IPC(Inter-Process Communication)
프로세스 간 통신(Inter-Process Communication, IPC)이란 프로세스들 사이에 서로 데이터를 주고받는 행위 또는 그에 대한 방법이나 경로를 뜻한다.
IPC는 마이크로커널과 나노커널의 디자인 프로세스에 매우 중요하다: 마이크로커널은 커널이 제공하는 기능의 수를 줄여준다. 해당 기능들은 IPC를 통해 서버와 통신함으로써 얻으며 일반적인 모놀리딕 커널에 비해 IPC의 수가 극적으로 증가된다.
위키백과 Link
마이크로서비스 아키텍처에셔는 각 서비스간 통신을 통해 상호 작용을 하면서 기능 요구사항을 달성하게 된다. 그러나 IPC에서 사용할 수 있는 많은 후보 기술들이 있고, 어떤 기술을 사용할 것인지는 서비스의 여러 측면에서 트레이드오프를 가져온다. 따라서 본 챕터에서는 가용성, 트랜잭션 관리 등에 중요한 영향을 미치는 IPC 기술에 대해서 살펴 본다.
상호 작용 스타일
통신은 일반적으로 client - server 모델로 동작한다. 서버는 통신 요청을 받아 들일 준비를 하고, 통신을 요청할 클라이언트에서 요청을 보내기를 기다리고 있으며, 클라이언트에서는 필요한 경우 서버에 통신을 위한 채널을 생성하고, 메시지를 보내 필요 사항(CRUD)를 요구한다. 서버는 클라이언트 요청에 따라 비즈니스 로직을 처리하여 적절한 응답(여기는 에러도 포함된다)을 생성하여 클라이언트에 응답하는 형태로 동작한다. 클라이언트 -서버 간 상호 작용은 다음의 두가지 기준으로 분류가 가능하다
참여자 수에 따른 분류
- 일대일(one to one): 각 클라이언트의 요청은 한 서비스가 처리
- 일대다(one to many): 각 클라이언트의 요청을 여러 서비스가 협동하여 처리
동기/비동기 분류
- 동기(synchronous): 클라이언트는 서버가 응답할때까지 블로킹하고 대기
- 비동기(asynchronous): 클라이언트는 서버의 응답을 기다리지 않고, 응답 이벤트가 발생했을때 처리
일대일 상호 작용의 종류
- 요청/응답(request/response): 클라이언트는 요청을 하고 응답을 대기하며, 서비스간 강한 결합
- 비동기 요청/응답(asynchronous request/response): 클라이언트는 서버에 요청을 하고 응답을 기다리며 블로킹하지 않고, 서버는 비동기로 응답하여 결합도 낮음
- 단방향 알림(one-way notification): 클라이언트는 서버에 이벤트 등의 발생만 요청 하고, 서버의 응답을 대기하지 않으며, 서버도 별도의 클라이언트로의 응답은 불필요
일대다 상호 작용의 종류
- 발행/구독(publish/subscribe): 클라이언트는 메시지를 발행하고, 관심있는 서버가 메시지를 처리
- 발행/비동기 응답(publish/asynchronous response): 클라이언트는 요청 메시지를 발행하고, 주어진 시간 동안 관련 서비스가 응답하길 대기
마이크로서비스의 API
서비스API는 서버(서비스)와 클라이언트 간의 약속으로 클라이언트가 호출 가능한 작업과, 서비스가 발행하는 이벤트로 구성되며, 작업에는 이름, 매개변수, 반환형 등으로 구성된다. 또한 타입과 필드를 가지는 이벤트는 사전에 정의된 채널에 발행되게 된다. 서비스API는 IDL(Interface Definition Language)로 정확히 정의가 필요하다.
시맨틱 버저닝
시맨틱 버저닝(Semantic Versioning)은 소프트웨어의 버전 변경 규칙 관련 내용으로, Semantic Versioning을 줄여서 SemVer이라고도 한다.
- MAJOR: API 호환성이 깨질만한 큰 변경 사항을 API에 반영
- MINOR: 하위 호환성 지키면서 API 기능이 추가 등 변경이 발생되는 것
- PATCH: 하위 호환성 지키는 범위 내에서 오류 수정 등
추가로 다음의 제약조건도 따르는 것이 권장 된다.
- MAJOR Version이 올라가면 MINOR Version과 PATCH Version은 0으로 리셋
- MINOR Version이 올라가면 PATCH Version이 0으로 리셋
- 정식배포전에 pre-release는 -또는 . 을 사용
- MAJOR에 0으로 시작하는 경우(0.y.z)는 초기 개발 버전에만 사용
이러한 버저닝 정보는 REST API인 경우 URL의 경로 첫번째에 할당하는 형태로 사용 가능하며, 또는 HTTP프로토콜의 MIME 타입 내부에 포함시켜 클라이언트가 지원하는 버전을 지정하는 등의 방법도 있다.
GET /order/xyz HTTP/1.1
Accept: application/vnd.example.resource+json; version=1메시지 포맷
API는 추후 어떤 개선이 발생될지 예측이 어렵고, 아예 다른 언어를 사용하여 재개발이 이뤄질 수도 있다. 따라서 메시지 포맷은 특정 언어/플랫폼에 종속되지 않는 형태로 선택하는 것이 중요하다. 예를 들어 JAVA의 직렬화(Java serialization)은 Java 언어에 종속된 방식이므로 python 등 타 언어로 연동, 호출하거나 API를 개선하는데 장애가 될 수 있어 배제하는 것이 합리적이다.
텍스트 메시지 포맷
XML이나 JSON 등의 텍스트 기반의 포맷은 하위 호환성 유지나, human readablity에서 장점을 갖는다. 그러나 메시지가 많이 길어진다는 단점(XM은 특히 더)이 있어 통신 지연 또는 저장공간을 많이 차지하는 문제가 된다.
바이너리 포맷
Protocol buffer, Avro, Thrift 등 텍스트 기반의 메시징에 성능(특히 throughput) 문제를 해결하기 위한 바이너리 기반의 메시징 포맷이다. 각 기술에 따른 버전 비교는 다음 링크를 참고하자. 중요한 것은, 언어에 독립적이고 높은 성능을 낼 수 있는 기술을 선택하는 것이 필요하다.
Protocol Buffers, Avro, Thrift & MessagePack
작성자: Ilya Grigorik (2011년 8월 1일) - 기계번역 by chatGPT구글에서 새로운 개발자가(‘누글러’라고 불림) 코드를 탐구하기 시작하면 가장 먼저 눈에 띄는 점 중 하나는 Protocol Buffers(PB)가 구글에서 "데이터의 언어"라는 점입니다. 간단히 말해, Protocol Buffers는 직렬화(serialization), 원격 프로시저 호출(RPC), 그리고 그 사이의 거의 모든 작업에 사용됩니다.
PB는 원래 2000년대 초에 최적화된 서버 요청/응답 프로토콜로 개발되었습니다(그래서 이름도 이렇게 붙여졌습니다). 이후로 구글에서 기본 데이터 유지 형식과 RPC 프로토콜로 자리 잡았습니다. 2008년에 대규모(v2) 재작성 후, 구글은 PB를 오픈 소스로 공개하였으며, 현재는 다양한 서드파티 확장 덕분에 루비를 포함한 수십 가지 언어에서 사용할 수 있습니다.
하지만 Protocol Buffers가 모든 것에 사용된다고요? 구글에서는 이 방식이 효과적인 것 같지만, 중요한 점은 이러한 도구들이 개발된 역사적 맥락을 이해하는 것이 기능을 비교하고 속도를 벤치마크하는 것만큼 중요하다는 것입니다.
Protocol Buffers vs. Thrift
PB와 그 "경쟁자들"을 비교해봅시다. 여기에는 많은 도구들이 있는데, PB, Thrift, Avro, MessagePack 중 어떤 것이 최고일까요? 사실 그들 모두 훌륭하며 각자 강점이 있습니다. 따라서 답은 개인적인 선택일 뿐만 아니라, 각 도구가 개발된 역사적 배경과 사용자의 요구사항을 올바르게 이해하는 것에 달려있습니다.Protocol Buffers가 처음 개발되었을 때(2000년대 초), 구글에서 선호하는 언어는 C++이었습니다(현재는 Java도 동등하게 사용됨). 따라서 PB가 강력한 타입을 가지고 있으며 별도의 스키마 파일과 컴파일 단계가 있어 메시지를 읽고 직렬화하는 데 필요한 언어별 보일러플레이트를 생성한다는 것은 놀랍지 않습니다. 이를 위해 구글은 proto 파일을 지정하는 IDL(인터페이스 정의 언어)을 정의하고, PB의 디자인 범위를 자바, C++, 파이썬에서 사용되는 일반적인 타입과 속성의 효율적인 직렬화로 제한했습니다. 따라서 PB는 기존의 RPC 메커니즘 위에 계층화되도록 설계되었습니다.
비교하자면, 2007년 후반에 페이스북에서 오픈 소스화한 Thrift는 PB와 매우 유사하게 보입니다. 아마도 PB의 디자인에서 어느 정도 영향을 받은 것 같습니다. 그러나 PB와 달리 Thrift는 RPC를 중요한 요소로 다룹니다. Thrift 컴파일러는 다양한 전송 옵션(네트워크, 파일, 메모리)을 제공하며 더 많은 언어를 지원하려고 시도합니다.
둘 중 어떤 것이 더 나은가요? 두 도구 모두 대규모 프로덕션 환경에서 테스트되었기 때문에 사용자의 상황에 따라 다릅니다. 주로 바이너리 직렬화에 관심이 있거나 이미 RPC 메커니즘을 가지고 있다면 Protocol Buffers를 시작점으로 삼는 것이 좋습니다. 반면, 아직 RPC 메커니즘이 없고 이를 찾고 있다면 Thrift를 고려해볼 만합니다. (주의사항: 역사적으로 Thrift는 모든 언어에서 기능 지원과 성능이 일관되지 않았으니 조사를 해보세요.)
Protocol Buffers vs. Avro, MessagePack
Thrift와 PB가 범위에서 주로 다르다면, Avro와 MessagePack은 최근의 동적 언어와 JSON의 인기에 비추어 비교해야 합니다. 대부분의 웹 개발자가 알다시피, JSON은 이제 어디서나 쓰이며 구문 분석, 생성 및 읽기가 쉬워서 인기가 많습니다. 또한 JSON은 스키마가 필요 없고, 타입 검사가 없으며, UTF-8 기반 프로토콜이기 때문에 다루기 쉽지만 네트워크 전송 시 매우 효율적이지는 않습니다.MessagePack은 효율적인 바이너리 인코딩을 제공하는 JSON과 같습니다. JSON처럼 타입 검사나 스키마가 없기 때문에 애플리케이션에 따라 이 점이 장점이 될 수도 있고 단점이 될 수도 있습니다. 그러나 이미 API를 통해 JSON을 스트리밍하거나 스토리지로 사용하고 있다면 MessagePack은 거의 그대로 교체해 사용할 수 있습니다.
반면 Avro는 약간 하이브리드적인 성격을 띕니다. 기능 면에서 PB와 Thrift에 가깝지만, Avro는 동적 언어를 염두에 두고 설계되었습니다. PB와 Thrift와 달리 Avro 스키마는 메시지 헤더에 직접 포함되어 있어 추가적인 컴파일 단계가 필요하지 않습니다. 게다가 스키마 자체는 JSON 블롭으로, 별도의 파서가 필요 없습니다! Avro는 스키마를 강제함으로써 데이터 프로젝션(각 레코드에서 개별 필드를 읽는 것), 타입 검사, 그리고 메시지 구조를 강제할 수 있습니다.
"최고의" 직렬화 형식
구글에서의 Protocol Buffers 사용과 위의 경쟁자들을 반영해보면, 하나의 확정적 "최고"의 옵션은 없다는 것이 분명합니다. 각 솔루션은 개발된 맥락에서 완벽한 의미를 가지며, 따라서 동일한 논리를 자신의 상황에 적용해야 합니다.강력한 타입을 가진 직렬화 형식을 찾고 있다면 Protocol Buffers가 훌륭한 선택입니다. 또한 다양한 내장 RPC 메커니즘이 필요하다면 Thrift를 조사할 가치가 있습니다. 이미 JSON을 교환하거나 작업 중이라면 MessagePack은 거의 그대로 교체해 최적화할 수 있습니다. 마지막으로 강력한 타입 특성을 원하지만 동적 언어와의 상호 운용성을 쉽게 유지하고 싶다면 Avro가 현재로서는 가장 적합한 선택일 수 있습니다.
에이브로(Avro), 프로토콜 버퍼(Protocol Buffers) 그리고 스리프트(Thrift)의 스키마 변경(evolution)
동기 RPI(Remote Procedure Invocation) 패턴
RPI는 클라이언트가 서버에 요청을 보내면, 서버가 해당 요청을 처리하고 결과를 응답하는 IPC(interprocess communication)이다. 클라이언트는 서버의 응답이 오기까지 계속 대기하는 blocking 방식이 기본이다. 일부 reactive nonblocking 형태로 클라이언트를 만들어 서버의 응답을 기다리지 않을 수 있으나, 서버의 응답이 필요한 시간내에 완료될 것을 기대하는 형태로 동작한다.
