power BI, Synapse SQL, Dashboards |
| Diagnostic | 왜 그런 일이 발생했나? | 이상 원인 분석 및 근본 원인 규명 | Log Analytics (KQL), Azure Monitor, Power BI |
| Predictive | 무엇이 일어날까? | 미래 예측 | Azure ML, Databricks, Synapse Spark, Time Series |
| Prescriptive | 어떻게 대응할까? | 최적 의사결정, 행동 제안 | Azure ML + 최적화 모델, Synapse, Databricks |
| Cognitive | 데이터를 어떻게 ‘인지’할까? | 비정형 데이터 처리, 인간 유사 분석 수행 | Azure Cognitive Services (Vision, Language 등) |
주요 차트 유형
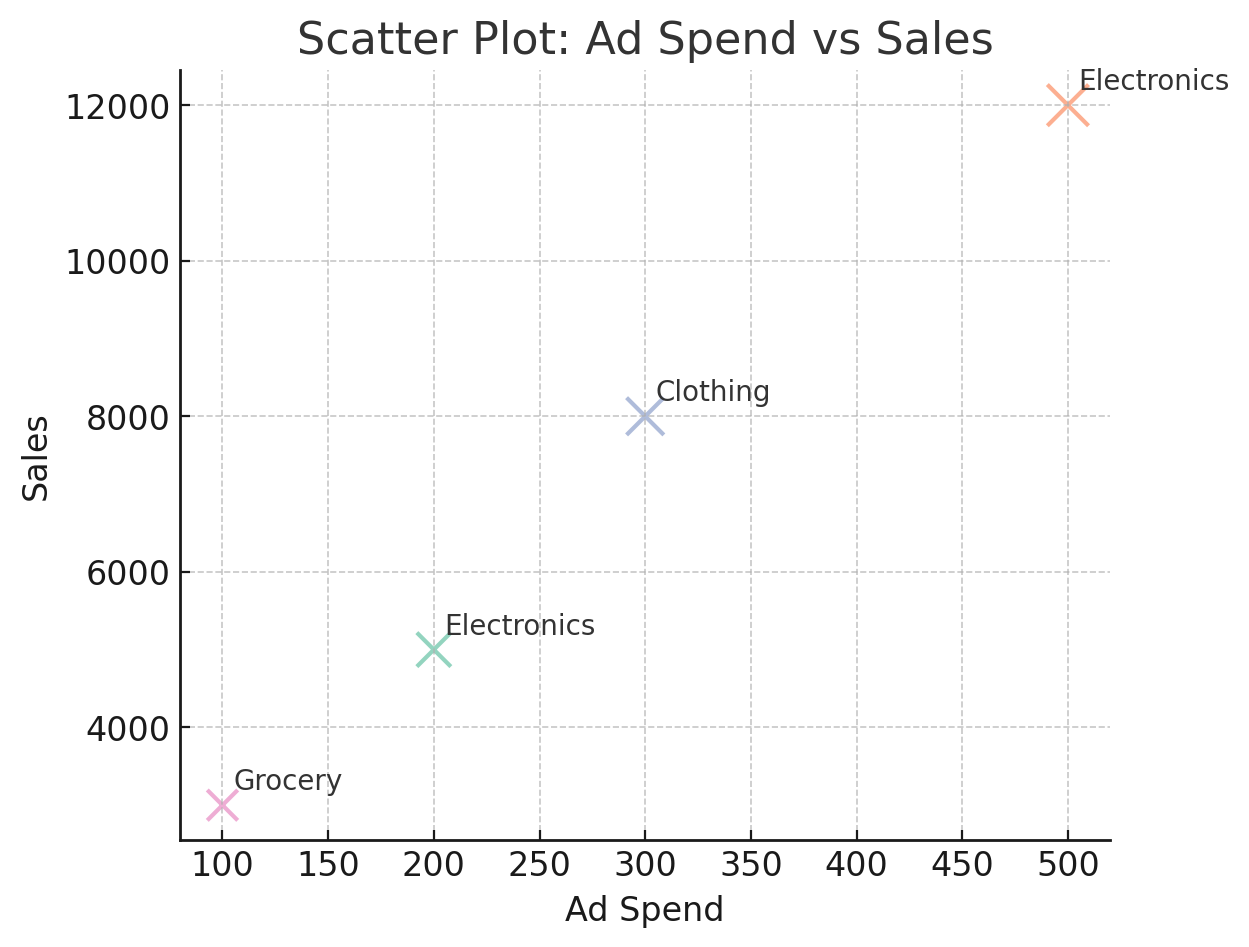
스캐터 차트 (Scatter Chart)
- 정의: 두 개(또는 세 개)의 수치형 변수를 좌표 평면에 점으로 표시하는 시각화.
- 특징:
- X축, Y축에 수치 데이터 배치
- 버블 크기나 색으로 추가 변수 표현 가능
- 예시:
- 매출 vs 광고비:
- X축 = 광고비
- Y축 = 매출액
- 버블 크기 = 고객 수
- → 광고비가 늘어날수록 매출이 어떻게 변화하는지 관계를 한눈에 확인 가능
- 학생 성적 분석:
- X축 = 공부 시간
- Y축 = 시험 점수
- 색상 = 성별
- → 공부 시간과 성적 간의 상관관계를 파악
- 매출 vs 광고비:
트리맵 (Tree Map)
- 정의: 계층적 데이터를 사각형 블록의 크기와 색상으로 표현하는 시각화.
- 특징:
- 크기(Size) = 수치 값 (예: 매출액)
- 색상(Color) = 추가 범주/지표 (예: 이익률, 증가율)
- 계층(Hierarchy) = 상위-하위 분류 가능 (예: 카테고리 → 제품군)
- 예시:
- 소매업 매출 분석:
- 블록 크기 = 제품 매출액
- 색상 = 이익률 (녹색 = 높음, 빨강 = 낮음)
- → 카테고리별 비중 + 수익성을 동시에 파악
- 국가별 인구 분석:
- 크기 = 인구 수
- 색상 = GDP per capita
- → 인구가 많은 국가와 경제 수준을 동시에 비교
- 소매업 매출 분석:
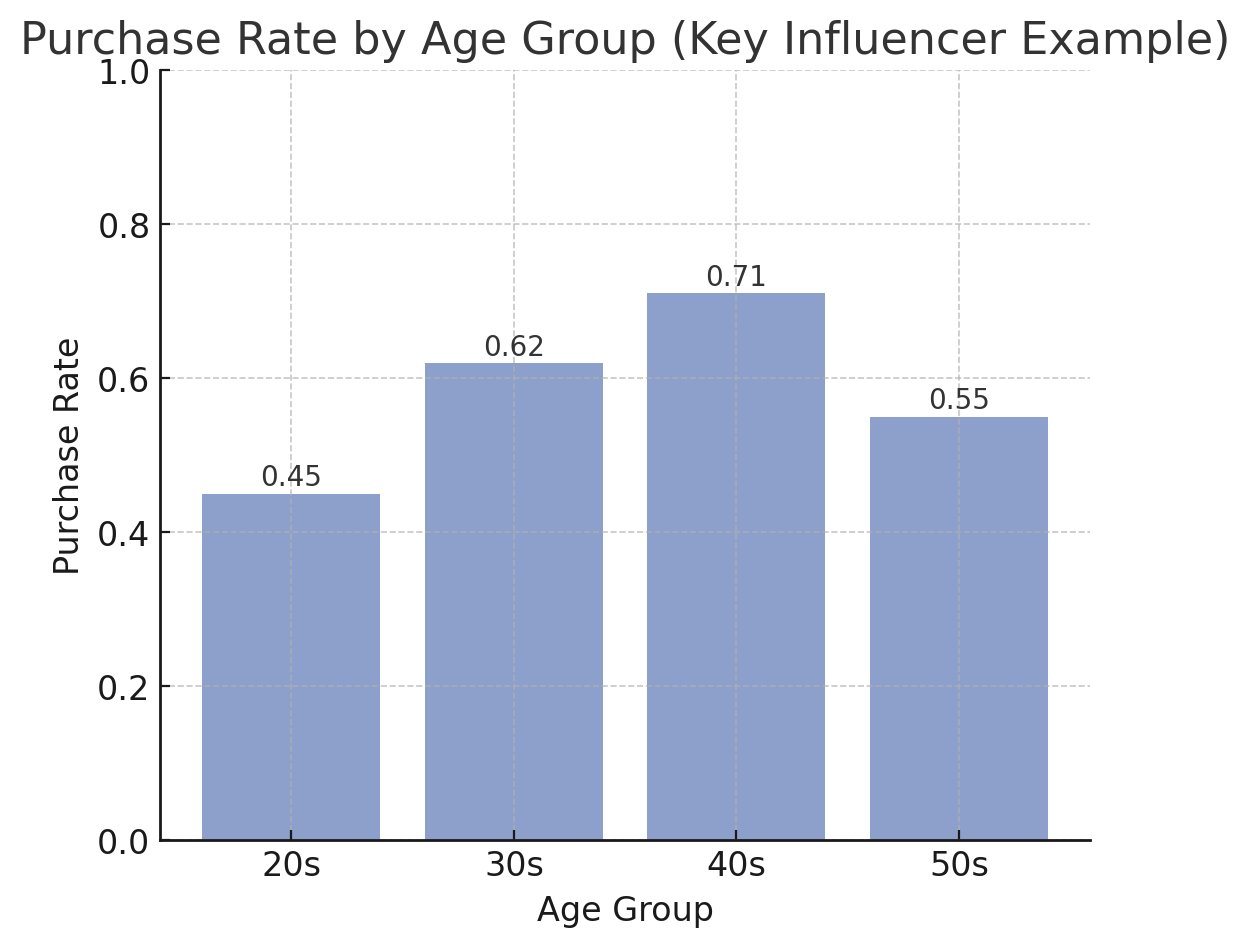
키 인플루언서 (Key Influencer)
- 정의: Power BI의 AI 시각화 기능으로, 특정 결과(타깃 변수)에 영향을 주는 주요 요인을 자동으로 분석하여 보여줌.
