시작 전에
원글의 주소는 https://bespoyasov.me/blog/clean-architecture-on-frontend/ 입니다.
최근 프로젝트 아키텍처를 어떻게 구성할지에 대해 고민을 하다 이 글이 정말 잘 적혀 있는 것 같아 번역해보았습니다.
부족한 번역 실력이니까 지적 많이 해주세요.
메모
- adapter와 port의 경우 repositoryImpl와 repository로도 부른다
- port가 인터페이스, adapter가 그 인터페이스에 대한 구현으로 생각하면 될까? - driven adapter = primary adapter, driven adapter = secondary adapter
- driven adapter = inbound adapter, inner port = inbound port, outer port = outbound port
최근에도 프론트엔드에서의 클린 아키텍처에 대해 이야기한 적이 있습니다. 이번 글에서는 그 이야기들을 요약하고, 설명할 시간이 없었던 개념들과 자세한 내용들에 대해 더 설명하려고 합니다.
당신이 읽으면 도움이 될 모든 종류의 유용한 글들에 대한 링크를 아래에 첨부하겠습니다.
- The Public Talk
- Slides for the Talk
- The source code for the application we're going to design
- Sample of a working application
What's the Plan
우선, 클린 아키텍처가 일반적으로 무엇인지에 대해 이야기하기 위해 도메인(domain), 유스 케이스(use case) 그리고 어플리케이션(application) 레이어와 같은 개념에 대해 소개하려 합니다.
다음으로, 클린 아키텍처의 규칙을 지키며 쿠키 가게(진짜로 먹는 쿠기 가게)를 위한 프론트엔드를 설계할 것입니다. 마지막으로, 유스 케이스들 중 하나를 실제로 사용 가능하게끔 기초부터 구현할 것입니다.
이 접근 방식이 UI 프레임워크와 함께 사용될 수 있음을 보여주기 위해 React를 사용할 것입니다(그리고 이 게시물의 주제는 이미 React를 사용하고 있는 개발자를 대상으로 했기 때문입니다.). React가 필수적이진 않습니다, 당신은 다른 UI 라이브러리나 프레임워크를 사용해서도 이 글의 내용을 충분히 구현 가능합니다.
엔티티들을 구현하기 위해 interfaces와 types을 어떻게 사용할지 보여주기 위해 조금의 Typescript 코드가 들어갑니다. 이 글의 모든 코드는 명확하게 표현되진 않지만 Javascript로도 작성 가능합니다.
비교적 어려운 개념인 OOP에 대해 거의 이야기하지 않을 것입니다. 글의 후반부에 OOP에 대해서 한 번 언급하지만, 모른다고해서 애플리케이션 설계에 지장이 있지는 않을 것입니다.
또한 테스트에 대해서는 글의 메인 주제가 아니기에 넘어갈 것입니다. 하지만 테스트를 작성할 가능성을 염두에 두고 테스트를 개선할 방법에 대해서는 언급할 것입니다.
그리고 마지막으로, 이 글은 대부분 클린 아키텍처의 개념을 이해하는 것에 관한 것입니다. 게시물의 예제는 단순화되어 있으므로 코드를 작성하는 방법에 대한 설명서가 아닙니다. 원리를 이해하고 이러한 원칙을 프로젝트에 적용할 수 있는 방법에 대해 고려해보세요.
이 글의 마지막에서는 클린 아키텍처와 프론트엔드에서 광범위하게 사용되는 방법론들의 목록을 첨부했습니다. 당신의 프로젝트의 규모에 따라 가장 잘맞는 방법을 찾을 수 있을 것입니다.
이제부터 시작합니다.