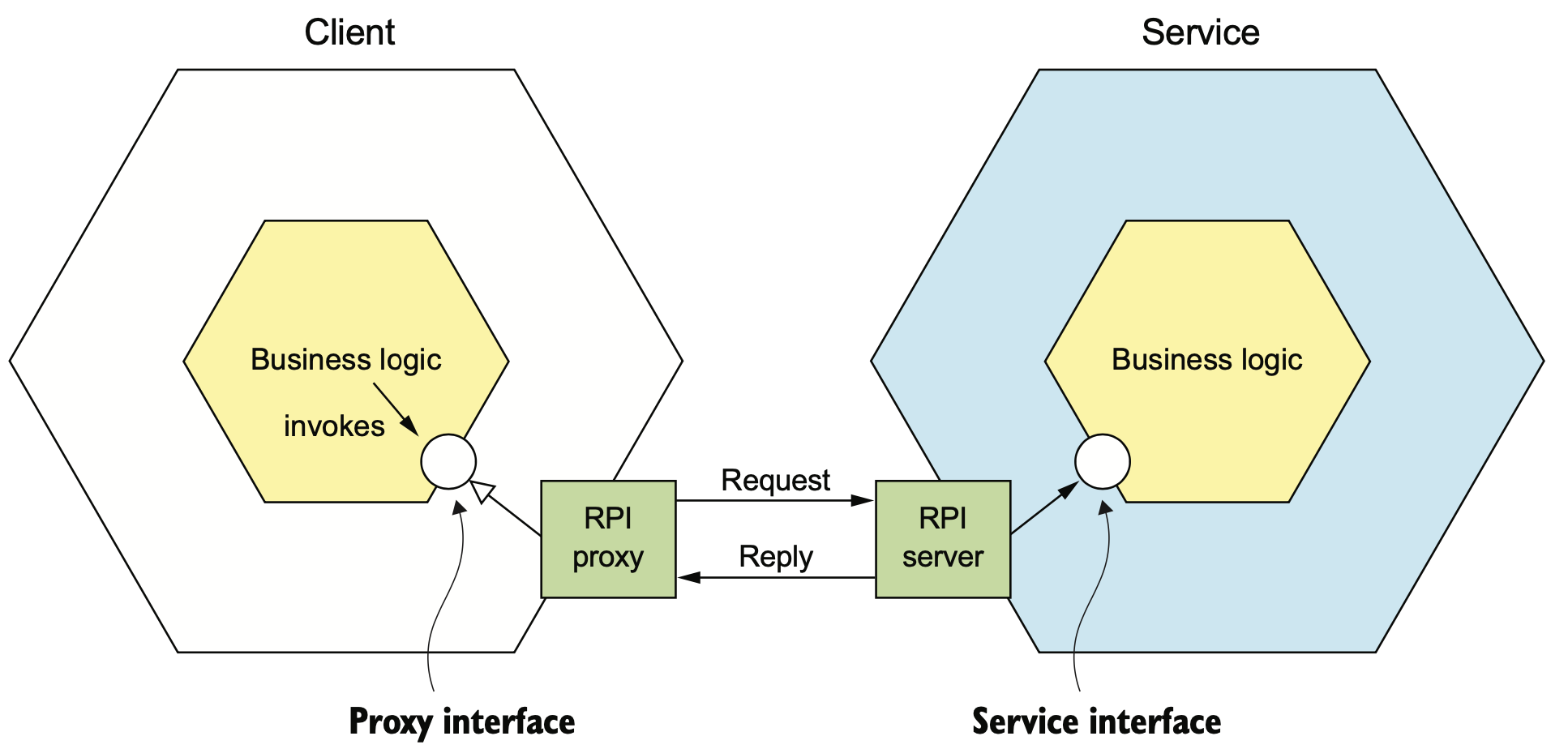
The client’s business logic invokes an interface that is implemented by an RPI proxy adapter class. The RPI proxy class makes a request to the service. The RPI server adapter class handles the request by invoking the service’s business logic.
REST
REST는 HTTP를 기반으로 하는 통신 방식으로, HTTP의 동사(verb)를 활용하여 URL에 리소스에 대한 요청(생성, 삭제, 갱신, 조회)를 수행하는 형태이다. 일반적으로 GET은 조회성으로 사용되며, 응답은 주로 XML 혹은 JSON 형태로 발행하며, POST는 신규 생성, PUT은 갱신 및 DELETE은 삭제를 요청하는 형태이다. 최근 REST의 활용은 대세이지만, 다음 특이사항들이 있다.
- 한번에 많은 리소스를 가져오는데 적합하지 않음
- 한정된 HTTP동사에 맞춰 비즈니스 로직 설계의 복잡함 (/order/{orderId}/cancel 처럼 동사로 부족한 cancel을 처리하기위한 최종 리소스 정의 등 필요)
- 요청/응답의 형태만 지원 가능
이러한 단점때문에 GraphQL이나, Netflix Falcor 같은 유사 기술도 소개되고 있다. 그러나 이 책은 IPC 자체에 대한 내용을 기술하는 것이 목적이 아니기 때문에 별도 학습이 필요한 부분이다.
Richardson 성숙도 모델: REST로 향하는 단계 (기계 번역/요약)
(레너드 리처드슨이 개발한) 이 모델은 REST 접근 방식의 주요 요소를 세 단계로 나누어 설명하며, 여기에는 리소스, HTTP 메서드, 그리고 하이퍼미디어 제어가 포함됩니다.
2010년 3월 18일
마틴 파울러 (원문링크)
목차
- 레벨 0
- 레벨 1 - 리소스
- 레벨 2 - HTTP 메서드
- 레벨 3 - 하이퍼미디어 제어
- 각 레벨의 의미
최근 나는 동료들이 작업 중인 Rest In Practice라는 책의 초안을 읽었습니다. 그들의 목표는 Restful 웹 서비스가 기업이 직면한 통합 문제를 어떻게 해결할 수 있는지 설명하는 것입니다. 이 책의 핵심 개념은 웹이 잘 작동하는 대규모 분산 시스템의 존재 증거라는 것이며, 이 아이디어를 통해 통합 시스템을 더 쉽게 구축할 수 있다는 것입니다.
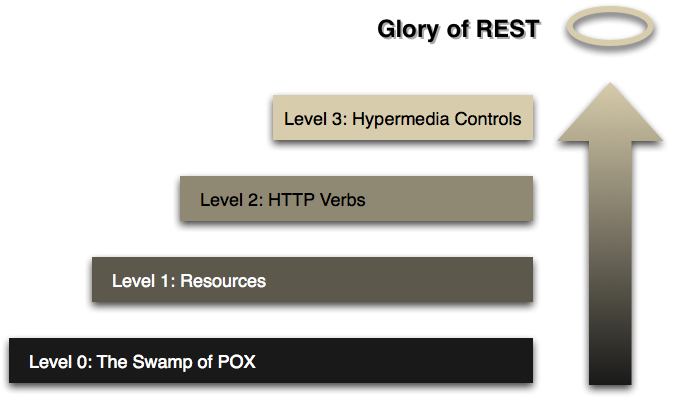
Steps toward REST
레벨 0
이 모델의 시작점은 HTTP를 원격 상호작용을 위한 전송 시스템으로 사용하지만 웹의 메커니즘을 사용하지 않는 것입니다. 즉, HTTP를 자체 원격 상호작용 메커니즘을 위한 터널링 시스템으로 사용하는 방식입니다.
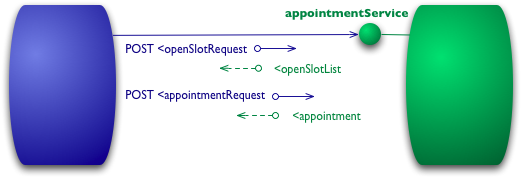
An example interaction at Level 0
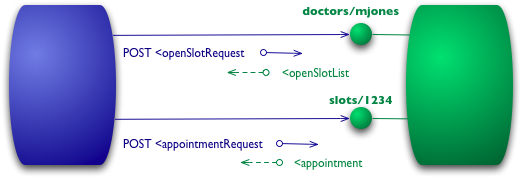
예를 들어, 내가 의사와 예약을 하고 싶다면 예약 소프트웨어는 특정 날짜에 의사의 빈 슬롯을 알아내기 위해 병원 예약 시스템에 요청을 보냅니다. 레벨 0 시나리오에서는 병원이 URI로 서비스 엔드포인트를 노출하고, 나는 요청 내용을 포함한 문서를 그 엔드포인트로 전송합니다.
POST /appointmentService HTTP/1.1 [various other headers] <openSlotRequest date = "2010-01-04" doctor = "mjones"/>서버는 내가 요청한 정보를 포함한 문서를 반환합니다.
HTTP/1.1 200 OK [various headers] <openSlotList> <slot start = "1400" end = "1450"> <doctor id = "mjones"/> </slot> <slot start = "1600" end = "1650"> <doctor id = "mjones"/> </slot> </openSlotList>다음으로, 예약을 하려면 또다시 문서를 엔드포인트로 전송합니다.
POST /appointmentService HTTP/1.1 [various other headers] <appointmentRequest> <slot doctor = "mjones" start = "1400" end = "1450"/> <patient id = "jsmith"/> </appointmentRequest>모든 것이 잘 되면 예약이 완료되었다는 응답을 받습니다.
HTTP/1.1 200 OK [various headers] <appointment> <slot doctor = "mjones" start = "1400" end = "1450"/> <patient id = "jsmith"/> </appointment>만약 예약에 문제가 있다면 다음과 같은 에러메시지를 포함한 응답을 받습니다.
HTTP/1.1 200 OK [various headers] <appointmentRequestFailure> <slot doctor = "mjones" start = "1400" end = "1450"/> <patient id = "jsmith"/> <reason>Slot not available</reason> </appointmentRequestFailure>이 시점에서 우리는 단순히 XML을 주고받는 전통적인 원격 프로시저 호출(RPC) 스타일 시스템을 사용하고 있습니다.
레벨 1 - 리소스
레벨 1로 올라가면서 리소스를 도입합니다. 이제는 단일 서비스 엔드포인트에 모든 요청을 보내는 대신, 개별 리소스와 상호작용을 시작합니다.
Level 1 adds resources
POST /doctors/mjones HTTP/1.1 [various other headers] <openSlotRequest date = "2010-01-04"/>응답은 여전히 같은 정보를 포함하지만, 이제 각 슬롯은 개별적으로 주소를 지정할 수 있는 리소스가 됩니다.
HTTP/1.1 200 OK [various headers] <openSlotList> <slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/> <slot id = "5678" doctor = "mjones" start = "1600" end = "1650"/> </openSlotList>이제 특정 슬롯에 대한 예약은 해당 슬롯의 URI에 POST 요청을 보냄으로써 이루어집니다.
POST /slots/1234 HTTP/1.1 [various other headers] <appointmentRequest> <patient id = "jsmith"/> </appointmentRequest>이 방식은 객체 지향 프로그래밍의 객체 정체성 개념과 유사합니다. 특정 객체에 메서드를 호출하는 방식으로 상호작용합니다.
레벨 2 - HTTP 메서드
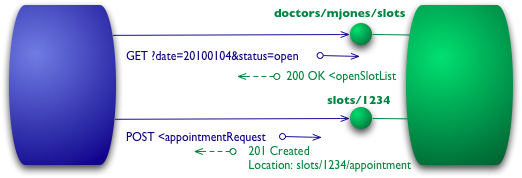
레벨 2에서는 HTTP 메서드를 보다 HTTP 본래의 방식에 맞게 사용하기 시작합니다. 예를 들어, 슬롯 목록을 가져오려면 이제 GET을 사용합니다.
Level 2 addes HTTP verbs
GET /doctors/mjones/slots?date=20100104&status=open HTTP/1.1 Host: royalhope.nhs.uk조회 요청에 대하여 1단계와 유사하게 응답을 받게 됩니다.
HTTP/1.1 200 OK [various headers] <openSlotList> <slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/> <slot id = "5678" doctor = "mjones" start = "1600" end = "1650"/> </openSlotList>응답은 이전과 동일하지만, 중요한 차이점은 GET이 안전한 작업으로 정의된다는 것입니다. 이는 캐싱을 허용하며, 웹 성능을 높이는 데 중요한 요소입니다. 예약을 위해서는 상태를 변경하는 POST 또는 PUT을 사용합니다.
예약을 위해서는 이제 HTTP 동사를 활용하여 요청하게 됩니다.POST /slots/1234 HTTP/1.1 [various other headers] <appointmentRequest> <patient id = "jsmith"/> </appointmentRequest>위 요청에서 POST 라는 동사와 /slots/1234 라는 리소스를 사용하여 요청한 것을 확인할 수 있다. POST외 PUT을 사용하여 변경 등을 처리할 수 있으며, 예약 요청 성공 시 201 응답 코드와 새 리소스의 URI가 제공되어 client는 필요시 GET 동사를 사용하여 현재 리소스에 대한 상태를 조회할 수 있게 된다.
HTTP/1.1 201 Created Location: slots/1234/appointment [various headers] <appointment> <slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/> <patient id = "jsmith"/> </appointment>실패 시 409 Conflict와 같은 명시적인 HTTP 응답 코드를 사용합니다.