- 특징:
- 타깃 필드(예: 구매 여부, 이직 여부)를 지정
- 다른 속성(나이, 지역, 제품 카테고리 등)과의 상관성을 분석
- "어떤 요인이 결과에 가장 크게 영향을 주는가?"를 설명
- 예시:
- 고객 구매 분석:
- 타깃 = "구매 여부" (Yes/No)
- 주요 인플루언서 = "30대 여성", "할인율이 20% 이상", "주말 접속"
- → 구매 확률을 높이는 핵심 요인 자동 도출
- 직원 이직 분석:
타깃 = "퇴사 여부"
주요 인플루언서 = "근속연수 < 2년", "부서 = 영업", "연봉 하위 20%"
* → HR 부서에서 이직 방지 전략 수립에 활용
- 고객 구매 분석:
요약 비교표
| 차트 유형 | 목적 | 데이터 구조 | 예시 |
|---|---|---|---|
| 스캐터 | 두 변수 간 관계 분석 | 수치형(X, Y) + 옵션(크기, 색상) | 광고비 vs 매출 |
| 트리맵 | 계층형 데이터 비율·비교 | 범주형(계층) + 수치형(크기) + 색상 | 제품군별 매출 & 이익 |
| 키 인플루언서 | 결과에 영향을 주는 요인 분석 | 타깃 변수(결과) + 설명 변수들 | 고객 구매 요인, 이직 요인 |
Data 구조
structured data
- 행/열로 이루어진 데이터로 관계형(relational) 데이터라고도 함
- 이상현상(Anomaly behavior)를 제거하기 위해 정규화(normalization)을 수행
- azure SQL DB 사용
Semi structured data
- 일부는 정리되어 있지만 완벽히 구조화 되지 않으며, NoSQL(Not-Only SQL)이라고 불리움
- Azure cosmos DB
Unstructured data
- 어떤 구조도 가지고 있지 않은 데이터로, 평범한 이진파일들이 대표적인 유형
- Azure File, Blob storage 등
OLTP vs OLAP
OLTP (Online Transaction Processing)
- 정의: 온라인 트랜잭션 처리 시스템
- 목적: **실시간 업무 처리(입력·갱신·조회·삭제)**에 최적화
- 특징
- 다수의 사용자 요청(트랜잭션)을 빠르고 안정적으로 처리
- 짧고 빈번한 SQL(INSERT/UPDATE/DELETE)
- 정규화된 스키마 사용 → 데이터 중복 최소화
- 응답 시간(ms~초 단위)이 매우 중요
- 트랜잭션 무결성(ACID) 보장
- 예시
- 은행 계좌 입출금 처리
- 온라인 쇼핑몰 주문
- 항공권 예약 시스템
- 병원 환자 접수·예약
OLAP (Online Analytical Processing)
- 정의: 온라인 분석 처리 시스템
- 목적: 대용량 데이터 분석, 집계, 의사결정 지원에 최적화
- 특징
- 비교적 적은 사용자가 복잡한 쿼리를 수행
- SELECT(집계, 조인, 그룹핑) 위주의 긴 쿼리
- 비정규화/스타 스키마(Star Schema) 또는 스노우플레이크 스키마 사용
- 읽기(조회) 성능 극대화, 다차원 분석 가능
- 응답 시간은 초~분 단위까지 허용
- 예시
- 매출 분석 (지역·시간·상품별 매출 집계)
- 마케팅 캠페인 효과 분석
- 고객 행동 분석
- 경영진 의사결정용 BI 리포트
OLTP vs OLAP 비교 표
| 구분 | OLTP | OLAP |
|---|---|---|
| 목적 | 실시간 업무 처리 | 데이터 분석·의사결정 지원 |
| 사용자 | 다수의 최종 사용자 (직원, 고객 등) | 소수의 분석가, 관리자 |
| 쿼리 유형 | 단순하고 짧음 (INSERT/UPDATE/DELETE) | 복잡하고 길음 (집계, 다중 조인) |
| 데이터 구조 | 정규화(3NF 등) → 중복 최소화 | 비정규화(스타/스노우플레이크 스키마) |
| 데이터 양 | GB ~ TB (작음, 현재 시점 위주) | TB ~ PB (대규모, 역사적 데이터) |
| 응답 속도 | ms ~ 초 단위 | 초 ~ 분 단위 |
| 초점 | 빠른 트랜잭션, 무결성 보장(ACID) | 빠른 읽기/분석 성능, 다차원 분석 |
| 예시 | 은행, 예약 시스템, 쇼핑몰 | BI, 데이터 웨어하우스, 데이터 레이크 |
OLTP와 OLAP의 연결
- OLTP → OLAP
- OLTP에서 발생한 트랜잭션 데이터를 ETL(Extract, Transform, Load) 또는 ELT를 통해 데이터 웨어하우스/데이터 레이크로 적재
- OLAP 환경에서 BI, AI, 예측 분석 등에 활용
- Azure 예시
- OLTP: Azure SQL Database, Cosmos DB
- OLAP: Azure Synapse Analytics, Azure Databricks, Power BI
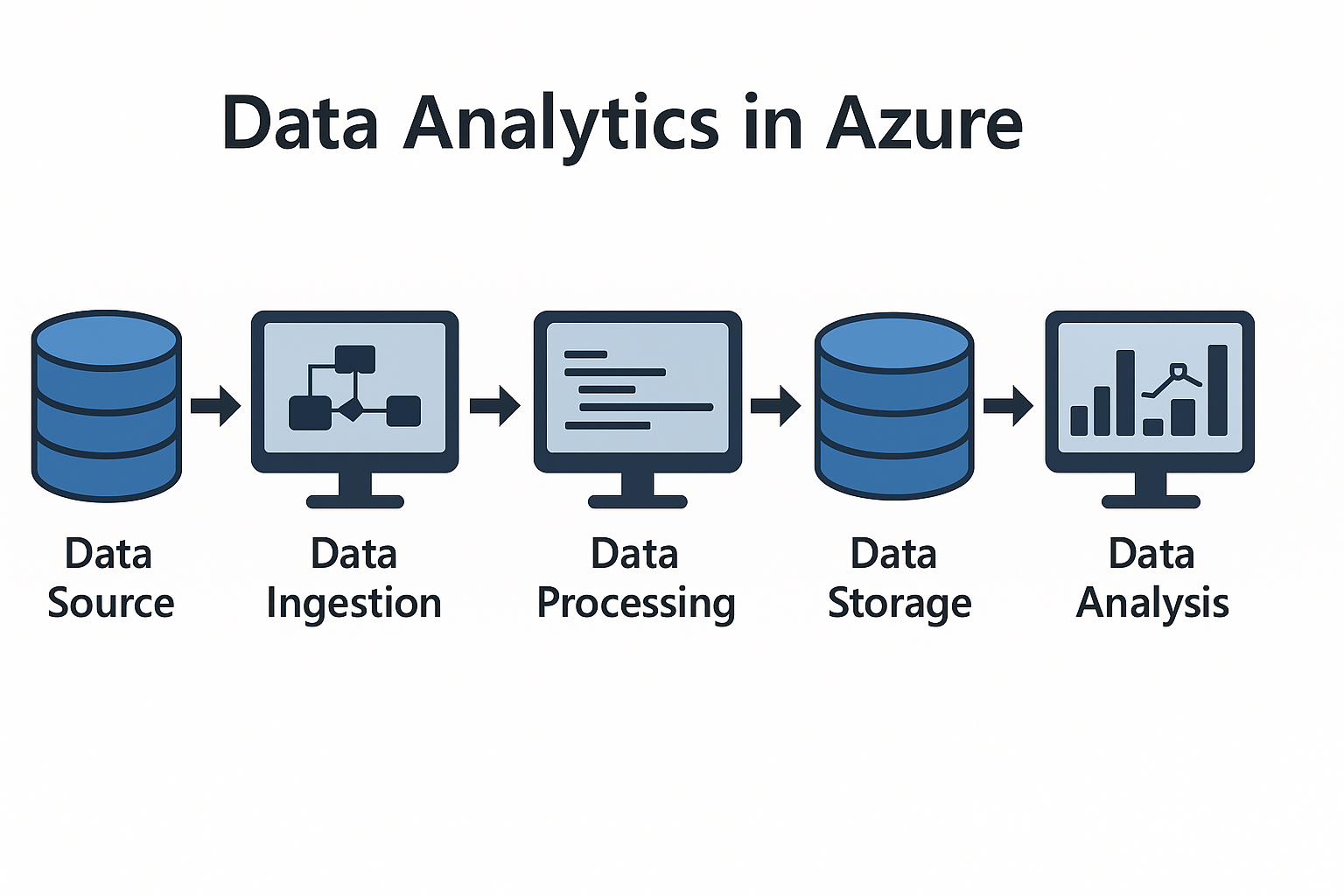
Data pipeline
Data Ingestion (데이터 수집)
- 정의: 다양한 소스에서 발생하는 데이터를 중앙 데이터 플랫폼(예: Data Lake, Data Warehouse, Blob Storage)으로 모으는 과정
- 데이터 소스
- 정형 데이터: RDBMS(SQL Server, Oracle, PostgreSQL 등)
- 반정형 데이터: JSON, XML, CSV, Parquet
- 비정형 데이터: 이미지, 로그, 센서 데이터, 오디오/비디오
- 스트리밍 데이터: IoT 센서, Kafka, Event Hub, 실시간 로그
- 방식
- Batch ingestion: 정해진 주기로 한꺼번에 수집 (예: 하루 1회 매출 데이터 적재)
- Streaming ingestion: 이벤트가 발생하는 즉시 실시간으로 수집 (예: IoT 센서 데이터)
- Azure 주요 서비스
- Azure Data Factory: Batch 기반 ETL/ELT 파이프라인 구축
- Azure Synapse Pipelines: 대용량 분석 환경과 연계
- Azure Event Hubs / IoT Hub: 실시간 이벤트 스트리밍 수집
- Azure Databricks Autoloader: Blob/Data Lake에서 파일 자동 감지·적재
Data Processing (데이터 처리)
- 정의: 수집된 데이터를 정제·변환·집계·분석 가능 형태로 가공하는 과정
- 주요 처리 방식
- ETL (Extract-Transform-Load)
- 원천 시스템 → 추출(Extract) → 변환(Transform) → 적재(Load)
- 전통적인 DW 모델 (SQL 기반, 사전에 스키마 정의)
- 예: Azure Data Factory → Azure SQL DB
- ELT (Extract-Load-Transform)
- 원천 데이터 → Data Lake에 적재(Load) → 필요한 시점에 변환(Transform)
- 현대적인 Big Data / Data Lakehouse 패턴 (Parquet/Delta 기반)
- 예: Data Lake에 Raw Data 저장 → Synapse SQL / Databricks에서 변환
- Batch Processing
- 대량 데이터를 주기적으로 처리 (Hadoop/Spark, Data Factory)
- 예: 하루치 거래 데이터 집계
- Stream Processing
- 실시간 이벤트 처리 (Azure Stream Analytics, Databricks Structured Streaming)
- 예: IoT 센서 이상 탐지, 실시간 Fraud Detection
- ETL (Extract-Transform-Load)
- Azure 주요 서비스
- Azure Data Factory: 대규모 ETL/ELT 처리, 스케줄링
- Azure Synapse Analytics: 대규모 SQL 분석, DW 처리
- Azure Databricks: Spark 기반 Batch/Streaming 처리 + ML Pipeline
- Azure Stream Analytics: 실시간 스트리밍 데이터 처리
- Azure Functions: 이벤트 기반 Serverless 데이터 처리
Data Storage & Serving (저장 및 제공)
- 저장 계층
- Raw Zone: 원천 데이터 그대로 저장 (Blob, Data Lake Gen2)
- Cleansed/Curated Zone: 정제/변환된 데이터 저장 (Parquet/Delta)
- Serving Zone: BI/분석용 Data Warehouse (Synapse, SQL DB)
- Azure 저장 서비스
- Azure Data Lake Storage Gen2: Data Lake용 Blob
- Azure Synapse Analytics: DW + Serverless SQL
- Cosmos DB: NoSQL/글로벌 분산 저장
End-to-End 데이터 파이프라인 (Azure 예시)
- Ingestion (수집)
- IoT 센서 → Event Hub
- ERP/CRM DB → Data Factory → Blob(Data Lake)
- Processing (처리)
- 실시간 데이터 → Stream Analytics/Databricks → Delta Lake 저장
- Batch 데이터 → ADF/Databricks로 변환 후 Synapse 적재
- Storage (저장)
- 원본은 Data Lake Raw Zone
- 정제본은 Curated Zone (Parquet/Delta)
- 분석용은 Synapse DW
- Serving (제공)
- BI 도구(Power BI)로 리포트 및 대시보드 제공
- ML 모델 → Azure ML → 예측 API 제공
요약 테이블
| 단계 | 설명 | Azure 서비스 예시 |
|---|---|---|
| Ingestion | 데이터 소스에서 Blob/Data Lake로 수집 (Batch/Streaming) | Data Factory, Event Hubs, IoT Hub |
| Processing | 변환·정제·집계 (Batch/Stream, ETL/ELT) | Data Factory, Databricks, Stream Analytics |
| Storage | Raw/Curated/Serving Zone으로 저장 | Data Lake Gen2, Synapse, Cosmos DB |
| Serving | 분석/리포트/예측 제공 | Power BI, Synapse, Azure ML, API Apps |
ETL vs ELT
ETL (Extract – Transform – Load)
- 흐름
- Extract: 원천 시스템에서 데이터를 추출
- Transform: 별도의 ETL 엔진(전용 서버/도구)에서 변환 (정제, 집계, 스키마 변경 등)
- Load: 변환된 데이터를 최종 타깃(예: Data Warehouse)에 적재
- 특징
- 전통적인 데이터 웨어하우스 아키텍처에서 많이 사용
- DW에 적재되는 데이터는 이미 변환/정제된 상태 → 즉시 사용 가능
- 변환 작업이 ETL 서버에서 수행되므로 DW의 부하가 적음
- 하지만 데이터가 커질수록 ETL 서버에 부하 집중
- 장점
- DW가 깔끔하고, 불필요한 원본 데이터 저장 X
- 보안/품질 관리 용이
- 단점
- 대규모 데이터 처리 시 ETL 서버 병목 발생
- 변환 작업을 추가/수정하면 재처리 비용 ↑
- 원천 데이터 원본 보존 어려움
- Azure 관련 서비스
- Azure Data Factory (ETL 도구 역할)
- SSIS on Azure (SQL Server Integration Services)
ELT (Extract – Load – Transform)
- 흐름
- Extract: 원천 시스템에서 데이터를 추출
- Load: 원천 데이터를 Data Lake / DW에 먼저 적재
- Transform: 변환/정제 작업을 DW나 Data Lake 엔진에서 직접 수행
- 특징
- 클라우드·빅데이터 시대에 주로 사용
- 원본 데이터를 Raw Zone에 보존 → 유연하게 재처리 가능
- DW/데이터레이크의 대규모 분산 처리 성능 활용 가능 (Spark/SQL 엔진)
- 장점
- 확장성, 대용량 데이터 처리에 유리
- 원본 데이터 보존 → 다양한 목적(재분석, 머신러닝 등)에 재사용 가능
- 변환 로직을 클라우드 엔진(Synapse, Databricks)에서 실행하므로 성능 최적화
- 단점
- DW/데이터레이크에 변환 부하 발생
- 보안/규제 환경에서 원본 데이터 저장에 제약 가능
- Azure 관련 서비스
- Azure Data Lake Storage (Gen2) → 원본 데이터 적재
- Azure Synapse Analytics (SQL, Serverless) → 변환/쿼리
- Azure Databricks (Spark 기반) → 대규모 변환
비교 요약
| 구분 | ETL | ELT |
|---|---|---|
| 순서 | Extract → Transform → Load | Extract → Load → Transform |
| 변환 위치 | ETL 서버/중간 엔진 | DW/데이터 레이크 내 (분산 엔진) |
| 데이터 적재 형태 | 변환된 데이터만 보관 | 원본 데이터 + 변환 데이터 모두 보관 |
| 장점 | DW 성능 부담 적음 품질 관리 용이 | 대규모 데이터 확장성 원본 보존, 유연성 ↑ |
| 단점 | 대규모 처리 시 ETL 병목 | DW/레이트에 부하 발생 |
| 적합 환경 | 전통적 온프레 DW | 클라우드/빅데이터 플랫폼 |
| Azure 서비스 | Data Factory, SSIS | Data Factory + Synapse, Databricks, Data Lake |
- ETL = 변환 후 적재 (전통적 방식, DW 중심)
- ELT = 적재 후 변환 (클라우드/빅데이터 시대 표준)
RDB (Relational Database, 관계형 데이터베이스)
개요
- 정의: 데이터를 **행(Row)과 열(Column)**로 구성된 **테이블(Table)**에 저장하고, 테이블 간 **관계(Relationship, PK/FK)**를 기반으로 관리하는 데이터베이스.
