1) 개요
여러개의 문장 내에 중요(핵심) 키워드를 추출하기 위한 프로그램이다.
2) 환경
- tool: pycharm
- language: python
- library: pandas, openpyxl, keybert, konlpy
3) 프로그램 설정
- 라이브러리 설치 진행(bash)
pip install pandas # 데이터 분석, 처리, 통계
pip install openpyxl # 엑셀 파일(.xlsx) 직접 조작
pip install konlpy # 전처리 모델(형태소 분석)
pip install keybert # 임베딩 모델 사용
pip install sentence-transformers # keybert 버전에 따라 같이 설치될 수 있음 아니라면 명령어로 직접 설치※ 만약 konlpy가 설치되지 않는다면 jdk가 없는 것이므로 설치를 해야 한다.
4) 키워드 추출 방식 선택
- keybert방식은 문장을 임베딩 벡터로 변환하여 문장과 단어 벡터 간 코사인 유사도를 계산하여 중요한 단어를 선택하다.
- LLM(open ai)방식은 문장 의미와 문맥을 이해한 후 중요 키워드를 생성한다.
=> 이 프로그램에서는 1) 방식을 채택했다. 통계, 문맥 기반으로 단어 수준의 중요도(텍스트의 의미적 유사도)를 반영하며 추가 학습이 필요없기 때문이다.
5) 프로그램 설명
- 모든 정보가 들어있는 ‘data.xlsx’ 파일을 열어 ‘asset_desc’ 열(설명)만 추출하여 ‘desc.xlsx’ 파일로 생성한다.
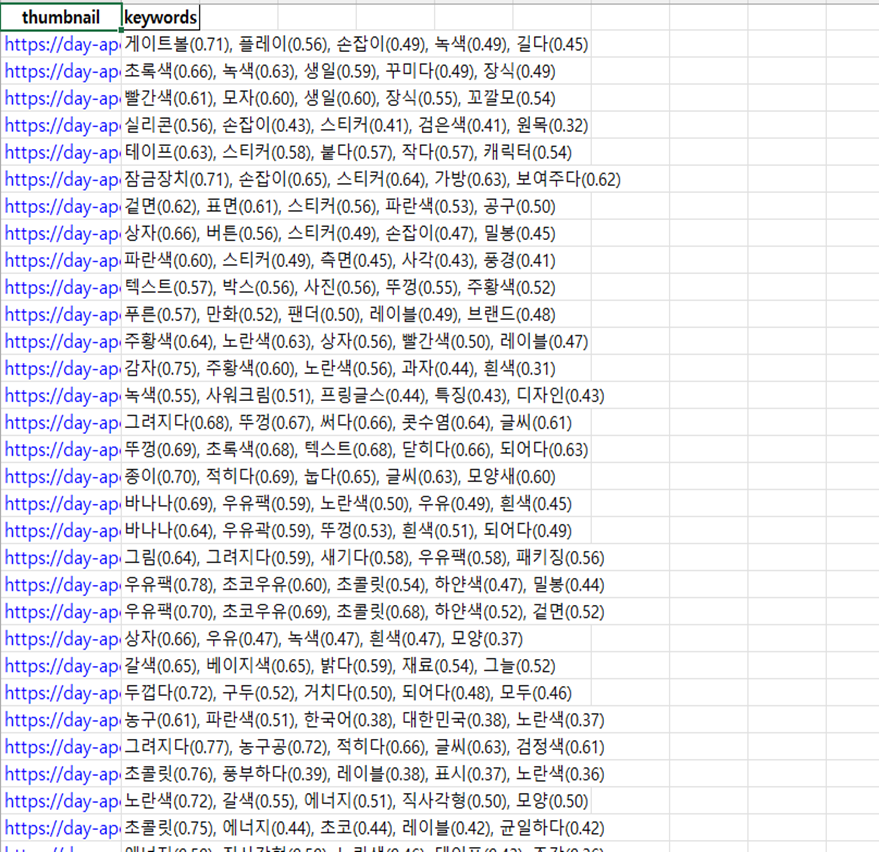
- ‘thumbnail’ 열만 추출하여 ‘thumbnail.xlsx’ 파일을 생성한다. 이후 추출된 키워드는 ‘thumbnail.xlsx’ 파일의 마지막 열에 들어간다.