HTTP/1.1 409 Conflict [various headers] <openSlotList> <slot id = "5678" doctor = "mjones" start = "1600" end = "1650"/> </openSlotList>이 응답에서 중요한 부분은 문제가 발생했음을 나타내기 위해 HTTP 응답 코드를 사용하는 것입니다. 이 경우, 누군가가 리소스를 호환되지 않는 방식으로 이미 업데이트했음을 나타내기 위해 409 코드가 적절한 선택입니다. 200 응답 코드를 사용하고 오류 응답을 포함시키는 대신, 레벨 2에서는 명시적으로 이러한 오류 응답을 사용합니다. 어떤 코드를 사용할지는 프로토콜 설계자의 판단에 달려 있지만, 오류가 발생할 경우 2xx가 아닌 응답 코드를 사용해야 합니다. 레벨 2는 HTTP 동사(verbs)와 HTTP 응답 코드를 사용하는 것을 도입합니다.
여기에는 모순이 있습니다. REST 지지자들은 모든 HTTP 동사를 사용하는 것에 대해 이야기합니다. 그들은 REST가 웹의 실질적인 성공에서 교훈을 얻으려고 한다고 정당화하지만, 실제로 전 세계 웹에서는 PUT이나 DELETE가 자주 사용되지 않습니다. PUT과 DELETE를 더 자주 사용하는 것이 합리적인 이유가 있지만, 그것이 웹의 존재 증거에서 기인한 것은 아닙니다.
웹이 존재하면서 지지되는 핵심 요소는 안전한 작업(GET 등)과 안전하지 않은 작업 간의 강력한 분리, 그리고 상태 코드(status code)를 사용하여 발생한 오류 유형을 소통하는 것입니다.
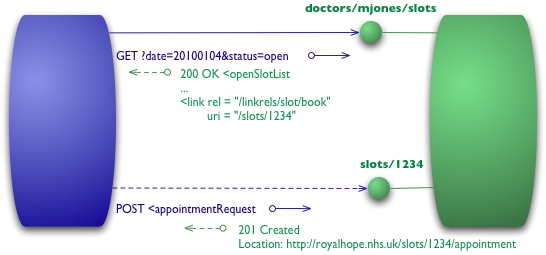
레벨 3 - 하이퍼미디어 제어
레벨 3에서는 하이퍼미디어 제어(HATEOAS)를 도입합니다. 응답에 하이퍼미디어 링크를 포함하여 다음 작업을 어떻게 해야 하는지 클라이언트에게 알립니다.
Level 3 adds hypermedia controls
우선 클라이언트는 level 2와 동일하게 GET 요청을 합니다.
GET /doctors/mjones/slots?date=20100104&status=open HTTP/1.1 Host: royalhope.nhs.uk그러나 level 3의 응답은 기존 level 2와 달리 새로운 항목(link)이 추가됩니다.
HTTP/1.1 200 OK [various headers] <openSlotList> <slot id = "1234" doctor = "mjones" start = "1400" end = "1450"> <link rel = "/linkrels/slot/book" uri = "/slots/1234"/> </slot> <slot id = "5678" doctor = "mjones" start = "1600" end = "1650"> <link rel = "/linkrels/slot/book" uri = "/slots/5678"/> </slot> </openSlotList>이제 각 슬롯에는 예약을 어떻게 할 수 있는지 알려주는 URI를 포함한 링크 요소가 있습니다.
하이퍼미디어 제어의 핵심은 우리가 다음에 무엇을 할 수 있는지, 그리고 그 작업을 수행하기 위해 어떤 리소스를 조작해야 하는지를 알려주는 것입니다. 예약 요청을 어디로 전송해야 하는지 미리 알고 있을 필요 없이, 응답 내의 하이퍼미디어 제어가 이를 안내해줍니다.
POST 요청은 다시 레벨 2에서 사용했던 것과 동일하게 작성됩니다.POST /slots/1234 HTTP/1.1 [various other headers] <appointmentRequest> <patient id = "jsmith"/> </appointmentRequest>이제 답변에는 201 정상으로 예약되었다는 답변과 함께, 다음에 할 작업들에 대한 링크를 제공하게 됩니다.
Location: http://royalhope.nhs.uk/slots/1234/appointment [various headers] <appointment> <slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/> <patient id = "jsmith"/> <link rel = "/linkrels/appointment/cancel" uri = "/slots/1234/appointment"/> <link rel = "/linkrels/appointment/addTest" uri = "/slots/1234/appointment/tests"/> <link rel = "self" uri = "/slots/1234/appointment"/> <link rel = "/linkrels/appointment/changeTime" uri = "/doctors/mjones/slots?date=20100104&status=open"/> <link rel = "/linkrels/appointment/updateContactInfo" uri = "/patients/jsmith/contactInfo"/> <link rel = "/linkrels/help" uri = "/help/appointment"/> </appointment>이러한 하이퍼미디어 제어는 클라이언트가 서버의 URI 체계를 몰라도 상호작용할 수 있게 해주며, 서버가 새로운 기능을 클라이언트에게 광고할 수 있게 합니다.
하이퍼미디어 컨트롤의 분명한 장점 중 하나는 서버가 URI 스킴을 변경하더라도 클라이언트가 깨지지 않도록 할 수 있다는 점입니다. 클라이언트가 “addTest” 링크 URI를 참조하기만 하면, 서버 팀은 초기 진입점 외의 모든 URI를 자유롭게 변경할 수 있습니다.또 다른 장점은 클라이언트 개발자가 프로토콜을 탐색하는 데 도움이 된다는 점입니다. 링크는 클라이언트 개발자에게 다음에 어떤 작업을 할 수 있을지 힌트를 제공합니다. 링크가 모든 정보를 제공하지는 않지만, 예를 들어 “self”와 “cancel” 컨트롤이 동일한 URI를 가리킬 때, 클라이언트는 하나는 GET이고 다른 하나는 DELETE라는 것을 스스로 파악해야 합니다. 하지만 이 링크들은 더 많은 정보를 찾기 위한 출발점을 제공하고, 프로토콜 문서에서 유사한 URI를 찾는 데 도움이 됩니다.
마찬가지로, 서버 팀은 응답에 새로운 링크를 추가하여 새로운 기능을 광고할 수 있습니다. 클라이언트 개발자가 알지 못하는 링크를 주의 깊게 살핀다면, 이 링크들은 추가적인 탐색을 유도하는 트리거가 될 수 있습니다.
하이퍼미디어 컨트롤을 표현하는 데 절대적인 표준은 없습니다. 여기서는 REST in Practice 팀의 현재 권장 사항을 따랐으며, ATOM(RFC 4287)을 기준으로 했습니다. ATOM에서는 요소를 사용하고, 대상 URI를 위해 uri 속성을, 관계를 설명하기 위해 rel 속성을 사용합니다. 잘 알려진 관계(예: 해당 요소 자체에 대한 참조인 'self')는 단순히 표현되며, 서버에 특정한 것은 완전히 명시된 URI를 사용합니다. ATOM에서는 잘 알려진 링크 관계 정의가 링크 관계 레지스트리에 정의되어 있으며, ATOM은 레벨 3 REST의 선두 주자로 인정받고 있습니다.
각 레벨의 의미
리처드슨 성숙도 모델은 REST의 요소를 단계별로 이해하는 데 유용합니다.
- 레벨 1은 복잡성을 처리하기 위해 '분할 정복' 방식을 적용하여, 하나의 큰 서비스 엔드포인트를 여러 개의 리소스로 분해하는 문제를 해결합니다.
- 레벨 2는 표준화된 HTTP 동사를 도입하여 유사한 상황을 동일한 방식으로 처리하게 하여 불필요한 변동성을 제거합니다.
- 레벨 3은 '발견 가능성'을 도입하여 프로토콜을 더 자체적으로 문서화할 수 있는 방법을 제공합니다. 이 모델의 결과는 우리가 제공하려는 HTTP 서비스 유형에 대해 생각하게 하고, 해당 서비스와 상호작용하고자 하는 사람들의 기대를 조율하는 데 도움이 됩니다.
gRPC
HTTP의 한정된 동사만 사용 가능한 이슈의 해소를 위한 gRPC는 protocol buffer를 활용한 이진 메시지 기반의 프로토콜이다. gRPC API는 이진 메시지 기반이므로 요청/응답 메시지 정의(definition)가 필요하며, 프로토콜 버퍼의 필드 번호, 타입코드 기반으로 메시치 처리가 가능하다.
gRPC Summary (링크)
gRPC에서는 아직 브라우저 관련 API가 제공되지 않기 때문에 브라우저에서 직접 gRPC 서비스를 호출하는 것은 불가능합니다. 또한 기존 데이터 통신과 다르게 텍스트 기반이 아니라 Encoding 된 Binary Stream이기 때문에 사람이 읽기는 어렵죠. 하지만 아래와 같이 장점이 훨씬 큰 기술이므로 서비스 개발 시 높은 생산성, 다양한 언어, 빠른 속도 등의 좋은 퍼포먼스를 보여줄 것입니다.
1. 특징 및 장점
- 높은 생산성과 효율적인 유지 보수: ProtoBuf의 IDL만 정의하면 높은 성능을 보장하는 서비스와 메시지에 대한 소스코드가 자동으로 생성
- 다양한 언어와 플랫폼 지원: IDL을 활용한 서비스 정의 한 개로 다양한 언어와 플랫폼에서 동작하는 서버와 클라이언트 코드가 생성
- HTTP/2 기반의 양방향 스트리밍: 서버와 클라이언트가 서로 동시에 데이터를 스트리밍으로 주고받음
- 높은 메시지 압축률과 성능: HTTP/2에 의한 압축뿐만 아니라 protoBuf에 의한 메시지 정의에 의해서 메시지 크기를 획기적으로 줄임
- 다양한 gRPC 생태계: 필요에 따라 Authentication, Tracing, Load Balancing, Health Checking, API Gateway 등의 다양한 도구 지원
2. When is is used?
거의 모든 서버 시스템 개발에 효율적으로 적용될 수 있지만, 특히 Microservice Architecture 서비스에 적합합니다. 마이크로서비스는 작은 서비스들을 유기적으로 결합해 하나의 응용프로그램을 개발하는 방법론인데요. 구성 서비스가 독립적이기에 개발 및 배포 운영이 용이하여, 확장을 유연하게 할 수 있죠. 때문에 새로운 기술 도입 및 변경에도 용이한 면을 보입니다.하지만 분산 시스템 특성상 공통 기능의 중복이 발생하여 메모리를 비효율적으로 사용할 수도 있고, 프로그램 규모가 커질 수록 구성원들의 철학이나 기술 스택이 제각기 다르니 운영도 어려워지는데요. 이에 gRPC는 앞서 언급한 특징 덕에 이러한 단점을 보완하며 장점을 극대화 시킬 수 있습니다.
브라우저를 사용하지 않는 백엔드간 서버 통신이나, 자원 한정적인 환경에서도 유용합니다. byte/호출/cpu 수 등으로 과금되는 클라우드 환경에서는 비용 절감의 효과도 생각할 수 있겠네요. 최근엔 시스코, 주니퍼 등 주요 네트워크 장비에서도 grpc를 모두 지원하고 있어 모니터링이나 자동화 등 인프라 운영에도 활용 방안이 많을 것으로 기대합니다.
회로 차단기 패턴(Circuit breaker)
분산 시스템은 다른 서비스를 동기 호출할 때 마다 실패할 가능성이 항상 존재한다. 서비스는 기술적 오류나 과부하, 네트워크 지연, 장애 등으로 인해 응답을 못 받거나, 늦어지는 경우가 발생할 수 있는데, 클라이언트는 응답 도중에 블로킹되므로, 동기 호출된 서비스의 문제가 클라이언트까지 올라가게 되어 전체 시스템이 중단되는 위험성을 가지게 된다. 따라서 부분의 실패가 전체 시스템에 영향을 주지 않도록 시스템을 견고하게 설계를 해야한다. 다른 서비스를 동기 호출(즉, 호출 후 blocking하여 대기하는 경우)하는 경우 스스로를 방어하는 방법은 다음 형태가 있다.
- 네트워크 타임아웃: 응답을 대기하는데 timeout을 생성
- 미처리 요청 개수 제한: 호출자, 즉 클라이언트에서 서비스, 즉 서버에 요청 가능한 최대 미처리 요청 개수(일반적으로 큐에 쌓여 있는 미처리 메시지의 수)를 제한하고, 특정 개수를 초과한 상태에서의 요청은 즉시 에러 처리하는 형태
- 회로 차단기: 성공/실패 처리 현황을 모니터링 하면셔, 에러율이 임계치를 초과하기 시작하면 그 이후의 시도를 바로 실패처리하는 것으로 일정 시간의 타임아웃을 두고, 이후에 재 시도를 통해 정상으로 복구 처리
서비스 디스커버리(Service Discovery)
이전까지는 애플리케이션의 인스턴스는 지정된 물리장비에 설치되는 형태이므로 대부분 정적 주소를 가지고 있었다. 그러나 Cloud Native 등으로 전환이 진행되면서, 마이크로서비스의 애플리케이션들은 인스턴스마다 네트워크 위치들이 동적으로 배정되거나, 자동 확장/축소, 장애 대응 등의 다양한 사유로 인해 변화할 요인 지속 발생된다. 따라서 애플리케이션은 사전에 어떤 주소에 접속해야 할지 파악할 수 없으며, 필요한때에 동적으로 파악해야 한다. 결과적으로, 서비스 인스턴스의 네트워크 위치를 DB화하는 서비스 레지스트리를 통해 애플리케이션의 서비스 인스턴스의 네트워크 위치를 파악할 수 있도록 관리하는 서비스 디스커버리(service discovery)를 사용해야 한다.