- 특징
- 정형 데이터 저장에 강함
- ACID 트랜잭션 보장 (Atomicity, Consistency, Isolation, Durability)
- SQL이라는 표준 질의 언어 사용
- 데이터 중복 최소화를 위해 정규화 활용
- 대표 제품
- 오픈소스: MySQL, PostgreSQL, MariaDB
- 상용: Oracle DB, Microsoft SQL Server, IBM Db2
- 클라우드: Azure SQL Database, Amazon RDS, Google Cloud SQL
Index (색인)
Clustered Index (클러스터형 인덱스)
- 정의: 실제 데이터(테이블의 행)가 인덱스 키 순서에 맞게 정렬·저장되는 인덱스
- 특징
- 테이블당 1개만 생성 가능 (데이터 자체의 물리적 정렬 방식이 되기 때문)
- 인덱스 = 데이터 → 검색 속도가 매우 빠름
- 주로 Primary Key가 기본적으로 Clustered Index가 됨
- 장점
- 범위 검색(예: 날짜 범위)에서 효율적
- 단점
- 데이터 삽입/갱신 시 정렬 유지 부담 → 쓰기 성능 저하
Non-clustered Index (비클러스터형 인덱스)
- 정의: 인덱스 페이지에 데이터 위치 포인터(RID, Row Identifier)만 저장, 실제 데이터는 별도로 존재
- 특징
- 테이블당 여러 개 생성 가능
- 인덱스 키 + 데이터 위치(포인터) 구조
- 장점
- 특정 컬럼 기반 조회 최적화 가능
- 다양한 쿼리 패턴 대응 가능
- 단점
- 인덱스 → 포인터 → 실제 데이터 접근하는 과정이 필요 → I/O 오버헤드
View (뷰)
- 정의: 하나 이상의 테이블/쿼리를 기반으로 만들어진 가상 테이블
- 특징
- 물리적으로 데이터가 저장되지 않고, 쿼리 실행 시 결과를 반환
- 보안/권한 관리(특정 컬럼만 노출), 복잡한 쿼리 단순화에 사용
- 종류
- 단순 뷰: 하나의 테이블 기반
- 복합 뷰: 여러 테이블 조인/집계 기반
- Indexed View (Materialized View, SQL Server/Oracle): 실제 데이터가 저장·갱신됨 → 성능 최적화 가능
SQL (Structured Query Language)
- 정의: RDB를 다루기 위한 표준 질의 언어
- 분류
- DDL (Data Definition Language): 스키마 정의
CREATE,ALTER,DROP
- DML (Data Manipulation Language): 데이터 조작
SELECT,INSERT,UPDATE,DELETE
- DCL (Data Control Language): 권한 제어
GRANT,REVOKE
- TCL (Transaction Control Language): 트랜잭션 제어
COMMIT,ROLLBACK,SAVEPOINT
- DDL (Data Definition Language): 스키마 정의
배포 옵션 (Deployment Options)
온프레미스(On-Premise)
- 자체 서버에 DB 설치·운영
- 장점: 보안/성능 제어권 높음
- 단점: 인프라 관리 부담, 초기 비용 큼
클라우드 IaaS (Infrastructure as a Service)
- VM에 RDBMS 설치 (예: Azure VM + SQL Server)
- 장점: 기존 라이선스/구성 재사용 가능
- 단점: 관리 부담은 여전히 존재
클라우드 PaaS (Platform as a Service)
- DB를 서비스로 제공받음 (예: Azure SQL Database, Amazon RDS)
- 장점: 패치/백업/가용성 자동 관리
- 단점: 커스터마이징 제한
클라우드 분산/대규모 분석용
- Azure Synapse Analytics, Amazon Redshift, Google BigQuery
- OLAP 워크로드 중심, 대규모 병렬 처리(MPP) 지원
요약
| 구분 | 설명 | 예시 |
|---|---|---|
| RDB | 관계형 데이터베이스, 정규화·SQL 기반 | Oracle, PostgreSQL, SQL Server |
| Clustered Index | 데이터 자체가 인덱스 순서대로 저장 | PK 인덱스 |
| Non-clustered Index | 인덱스 + 포인터 구조, 다수 생성 가능 | 검색 최적화 인덱스 |
| View | 가상 테이블, 쿼리 재사용·보안 용이 | 단순 뷰, Indexed View |
| SQL | 데이터 정의·조작 언어 | DDL, DML, DCL, TCL |
| 배포 옵션 | 온프레미스/클라우드(IaaS, PaaS, MPP) | Azure SQL DB, Synapse, RDS |
Azure SQL Database vs Azure SQL Data Warehouse
Azure SQL Database
- 정의: Microsoft SQL Server 기반의 완전 관리형(Relational) PaaS DB
- 성격: OLTP (Online Transaction Processing)에 최적화
- 특징
- 수천~수만 건의 트랜잭션을 실시간으로 처리 가능
- 단일 데이터베이스, 탄력적 풀(Elastic Pool), Hyperscale 등 다양한 배포 옵션
- 자동 백업, 자동 패치, 고가용성(HA) 기본 제공
- ACID 트랜잭션 보장, JSON 지원, T-SQL 지원
- 활용 사례
- 전자상거래 주문 처리
- 은행 계좌 거래
- CRM/ERP 운영 DB
- 모바일/웹 애플리케이션 백엔드
Azure SQL Data Warehouse (현 Synapse Dedicated SQL Pool)
- 정의: 대규모 데이터 분석을 위한 MPP(Massively Parallel Processing) 기반 Data Warehouse 서비스
- 성격: OLAP (Online Analytical Processing)에 최적화
- 특징
- 수십~수백 TB 이상의 데이터 처리 가능
- 분산 저장소 + 분산 컴퓨팅 구조 → 병렬 쿼리 실행
- 스타 스키마/스노우플레이크 스키마 기반 분석 최적화
- 대규모 집계, 조인, BI 시나리오에 강함
- 컴퓨팅과 스토리지를 독립적으로 확장 가능
- 활용 사례
- 매출/고객/물류 데이터 분석
- 경영진 리포트 및 BI 대시보드
- 머신러닝을 위한 대규모 데이터 준비
- IoT/로그 데이터 분석
비교 요약
| 구분 | Azure SQL Database | Azure SQL Data Warehouse (Synapse Dedicated SQL Pool) |
|---|---|---|
| 주요 목적 | 트랜잭션 처리(OLTP) | 데이터 분석(OLAP) |
| 워크로드 | 다수의 짧은 쿼리 (INSERT/UPDATE/SELECT) | 적은 사용자, 복잡한 분석 쿼리 (집계/조인) |
| 데이터 크기 | GB ~ 수 TB | 수십 TB ~ PB |
| 데이터 구조 | 정규화 스키마 중심 | 스타/스노우플레이크 스키마 |
| 확장 방식 | 수직 확장 (DTU/vCore 기반) | 수평 확장 (MPP, 분산 노드) |
| 강점 | 실시간 트랜잭션 성능, 관리 자동화 | 대규모 분석 성능, 병렬 처리 |
| Azure 대체/연계 서비스 | Cosmos DB(글로벌 분산 NoSQL), Managed Instance | Synapse Serverless SQL, Databricks |
- OLTP 데이터(운영 DB)는 Azure SQL Database에 저장
- 일정 주기(배치/실시간)로 데이터를 Data Lake나 Synapse Data Warehouse로 이동 (ETL/ELT)
- 분석/BI는 Synapse, Power BI에서 수행
- 즉, 운영과 분석을 분리(Separation of Concerns)하여 성능과 비용 최적화
인터넷에서 데이터베이스 쿼리 실행을 위한 필수 조건
사용자 계정 (Authentication)
- 필수 요소
- 데이터베이스에 사용자 계정이 존재해야 함
- 해당 계정은 올바른 자격 증명(아이디/비밀번호)을 보유해야 함
- Azure SQL Database 기준
- 서버 수준 로그인 (SQL Server admin)
- 데이터베이스 사용자 계정 (개별 DB 단위)
- Azure AD 계정 기반 인증도 가능 (권장 보안 방식)
권한 (Authorization)
- 필수 요소
- 쿼리를 실행하려면 대상 테이블에 대한 SELECT 권한이 있어야 함
- 다른 작업(INSERT, UPDATE, DELETE, EXECUTE 등)을 하려면 해당 권한도 부여 필요
- 예시 SQL 명령
GRANT SELECT ON [TableName] TO [UserName];
네트워크 접근 (Firewall & IP 허용)
- 필수 요소
- 클라이언트의 IP 주소가 데이터베이스 서버 방화벽 규칙에 허용되어야 함
- Azure SQL Database 기준
- Azure Portal 또는 Azure CLI를 통해 방화벽 규칙 설정
- 정적 IP일 경우 해당 IP를 허용
- 동적 IP 환경에서는 0.0.0.0 설정 가능하지만 보안상 권장되지 않음
- 사설망 접근 시 Private Endpoint를 활용하는 것이 권장
요약 정리
| 구분 | 필수 조건 | Azure SQL Database 예시 |
|---|---|---|
| 사용자 계정 | DB에 사용자 존재, 올바른 인증 정보 필요 | SQL 로그인 / Azure AD 계정 |
| 권한 | SELECT 등 필요한 권한 부여 | GRANT SELECT ON Sales TO user1; |
| 네트워크 접근 | 방화벽 규칙에서 IP 허용 필요 | 포털/CLI에서 클라이언트 IP 추가 |
인터넷에서 DB 쿼리를 실행하려면
1. 인증(Authentication) = 사용자 계정 필요
2. 권한(Authorization) = 대상 오브젝트 권한 필요
3. 네트워크 접근(Network Access) = 방화벽/IP 허용 필요
NoSQL 데이터 모델별 주요 타입
Key-Value Store
- 예시: Redis, DynamoDB, Azure Table Storage
- 데이터 타입
- Key: 문자열 (Unique Identifier)
- Value: 단일 값 또는 직렬화된 객체
- Value 지원 타입 (Redis 기준)
- String (문자열, 숫자)
- List (순서 있는 배열)
- Set (중복 없는 집합)
- Sorted Set (정렬된 집합)
- Hash (Key-Value 쌍의 집합, 객체 구조 표현 가능)
Document Store
- 예시: MongoDB, CouchDB, Cosmos DB (Core API)
- 데이터 타입
- 문자열(String)
- 숫자(Number) (정수, 부동소수점)
- Boolean (true/false)
- Date/Time
- Null
- 배열(Array)
- 객체(Document/Embedded Object)
- 이진 데이터(Binary Data) (BSON의 경우 ObjectId, Binary 등 특수 타입 포함)
- 특징
- JSON/BSON 구조 기반 → 계층적 데이터 저장
- 동적 스키마 (필드 추가/삭제 자유로움)
Column-Family Store
- 예시: Cassandra, HBase, ScyllaDB
- 데이터 타입
- 문자열(String), 숫자(Int, BigInt, Float 등), Boolean, UUID, Timestamp 등
- 컬럼 단위로 데이터 타입 지정 가능 (스키마 유연)
- 특징
- Row Key + Column Family + Column 조합으로 저장
- 하나의 Row에 수천 개 이상의 컬럼을 둘 수 있음
Graph Database
- 예시: Neo4j, Cosmos DB (Gremlin API), Amazon Neptune
- 데이터 타입
- 노드(Node)와 관계(Relationship)에 **속성(Property)**을 Key-Value 쌍으로 저장
- 문자열, 숫자, Boolean, DateTime, Array 등 지원
- 특징
- 데이터 타입보다는 관계(Edge) 표현에 초점
- 그래프 탐색 쿼리(Cypher, Gremlin) 활용
요약 표
| NoSQL 유형 | 예시 DB | 주요 데이터 타입 |
|---|---|---|
| Key-Value Store | Redis, DynamoDB | String, List, Set, Sorted Set, Hash, Binary |
| Document Store | MongoDB, CouchDB | String, Number, Boolean, Date, Array, Object, Binary |
| Column-Family Store | Cassandra, HBase | String, Int/BigInt, Float, Boolean, UUID, Timestamp |
| Graph Database | Neo4j, Cosmos DB (Gremlin) | Node/Edge Property: String, Number, Boolean, Date, Array |
- Key-Value → 단순하고 빠름 (캐시, 세션 저장소)
- Document → JSON/BSON 기반, 복잡한 계층 구조 저장 (앱 데이터, 카탈로그)
- Column-Family → 대규모 시계열/로그/IoT 데이터에 강점
- Graph → 관계 중심 분석 (추천 시스템, 소셜 네트워크)
NoSQL의 데이터 타입은 저장 모델에 따라 다양하지만, 공통적으로 문자열·숫자·Boolean·날짜·배열·객체 같은 기본 타입을 지원하고, 각 엔진별로 특수 타입(UUID, Binary, ObjectId 등)이 추가된다.