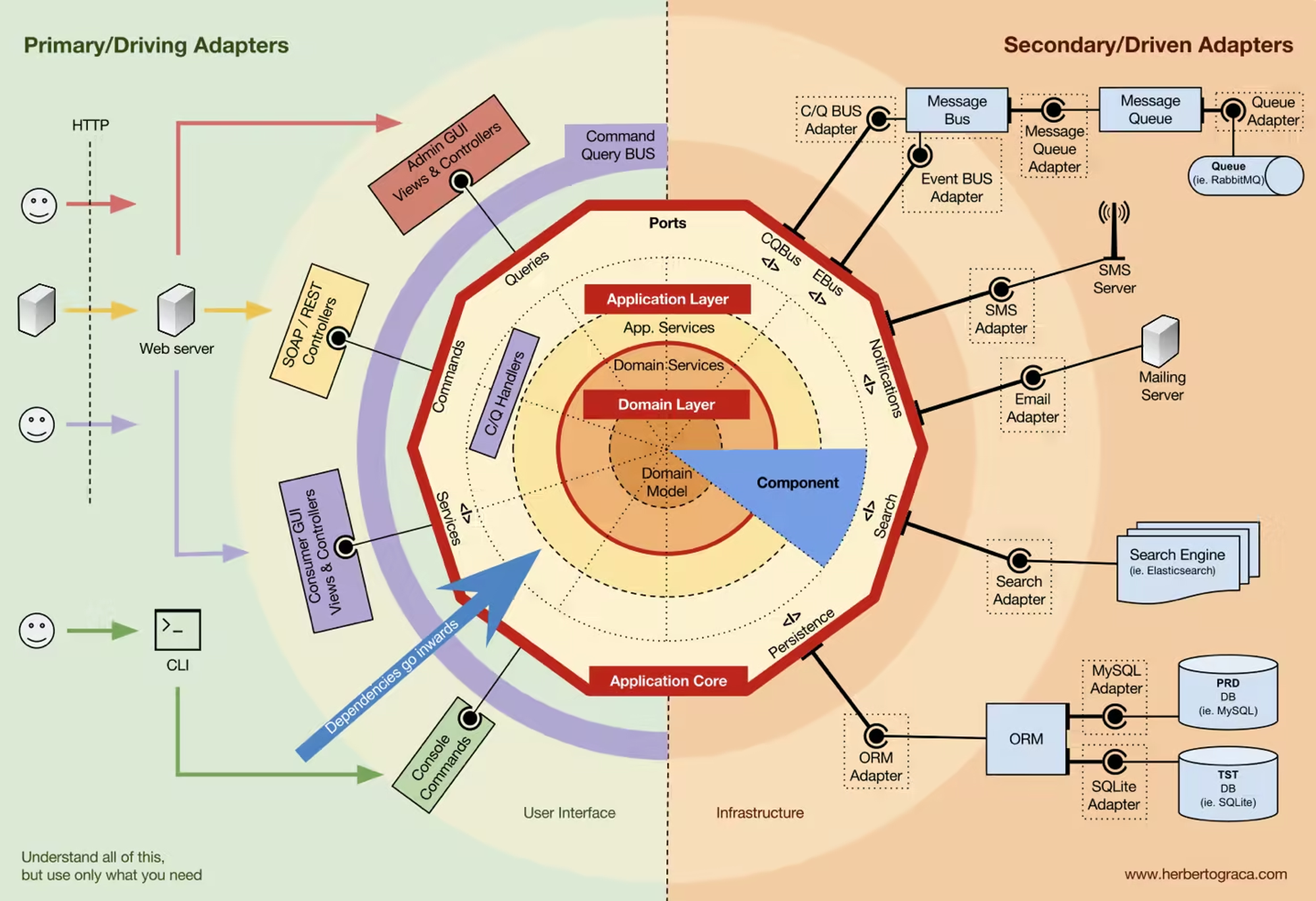
Architecture and Design
Designing is fundamentally about taking things apart... in such a way that they can be put back together. ...Separating things into things that can be composed that's what design is.
— Rich Hickey. Design Composition and Performance
인용에 따르면 시스템 설계(System design)는 나중에 재조립할 수 있도록 시스템을 분리하는 것입니다. 가장 중요한 것은, 추가적인 노력이 적게 들며 조립되어야 한다는 점입니다.
저도 동의합니다. 하지만 저는 시스템의 확장성이 아키텍처의 또 다른 목표라고 생각합니다. 프로그램의 요구사항은 지속적으로 변합니다. 우리는 프로그램이 새로운 요구사항들을 쉽게 업데이트하고 수정하기를 원합니다. 클린 아키텍처가 바로 이러한 목표를 이루도록 도와줍니다.
The Clean Architecture
클린 아키텍처는 애플리케이션 도메인과의 근접성(proximity)에 따라 책임과 기능의 일부를 분리하는 방법입니다.