애플리케이션의 서비스 디스커버리
서비스 인스턴스는 자신의 네트워크 위치를 서비스 레지스트리에 등록하고, 서비스 클라이언트는 이 서비스 레지스트리로부터 전체 서비스 인스턴스의 목록을 확보하고, 확보된 리스트 중 우선순위에 따라 특정 서비스 인스턴르소 라우팅을 수행하는 형식이다. 이는 크게 두가지 서비스 패턴을 조합한 형태이다.
패턴: 자가등록
서비스 인스턴스는 서비스 레지스트리에 자기 자신을 등록한다.
패턴: 클라이언트의 디스커버리
서비스 클라이언트는 서비스 레지스트리에 있는 가용 서비스 인스턴스 목록을 조회하고 부하 분산한다.
자가 등록이란 서비스 인스턴스가 기동되면 자신의 네트워크 위치를 레지스트리 등록 API에 연결하여 직접 등록을 요청하는 형태이다. 단순히 등록만으로 충분하지는 않고, health check를 지속 수행해야 등록 후 발생된 장애에 대하여 대응이 가능할 수 있다. 클라이언트는 서비스의 엔드포인트를 직접 파악하는 것이 아니라, 서비스 인스턴스가 등록해 놓은 목록을 레지스트리에 검색하여 받아온 후에 부하분산 형태로 서버를 호출하는 형태로 주로 동작한다.
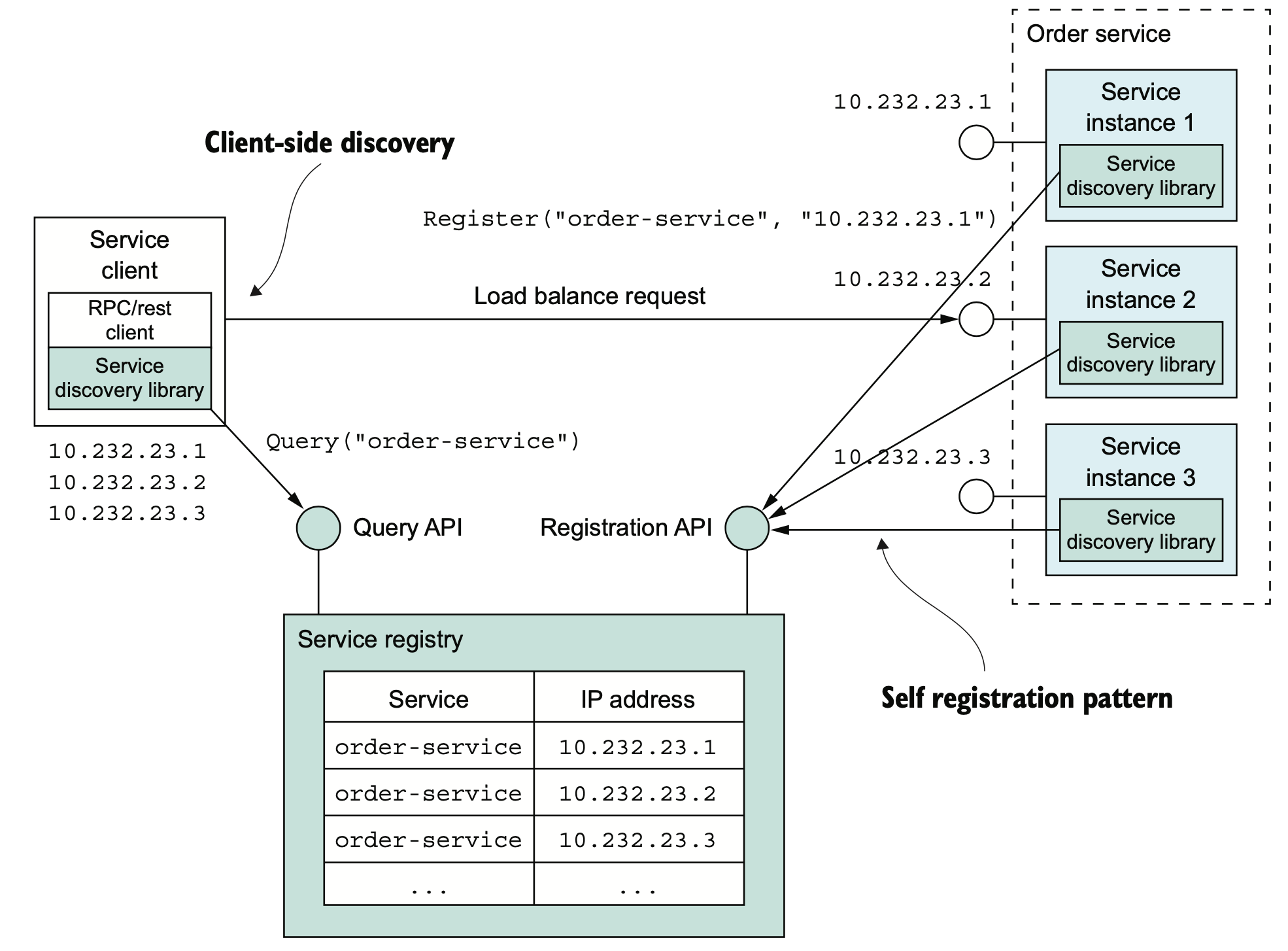
The service registry keeps track of the service instances. Clients query the service registry to find network locations of available service instances.
도커나, 쿠버네티스 등 배포 플랫폼을 사용하면 내장된 디스커버리 패턴을 지원하고, 플랫폼의 라우터를 통해 분배 정책등도 총괄해서 관리한다. 배포 플랫폼이 서비스 등록을 같이 포함하므로 제3자 등록 패턴 및 서버 측 디스커버리 패턴도 사용한다.
패턴: 서드파티 등록
서드파티가 서비스 인스턴스를 서비스 레지스트리에 자동 등록한다.
패턴: 서버 쪽 디스커버리
클라이언트가 서비스 디스커버리를 담당한 라우터에 요청한다.
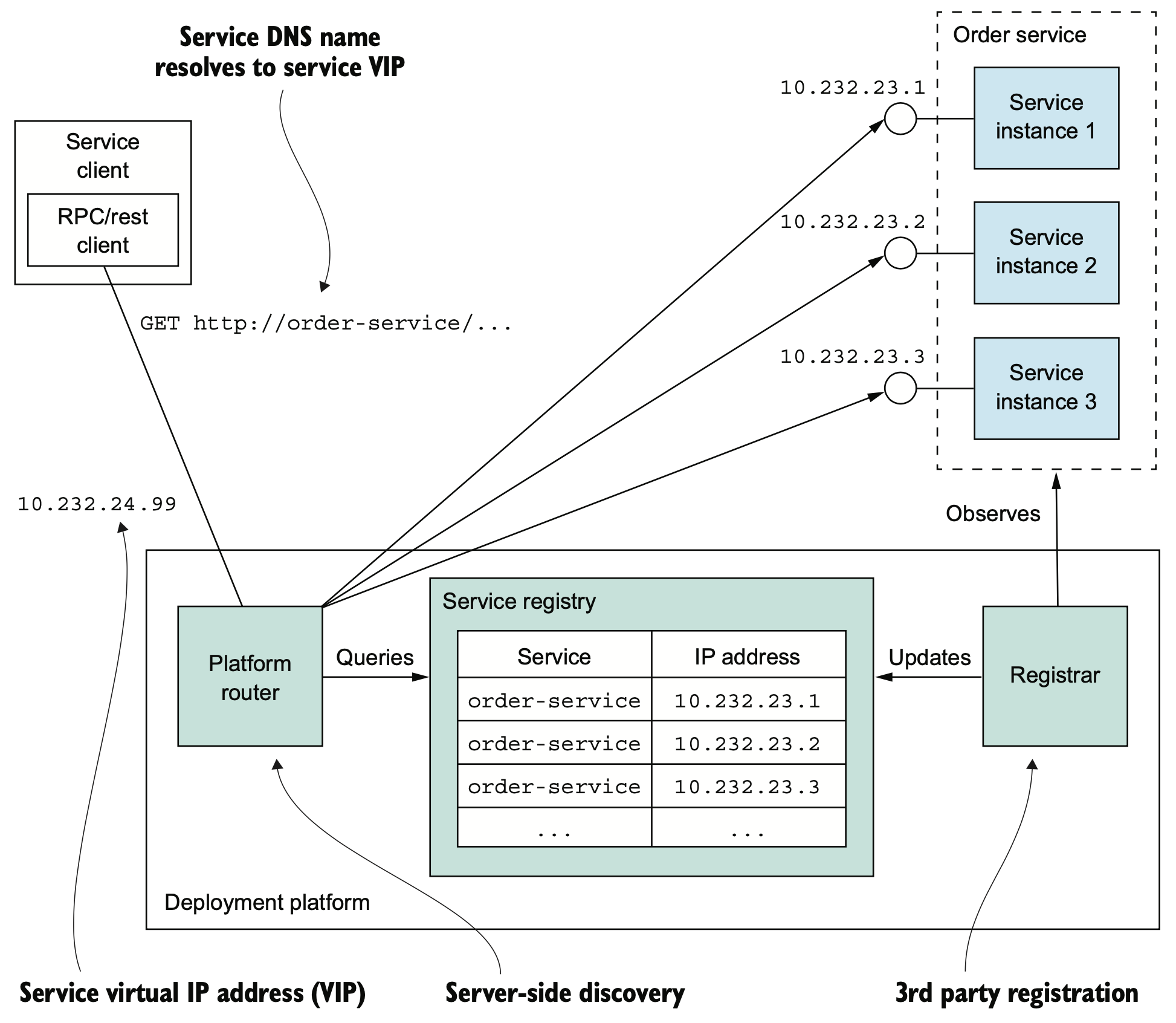
The platform is responsible for service registration, discovery, and request routing. Service instances are registered with the service registry by the registrar. Each service has a network location, a DNS name/virtual IP address. A client makes a request to the service’s network location. The router queries the service registry and load balances requests across the available service instances.
비동기 메시징 패턴
패턴: 메시징
클라이언트는 비동기 메시징을 통해 서비스를 호출한다.
메시징은 서비스가 메시지를 서로 비동기적으로 주고받는 통신 방식이다. 일반적으로 메시지를 중개하는 브로커(broker)를 포함하여 구성되지만, 일부 brokerless 아키텍처도 있다. 비동기 통신 방식이므로, 클라이언트는 서비스에 메시지를 보내고 블로킹 하지 않고 다음 업무를 처리하는 형태이다.
메시징
메시지는 헤더(header)와 본문(body)으로 구성된다. 헤더는 메타 데이터의 키/값 쌍으로 주로 구성되며, 본문은 실제 데이터가 된다. 메시지는 채널을 통해 교환되며, 채널은 점대점(point-to-point) 또는 발행-구독(publish-subcribe) 형태의 큐로 구성되어 있다.
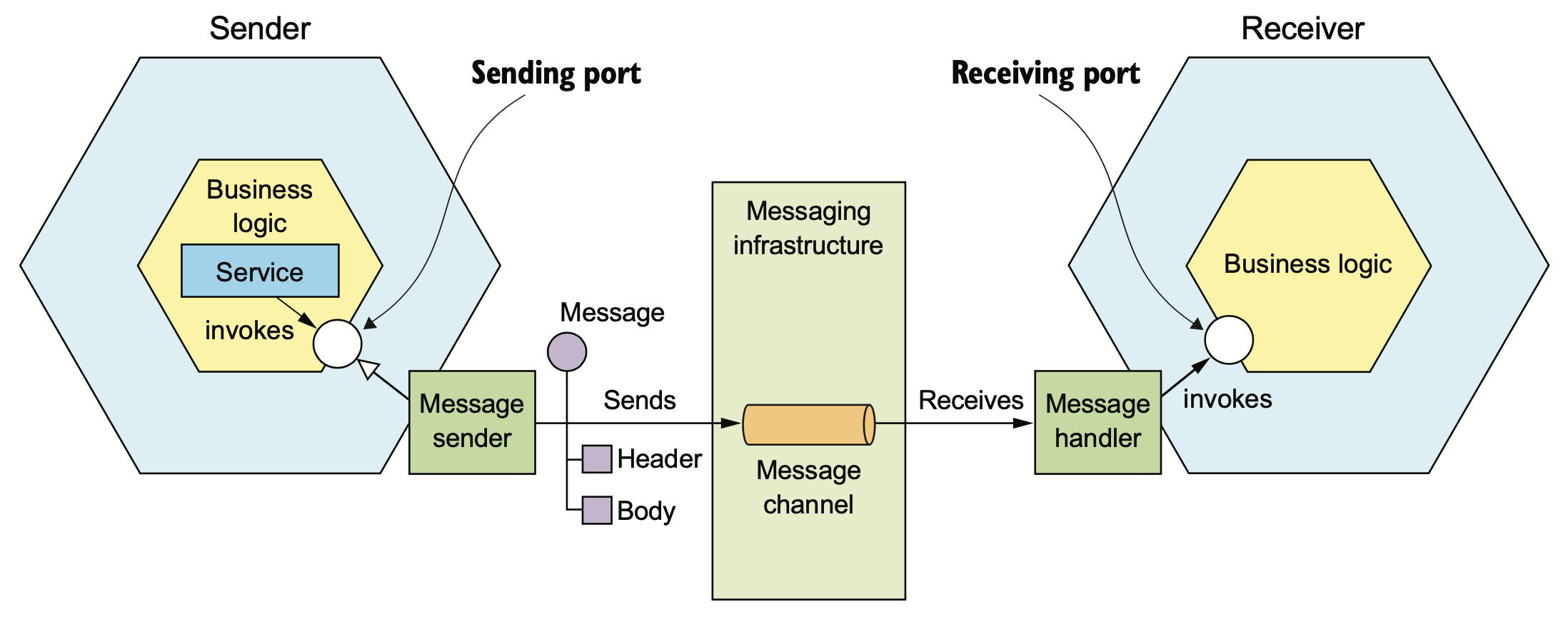
The business logic in the sender invokes a sending port interface, which is implemented by a message sender adapter. The message sender sends a message to a receiver via a message channel. The message channel is an abstraction of messaging infrastructure. A message handler adapter in the receiver is invoked to handle the message. It invokes the receiving port interface implemented by the receiver’s business logic.