NoSQL 솔루션
IaaS 기반 NoSQL 처리
- 설명: 사용자가 VM을 만들고 직접 NoSQL 엔진을 설치/운영
- 예시 시나리오
- VM에 MongoDB, Cassandra, Redis, Neo4j 직접 설치
- 데이터 스토리지/백업/보안/패치 모두 직접 관리
- 장점
- 원하는 NoSQL 엔진을 자유롭게 선택 가능
- 설정 및 최적화를 세밀하게 제어 가능
- 단점
- 유지보수·확장성 부담이 큼
- Azure 서비스
- Azure Virtual Machines (Linux/Windows)
- Azure Managed Disks + Blob Storage(백업/저장소)
Azure Marketplace 제공 매니지드 OSS (Partially Managed)
- 설명: 파트너/커뮤니티가 제공하는 매니지드 NoSQL 솔루션 사용
- 예시
- Bitnami MongoDB / Cassandra / Redis 이미지
- Confluent Kafka on Azure
- 특징
- 설치/기본 설정 자동화, 운영 편의성 제공
- 여전히 일부 관리(스케일링, 패치)는 사용자가 해야 함
완전 관리형 PaaS (Azure Native Services)
Azure는 주요 **NoSQL 패턴(문서, 키-값, 그래프, 컬럼)**을 커버하는 매니지드 서비스를 제공
Azure Cosmos DB
- 멀티모델 NoSQL DB (글로벌 분산, SLA 보장)
- 지원 API:
- SQL(Core API) → 문서형(JSON 기반)
- MongoDB API → Mongo 호환 문서형
- Cassandra API → 컬럼 패밀리형
- Gremlin API → 그래프 DB
- Table API → 키-값 (Azure Table Storage 호환)
- 특징
- 글로벌 리플리케이션, 멀티마스터, 99.999% SLA
- 자동 스케일링(서버리스 옵션 제공)
- 활용
- IoT 데이터 저장
- 전자상거래 카탈로그
- 사용자 프로필/세션 저장
Azure Cache for Redis
- 인메모리 Key-Value 저장소
- 사용 예: 세션 캐시, 실시간 순위표, Pub/Sub 메시징
Azure Table Storage
- 간단한 Key-Value/NoSQL 스토리지 (Cosmos DB Table API와 유사)
- 저비용, 단순 로그/메타데이터 저장에 적합
데이터 레이크 및 비정형 데이터 처리
- Azure Data Lake Storage Gen2 (ADLS Gen2)
- HDFS 호환 Blob 스토리지
- JSON, Avro, Parquet 같은 반정형 데이터 저장
- Azure Blob Storage
- 이미지, 동영상, 로그 등 비정형 데이터 저장
- Azure Synapse Analytics
- Cosmos DB, Data Lake와 연계해 분석 (Serverless SQL, Spark)
- Azure Databricks
- NoSQL + 비정형 데이터 ETL/ELT 및 AI/ML 모델 학습
SaaS/Serverless Integration
- Azure Cognitive Search
- Cosmos DB, Blob Storage 연동 → 문서/텍스트/이미지 검색
- Azure Cognitive Services
- 비정형 데이터(텍스트, 음성, 이미지, 비디오)에서 AI 인사이트 추출
- Azure Functions
- 서버리스 방식으로 NoSQL 이벤트 트리거 처리 (예: Cosmos DB Change Feed → 실시간 이벤트 처리)
요약 표
| 계층 | 방식 | 예시 서비스 | 활용 |
|---|---|---|---|
| IaaS | VM 설치형 | Azure VM + MongoDB/Cassandra | 직접 제어, 커스터마이징 |
| Marketplace | Semi-managed | Bitnami MongoDB, Confluent Kafka | 빠른 배포, 일부 관리 자동화 |
| PaaS | 완전 관리형 | Cosmos DB, Redis, Table Storage | 운영 관리 최소화, SLA 보장 |
| 데이터 레이크/분석 | 비정형/반정형 처리 | Data Lake Gen2, Blob, Databricks, Synapse | 대규모 분석, ML |
| SaaS/Serverless | AI/검색/이벤트 | Cognitive Services, Cognitive Search, Functions | 비정형 데이터 인사이트, 이벤트 기반 처리 |
Azure Table Storage
개요
- 정의: Azure Storage 서비스의 한 구성 요소로, Key-Value 기반 NoSQL 저장소
- 특징
- 스키마리스(Schema-less): 테이블 구조는 있지만 각 엔터티(Entity)는 자유롭게 다른 속성 보유 가능
- 확장성: 수십억 개의 행(Row), TB~PB 규모 데이터 저장 가능
- 저비용: 대량 데이터 저장에 적합
- REST API, OData, SDK(.NET, Java, Python 등)로 접근 가능
데이터 구조
- Table: 데이터 저장 단위 (RDB의 테이블과 유사)
- Entity: 한 행(Row)에 해당, Key-Value 쌍의 집합
- Properties: 엔터티 내의 컬럼 (각 속성은 문자열, 정수, 날짜, GUID 등)
주요 키
- PartitionKey
- 테이블 내 데이터를 논리적 파티션으로 나누는 키
- 동일 PartitionKey를 가진 엔터티는 함께 저장 → 쿼리 및 트랜잭션 성능 최적화
- RowKey
- 파티션 내 엔터티를 고유하게 식별하는 키
- Timestamp
- 시스템에서 자동 생성/갱신되는 엔터티의 마지막 수정 시간
따라서 PartitionKey + RowKey 조합이 Primary Key 역할을 수행합니다.
지원 데이터 타입
- String
- Int64 (long)
- Double
- Boolean
- DateTime
- GUID
- Binary
장점
- 저비용: 대규모 데이터 저장 시 경제적
- 확장성: 자동 샤딩(PartitionKey 기반)으로 대규모 확장 가능
- 유연성: 스키마 변경 없이 속성 추가 가능
- Azure 서비스 연계: Blob/Table/Queue 등과 함께 통합된 Azure Storage 계정 내에서 운영
단점
- 복잡한 쿼리 불가 (조인, 집계, 외래키 없음)
- 쿼리는 주로
PartitionKey또는RowKey기준으로 최적화됨 - 트랜잭션은 동일 파티션 내 엔터티에만 지원
- 고급 NoSQL 기능(인덱스, 집계, 트리거 등)은 미지원
활용 사례
- 사용자 프로필 저장 (Key = UserId)
- IoT/로그 데이터 저장 (PartitionKey = DeviceId, RowKey = Timestamp)
- 메타데이터/설정 값 관리
- 단순 조회 중심의 대량 데이터 저장
Azure Table Storage vs Cosmos DB Table API
- Azure Table Storage
- 저비용, 단순한 NoSQL Key-Value 저장소
- SLA, 글로벌 분산 기능 제한적
- Azure Cosmos DB Table API
- Table Storage API와 호환
- 글로벌 분산, 낮은 지연 시간, 99.999% SLA 보장
- 자동 인덱싱 지원
요약
| 구분 | 특징 |
|---|---|
| 저장 모델 | Key-Value (NoSQL, 스키마리스) |
| 키 구조 | PartitionKey + RowKey (고유 식별자) |
| 데이터 타입 | String, Int64, Double, Boolean, DateTime, GUID, Binary |
| 장점 | 저비용, 확장성, 유연성 |
| 제약 | 복잡한 쿼리 불가, 파티션 범위 내 트랜잭션만 가능 |
| 대안 | 고급 기능 필요 시 Cosmos DB Table API 사용 |
Azure Table Storage는 간단하고 저렴한 NoSQL Key-Value 저장소로, 대규모 비정형/반정형 데이터를 빠르고 싸게 저장하는 데 적합하지만 분석·고급 기능이 필요하다면 Cosmos DB Table API로 확장하는 것이 권장
Azure Cosmos DB
개요
- 정의: Microsoft Azure에서 제공하는 글로벌 분산형, 완전 관리형 NoSQL 데이터베이스 서비스
- 특징
- 멀티모델(Multi-model): 문서, 키-값, 그래프, 컬럼 패밀리 등 다양한 데이터 모델 지원
- 멀티 API: SQL(Core), MongoDB, Cassandra, Gremlin(Graph), Table API 지원
- 글로벌 분산(Global Distribution): 전 세계 여러 리전에 데이터 자동 복제
- 수평 확장성: 자동 샤딩(Partition Key) 기반 확장
- SLA 보장: 가용성, 지연 시간(밀리초 단위), 처리량, 내구성까지 SLA 제공
데이터 모델 & API
Cosmos DB는 여러 NoSQL 워크로드를 하나의 서비스에서 지원
- SQL(Core API)
- JSON 문서 저장
- SQL과 유사한 쿼리 언어 지원
- MongoDB API
- MongoDB 프로토콜 호환
- MongoDB 클라이언트/드라이버로 접근 가능
- Cassandra API
- 컬럼 패밀리 기반 (CQL 지원)
- Cassandra 워크로드와 호환
- Gremlin API
- 그래프 데이터 모델 (노드/엣지 + 속성)
- Gremlin 쿼리 언어로 탐색 가능
- Table API
- Azure Table Storage 호환
- Key-Value 기반
주요 개념
- Container: 데이터 저장 단위 (SQL API에서는 Collection, Mongo API에서는 Collection, Cassandra API에서는 Table)
- Item: JSON 문서 혹은 행(Row)에 해당
- Partition Key: 데이터를 파티션 단위로 나누어 수평 확장
- Throughput (RU/s, Request Unit per second): 성능 단위
- 쿼리, 쓰기, 읽기 작업이 모두 RU 단위로 과금/제한
주요 기능
- 글로벌 분산
- 원하는 Azure 리전에 버튼 클릭으로 데이터 복제
- 다중 쓰기(Multi-master) 지원 → 어느 리전에서든 읽기/쓰기 가능
- 일관성 모델 (Consistency Levels)
- Strong (강한 일관성)
- Bounded Staleness (지연된 강한 일관성)
- Session (세션 단위 일관성, 기본값)
- Consistent Prefix (쓰기 순서 보장)
- Eventual (최종 일관성)
- 자동 인덱싱
- 스키마 정의 없이 모든 속성 인덱싱
- 필요 시 인덱스 정책 조정 가능
- 보안
- RBAC, Key 인증, Azure AD 통합
- 암호화(저장/전송 중) 기본 제공
장점
- 글로벌 분산 + 멀티마스터
- 밀리초 단위 읽기/쓰기 지연 시간
- 다양한 API → 기존 워크로드 이전 용이
- 완전 관리형 → 패치, 백업, 확장 자동화
- AI/ML, 실시간 분석 파이프라인과 연계 용이
단점
- RDBMS처럼 복잡한 조인/트랜잭션 지원은 제한적 (단일 파티션 내 트랜잭션은 가능)
- 비용 구조가 RU 기반이라 설계/쿼리 최적화 필요
- 관계형 DB 스키마 기반 분석에는 부적합 (Synapse 등과 연계 필요)
활용 사례
- IoT: 센서 데이터 수집/실시간 처리
- e-Commerce: 사용자 프로필, 장바구니, 주문 이벤트 저장
- 게임: 플레이어 상태, 리더보드, 인벤토리 관리
- 금융/리테일: 실시간 Fraud Detection, 트랜잭션 로그
- 추천 시스템: 그래프 API로 소셜/추천 관계 탐색
요약 표
| 구분 | Cosmos DB |
|---|---|
| 유형 | 완전 관리형 NoSQL (멀티모델, 멀티API) |
| 확장성 | Partition Key 기반 무한 수평 확장 |
| 글로벌 분산 | 리전 간 복제 + 멀티마스터 지원 |
| SLA | 가용성, 처리량, 지연 시간, 일관성 보장 |
| 일관성 모델 | Strong, Bounded Staleness, Session, Consistent Prefix, Eventual |
| 활용 사례 | IoT, e-Commerce, 게임, 금융, 추천 시스템 |
Cosmos DB = 글로벌 규모로 확장 가능한 초저지연 완전 관리형 NoSQL DB로,
문서/그래프/키-값/컬럼 등 다양한 모델을 지원해서, 범용 NoSQL 플랫폼이다.