도메인이란 우리가 프로그램으로 모델링하는 현실 세계의 일부를 의미합니다. 이것은 실제 세계의 변화를 반영하는 데이터 변환입니다. 예를 들어, 우리가 물품의 이름을 업데이트했다면, 이전의 이름을 새로운 이름으로 대체하는 것이 도메인 변환(domain transformation)입니다.
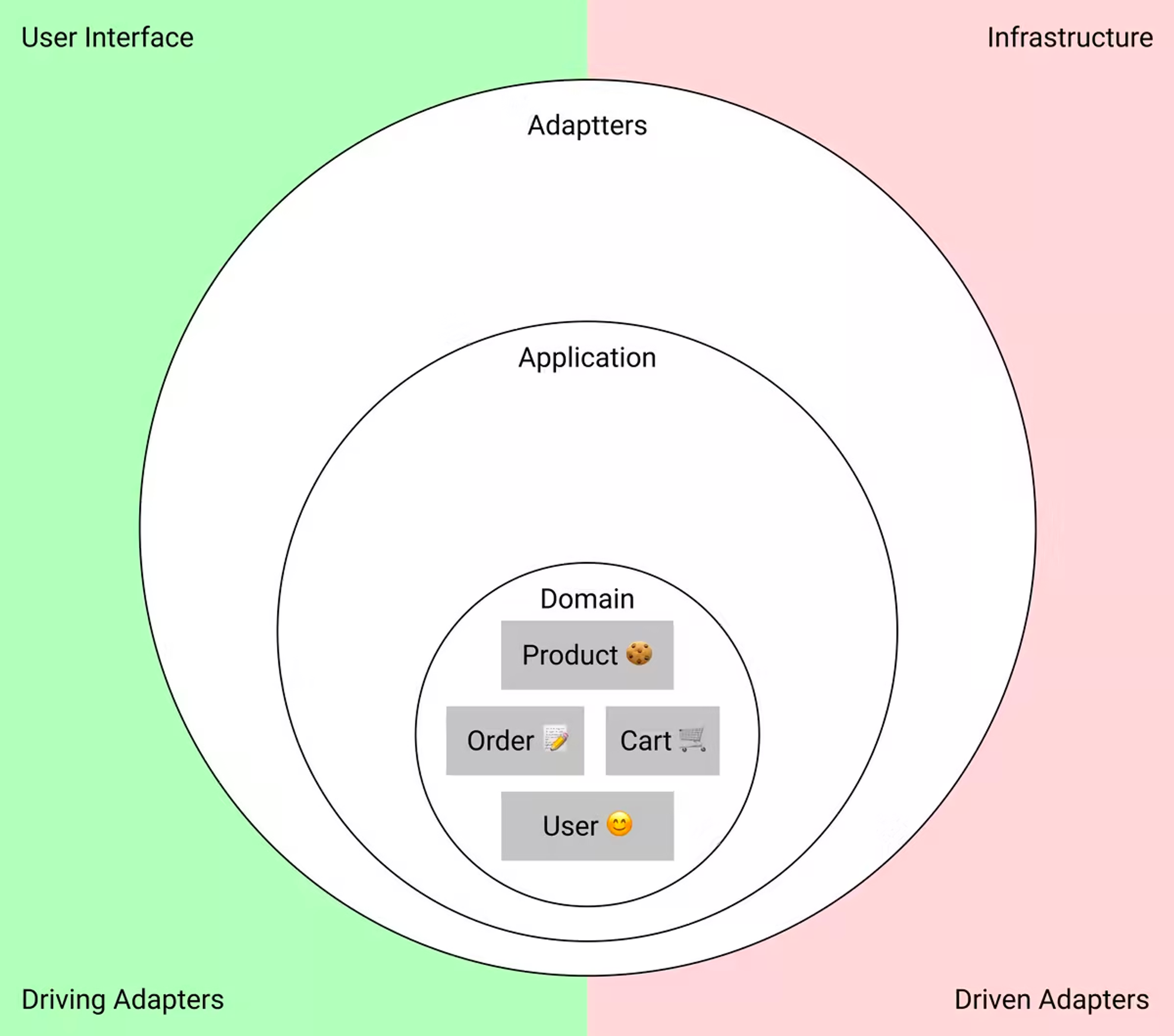
클린 아키텍처는 레이어로 나뉜 기능들로 인해 종종 3-레이어 아키텍처로 참조됩니다. 클린 아키텍처에 대한 최초의 글은 레이어가 강조 표시된 다이어그램을 제시했습니다.