2-1. ‘thumbnail’은 바로 확인할 수 있도록 baseurl을 붙여 하이퍼링크로 생성한다.(하이퍼링크 작업은 마지막에 해야 잘 작동한다. – 중간에 작동하면 추후 파일을 다시 열어 데이터 수정 시 하이퍼링크가 사라진다.)- keybert의 'paraphrase-multilingual-MiniLM-L12-v2' (한국어 지원 경량 모델)을 사용한다.
- 명사, 동사, 형용사만 추출하기 위해 한글 전처리를 한다.
4-1. 불용어 리스트에 있는 글자들을 제외하며 konlpy의 okt를 사용하여 명사, 동사(원형), 형용사만 고른다.- keybert에서 선택한 모델의 extract_keywords 함수를 통해 키워드 5개를 추출한다.
5-1. 키워드(유사성소수점 2자리까지)로 표시하여 ‘thumbnail.xlsx’ 파일의 마지막열에 삽입한다.- 4000건으로 데이터가 많아 500건씩 실행하도록 배치 처리한다.
6) 프로그램 코드(main.py)
import pandas as pd
from openpyxl import load_workbook
from keybert import KeyBERT
from konlpy.tag import Okt
input_file = "data.xlsx"
df = pd.read_excel(input_file)
desc_df = df[["asset_desc"]]
desc_df.to_excel("desc.xlsx", index=False)
print("문장파일(desc) 생성 완료")
baseurl = "https://day-apoc-kit.s3.ap-northeast-2.amazonaws.com/"
df["thumbnail"] = baseurl + df["thumbnail"].astype(str)
new_df = df[["thumbnail"]]
output_file = "thumbnail.xlsx"
new_df.to_excel(output_file, index=False)
print("썸네일파일(thumbnail) 생성 완료")
####문장 내 키워드 추출
desc_path = "desc.xlsx"
keyword_path = "thumbnail.xlsx"
df = pd.read_excel(desc_path) #asset_desc열에 문장
keyword_df = pd.read_excel(keyword_path) #썸네일 파일에 키워드 저장예정
model = KeyBERT('paraphrase-multilingual-MiniLM-L12-v2') # 한국어 지원 경량 모델
okt = Okt() #전처리하기 위해
korean_stopwords = ["있다","하다","되다","있습니다","그리고","또한","이","그","저","것","수","등","같은","더","를","은","는","이","가","에","으로","때"] #한국어 불용어 리스트
#전처리 함수(명사, 동사, 형용사만 선택)
def preprocess_text(text, include_pos=["Noun","Verb","Adjective"]):
tokens = okt.pos(str(text), stem=True) #stem=Ture 동사원형만 사용
words = [word for word, pos in tokens if pos in include_pos and word not in korean_stopwords and len(word)>1]
return " ".join(words)
#키워드 추출 함수
def extract_keywords_str(text, top_n=5):
clean_text = preprocess_text(text)
if not clean_text: #전처리 후 내용이 없다면 표시 X
return []
keywords = model.extract_keywords(clean_text, keyphrase_ngram_range=(1,1), #단어 단위
stop_words=None, top_n=top_n)
return ", ".join([f"{word}({score:.2f})" for word, score in keywords]) # 단어(유사도)로 출력
#배치 처리
batch_size = 500
all_keywords = []
for i in range(0, len(df), batch_size):
batch = df['asset_desc'].iloc[i:i+batch_size].tolist()
batch_keywords = [extract_keywords_str(text) for text in batch]
all_keywords.extend(batch_keywords)
keyword_df['keywords'] = all_keywords #thumbnail파일의 마지막 열에 키워드 추가
keyword_df.to_excel(keyword_path, index=False)
print("키워드 추출 완료")
#썸네일 하이퍼링크 처리(파일 재오픈)
wb = load_workbook(output_file)
ws = wb.active
thumbnail_col_idx = list(new_df.columns).index("thumbnail")+1 #열 번호
for row in range(2, ws.max_row+1): #썸네일 하이퍼링크
cell = ws.cell(row=row, column=thumbnail_col_idx)
url = cell.value
if url:
cell.value = url
cell.hyperlink = url
cell.style = "Hyperlink"
wb.save(output_file) #최종 저장
print("썸네일 하이퍼링크 완료")
7) 프로그램 결과
8) GitHub

이것저것 개발자