데이터 웨어하우스 (Data Warehouse, DW) vs 데이터 레이크(Data Lake)
Data warehouse
정의
- 기업의 의사결정 지원을 위해 설계된 분석 전용 데이터베이스
- OLAP(Online Analytical Processing)에 최적화
특징
- 정형 데이터 중심 (RDBMS, ERP, CRM 등)
- 스키마 사전 정의 (Schema-on-Write) → 데이터 적재 전에 변환 필요
- 데이터 품질/정합성 보장
- 복잡한 분석 쿼리, 집계, 다차원 분석에 강함
- 예시: Azure Synapse Analytics (Dedicated SQL Pool), Amazon Redshift, Snowflake
활용 사례
- 매출 분석, 고객 행동 분석, 재무 리포팅, KPI 모니터링
데이터 레이크 (Data Lake)
정의
- 모든 형태의 데이터(정형·반정형·비정형)를 원본 그대로 저장하는 중앙 저장소
- 저비용 스토리지(예: Azure Data Lake Storage, Blob Storage) 기반
특징
- 정형 + 반정형(JSON, Avro, Parquet) + 비정형(영상, 로그, IoT 등) 저장 가능
- 스키마 사후 적용 (Schema-on-Read) → 분석 시점에 스키마 정의
- 대규모 확장성 (PB~EB 단위)
- AI/ML, 빅데이터 분석에 활용
- 예시: Azure Data Lake Storage Gen2, AWS S3 기반 Data Lake
활용 사례
- IoT 센서 데이터 저장
- 로그/이벤트 스트리밍 보관
- 머신러닝 학습용 데이터셋 관리
- 다양한 소스 데이터를 원본 그대로 보존 → “Single Source of Truth”
데이터 웨어하우스 vs 데이터 레이크 비교
| 구분 | 데이터 웨어하우스 | 데이터 레이크 |
|---|---|---|
| 데이터 유형 | 정형 데이터 | 정형 + 반정형 + 비정형 |
| 스키마 적용 시점 | Schema-on-Write (적재 전) | Schema-on-Read (조회 시) |
| 저장소 | 고성능 DB (Azure Synapse SQL Pool) | 저비용 스토리지 (ADLS Gen2) |
| 처리 최적화 | BI/리포팅, 집계, OLAP | 빅데이터, AI/ML, Data Exploration |
| 데이터 품질 | 높은 정합성, 품질 관리 | 원본 데이터 유지, 가공 전 데이터 혼재 |
| 확장성/비용 | 확장 제한적, 비용 상대적으로 높음 | 무제한 확장 가능, GB당 비용 저렴 |
| 사용자 | BI 분석가, 경영진 | 데이터 엔지니어, 데이터 과학자 |
Azure에서의 통합 전략
현대 데이터 관리에서는 Data Warehouse와 Data Lake를 결합하는 접근이 표준이 되고 있습니다.
- Azure Data Lake Storage (ADLS Gen2)
- 원본 데이터 저장소 (Raw Zone, Curated Zone)
- Azure Synapse Analytics
- Data Lake와 직접 연동 → 외부 테이블/Serverless SQL로 조회 가능
- ETL/ELT 후 분석 최적화
- Azure Databricks
- Data Lake 상에서 데이터 정제/머신러닝 처리 후 DW 또는 BI로 전달
- Power BI
- 최종 사용자 대시보드/리포팅
➡️ 이 아키텍처는 흔히 “Lakehouse” 또는 “Modern Data Warehouse”로 불린다.
핵심 요약
- 데이터 웨어하우스
- 목적: 분석/BI
- 강점: 정제된 정형 데이터, 신뢰성 높은 리포트
- 도구: Azure Synapse Analytics
- 데이터 레이크
- 목적: 대규모 데이터 저장/탐색/AI
- 강점: 모든 유형의 데이터 보관, 무제한 확장성, 저비용
- 도구: Azure Data Lake Storage Gen2
- 최신 접근: Data Lake + Data Warehouse → Lakehouse 아키텍처
- 원본 데이터는 Data Lake에 저장
- 분석/리포팅은 DW(Synapse)와 BI(Power BI)에서 수행
- 데이터 엔지니어링/머신러닝은 Databricks와 통합
- Data Warehouse = 정제·분석 중심
- Data Lake = 저장·탐색 중심
- Azure에서는 둘을 결합해 Lakehouse 형태로 운영하는 것이 핵심 전략입니다.
스타 스키마(Star Schema)
개요
- 정의: 데이터 웨어하우스(DW)나 OLAP 시스템에서 가장 널리 사용되는 차원 모델링(Dimensional Modeling) 방식.
- 구조: 중앙에 Fact Table(사실 테이블)을 두고, 그 주변에 여러 Dimension Table(차원 테이블)이 별 모양으로 배치되는 형태.
- 목적: 데이터를 분석/리포팅하기 쉽게 설계하는 것.
Fact Table (사실 테이블)
- 정의: 비즈니스 이벤트(거래, 판매 등)와 관련된 측정값(Measure)을 저장하는 테이블.
- 특징
- 보통 매우 큰 테이블 (수억 건~수십억 건)
- Key: Dimension Table들의 외래 키(Foreign Key) 조합
- 값: 수치형 데이터 (매출액, 수량, 시간, 비용 등)
Dimension Table (차원 테이블)
- 정의: Fact Table의 데이터를 설명하는 속성 정보를 가진 테이블.
- 특징
- 상대적으로 크기가 작음
- 각 Dimension은 Primary Key를 가지고 Fact Table과 관계를 맺음
- 예: 고객 정보, 상품 정보, 지역 정보, 시간 정보
예시: 판매 데이터 스타 스키마
┌────────────┐
│ DimCustomer│
└─────┬──────┘
│
┌──────────┐ ┌──▼─────────┐ ┌───────────┐
│DimProduct │ │ FactSales │ │ DimDate │
└─────┬─────┘ └───┬───────┘ └────┬──────┘
│ │ │
│ │ │
┌────▼────┐ ┌──▼─────────┐ ┌──▼─────────┐
│DimStore │ │ DimRegion │ │DimPromotion│
└─────────┘ └────────────┘ └────────────┘- FactSales: 매출 금액, 판매 수량 저장
- DimProduct: 제품 이름, 카테고리, 브랜드
- DimCustomer: 고객 나이, 성별, 지역
- DimDate: 날짜, 요일, 분기, 연도
- DimStore/DimRegion: 매장/지역 정보
- DimPromotion: 프로모션 이벤트
장점
- 구조가 단순하고 직관적 (별 모양)
- BI/분석 도구(Power BI, Tableau, SSAS)와 잘 맞음
- 빠른 집계/쿼리 가능 (차원과 사실 연결)
- 사용자 친화적: “누가, 무엇을, 언제, 어디서, 얼마만큼” 질문에 답하기 적합
단점
- 데이터 중복 가능성 ↑ (차원 테이블이 정규화 안 되어 있음 → 비정규화 구조)
- 변경 관리 어려움 (예: 차원 속성 변경 시 테이블 크기 커질 수 있음)
- 관계가 단순해서 복잡한 분석에는 한계 → 이 경우 스노우플레이크 스키마(Snowflake Schema) 사용
스타 스키마 vs 스노우플레이크 스키마
| 구분 | 스타 스키마 | 스노우플레이크 스키마 |
|---|---|---|
| 차원 테이블 | 비정규화, 단순 구조 | 정규화, 다단계 구조 |
| 쿼리 성능 | 빠름 (조인 적음) | 상대적으로 느림 (조인 많음) |
| 설계 난이도 | 단순 | 복잡 |
| 데이터 중복 | 있음 | 최소화 |
활용
- 데이터 웨어하우스 모델링의 기본 패턴
- 주로 OLAP, BI 시스템에서 리포팅/분석용으로 사용
- Azure Synapse, SQL DW, Power BI 모델 설계 시 가장 흔히 적용
스타 스키마 = Fact Table(측정값) + Dimension Table(설명값) 구조로, 데이터 웨어하우스에서 분석을 쉽게 하기 위한 핵심 모델링 방식
데이터 웨어하우스와 Data Lake의 협력 관계
- Azure Data Lake
- 정형, 반정형, 비정형 데이터를 원본 그대로 저장
- Raw Zone → 수집된 데이터 원본
- Curated Zone → 정제·가공된 데이터 저장
- AI/ML, 빅데이터 분석, 데이터 탐색 단계에 유리
- 데이터 웨어하우스 (예: Azure Synapse Analytics)
- 정제된 데이터를 저장
- 스키마 기반, OLAP 분석/BI 리포팅 최적화
- 의사결정 지원, KPI 분석, 대시보드 제공
➡️ 협력 관계
- Data Lake는 데이터 유연성·저비용 대규모 저장소 역할
- 데이터 웨어하우스는 고성능 분석과 리포팅에 특화
- Data Lake에서 데이터를 탐색·정제한 뒤, 필요한 부분을 Data Warehouse로 이관하여 분석
데이터 처리 과정 (Pipeline)
Data Ingestion (수집)
- 다양한 소스(ERP, CRM, IoT, 로그, 소셜 미디어)에서 데이터 수집
- Azure Data Factory, Event Hub, IoT Hub 사용
- 저장 위치: Data Lake Raw Zone
Data Exploration (탐색)
- Data Lake Raw Zone에 저장된 데이터를 EDA(탐색적 데이터 분석) 수행
- 품질 점검: Null 값, 이상치, 데이터 형식 불일치 확인
- 기본 통계량, 데이터 분포, 샘플링
- 도구
- Synapse Serverless SQL Pool → CSV/Parquet/JSON 직접 쿼리
- Azure Databricks Notebook → 데이터 시각화, 통계 탐색
- Azure Data Explorer(ADX) → 로그/시계열 데이터 탐색
Data Processing & Transformation (처리/정제)
- 탐색 결과를 기반으로 불필요한 데이터 제거, 변환, 표준화
- Databricks, Synapse Spark Pool, Data Factory로 ETL/ELT 수행
- 저장 위치: Data Lake Curated Zone
Data Warehousing (저장/적재)
- 정제된 데이터를 DW(Azure Synapse SQL Pool 등)에 적재
- 스키마 기반 구조화 (스타/스노우플레이크 스키마)
- 대규모 OLAP 쿼리, 집계, 분석 수행
Data Consumption (활용)
- BI/리포팅: Power BI → DW에서 KPI, 대시보드 생성
- AI/ML: Databricks, Azure ML → Data Lake의 원본/정제 데이터 활용
- Ad-hoc Query: Synapse Serverless SQL로 Data Lake 직접 질의
협력 아키텍처 요약
[Source Systems]
↓ (Ingestion: ADF/Event Hub)
[Data Lake - Raw Zone]
↓ (Explore: Synapse Serverless SQL, Databricks, ADX)
[Data Lake - Curated Zone]
↓ (Processing & ETL/ELT)
[Data Warehouse (Synapse)]
↓
[BI, Reporting (Power BI)] + [AI/ML (Databricks, Azure ML)]핵심 요약
- 데이터 탐색(Explore)은 Data Lake와 DW를 연결하는 중간 다리 역할
- Data Lake에서 탐색 → 정제 → DW 적재 흐름으로 이어져야 데이터 품질이 보장됨
- Azure에서는 Synapse Serverless SQL, Databricks, ADX가 탐색 도구 역할 수행
- 결과적으로 Data Lake는 유연한 데이터 저장·탐색, Data Warehouse는 신뢰성 있는 분석/리포팅을 담당하여 상호 보완적으로 협력
Azure Synapse Analytics
개요
- 정의: Microsoft Azure의 데이터 통합 분석 플랫폼
- 목적: 데이터 웨어하우스(DW)와 Data Lake를 연결하여 하나의 환경에서 분석할 수 있도록 지원