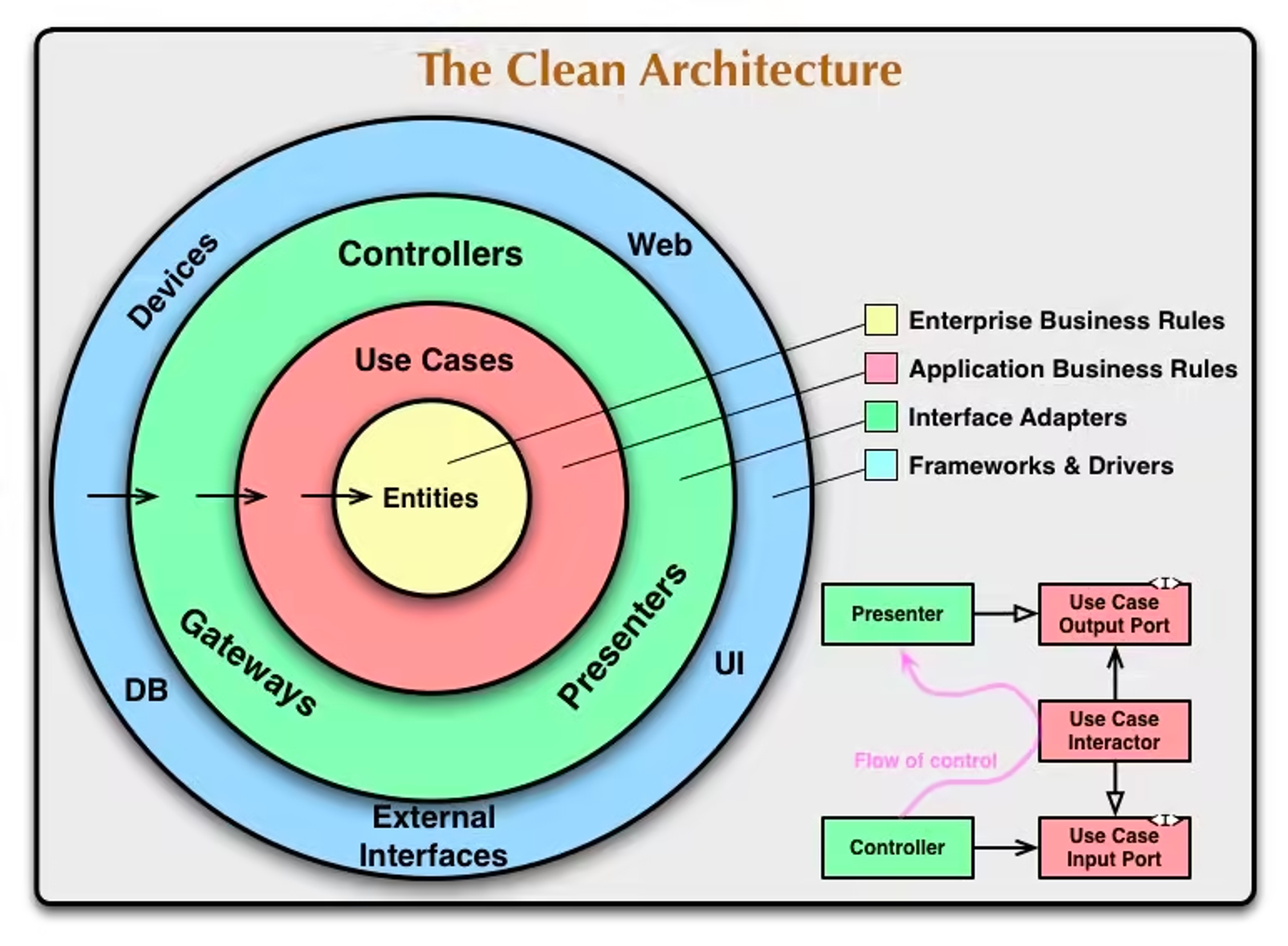
레이어 다이어그램: 도메인이 중심에 있으며, 어플리케이션 레이어가 그 주위를 감싸고 어댑터 레이어(adapters layer)가 바깥쪽에 있다.