Message Pattern
다음 설명의 이미지는 The Stuff That Every Developer Should Know About Message Queues의 내용을 발췌하여 요약한 것이다.
One-way Messaging (단방향 알림)
Producer는 지정된 채널(여기서는 메시지 큐)을 이용하여 해당 채널을 바라보고(일반적으로 polling) 있는 consumer가 어떤 시점(queue에 메시지가 밀려 있다면 늦어질 수 있음)에 message를 확인하여 처리할 것을 기대하고 message를 보내는 형태이다.
Producer는 consumer의 상태나, consumer에서 어떻게 처리할지 등의 세부 사항은 파악할 필요가 없으며, consumer의 응답을 기대하지 않는 형태로, 메시지를 보내는데 producer는 consumer의 응답에 의존적하지 않는 특징이 있다.발행/비동기 응답(Request/ Async. Reply)
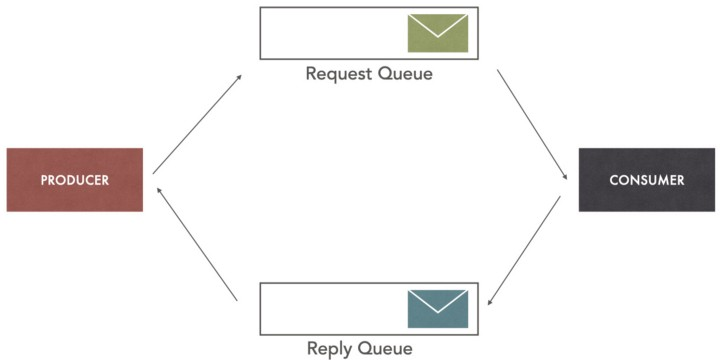
송신 큐(queue)와 응답 큐의 두개로 구성된 형태로 producer는 메시지를 송신 큐에 기록하고, 응답 큐에 해당 메시지에 대한 응답이 오기를 기다리고 있는 형태이다. 앞에서 처리한 동기 메시지와 유사한 동작을 할 수 있으며(producer가 consumer로 부터의 응답을 blocking형태로 기다리게 할 수도 있음), 장애 상황등을 대비하기 위해 기대하는 기간 이내에 응답이 오지 않는다면, 메시지를 다시 보내거나 혹은 timeout 등의 예외 처리 로직을 만들 수 있다.
일반적인 경우는 producer는 메시지에 대하여 응답이 올때까지 기다리면서 예외 처리를 하지 않고, 응답이 오면 별도로 처리하도록 구성하여 비동기로 처리하는 형태로 구성된다. 예를 들어 주문 생성 버튼을 눌렀을때 클라이언트는 서버(서비스)에 주문 생성 요청을 보내고, 응답이 완료될때까지 기다리지 않고 랜딩페이지로 넘어가서 다음 상호작용을 하면서 reply 큐에 응답이 오는지를 polling하다가 응답이 오면 주문 생성 완료 페이지로 넘어가는 형태로 구성할 수 있다.발행/구독(Pub/Sub)
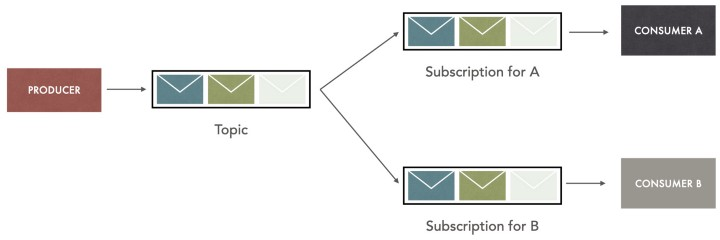
Producer는 메시지에 관심사(topic)을 지정하여 발행하여 채널의 큐에 적재하면 각 consumer들이 자신의 관심사를 기반으로 메시지를 가져가는 형태이다. Consumer는 message에 대해서 경쟁하지 않고 오직 topic에만 관심을 갖는 형태로, consumer들은 특정한 메시지의 filter를 만들고, 발행 된 메시지 중 filter를 통과한 메시지에 대해서만 구독하여 처리하게 된다. 따라서 consumer는 producer가 누구인지 등에 의존하지 않으며, producer도 생성한 메시지가 어떤 consumer에서 처리했는지에 대해 관심이 없어 상호 의존적이지 않다. 하나의 토픽에 생성된 메시지는 관심이 있는 consumer에 복제되어 분배될 수 있으므로 여러 consumer에 동시에 메시지를 전달하는데 유용하다.메시징 자체에 대하여 더 공부하고 싶으면, 위의 링크를 참고하거나 다음 동영상 Message Queue Fundamentals Explained in 20 Minutes 을 참고하자.

메시지 브로커
메시징 시스템을 설계할 때, 메시지 브로커를 사용할지 브로커리스(brokerless) 방식을 선택할지 결정하는 것은 시스템의 아키텍처와 성능에 중대한 영향을 미치며, 두 접근법 모두 각각의 장점과 단점이 있으며 세부 사항은 교재보다는 외부 내용을 정리한다.
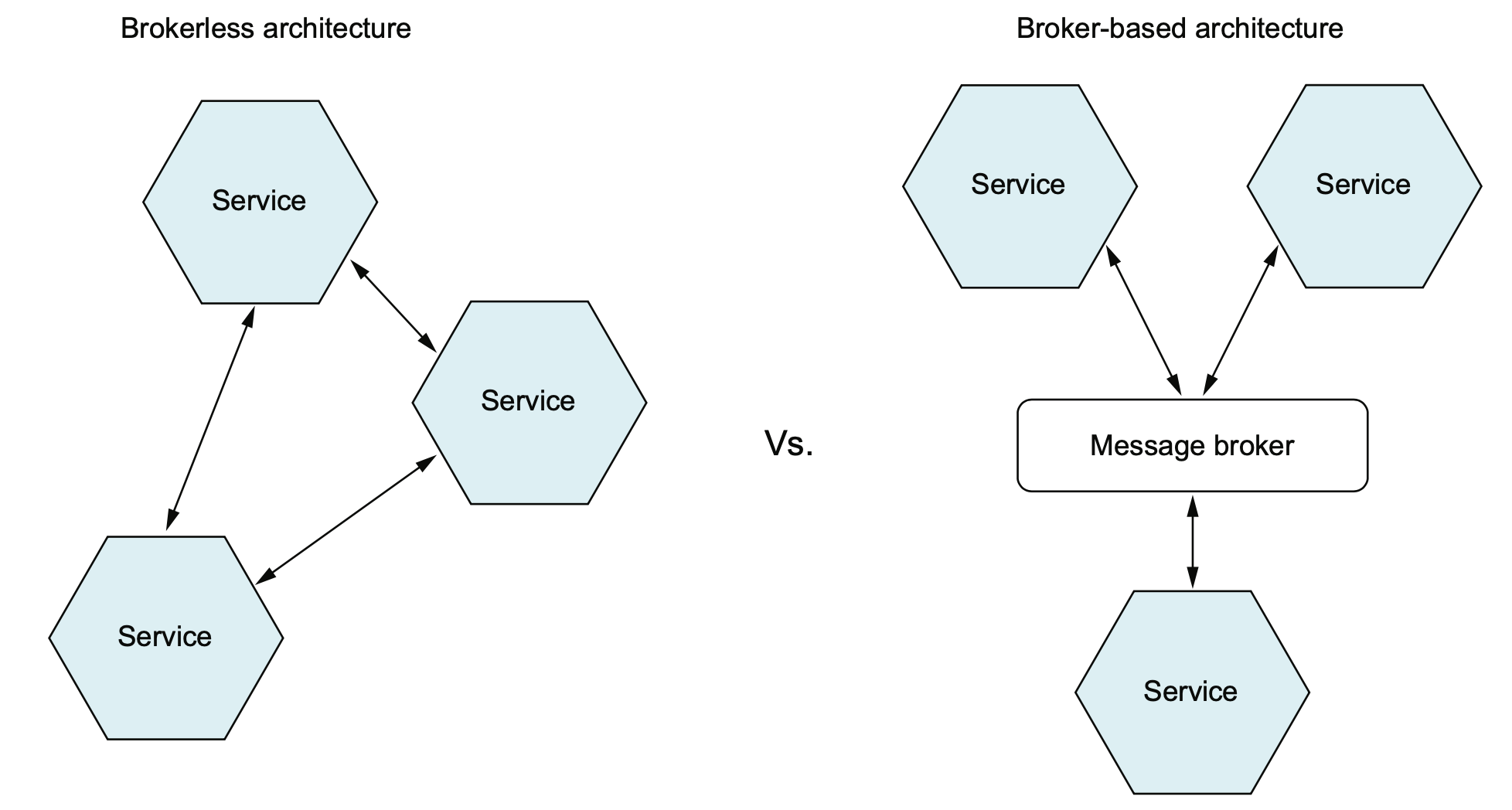
The services in brokerless architecture communicate directly, whereas the services in a broker-based architecture communicate via a message broker.
브로커리스 메시징 (Brokerless Messaging)
브로커리스 메시징에서는 중앙 중개자 없이 서비스 간 직접 통신이 이루어지는 형태이다. 대표적으로 gRPC, ZeroMQ 등이 사용된다.
장점:
- 지연 감소: 메시지가 직접 전달되므로 중개자에 의한 지연이 줄어듦.
- 단순성: 브로커 관리 필요 없이 빠르고 간단하게 통신 가능.
- 성능 최적화: 대용량 처리에 적합하며, 메시지가 중개 과정을 거치지 않으므로 성능이 극대화될 수 있음.
단점:
- 내결함성 부족: 메시지 손실에 대한 복구 메커니즘이 부족.
- 복잡한 라우팅 부재: 메시지 전달을 위한 복잡한 라우팅이나 변환 기능이 제공되지 않음.
- 일관성 문제: 메시지 전달 보장이 약하므로 메시지 손실 위험이 있음.
한계:
- 서비스가 동시 실행되어야 함.
- 메시지 전달 실패 시 별도의 재전송 로직을 구현해야 함.
메시지 브로커 기반 메시징(Broker-based Messaging)
메시지 브로커는 중앙 집중형 중개자가 메시지를 관리하고 전달하는 방식으로, 대표적으로 Apache Kafka, RabbitMQ 등이 있다.
장점:
- 확장성: 메시지 큐를 통해 여러 소비자에게 메시지를 분산 가능.
- 내결함성: 브로커가 메시지 저장 및 재처리 기능 제공.
- 복잡한 라우팅 및 변환: 다양한 라우팅 및 메시지 필터링 기능을 지원.
단점:
- 단일 장애 지점(SPOF): 브로커가 중단되면 전체 시스템에 영향을 미침.
- 추가적인 유지보수 비용: 브로커 설정, 관리 및 모니터링 필요.
- 지연: 브로커의 중개 과정에서 처리 지연이 발생할 수 있음.
한계:
- 고가용성과 성능을 유지하려면 추가적인 인프라 설정이 필요.
- 처리량이 높은 환경에서는 복잡도가 증가.
브로커 기반과 브로커리스의 비교
항목 메시지 브로커 브로커리스 메시징 지연 중간 브로커로 인해 지연 발생 가능 중개자 없이 바로 전달, 지연 최소화 확장성 높은 확장성, 다양한 소비자 지원 직접 통신으로 확장성 제한적 내결함성 메시지 저장 및 재처리 지원 내결함성 부족, 재전송 로직 필요 복잡도 브로커 설정 및 관리 필요 간단한 통신 구조 라우팅 및 변환 복잡한 라우팅 및 메시지 변환 지원 직접 통신, 라우팅 및 변환 없음 메시지 브로커는 내결함성, 확장성, 복잡한 메시지 라우팅을 제공하지만, 유지보수 및 지연 문제를 해결해야 하며, 브로커리스 메시징은 성능과 단순성 측면에서 유리하지만, 메시지 손실 방지 및 복구 메커니즘이 부족하여 문제가 될 수 잇다. 따라서 일반적으로 대규모 엔터프라이즈 환경에서는 메시지 브로커가 유리할 수 있으며, 실시간 데이터 전송과 단순한 시스템에서는 브로커리스 메시징이 적합할 수 있다.