- 특징
- DW 기능: 전통적인 MPP(대규모 병렬 처리) 기반 SQL Data Warehouse 기능 제공
- Data Lake 기능: Data Lake Storage Gen2에 저장된 반정형/비정형 데이터를 직접 쿼리 가능
- 엔드투엔드 분석: 수집 → 저장 → 탐색 → 처리 → 시각화까지 지원
Data Warehouse + Data Lake 통합 구조
Data Lake (저장소 역할)
- Azure Data Lake Storage Gen2에 모든 데이터 저장 (Raw Zone, Curated Zone)
- 정형(ERP, CRM 데이터) + 반정형(JSON, Parquet, Avro) + 비정형(로그, IoT, 이미지)
Data Warehouse (분석 엔진 역할)
- Azure Synapse Dedicated SQL Pool → 구조화된 데이터 저장 및 OLAP 분석
- 스타 스키마/스노우플레이크 스키마 기반 데이터 모델링
- 빠른 집계, BI, KPI 분석
통합 (Synapse Analytics)
- Serverless SQL Pool: Data Lake의 파일을 직접 쿼리 (ETL 없이 Ad-hoc Query)
- Pipelines: Data Factory 기능과 통합 → ETL/ELT 파이프라인 관리
- Spark Pools: 빅데이터 처리, ML/AI 워크로드 실행
- Power BI 연계: Synapse Studio에서 대시보드/리포트 바로 연결
데이터 처리 과정 (Synapse 중심)
- Ingestion (수집)
- 원천 시스템(ERP, CRM, IoT, SNS 등) → Synapse Pipeline/ADF → Data Lake 저장
- Exploration (탐색)
- Serverless SQL Pool / Spark Pool → Data Lake Raw Zone 탐색
- 데이터 품질 점검, 스키마 추출
- Processing & Transformation (정제/가공)
- Spark Pool, Dataflow, SQL을 활용한 정제
- Curated Zone에 저장 (주로 Parquet/Delta 형식)
- Warehousing (구조화)
- 정제된 데이터를 Synapse Dedicated SQL Pool에 적재
- BI 분석 및 OLAP 최적화
- Consumption (활용)
- Power BI, Excel, ML/AI 모델링 → Synapse와 직접 연계
장점
- 단일 플랫폼에서 Data Lake + DW 통합 분석 가능
- Serverless + Dedicated 혼합 → 유연한 비용 관리 (필요 시만 컴퓨팅 과금)
- 멀티모델 지원: 정형(SQL) + 반정형(JSON/Parquet) + 비정형 분석
- 엔터프라이즈 통합: Power BI, Azure ML, Cognitive Services 등과 네이티브 통합
활용 시나리오
- BI 보고 & KPI 분석: Synapse DW + Power BI
- Data Lake 탐색: Serverless SQL로 Raw 데이터 Ad-hoc 조회
- 빅데이터 & AI: Spark Pool에서 ML 모델 학습 → Synapse DW에 결과 적재
- IoT/로그 분석: Event Hub → Data Lake → Synapse Serverless SQL
요약 다이어그램 (텍스트 표현)
[원천 데이터 (ERP, IoT, 로그, 앱)]
↓ (수집: Synapse Pipeline/ADF)
[Azure Data Lake Storage Gen2 (Raw Zone)]
↓ (탐색: Serverless SQL, Spark)
[Azure Data Lake Storage Gen2 (Curated Zone)]
↓ (정제/적재)
[Azure Synapse Dedicated SQL Pool (DW)]
↓
[Power BI / Azure ML / 리포트]핵심 요약
- Data Lake = 원본 데이터 저장 (Raw → Curated)
- Data Warehouse = 정제된 데이터의 고성능 분석
- Azure Synapse Analytics = 둘을 하나의 통합 플랫폼에서 관리·분석할 수 있도록 해주는 핵심 서비스
Azure Synapse Analytics = Data Lake(유연성) + Data Warehouse(고성능 분석)를 결합한 Modern Data Platform
Azure Databricks
개요
- 정의: Apache Spark 기반의 클라우드 빅데이터·AI 플랫폼
- 특징
- Azure에 네이티브 통합 (ADLS, Synapse, Power BI, Azure ML과 직접 연동)
- 대규모 데이터 처리 + 머신러닝 학습 환경 제공
- Python, R, Scala, SQL 등 다양한 언어 지원
- Notebook 기반 협업 환경
데이터 분석/AI 수명주기 (CRISP-DM 관점)
일반적으로 데이터 기반 프로젝트는 다음과 같은 흐름을 가집니다:
- Ingest: 데이터 수집 (Event Hub, IoT Hub, ADF 등)
- PREP: 데이터 준비 (정제, 탐색, 특징 엔지니어링)
- TRAIN: 모델 학습 및 튜닝
- DEPLOY: 모델 배포 및 서비스화
- MONITOR: 운영 모니터링, 피드백
➡️ Azure Databricks는 이 중에서 PREP / TRAIN 단계의 핵심 도구 역할을 합니다.
PREP 단계 (데이터 준비)
- 역할: 다양한 데이터 원본에서 데이터를 불러와 정제·탐색·가공하는 단계
- Databricks 활용 포인트
- 데이터 연결: ADLS Gen2, Blob, Cosmos DB, Event Hub, Kafka 등에서 데이터 수집
- 데이터 탐색/EDA: Notebook 환경에서 Pandas, PySpark, Koalas 활용 → 통계, 분포, 이상치 확인
- 데이터 정제: 결측치 처리, 데이터 타입 변환, 중복 제거
- 데이터 변환: 로그/반정형(JSON, Avro) → Parquet/Delta 변환
- 특징 엔지니어링: 모델 학습을 위한 Feature 생성 및 스케일링
- Delta Lake: Data Lake 위에서 트랜잭션 지원, 정제된 데이터 버전 관리
TRAIN 단계 (모델 학습)
- 역할: 정제된 데이터를 기반으로 ML/AI 모델을 학습하는 단계
- Databricks 활용 포인트
- 분산 학습: Apache Spark MLlib, Horovod, TensorFlow, PyTorch, Scikit-learn 분산 학습 지원
- AutoML: Databricks AutoML → 여러 알고리즘 자동 시도 + 피처 중요도 분석
- Hyperparameter Tuning: Hyperopt, MLflow와 통합해 최적화
- MLflow: 실험 관리(Experiment Tracking), 모델 버전 관리(Model Registry)
- GPU/CPU 클러스터: 딥러닝/머신러닝 학습용 스케일 아웃 클러스터 지원
Azure 통합 포인트
- 데이터 저장소: ADLS Gen2, Blob Storage에서 데이터 읽기/쓰기
- 분석/리포팅: 결과 데이터를 Synapse, Power BI로 전달
- 모델 배포: 학습된 모델을 Azure Machine Learning이나 Databricks MLflow Serving으로 배포
- CI/CD: Azure DevOps, GitHub Actions 연계
요약
| 단계 | 핵심 역할 | Databricks 기능 |
|---|---|---|
| PREP (데이터 준비) | 데이터 탐색, 정제, 변환, 피처 엔지니어링 | Notebook, PySpark, Delta Lake, Pandas, Koalas |
| TRAIN (모델 학습) | 모델 학습, 튜닝, 관리 | Spark MLlib, TensorFlow/PyTorch, AutoML, Hyperopt, MLflow |
Azure Databricks는 데이터 사이언스 라이프사이클에서 PREP/TRAIN 단계의 핵심 도구
- PREP → 데이터 정제, 탐색, 특징 엔지니어링 (Delta Lake 포함)
- TRAIN → 대규모 ML/AI 모델 학습, AutoML, MLflow 관리
Azure HDInsight
개요
- 정의: Microsoft Azure에서 제공하는 완전 관리형 클라우드 기반 빅데이터 분석 서비스
- 기반 기술: Apache Hadoop 에코시스템 (오픈소스)
- 특징
- Hadoop, Spark, Hive, HBase, Kafka, Storm 등 주요 컴포넌트를 클러스터 형태로 관리형 서비스로 제공
- 대규모 데이터 처리(배치·스트리밍·대화형 분석)에 사용
- Azure Storage, Data Lake Storage와 네이티브 통합
- 온디맨드 클러스터 확장/축소 가능 → 비용 최적화
지원되는 Hadoop 에코시스템 컴포넌트
Azure HDInsight는 Hadoop 생태계를 클라우드에서 활용할 수 있도록 여러 엔진을 제공
- Apache Hadoop
- 분산 저장(HDFS) + 분산 처리(MapReduce)
- 대규모 데이터 배치 처리
- Apache Spark
- 인메모리 기반 고속 데이터 처리
- 머신러닝, 스트리밍, 그래프 분석
- Apache Hive
- SQL 유사 언어(HiveQL)로 대규모 데이터 질의
- BI 도구 연계 용이 (ODBC/JDBC)
- Apache HBase
- 분산형 NoSQL DB (Column-family 구조)
- 대규모 시계열, IoT, 실시간 데이터 저장
- Apache Kafka
- 분산 메시지 스트리밍 플랫폼
- IoT 이벤트 수집, 실시간 데이터 파이프라인
- Apache Storm
- 실시간 스트리밍 처리 엔진
아키텍처 구성
- 클러스터 노드
- Head Node: 클러스터 관리 및 작업 스케줄링
- Worker Node: 데이터 저장 및 처리 실행
- Zookeeper Node: 분산 조정/메타데이터 관리
- 스토리지 계층
- Azure Blob Storage 또는 Azure Data Lake Storage(ADLS Gen2)를 HDFS 대체 저장소로 사용
장점
- 완전 관리형: 클러스터 프로비저닝, 패치, 모니터링 자동화
- 확장성: 수십에서 수천 노드까지 확장 가능
- 유연성: 다양한 오픈소스 빅데이터 엔진 제공
- 비용 효율: 사용한 만큼 과금 (Pay-as-you-go)
- 보안: Azure AD 통합, 가상 네트워크, Kerberos 인증 지원
단점/고려사항
- 클러스터 유지 비용이 높을 수 있음 (항시 실행되는 경우)
- Spark/Databricks 같은 최신 대안에 비해 관리 편의성 떨어짐
- 주로 레거시 Hadoop 워크로드나 특정 OSS 호환성 요구가 있을 때 적합
활용 사례
- 배치 분석: 로그, IoT, Clickstream 데이터 처리 (Hadoop/Spark)
- 실시간 스트리밍: Kafka + Storm → 실시간 이벤트 처리
- 데이터 웨어하우스 대체/보완: Hive를 통한 SQL 쿼리
- 머신러닝/AI: Spark MLlib 활용
- IoT 시나리오: 센서 데이터 수집(Kafka) + 분석(Spark) + 저장(HBase)
요약
| 구분 | 설명 |
|---|---|
| 서비스명 | Azure HDInsight |
| 기반 | Apache Hadoop 에코시스템 |
| 지원 엔진 | Hadoop, Spark, Hive, HBase, Kafka, Storm |
| 스토리지 | Blob Storage, Data Lake Storage (HDFS 대체) |
| 특징 | 완전 관리형, 확장성, Azure 통합 |
| 활용 | 빅데이터 처리(배치·실시간), IoT, ML/AI, 로그 분석 |
Azure HDInsight = Hadoop/Spark/Kafka/HBase 등 오픈소스 빅데이터 컴포넌트를 클라우드에서 관리형 서비스로 제공하는 플랫폼
Azure Stream Analytics란?