Domain Layer
중심에 위치한 부분이 도메인 레이어 입니다. 도메인 레이어는 어플리케이션의 주제 영역(subject area)를 표현하는 엔티티와 데이터 그리고 그것들을 조작하는 코드가 포함됩니다. 도메인은 한 어플리케이션을 다른 어플리케이션과 구분 가능하게 하는 핵심입니다.
도메인을 React에서 Angular로 UI 프레임워크를 바꾸거나, 유스 케이스 일부를 변경해도 바뀌지 않는 것이라고 생각해도 좋습니다.
도메인 엔티티들의 데이터 구조와 변환의 핵심은 외부로부터 독립적입니다. 외부의 이벤트들은 도메인 변환(domain transformation)을 일으키지만, 어떤 식으로 발생할지에 대한 상세 사항은 결정하지 않습니다.
예를 들어, “장바구니에 아이템을 추가한다”라는 기능은 아이템이 유저 스스로 구매 버튼을 눌렀는지 혹은 프로모션 코드를 통해 자동으로 추가되었는지 등에 대해 전혀 신경쓰지 않습니다. 해당 기능은 두가지 경우에 모두 작동하며, 아이템을 받아 카트에 추가할 아이템을 업데이트하기만 할 뿐입니다.
Application Layer
도메인을 둘러싸는 것은 어플리케이션 레이어입니다. 이 레이어는 유저의 시나리오와 같이 유스 케이스를 묘사합니다. 즉 어떤 이벤트가 발생했을 때 무엇이 일어날지에 대해 담당합니다.
예를 들어, “카트에 추가하기” 시나리오는 유스 케이스입니다. 이것은 버튼이 클릭되었을 때 일어나야하는 액션에 대해 묘사합니다. 마치 오케스트라 연주자와 같이:
- 서버에 요청을 보내고
- 도메인 변환을 수행하고
- 응답 데이터를 가지고 UI를 다시 그립니다.
또한 어플리케이션 레이어에는 포트들(ports)이 존재합니다. 포트들은 우리의 어플리케이션이 외부와 어떻게 소통하기를 원하는지에 대한 명세들(specifications)입니다. 포트는 어떻게 동작할지 규정하는 인터페이스와 비슷합니다.
포트는 어플리케이션의 필요 실제 사이의 "임시 공간(buffer zone)" 역할을 합니다. 입력(인바운드) 포트는 응용 프로그램이 외부와 어떻게 연결되기를 원하는지 알려줍니다. 출력(아웃바운드) 포트는 어플리케이션이 어떻게 외부와 통신하여 준비할 것인지를 나타냅니다.
포트들에 대해서는 추후 더 자세히 보겠습니다.
Adapters Layer
가장 바깥의 레이어는 외부 서비스로의 어댑터들(adapters)을 포함합니다. 어댑터들은 호환되지 않는 외부 서비스의 API들을 우리의 필요에 맞게 변환하기 위해 필요합니다.
어댑터들은 우리의 코드와 서드파티 서비스들을 결합도(coupling)를 낮추는데 있어 훌륭한 방법입니다.
어댑터들은 보통 2가지로 나뉘는데:
- driving(인바운드) - 우리 어플리케이션으로 신호를 보내는 종류
- driven(아웃바운드) - 우리 어플리케이션으로부터 신호를 받는 종류
유저의 상호작용은 대부분 driving 어댑터들과 일어납니다. 예를 들어, UI 프레임워크의 버튼 클릭 핸들링은 driving 어댑터의 일입니다. 그것은 브라우저 API (서드파티 서비스)와 작동하며 이벤트를 우리의 어플리케이션이 이해할 수 있는 신호로 변환해 줍니다.
Driven 어댑터들은 인프라(infrastructure)와 상호작용 합니다. 프론트엔드에서 대부분의 인프라는 백엔드 서버입니다. 그러나 가끔은 다른 서비스(검색 엔진과 같은)들과 직접적으로 상호작용하기도 합니다.