주로 사용되는 Apache Kafka, RabbitMQ, ActiveMQ와 같은 전통적인 메시지 브로커와 AWS Kinesis, AWS SQS, Azure Service Bus와 같은 클라우드 메시징 서비스의 특징을 보면 다음과 같다.
메시지 브로커
Apache Kafka
- 장점: 실시간 데이터 스트리밍 및 대규모 처리에 탁월. 확장성이 뛰어나며 내결함성을 보장.
- 단점: 설정이 복잡하고 처리 지연이 발생할 수 있음.
- 사용 사례: 실시간 로그 처리, 대용량 이벤트 스트리밍.
RabbitMQ
- 장점: 설정이 간단하고 메시지 라우팅이 강력. 우선순위 및 TTL 관리 가능.
- 단점: 처리량이 제한적이며 확장 시 관리가 어려울 수 있음.
- 사용 사례: 비동기 작업 처리, 간단한 메시지 큐잉.
ActiveMQ
- 장점: 다양한 프로토콜 지원, 유연한 클러스터링. 내결함성 보장.
- 단점: 높은 트래픽 시 성능 저하 가능. 관리에 오버헤드 발생.
- 사용 사례: 복잡한 엔터프라이즈 메시징, 다양한 통신 프로토콜이 필요한 환경.
클라우드 기반 메시징 서비스
AWS Kinesis
- 장점: 실시간 스트리밍 데이터 처리에 최적화. 무한 확장 가능.
- 단점: 설정이 복잡하며, 대량 데이터 처리 시 비용 증가.
- 사용 사례: 실시간 로그 분석, IoT 데이터 처리.
AWS SQS
- 장점: 저렴한 비용의 관리형 서비스로 비동기 메시지 큐잉 제공. 내결함성 뛰어남.
- 단점: 메시지 순서 보장이 기본적으로 없고, 복잡한 라우팅 기능 부재.
- 사용 사례: 비동기 데이터 교환, 주문 처리 시스템.
Azure Service Bus
- 장점: 복잡한 메시징 패턴과 보안성을 제공. 다양한 프로토콜 지원.
- 단점: 고급 기능 사용 시 비용 증가. 설정이 복잡할 수 있음.
- 사용 사례: 대규모 B2B 메시징, 복잡한 워크플로우 관리.
| 항목 | Apache Kafka | RabbitMQ | ActiveMQ | AWS Kinesis | AWS SQS | Azure Service Bus |
|---|---|---|---|---|---|---|
| 확장성 | 매우 뛰어남 | 제한적 | 유연한 클러스터링 가능 | 무한 확장 가능 | 자동 확장 지원 | 유연한 확장성 |
| 주요 사용 사례 | 대규모 데이터 처리 | 비동기 작업 처리 | 복잡한 엔터프라이즈 메시징 | 실시간 데이터 스트리밍 | 비동기 메시지 큐잉 | 복잡한 워크플로우 관리 |
| 메시지 순서 보장 | 보장 가능 | 큐 기반으로 순서 보장 | 큐 및 토픽 기반 메시징 | 스트리밍 순서 보장 | FIFO 선택 시 가능 | 기본적으로 순서 보장 |
| 보안성 | 적절함 | 적절함 | 고급 보안 기능 제공 | AWS IAM과 통합 | AWS IAM과 통합 | 고급 보안 및 인증 기능 제공 |
| 비용 | 사용량에 따라 변동 | 저비용 | 중간 | 사용량에 따라 변동 | 저비용 | 사용량 및 기능에 따른 비용 변동 |
- 전통적 메시지 브로커: Apache Kafka는 대규모 실시간 스트리밍에, RabbitMQ는 비동기 작업 처리에, ActiveMQ는 다양한 프로토콜을 지원하는 복잡한 엔터프라이즈 메시징에 적합
- 클라우드 메시징 서비스: AWS Kinesis는 실시간 대규모 데이터 스트리밍에, AWS SQS는 저비용 비동기 큐잉에, Azure Service Bus는 복잡한 메시징 패턴 및 워크플로우 관리에 유리
분산 시스템에서 메시지 큐와 메시지 브로커 비교
(원문 링크) - ChatGPT번역
현대의 분산 컴퓨팅 시스템에서 다양한 애플리케이션과 시스템 간의 통신은 필수적입니다. 특히, 마이크로서비스 아키텍처에서는 이러한 통신을 가능하게 하는 방법으로 메시징 시스템이 필수적으로 사용됩니다. 여기서 메시지 큐(Message Queue)와 메시지 브로커(Message Broker)는 널리 사용되는 기술이지만, 많은 사람들이 이 둘의 차이를 혼동하거나 동일한 것으로 취급하는 경향이 있습니다. 이 글에서는 메시지 큐와 메시지 브로커의 주요 차이점을 설명하고, 이 두 기술을 어떤 상황에서 사용하는 것이 적합한지 살펴보겠습니다. 또한, 메시지 큐와 메시지 브로커를 동시에 사용할 수 있는지 여부에 대해서도 설명합니다. 이 글을 읽고 나면 메시지 큐와 메시지 브로커의 개념과 그 차이점에 대해 명확한 이해를 할 수 있을 것입니다.
메시지 큐와 메시지 브로커의 개요
메시지 큐와 메시지 브로커는 분산 애플리케이션 간의 통신을 용이하게 하는 두 가지 유형의 미들웨어입니다. 메시지 큐는 비동기적으로 메시지를 송수신할 수 있는 메커니즘을 제공합니다. 이를 통해 송신 애플리케이션과 수신 애플리케이션이 서로 독립적으로 작동할 수 있으며, 시스템의 유연성과 확장성을 높입니다. 반면 메시지 브로커는 송신자와 수신자 사이에서 메시지를 라우팅하고, 추가적인 기능(예: 변환, 메시지 강화 등)을 제공하는 중개 역할을 합니다.
메시지 큐란 무엇인가?
메시지 큐는 분산 시스템에서 널리 사용되는 메시징 패턴 중 하나로, 소프트웨어 구성 요소나 시스템 간에 비동기적으로 데이터를 교환할 수 있게 하는 메커니즘입니다. 메시지 큐는 주로 다음과 같은 방식으로 동작합니다:
- 프로듀서(Producer): 송신 애플리케이션이 메시지를 큐에 전송합니다.
- 큐: 메시지는 큐에 저장되어 수신 애플리케이션이 준비될 때까지 대기합니다.
- 컨슈머(Consumer): 준비가 된 수신 애플리케이션은 큐에서 메시지를 가져가 처리합니다.
메시지 큐는 송신 애플리케이션과 수신 애플리케이션을 분리(디커플링)함으로써 두 시스템이 동시에 동작할 필요가 없도록 만듭니다. 이는 시스템의 유연성을 크게 높이며, 확장성과 장애 내성을 보장하는 데 중요한 역할을 합니다.
메시지 큐의 주요 특징
- 비동기 통신: 송신자와 수신자가 동시에 작동할 필요가 없습니다. 메시지는 큐에 저장되어 나중에 처리됩니다.
- 단순성과 경량성: 메시지 큐는 신뢰성 있는 메시지 전달을 위해 설계되었으며, 상대적으로 간단하고 가볍습니다.
- 메시지 순서 보장: 메시지가 큐에 입력된 순서대로 처리될 수 있도록 보장합니다(FIFO 방식).
- 메시지 필터링: 큐는 특정 조건에 맞는 메시지들을 필터링할 수 있어, 필요에 따라 소비자가 특정 메시지만 처리할 수 있도록 지원합니다.
메시지 브로커란 무엇인가?
메시지 브로커는 송신자와 수신자 간의 통신을 중개하는 서비스로, 다양한 시스템 또는 구성 요소들 간의 메시지 교환을 관리합니다. 메시지 브로커는 메시지를 라우팅하고, 메시지의 형식을 변환하며, 필요에 따라 메시지를 필터링하는 등의 역할을 수행합니다. 또한, 브로커는 퍼블리시/서브스크라이브(publish/subscribe) 모델을 지원하여 송신자는 하나 이상의 토픽이나 채널에 메시지를 게시하고, 수신자는 해당 토픽이나 채널에 구독하여 메시지를 받을 수 있습니다.
메시지 브로커의 주요 특징
- 엔터프라이즈 환경 적합성: 복잡한 메시징 시나리오에서 사용되며, 주로 대규모 엔터프라이즈 시스템에서 활용됩니다.
- 다양한 메시징 패턴: 퍼블리시/서브스크라이브 모델이나 요청/응답(request/reply) 모델을 지원합니다.
- 메시지 변환 및 라우팅: 송신자와 수신자 간의 메시지를 서로 다른 형식이나 프로토콜로 변환하고, 메시지를 특정 규칙에 따라 다양한 목적지로 라우팅할 수 있습니다.
- 로드 밸런싱: 메시지를 여러 소비자에게 분산하여 시스템 과부하를 방지하고, 작업을 균형 있게 분배할 수 있습니다.
- 장애 내성: 메시지 브로커는 높은 가용성과 장애 내성을 제공하며, 시스템 장애 발생 시에도 자동으로 복구됩니다.
메시지 큐와 메시지 브로커의 차이점
두 기술은 목적과 기능이 다릅니다. 메시지 큐는 간단한 비동기 메시지 전송에 주로 사용되며, 메시지 브로커는 보다 복잡한 메시징 시나리오에서 다양한 추가 기능을 제공합니다. 다음은 주요 차이점들입니다:
메시지 큐 메시지 브로커 단순한 비동기 메시지 전달 복잡한 라우팅, 필터링, 변환 기능 송신자와 수신자를 직접 연결 송신자와 수신자 사이의 중개 역할 FIFO 방식의 순차적 메시지 처리 다양한 라우팅 및 메시지 전달 방식 작은 규모의 시스템에 적합 대규모 엔터프라이즈 환경에 적합 어떤 기술을 선택해야 할까?
메시지 큐와 메시지 브로커는 각각의 장점이 있으므로, 상황에 맞게 선택해야 합니다. 예를 들어, 단순한 비동기 통신이 필요하다면 메시지 큐를 사용하는 것이 좋습니다. 반면에, 복잡한 메시지 라우팅이나 변환, 다중 시스템 간의 통합이 필요한 상황에서는 메시지 브로커가 적합합니다.
메시지 큐가 자주 사용되는 산업 및 사례
- 금융 서비스: 거래 처리 및 트랜잭션 관리
- 전자상거래: 주문 처리 및 재고 관리
- 의료: 환자 데이터 관리 및 임상 워크플로우
메시지 브로커가 자주 사용되는 산업 및 사례
- 사물인터넷(IoT): 센서 데이터 수집 및 분석
- 통신: 메시지 라우팅 및 중재
- 물류: 공급망 관리 및 추적
결론
메시지 큐는 메시지를 저장하고 전달하는 시스템이며, 메시지 브로커는 이러한 메시지를 관리하고 라우팅하는 역할을 하는 소프트웨어 구성 요소입니다. 두 기술은 각각의 장점을 가지고 있으며, 시스템 요구사항에 맞게 적절히 선택하거나 함께 사용할 수 있습니다.
메시징을 도입할때 필수로 고려해야 할 사항은 메시징 순서 유지와 확장성(scale out)이다. 이 두 문제는 상호간 충돌을 가져올 수도 있는 문제이지만, 최근의 메시지 브로커들은 샤딩(sharded)된 채널을 이용하여 문제를 해결 가능하다.
수신자 경합 문제와 확장성, 메시지 순서 보장
메시징 시스템에서 수신자 경합(Receiver Contention) 문제는 여러 수신자가 동일한 메시지를 처리하려고 할 때 발생하며, 처리할 메시지가 늘어나서 수신자를 확대하면 경합이 더욱 증가할 수 있고, 동시에 메시지 순서를 보장하는 것은 더욱 복잡해지게 된다.
수신자 경합 문제의 원인
메시징 시스템에서 여러 수신자가 동일한 큐에 접근하여 메시지를 처리를 시도할때 동시에 동일 메시지에 접근하려고 하는 수신자 경합 문제는 경쟁 상태를 초래한다. 이러한 경합 문제를 해결하지 않으면 시스템 성능 저하와 신뢰성 문제로 이어지게 될 수 있어 해결이 필요하다.
- 동시 메시지 처리 시도: 여러 수신자가 동일한 메시지를 동시에 가져가려 할 때 경합이 발생
- 부하 불균형: 특정 수신자에게 메시지가 집중될 경우, 과부하가 걸리고 다른 수신자들은 빈번하게 작업 없이 대기하는 상황이 발생
- 메시지 중복 처리: 메시지 처리 중 실패하거나 경합이 발생하여 메시지가 중복 처리될 위험
수신자 경합 문제 해결 방안
파티셔닝(Partitioning)은 메시지 큐나 스트림을 여러 개의 논리적 파티션으로 분할하여 각 파티션에 수신자를 할당하는 방법이다.