개요
- 정의: Microsoft Azure에서 제공하는 실시간 데이터 스트리밍 처리 서비스
- 특징
- 스트리밍 데이터(이벤트, 로그, IoT 센서 데이터)를 수 초 단위 지연(latency)로 분석 가능
- 완전 관리형: 인프라 관리 불필요, 서버리스(Serverless) 실행
- SQL 유사 쿼리 언어(ASA Query Language)로 데이터 변환 및 분석
- Azure Event Hub, IoT Hub, Blob Storage 등과 네이티브 통합
아키텍처 구성
[이벤트 소스]
IoT Hub / Event Hub / Blob Storage
↓
[Stream Analytics Job]
- 입력 (Input)
- 쿼리 (Query: SQL 기반)
- 출력 (Output)
↓
[대상 시스템]
Power BI / Cosmos DB / Blob / Data Lake / Synapse주요 기능
- 실시간 데이터 수집
- Event Hub, IoT Hub, Kafka와 직접 연계
- 실시간 분석
- SQL 기반 스트리밍 쿼리
- 집계 (SUM, AVG, COUNT)
- 윈도우 함수 (Tumbling, Hopping, Sliding windows)
- 패턴 매칭
- SQL 기반 스트리밍 쿼리
- 출력
- Power BI → 실시간 대시보드
- Azure SQL DB, Cosmos DB → 트랜잭션/저장
- Data Lake, Blob → 장기 저장
- Event Hub → 다른 애플리케이션 전달
- 확장성
- 이벤트 처리량에 맞춰 자동 확장 가능
- 복합 이벤트 처리 (CEP)
- 이벤트 간 관계 분석 (예: 특정 패턴 탐지, Fraud Detection)
장점
- 완전 관리형 → 인프라 관리 불필요
- SQL 문법 기반 → 학습 곡선 낮음
- Azure 서비스와 네이티브 통합 (IoT/BI/Storage/ML)
- 낮은 지연 시간(밀리초~초 단위)
단점/제약
- 복잡한 ML/AI 모델 학습에는 한계 (→ Databricks, Azure ML과 연계 필요)
- Spark Streaming이나 Flink보다 커스터마이징 유연성이 적음
- 오직 Azure 생태계 내에서 강력
활용 사례
- IoT 데이터 처리
- 센서 데이터 → IoT Hub → Stream Analytics → 실시간 대시보드(Power BI)
- 실시간 Fraud Detection
- 금융 거래 이벤트 → 패턴 탐지 → 의심 거래 알림
- 실시간 로깅/모니터링
- 앱 로그 → Event Hub → ASA → Cosmos DB 저장 + 경보 트리거
- 스마트 시티/스마트 팩토리
- 교통량/온도/에너지 사용량 분석 → 즉시 피드백 제공
요약
| 구분 | 설명 |
|---|---|
| 서비스명 | Azure Stream Analytics (ASA) |
| 유형 | 완전 관리형 스트리밍 데이터 분석 서비스 |
| 언어 | SQL 유사 쿼리 언어 |
| 입력 | Event Hub, IoT Hub, Blob Storage 등 |
| 출력 | Power BI, Cosmos DB, Data Lake, SQL Database 등 |
| 특징 | 서버리스, 낮은 지연 시간, Azure 통합 |
| 활용 | IoT, 실시간 대시보드, Fraud Detection, 실시간 모니터링 |
Azure Stream Analytics = 실시간 스트리밍 데이터 수집·처리·분석을 SQL 기반으로 손쉽게 수행할 수 있는 완전 관리형 서비스
Azure Data Factory란?
개요
- 정의: Microsoft Azure에서 제공하는 클라우드 기반 데이터 통합(ETL/ELT) 서비스
- 목적: 다양한 데이터 원본을 연결하여 데이터 추출(Extract), 변환(Transform), 적재(Load) 파이프라인을 시각적으로 설계 및 실행
- 특징:
- 코드 작성 없이 GUI 기반 파이프라인 빌드 가능
- 온프레미스 및 클라우드 데이터 소스를 모두 지원
- 배치 처리뿐 아니라 스케줄링 & 트리거 기반 자동화 가능
아키텍처 구성
[데이터 원본]
SQL DB, Blob Storage, Data Lake, SaaS, API 등
↓
[ADF 파이프라인]
- Linked Service (연결 정보)
- Dataset (데이터 구조 정의)
- Activity (복사, 변환, 제어 작업)
- Integration Runtime (실행 엔진)
↓
[대상 시스템]
Azure SQL, Synapse, Cosmos DB, Data Lake, Power BI 등주요 기능
- 데이터 연결
- 100+ 개 커넥터 지원 (SQL, Oracle, SAP, Blob, Data Lake, REST API 등)
- 데이터 이동
- Copy Activity를 통해 원본 → 대상으로 데이터 복사
- 데이터 변환
- Mapping Data Flow (시각적 변환 도구, Spark 기반)
- 필터링, 집계, 조인, 파티셔닝 등 지원
- 오케스트레이션
- 파이프라인 내에서 여러 액티비티를 조합
- 조건부 분기, 반복 처리, 병렬 실행 가능
- 스케줄링 & 트리거
- 시간 기반 (매일, 매시간 등)
- 이벤트 기반 (Blob 업로드 이벤트 등)
- 모니터링
- 실행 로그, 성능 모니터링 제공
- 실패 시 알림 및 재시도 정책 설정 가능
장점
- 코드 없이 GUI 기반으로 손쉬운 데이터 파이프라인 생성
- 온프레미스 & 클라우드 데이터 원본 통합 지원
- Azure Synapse, Databricks, ML, Power BI 등과 원활하게 연동
- 자동 확장 → 대규모 데이터 이동에도 유연 대응
단점/고려사항
- 실시간 스트리밍 처리에는 한계 (→ Azure Stream Analytics 적합)
- 복잡한 데이터 변환 로직은 Databricks 같은 Spark 기반 도구 필요
- 고빈도 대규모 처리 시 비용 관리 필요
활용 사례
- 데이터 웨어하우스 로딩
- 다양한 원본 데이터를 수집 → 정제 → Azure Synapse로 로드
- 데이터 레이크 통합
- 로그, IoT 데이터, 비정형 데이터 → Data Lake 저장
- 하이브리드 시나리오
- 온프레미스 ERP/CRM → 클라우드 분석 환경으로 자동 동기화
- 머신러닝 준비
- 학습 데이터 전처리 후 Azure ML에 전달
요약
| 구분 | 설명 |
|---|---|
| 서비스명 | Azure Data Factory (ADF) |
| 유형 | 클라우드 기반 ETL/ELT 데이터 통합 서비스 |
| 특징 | 코드 없는 파이프라인, 시각적 UI, 다양한 커넥터 지원 |
| 구성요소 | Linked Service, Dataset, Activity, Integration Runtime |
| 장점 | 손쉬운 데이터 파이프라인, 자동화, Azure 생태계 통합 |
| 제한 | 스트리밍 한계, 복잡한 로직은 Spark/Databricks 필요 |
| 활용 | DW 로딩, Data Lake 통합, ML 데이터 준비, 하이브리드 통합 |
Azure Data Factory = 코드 없이도 ETL/ELT 파이프라인을 시각적으로 설계하고, 다양한 원본과 대상을 연결해 데이터 이동·변환·자동화를 지원하는 Azure의 대표 데이터 통합 서비스
Power BI
개요
-
정의: Microsoft에서 제공하는 비즈니스 인텔리전스(BI) 및 데이터 시각화 도구
-
목적: 다양한 데이터 원본을 연결 → 분석 → 시각화 → 공유
-
형태
- Power BI Desktop: 로컬 앱, 데이터 준비/모델링/시각화 제작
- Power BI Service (Cloud): 웹 기반 공유·협업 환경
- Power BI Mobile: 모바일 앱에서 대시보드 활용
- Power BI Report Server: 온프레미스 보고서 관리
주요 기능
- 데이터 연결
- Azure SQL, Excel, CSV, API, SharePoint, Salesforce 등 수백 개 데이터 소스 지원
- 데이터 변환 & 모델링
- Power Query를 통한 ETL (추출, 변환, 로드)
- DAX(Data Analysis Expressions) 언어를 통한 계산 컬럼/측정값 정의
- 관계형 모델링 (다차원, 스타 스키마 기반)
- 시각화
- 기본 제공 차트(막대, 꺾은선, 지도, KPI, 게이지 등)
- 커스텀 비주얼 마켓플레이스 지원
- 실시간 분석
- Azure Stream Analytics와 연동 → 실시간 대시보드 생성
- 협업/공유
- Power BI Service를 통해 보고서·대시보드 공유
- Microsoft Teams, SharePoint 등과 통합
- AI 기능
- 자연어 질의(Q&A)
- Azure Cognitive Services 연계 → 텍스트·이미지 분석
아키텍처 개요
[데이터 원본]
└─ Excel / SQL / Azure / API
↓
[Power Query: 데이터 준비]
↓
[Power BI Desktop: 모델링 & 리포트 제작]
↓
[Power BI Service: 배포 & 공유]
↓
[Power BI Mobile / Teams / Embed: 활용]장점
- 직관적인 UI → 비개발자도 쉽게 사용 가능
- 다양한 데이터 소스 지원 → 클라우드·온프레미스 모두 연결 가능
- 실시간 대시보드 제공 → IoT/운영 모니터링에 적합
- Microsoft 생태계(Azure, Office 365, Teams)와 강력한 통합
단점/고려사항
- 대규모 엔터프라이즈 환경에서는 Premium 라이선스 비용 부담 가능
- 복잡한 데이터 모델링은 DAX 학습 필요
- 초대형 데이터셋은 성능 최적화 필요 (→ DirectQuery, Aggregation 활용)
활용 사례
- 경영 대시보드: 매출, 비용, KPI 모니터링
- IoT 분석: 센서 데이터 실시간 시각화 (Azure Stream Analytics → Power BI)
- 재무/영업 리포트: 데이터 자동 집계 & 시각화
- HR 분석: 인력 현황, 이직률 분석
- 학교/연구: 학생 성적, 연구 성과 분석
요약
| 구분 | 설명 |
|---|---|
| 서비스명 | Power BI |
| 유형 | BI(비즈니스 인텔리전스) & 데이터 시각화 도구 |
| 구성 요소 | Desktop, Service, Mobile, Report Server |
| 주요 기능 | 데이터 연결, 변환, 모델링, 시각화, 공유 |
| 특징 | 실시간 대시보드, AI 기능, Azure/Office365 통합 |
| 활용 | KPI 모니터링, IoT 실시간 분석, 재무/영업 보고 |
Power BI = 데이터 원본 연결부터 변환, 시각화, 공유까지 지원하는 Microsoft의 대표 BI 도구이며, Azure 생태계와 결합해 실시간 분석 + 대시보드 시각화에 강력한 장점
Azure Storage
Azure Data Storage의 데이터 유형(Data format)
Parquet
- 저장 방식: 컬럼 단위 저장 (열 기반)
- 특징
- 분석 최적화: 같은 컬럼의 데이터가 연속적으로 저장되므로 특정 열만 조회하는 경우 속도가 매우 빠름.
- 압축 효율성: 동일한 타입의 데이터가 연속적으로 저장되기 때문에 압축 효율이 높음.
- 활용 사례: 빅데이터 분석(예: Azure Synapse Analytics, Spark, Hive)에서 주로 사용.
- 장점
- 읽기 성능이 뛰어나서 대규모 데이터 분석에 유리
- 스키마 진화(Schema Evolution) 지원 → 컬럼 추가/삭제 시 유연
Avro
- 저장 방식: 로우 단위 저장 (행 기반)
- 특징
- 빠른 직렬화/역직렬화: JSON 기반의 스키마를 메타데이터에 포함, 데이터 전송/저장 시 효율적.
- 실시간 데이터 처리에 최적화: Kafka, Event Hub 등 스트리밍 시스템과 함께 자주 사용됨.
- 활용 사례: 로그 수집, 이벤트 스트리밍, 메시징 시스템.