중앙에서 멀어질수록 코드 기능은 더 "서비스 지향적(service-oriented)"이며 응용 프로그램의 도메인 지식(domain knowledge)과는 거리가 멀다는 점에 유의하십시오. 이것은 나중에 우리가 어떤 모듈이 어느 계층에 속해야 하는지 결정할 때 중요할 것이다.
Dependency Rule
3-레이어 아키텍처는 의존성 규칙이 존재합니다 : 바깥쪽에서 안쪽으로만 의존성을 가질 수 있습니다:
- 도메인은 반드시 독립적이여야 한다.
- 어플리케이션 레이어는 도메인에 의존성을 가질 수 있다.
- 바깥의 레이어는 어디에나 의존성을 가질 수 있다.
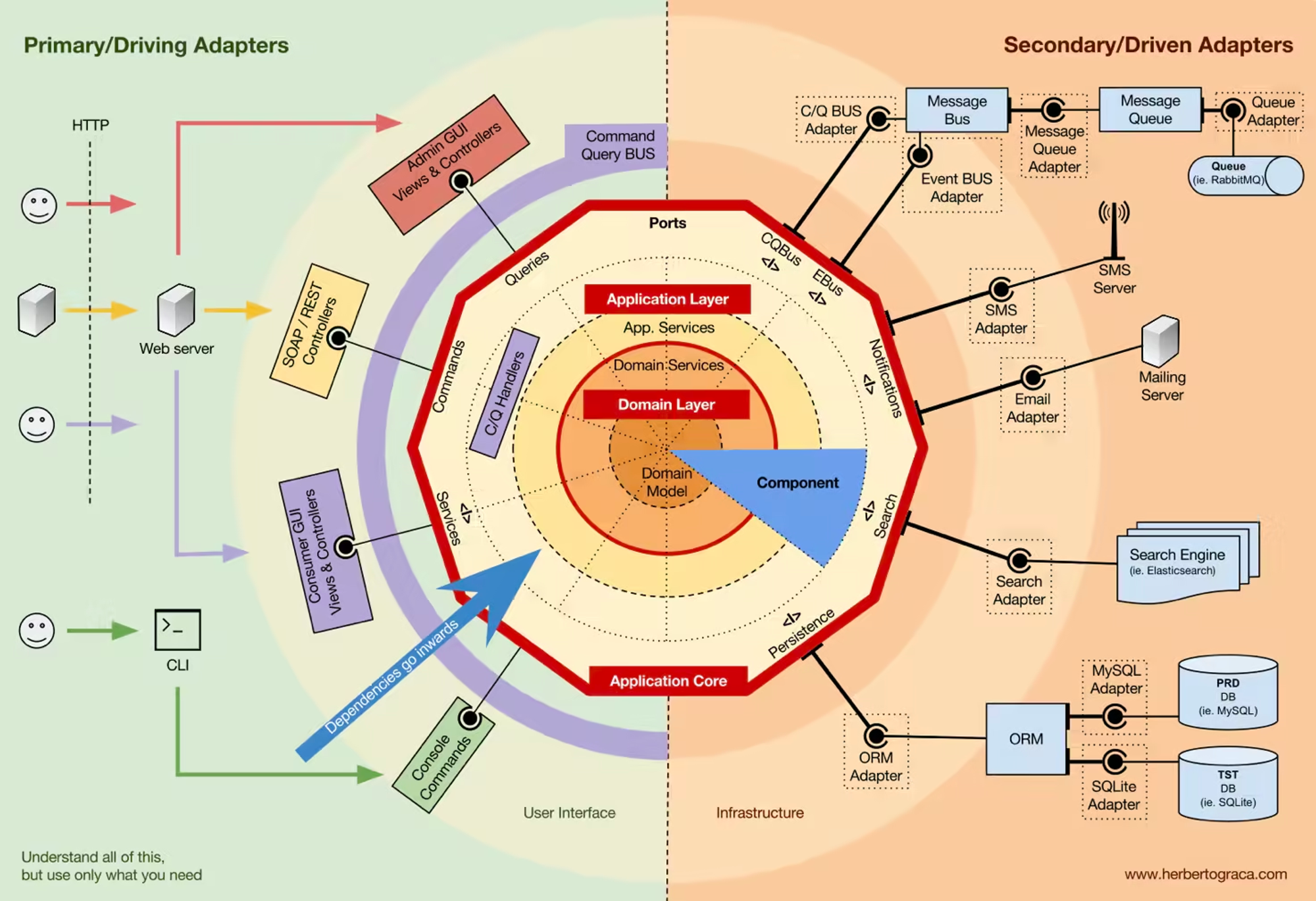
바깥쪽의 레이어만이 안쪽의 레이어에 의존성을 지닌다.