- 병렬 처리: 파티션이 각각 독립적으로 운영되므로 다수의 수신자가 병렬로 메시지를 처리
- 경합 감소: 각 파티션에 고유한 수신자를 배치함으로써 수신자 간 경합을 감소
- 확장성 증가: 시스템을 쉽게 확장할 수 있으며, 파티션 수를 늘려 더 많은 수신자를 투입해 처리 성능 향상
순서 토큰화(Ordering Tokens)는 메시지의 순서를 보장하기 위해 사용하며, 메시지에 순서 식별자를 부여하고 수신자는 이를 기반으로 처리하는 방식이다.
- 순서 보장: 토큰을 기반으로 메시지가 처리되므로 메시지의 순서를 유지
- 순차 처리: 수신자는 메시지를 수신할 때 순서가 맞는지 확인하고 순차적으로 처리
락(Lock)을 사용하여 동시 접근 문제를 해결하는 방법으로 특정 수신자가 메시지를 처리할 때 락을 걸어 다른 수신자가 동일한 메시지를 처리하지 못하도록 처리하여 경합을 방지할 수 있으나, 성능에 영향을 미칠 수 있다.
재처리 메커니즘으로 수신자가 메시지를 제대로 처리하지 못했을 때 이를 다시 처리하는 것고, 메시지 대기열(dead-letter queue)을 사용하여 처리되지 않은 메시지를 저장하는 형태로 실패한 메시지는 대기열에 저장한 후에 나중에 다시 처리하는 방법이다.
확장성을 확보하면서도 수신자 경합 문제를 최소화하기 위해서는 파티셔닝과 메시지 순서 토큰화, 동시성 제어와 재처리 메커니즘 등을 활용하는 아키텍처 설계가 필요하다.
중복 메시지 처리
일반적인 메시지 브로커는 최소한 한번의 메시지가 전달되는 것을 보장한다. 그러나 클라이언트나, 네트워크, 혹은 메시지 브로커의 장애 등으로 인해 중복으로 메시지가 전달되는 경우가 발생할 수 있다. 만약 구매 메시지를 중복 처리하거나, 금액 차감 메시지를 중복 처리한다면 중복 주문, 결제금액 차감 오류 등 비즈니스에 큰 영향을 미칠 수 있는 문제가 발생될 수 있기 때문에 반드시 중복메시지 처리하는 방법이 필요하다.
멱등성
멱등법칙(冪等法則) 또는 멱등성(冪等性, 영어: idempotent)은 수학이나 전산학에서 연산의 한 성질을 나타내는 것으로, 연산을 여러 번 적용하더라도 결과가 달라지지 않는 성질을 의미한다. 멱등법칙의 개념은 추상대수학(특히, 사영작용소·폐포연산자 이론)과 함수형 프로그래밍(참조 투명성의 성질과 관련된)의 여러 부분에서 사용하고 있다.
위키백과
멱등성의 중요성
- 분산 시스템 신뢰성: 마이크로서비스 아키텍처에서는 서비스 간 통신이 빈번합니다. 네트워크 불안정성으로 인해 요청이 중복되거나 실패할 수 있어 멱등성이 중요합니다.
- 장애 복구: 서비스 실패 시 안전하게 재시작하거나 복구할 수 있습니다.
- 성능 최적화: 캐싱과 같은 최적화 기술을 더 쉽게 적용할 수 있습니다.
HTTP 메서드별 멱등성
- GET: 리소스를 조회만 하므로 항상 멱등
- PUT: 리소스를 완전히 대체하므로 멱등
- DELETE: 리소스를 삭제하는 작업이므로 여러 번 수행해도 결과가 같
- POST: 일반적으로 새 리소스를 생성하므로 비멱등이
- PATCH: 리소스의 부분 수정을 위해 사용되며, 구현에 따라 멱등성 차이 발생
멱등성 구현 방법
- 고유 식별자 사용: 각 요청에 고유 ID를 부여하여 중복 처리를 방지합니다.
- 조건부 업데이트: 리소스의 현재 상태를 확인하고 조건에 맞을 때만 업데이트합니다.
- 멱등성 키: 클라이언트가 제공하는 고유 키를 사용하여 중복 요청을 식별합니다.
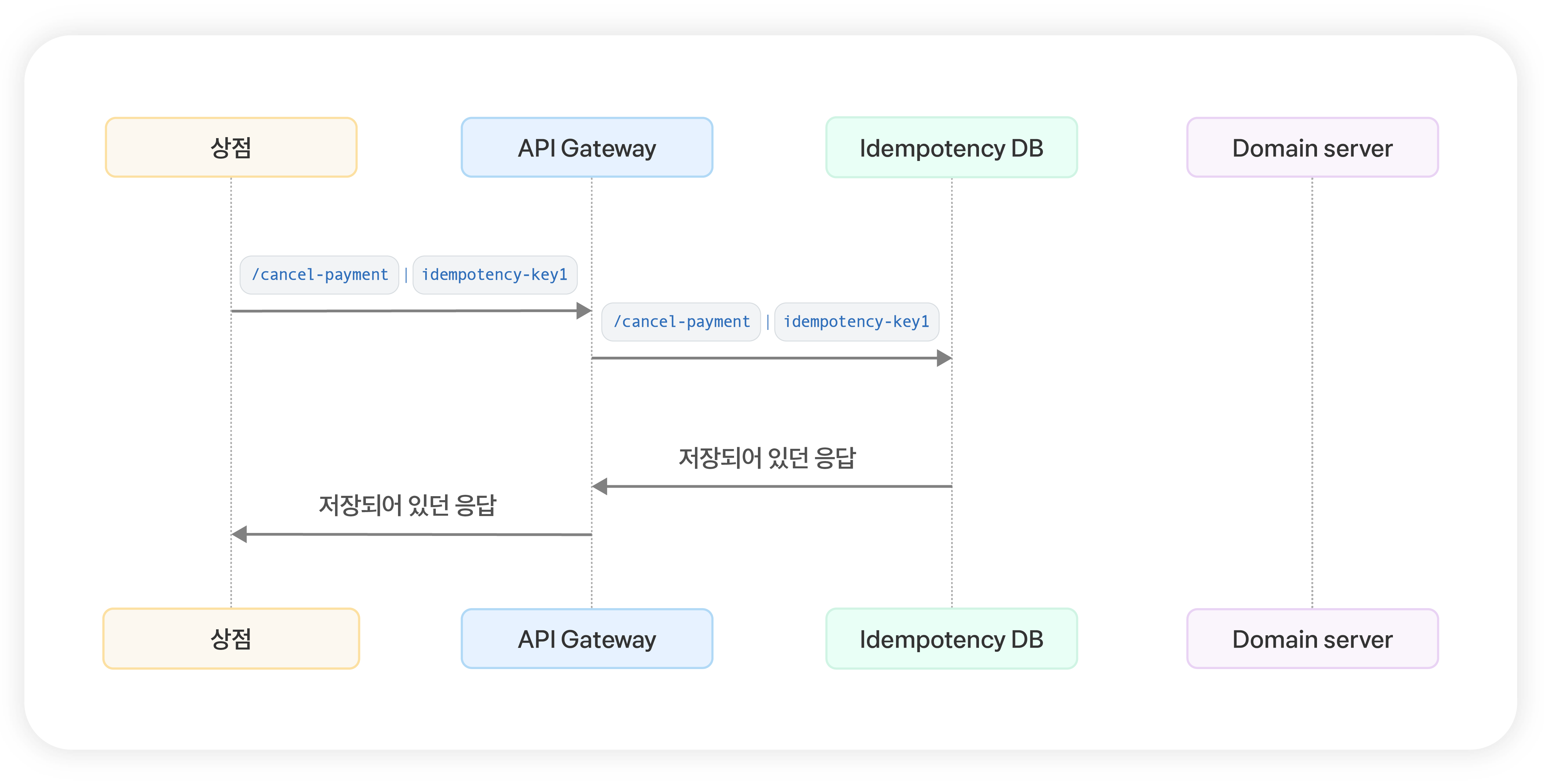
출처: 멱등성이 뭔가요?
from flask import Flask, request, jsonify
import uuid
app = Flask(__name__)
# 결제 정보를 저장할 딕셔너리
payments = {}
@app.route('/api/payment', methods=['POST'])
def process_payment():
idempotency_key = request.headers.get('Idempotency-Key')
if not idempotency_key:
return jsonify({"error": "Idempotency-Key is required"}), 400
# 이미 처리된 요청인지 확인
if idempotency_key in payments:
return jsonify(payments[idempotency_key]), 200
# 새로운 결제 처리
payment_data = request.json
payment_id = str(uuid.uuid4())
# 결제 처리 로직 (실제 구현에서는 더 복잡할 수 있음)
payment_result = {
"id": payment_id,
"amount": payment_data['amount'],
"status": "success"
}
# 결과 저장
payments[idempotency_key] = payment_result
return jsonify(payment_result), 201
if __name__ == '__main__':
app.run(debug=True)
- 클라이언트는 각 요청에 대해 고유한
Idempotency-Key를 제공 - 서버는 이 키를 사용하여 이전에 처리된 요청인지 확인
- 새로운 요청일 경우에만 결제를 처리하고 결과를 저장
- 동일한 키로 재요청이 오면 저장된 결과를 반환
멱등성 에러 시나리오
IETF 명세에는 아래 세 가지 시나리오에 대응하는 방법을 제안한다.
| 에러코드 | 사용 케이스 |
|---|---|
| 400 Bad Request | API 요청에 멱등키가 누락됐거나 형식에 맞지 않는 키 값이 들어왔을 때 |
| 409 Conflict | 동일 멱등키로 이전 요청 처리가 진행 중에 새로운 요청이 들어왔을 때 |
| 422 Unprocessable Entity | 동일한 멱등키로 들어온 요청의 세부 내용(payload)가 기존 요청과 다를 때 |
멱등성 구현의 도전 과제
- 분산 시스템에서의 동시성 관리
- 분산 락(Distributed Lock) 사용
- 낙관적 동시성 제어(Optimistic Concurrency Control) 구현
- 부분 실패 처리
- 트랜잭션 관리 및 롤백 메커니즘 구현
- 보상 트랜잭션(Compensating Transaction) 설계
- 타임아웃 및 재시도 전략
- 지수 백오프(Exponential Backoff) 알고리즘 사용
- 회로 차단기(Circuit Breaker) 패턴 적용
주의사항
- 멱등성 보장은 서버 측의 책임
- 멱등성 키의 저장 기간을 적절히 설정 필요
- 분산 시스템에서는 분산 캐시나 데이터베이스를 사용하여 멱등성을 관리 필요
메시지 추적 및 중복 메시지 필터링
멱등성은 모든 API에서 지원이 가능한 구조가 아니다. 따라서 각 서비스 단위에서 멱등성을 유지하기 위한 기능 개발이 필요하며, 그중 한 방법으로는 메시지를 소비하는 consumer에서 메시지의 ID(위에서 살펴본 Idempotency-Key와 유사)를 이용하여 이미 처리했던 메시지인지를 확인하고 미처리된 메시지만 처리하는 형태로 개발하는 것이다. 메시지 처리 여부를 관리하기 위해서는 별도 DB(서비스의 local DB)에 저장하는 형태를 주로 사용하게 된다.
Transactional Messaging
메시지의 소비 뿐만 아니라 메시지 생성에서도 중복해서 발행되지 않도록 처리해야 한다. 따라서 메시지 브로커에 바로 메시지를 전달하는 것이 아니라 transaction이 관리되는 local DB에 메시지를 기록하고, 트랜잭션 결과를 읽어 메시지 브로커에 보내는 형태가 가능하다.
가용성 개선
동기 통신에 따른 가용성 저하
동기 통신을 사용하면 모든 API가 동시에 가용해야지만 적절한 응답이 가능하다. 따라서 모든 서비스가 가용이어야 한다는 조건을 만족하기가 어려우므로 가용성이 저하되는 문제를 가진다. 동기 통신을 사용하면 발생하는 구조적 한계로 동기 통신을 제외해야지만 해소가 가능하다.