- 장점
- 스키마 정보가 포함되어 있어서 데이터 간 호환성이 좋음
- 실시간 전송/저장에 적합
ORC (Optimized Row Columnar)
- 저장 방식: 컬럼 단위 저장 (열 기반)
- 특징
- 색인(Index) 지원: 쿼리 시 필요한 데이터만 빠르게 접근 가능
- 고효율 압축: Parquet과 비슷하지만 Hadoop 에코시스템(Hive, Spark 등)에서 성능 최적화됨
- 활용 사례: 주로 Hive, Hadoop 기반 데이터 웨어하우스에서 사용
- 장점
- Hive 쿼리에 매우 효율적
- 디스크 I/O와 저장 공간 절약 효과가 큼
비교 요약 표
| 포맷 | 저장 방식 | 장점 | 활용 사례 |
|---|---|---|---|
| Parquet | 열 기반 | 분석 성능 최적화, 높은 압축 효율 | BI, 데이터 분석, Azure Synapse |
| Avro | 행 기반 | 빠른 직렬화/역직렬화, 실시간 처리 적합 | Kafka, 이벤트 스트리밍 |
| ORC | 열 기반 | 색인 + 고효율 압축, Hadoop 최적화 | Hive, Hadoop 기반 DW |
Azure Blob(Storage)
개요
- 정의: 대용량 비정형 데이터(파일)를 저장하는 Azure의 객체 스토리지. 파일 하나하나가 BLOB(Binary Large Object)
- 구성 요소
- Storage Account ⟶ Container ⟶ Blob(파일)
- BLOB 타입
- Block Blob: 가장 일반적. 텍스트/바이너리 파일, 데이터 레이크, 로그, 이미지, 포맷 파일(CSV/Parquet 등)에 사용.
- Append Blob: 추가 쓰기 전용(append-only) 로그/이벤트 덤프에 적합.
- Page Blob: 랜덤 읽기/쓰기(8KB 페이지). VHD/스냅샷 등 IOPS가 필요한 시나리오.
- 액세스 계층(비용 정책)
- Hot: 자주 읽음(저장비↑, 읽기비↓).
- Cool: 가끔 읽음(저장비↓, 조기 삭제 비용 有).
- Archive: 장기 보관(아주 저렴, 복구 지연).
- 주요 기능
- HNS(Data Lake Gen2): 계층형 네임스페이스(디렉터리/권한)로 데이터 레이크처럼 사용.
- Lifecycle 관리: 규칙 기반 계층 이동/보존/삭제.
- 버전관리·Soft delete·Immutability(WORM) 지원.
- 보안: SSE(서버측 암호화), CMK, SAS/미리서명 URL, RBAC/ACL(HNS).
Azure Blob에서의 포맷별 특징과 사용 팁
| 포맷 | 타입 | 스키마 포함 | 장점 | 단점/주의 | 주 사용 시나리오 | 권장 BLOB 타입 |
|---|---|---|---|---|---|---|
| CSV | 텍스트 | 없음 | 단순/범용, Excel/ADF/Synapse 호환 | 타입 손실, 대용량 비효율, 구분자/인코딩 이슈 | 간단한 교환·임시 적재·마이그레이션 | Block Blob |
| TSV | 텍스트 | 없음 | CSV보다 필드 충돌 적음 | 메타데이터 부족 | 로그/NLP 데이터셋 | Block Blob |
| XML | 텍스트 | 구조 명시(가능) | 계층표현·표준 교환 | 冗長, 파싱 느림 | 시스템 간 연동, 설정 | Block Blob |
| JSON | 텍스트 | 약함(구조 있지만 타입 약함) | 읽기 쉬움, REST/NoSQL 친화 | 초대용량 비효율, 스키마 관리 난이도 | API 응답, 로그, Cosmos/Databricks 파이프라인 | Block Blob |
| BSON | 바이너리 | 강함(타입 풍부) | 빠른 파싱, 타입 보존 | 가독성 낮음, 도구 제한 | Mongo/Cosmos(Mongo API) 백업/이관 | Block Blob |
| Parquet | 컬럼 바이너리 | 강함 | 분석 최적화, 고압축, 특정 컬럼만 빠른 스캔 | 실시간 이벤트에 부적합 | Lakehouse/Spark/Synapse 분석 | Block Blob |
| Avro | 로우 바이너리 | 강함 | 빠른 직렬화/역직렬화, 스키마 진화, 스트리밍 적합 | 컬럼 스캔 비효율 | Kafka/Event Hub 수집, CDC, 중간 저장 | Block/Append Blob(로그면 Append도) |
| ORC | 컬럼 바이너리 | 강함 | 색인+고압축, Hive 친화 | 도구 호환성은 Parquet보다 좁을 수 있음 | Hadoop/Hive 분석 | Block Blob |
압축: 텍스트 계열(CSV/JSON/XML)은
gzip으로 저장하면 비용·전송·처리 속도가 개선(도구가 스트리밍 압축을 인식하는지 확인). Parquet/ORC/Avro는 내부 코덱(Snappy/ZSTD 등) 활용 권장
언제 어떤 포맷을, 어떤 BLOB 타입을?
- 배치 분석/BI(대부분의 레이크·웨어하우스): Parquet + Block Blob + HNS(Gen2)
- 실시간 수집/중간 버퍼: Avro + Append Blob(로그/이벤트), 후단 변환 시 Parquet로 변환
- 간단 교환/임시 적재: CSV/TSV + Block Blob(가능하면 gzip)
- API/앱 이벤트 로그: JSON + Append Blob(또는 Block, 크기/롤링 정책에 따라)
- Mongo 계열 이관/백업: BSON + Block Blob
- 대용량 장기 보관: 어떤 포맷이든 Archive 계층 + 수명 주기 규칙
Azure Storage Redundancy (스토리지 중복성)
LRS (Locally Redundant Storage, 지역 중복 저장소)
- 구성: 데이터가 단일 리전의 단일 데이터센터 내에서 3중 복제
- 특징
- 가장 저렴한 옵션
- 하드웨어 장애(디스크, 랙, 서버)에는 안전
- 그러나 데이터센터 전체가 중단되면 데이터 손실 위험 존재
- 사용 시나리오
- 비용 민감한 개발/테스트 환경
- 재해 복구(DR) 필요성이 낮은 데이터
ZRS (Zone-Redundant Storage, 가용 영역 중복 저장소)
- 구성: 동일 리전 내 3개의 가용 영역(Availability Zone)에 데이터 복제
- 특징
- 단일 데이터센터 장애를 넘어 AZ 단위 장애에도 내구성 보장
- 읽기/쓰기 지연 시간이 낮음 (동일 리전 내 복제)
- 다만, 리전 전체 장애에는 대비 불가
- 사용 시나리오
- 고가용성이 필요한 운영 데이터
- 리전 내 다중 AZ 인프라와 연동되는 서비스
GRS (Geo-Redundant Storage, 지역 간 중복 저장소)
- 구성: LRS + 보조 리전으로 비동기 복제
- 기본 리전 내 LRS 3중 복제
- 보조 리전(수백 km 떨어진)에도 또 3중 복제 → 총 6개 복제본
- 특징
- 리전 전체 장애에도 데이터 보호 가능
- 단, 보조 리전 데이터는 읽기 불가 (페일오버 전까지)
- 사용 시나리오
- 재해 복구(Disaster Recovery) 필수
- RTO/RPO 요구사항이 낮은 데이터
RA-GRS (Read-Access Geo-Redundant Storage)
- 구성: GRS + 보조 리전 읽기 권한(Read Access) 제공
- 특징
- 보조 리전 데이터에 읽기 전용 접근 가능
- 리전 장애 시에도 읽기 연속성 제공
- 사용 시나리오
- 글로벌 서비스에서 DR 리전에 읽기 전용 백업 데이터 제공
- 리포트/분석용 데이터 조회
GZRS (Geo-Zone-Redundant Storage)
- 구성: ZRS + GRS
- 기본 리전 내 여러 AZ에 동기 복제
- 보조 리전에도 비동기 복제
- 특징
- 가장 높은 내구성 (AZ 장애 + 리전 장애 모두 보호)
- 다만 비용이 높음
- 사용 시나리오
- 금융, 의료, 공공기관 등 최고 수준의 가용성/내구성 요구
RA-GZRS (Read-Access Geo-Zone-Redundant Storage)
- 구성: GZRS + 보조 리전 읽기 권한
- 특징
- 기본 리전 AZ 장애 대비 + 보조 리전 읽기 가능
- Azure Storage Redundancy 옵션 중 최고 수준 보장
- 사용 시나리오
- 글로벌 기업, 미션 크리티컬 서비스
- DR 환경에서 즉시 읽기 가능한 서비스
비교 요약
| 옵션 | 리전 내 복제 | AZ 중복 | 보조 리전 | 보조 리전 읽기 | 내구성 수준 | 비용 |
|---|---|---|---|---|---|---|
| LRS | ✔ (3x) | ✘ | ✘ | ✘ | 기본 | 가장 저렴 |
| ZRS | ✔ (3x, AZ) | ✔ | ✘ | ✘ | AZ 장애 보호 | 중간 |
| GRS | ✔ (3x) | ✘ | ✔ (3x, 보조 리전) | ✘ | 리전 장애 보호 | 중간~높음 |
| RA-GRS | ✔ (3x) | ✘ | ✔ (3x, 보조 리전) | ✔ | 리전 장애 보호 + 보조 읽기 | 높음 |
| GZRS | ✔ (AZ 3x) | ✔ | ✔ (보조 리전) | ✘ | AZ + 리전 장애 보호 | 높음 |
| RA-GZRS | ✔ (AZ 3x) | ✔ | ✔ (보조 리전) | ✔ | 최고 수준 | 가장 높음 |
- LRS → GRS → RA-GRS: 단일 데이터 센터 -> 지역 단위 재해 복구 -> 타지역 읽기 지원
- ZRS → GZRS → RA-GZRS: 가용성 영역을 기반으로 확장, 지역 단위 확장 및 지역간 읽기 지원
*단, 쓰기 가능한 여러 지역(Multi-write regions)은 지원되지 않음
Azure File Storage
개요
- 정의: 클라우드에서 제공하는 완전 관리형 파일 공유 서비스
- 특징
- SMB(서버 메시지 블록) 프로토콜 또는 NFS(Network File System)로 접근 가능
- 온프레미스와 클라우드 애플리케이션이 동시에 같은 파일 공유에 접근 가능
- Windows, Linux, macOS 환경 모두 지원
- 완전 관리형 → 패치, 확장, HA 모두 Azure가 담당
주요 기능
- 표준 프로토콜 지원
- SMB 3.0 → Windows/Linux/macOS 클라이언트 직접 연결 가능
- NFS 4.1 → Linux 기반 워크로드 지원
- Azure Files Sync
- 온프레미스 Windows Server와 양방향 동기화
- 자주 쓰는 파일은 로컬 캐시, 전체 데이터는 클라우드 보관
- 보안
- Azure AD DS 인증, RBAC, 네트워크 방화벽, 암호화(전송 중/저장 시) 지원
- 백업/복구
- Azure Backup과 통합 가능
- Soft Delete 지원 (실수로 삭제한 파일 복구)
계층 (Performance Tiers)
- Premium (SSD 기반)
- 고성능/저지연, IOPS가 중요한 워크로드 (VDI, DB 백업, 고성능 앱)
- Transaction Optimized (HDD 기반)
- 일반적인 파일 공유 (사용자 홈 디렉토리, 애플리케이션 로그 등)
- Cool
- 자주 사용하지 않는 파일용 저비용 계층 (아카이빙 수준은 아님)
활용 사례
- Lift & Shift 애플리케이션
- 기존 앱이 SMB/NFS 파일 공유를 사용한다면 코드 수정 없이 Azure Files로 이전 가능
- 공유 파일 저장소
- 여러 VM/애플리케이션이 동일한 파일을 공유해야 할 때
- 로밍 프로필 및 사용자 홈 디렉토리
- Windows 가상 데스크톱(VDI) 환경에서 사용자 파일 저장소로 활용
- 백업/로그 저장소
- SQL Server 백업, 애플리케이션 로그 저장
Azure Files vs Azure Blob Storage
| 구분 | Azure File Storage | Azure Blob Storage |
|---|---|---|
| 접근 방식 | SMB, NFS (표준 파일 공유 프로토콜) | REST API, SDK |
| 시나리오 | 기존 앱 마이그레이션, 파일 공유, VDI | 빅데이터, 백업, 아카이빙, 비정형 데이터 |
| 구조 | 파일/폴더 계층 구조 | 컨테이너/Blob(객체) |
| 마운트 | OS 파일 시스템 드라이브로 바로 마운트 가능 | 직접 마운트 불가 (별도 API/툴 필요) |
배포 옵션
- Azure Files (Standard/Premium)
- 기본적인 클라우드 파일 공유
- Azure File Sync
- 온프레미스 Windows Server와 하이브리드 파일 공유 구축
정리
- Azure File Storage는 SMB/NFS 기반 완전 관리형 클라우드 파일 공유
- 코드 변경 없이 기존 온프레 파일 서버를 클라우드로 이전 가능
- 온프레미스와 클라우드 간 동기화(Azure File Sync) 지원
- 고성능부터 저비용까지 다양한 계층 제공