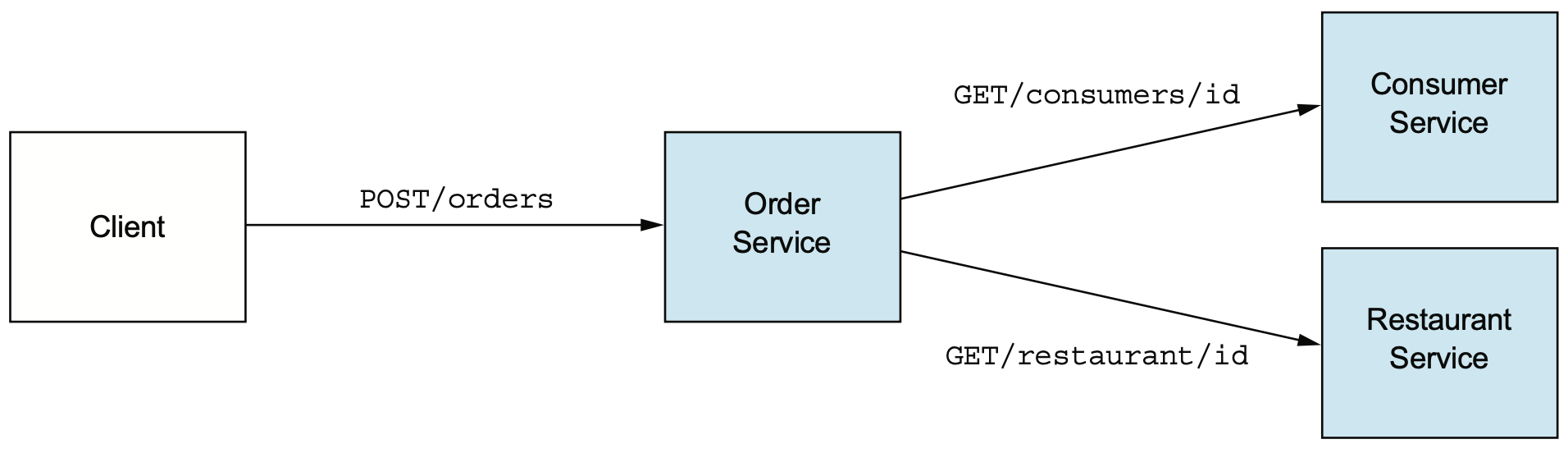
The Order Service invokes other services using REST. It's straightforward, but it requires all the services to be simultaneously available, which reduces the availability of the API.
비동기 통신을 활용한 가용성 확보
비동기 통신을 사용한 상호작용 스타일은 요청 채널과 응답 채널을 분리하여 요청 후 처리를 non-blocking으로 대기하는 형태가 가능하다. 클라이언트로 즉시 혹은 정해진 시간이내에 응답을 보내는 것이 확정되지는 못하지만, 반면에 최종적으로(eventually) 클라이언트의 응답 채널로 결과를 보내주는 형태이다.
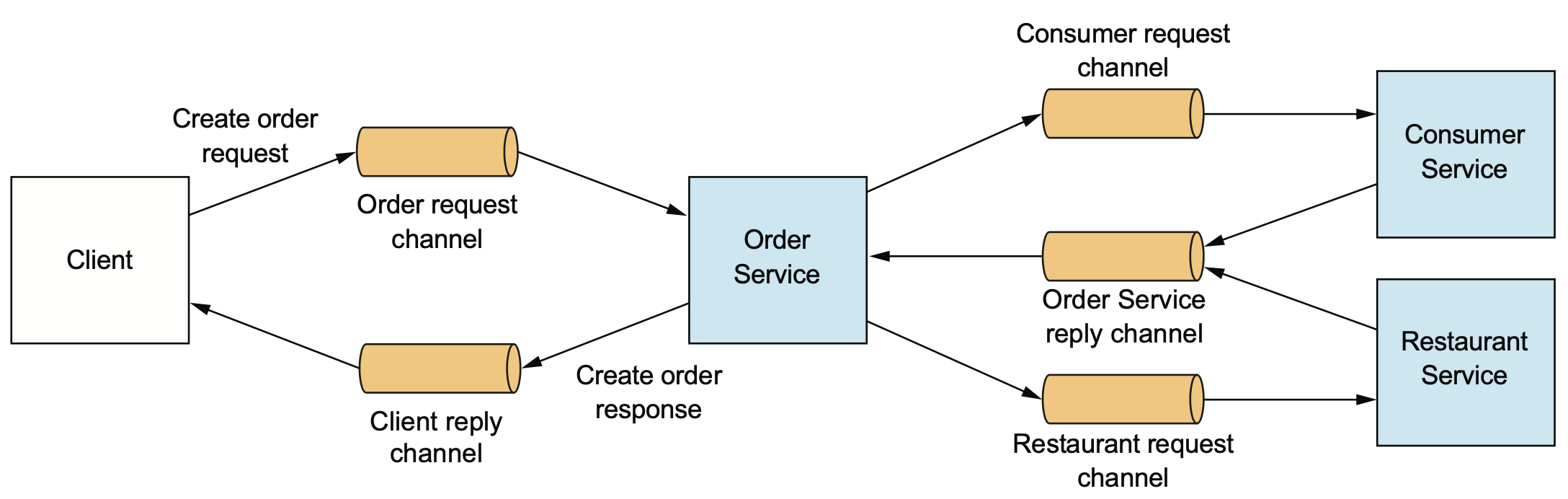
The FTGO application has higher availability if its services communicate using asynchronouse messaging instead of synchronous calls.
데이터 복제를 활용한 가용성 확보
추가로 고려해 볼 방안은 서비스 요청 처리시 필요한 데이터를 복제해서 관리하는 형태이다. 사전에 DB의 복제를 받아 외부 서비스에 의존하지 않고 local DB를 참조해서 응답을 하는 형태이다. 그러나 이 방법은 복제된 데이터가 오래되어 더이상 사용할 수 없게 되는 문제를 해결하기 위해 데이터의 변경이 발생될때 복제본을 업데이트 하는 메커니즘이 구현되어야 한다. 그러나 외부 DB/API 등에 의존하지 않으므로 API가 자체적으로 장애 복구 지원이 가능하게 된다.
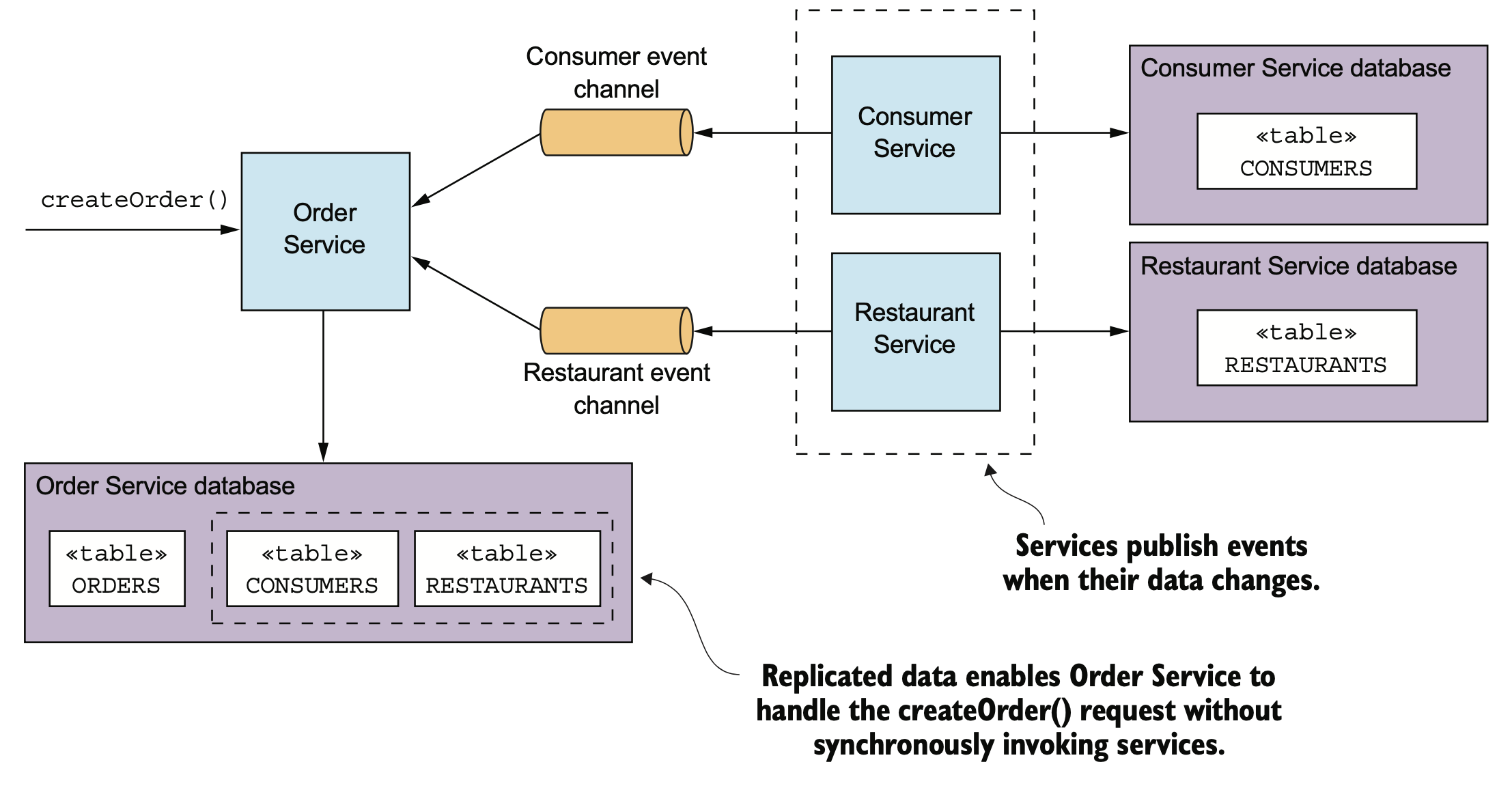
OrderService is self-contained because it has replicas of the consumer and restaurant data.
응답 반환 후 마무리
클라이언트의 요청이 완전히 처리되지 않았음에도 불구하고 우선 응답하고, 향후 validility 검사 및 오더 생성 등은 별도로 처리하는 형태를 의미한다. 이 경우 트랜잭션의 최종적 일관성 관리가 필요하며 해당 내용은 Chap4. 에서 더 확인해 봐야 한다.
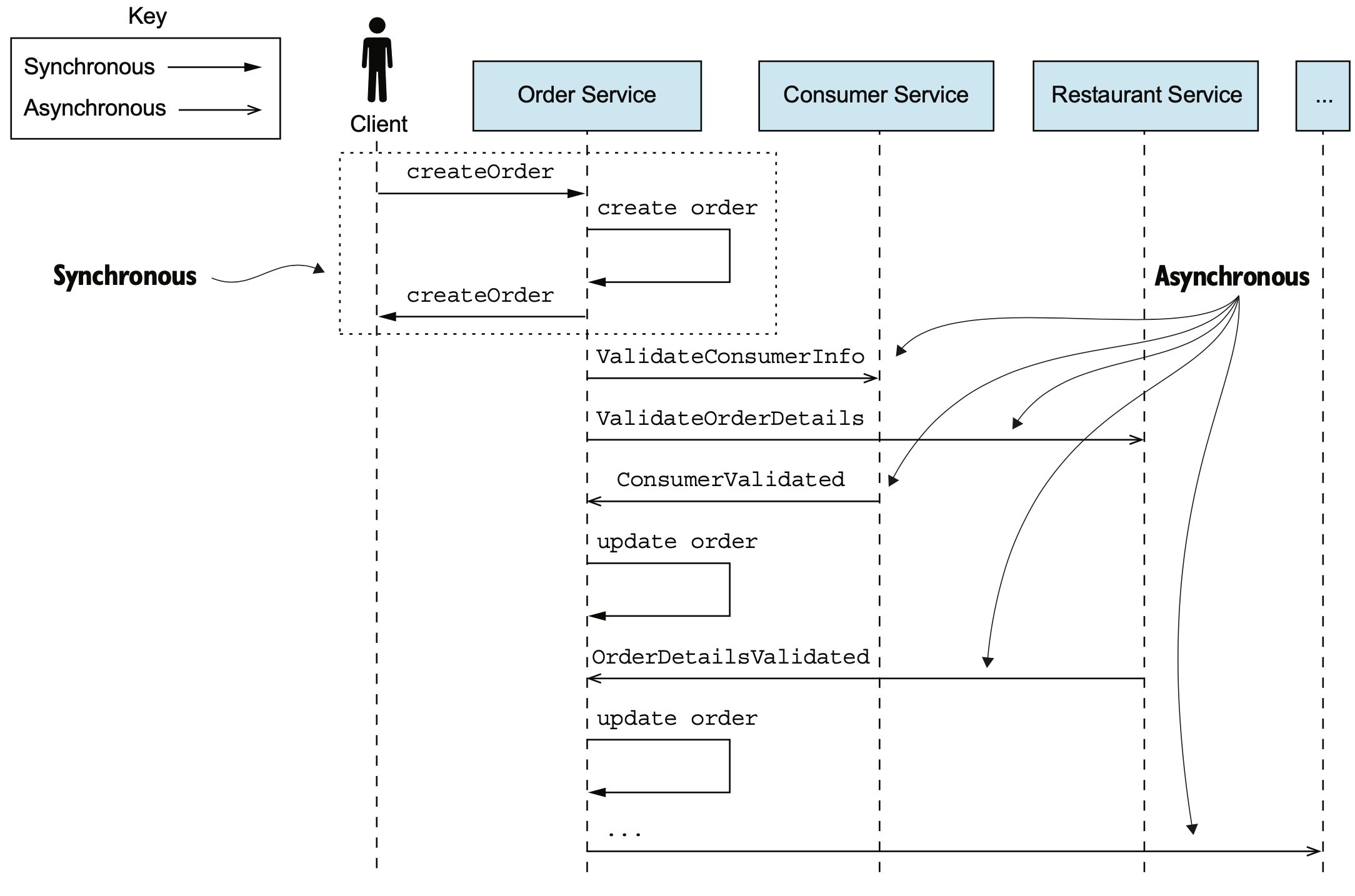
Order Service creates an order without invoking any other service. It then asynchronously validates the newly created Order by exchanging messages with other services, including Consumer Service and Restaurant Service.