그러지 않는게 좋겠지만, 이 규칙을 꼭 지킬 필요는 없습니다. 예를 들어, “라이브러리 같은(library-like)” 코드를 의존성이 존재하면 안되는 도메인에 두는 것이 종종 편리할 수 있습니다. 추후 소스 코드를 살펴보며 이러한 예제를 볼 것입니다.
의존성의 방향을 제대로 통제하지 않는다면 복잡하고 어려운 코드가 될 수 있습니다. 예를 들어, 종속성 규칙을 망가뜨리는 것은 이러한 결과를 낳을 수 있습니다:
- 순환 종속성(Cyclic dependencies): 모듈 A가 B에 의존하고, B가 C에 의존하며, C가 A에 의존함.
- 테스트의 어려움(Poor testability): 작은 부분을 테스트하기 위해 시스템의 전체를 시뮬레이션해야함.
- 너무 높은 결합도(Too high coupling): 모듈간의 불안정한 상호작용이 일어남.
Advantages of Clean Architecture
이제 이렇게 코드를 분리 했을 때의 장점에 대해 이야기 해보겠습니다. 몇가지 장점이 있습니다.
Separate domain
어플리케이션의 모든 주요 기능이 도메인 한 곳에서 격리되고 모아집니다.
도메인 내부의 기능은 독립적이므로 테스트하기가 더 쉽습니다. 모듈의 의존성이 줄어들수록, 테스트를 위한 인프라가 적게 필요하며, mocks와 stubs가 적게 필요합니다.
독립 실행형(stand-alone) 도메인은 비즈니스 기대치와 비교하여 테스트하기도 더 쉽습니다. 이것은 신규 개발자들이 애플리케이션이 무엇을 해야 하는지 파악하는 데 도움이 됩니다. 또한 독립 실행형 도메인은 비즈니스 언어에서 프로그래밍 언어로의 "번역(translation)"에서 오류와 부정확성을 더 빨리 찾을 수 있도록 도와줍니다.
Independent Use Case
애플리케이션 시나리오, 사용 사례에 대해서는 별도로 설명합니다. 그들은 우리가 필요로 하는 제3자 서비스를 지시한다. 우리는 외부 세계를 우리의 필요에 맞게 조정하는 것이지, 그 반대가 아닙니다. 이를 통해 서드파티 서비스를 더 자유롭게 선택할 수 있게 해줍니다. 예를 들어, 현재 사용 중인 결제 시스템이 요금을 너무 많이 받는다면 빠르게 다른 결제 시스템으로 변경할 수 있습니다.
유스 케이스 코드 또한 수평적으로(flat), 테스트하기 쉬위지며, 확장성이 높아집니다. 나중에 이에 대한 예제도 보여드리겠습니다.
Replaceable Third-Party Services
어댑터들 덕분에 외부 서비스들이 교체 가능해집니다. 인터페이스가 바뀌지 않는한 어떤 외부 서비스가 인터페이스를 구현하는지는 상관이 없어집니다.
이러한 방법으로, 우리는 전파(propagation)에 대한 방어막을 생성할 수 있습니다. 타인의 코드가 바뀌더라도 우리 코드에는 직접적으로 영향이 오지 않는 것입니다. 어댑터들은 또한 어플리케이션 런타임 중 버그의 전파도 제한합니다.
Costs of Clean Architecture
명심해야 되는 것이 아키텍처는 도구입니다. 모든 도구와 같이 클린 아키텍처 또한 장점만이 아닌 비용(cost)도 존재합니다.
Takes Time
가장 큰 비용은 시간입니다. 서드파티 서비스를 직접 사용하는 것이 어댑터를 작성하는 것보다 항상 쉽기에 설계와 구현 모두 시간이 들어갑니다.
또한 사전에 시스템의 요구사항과 제약을 모두 알지 못할 가능성이 높기에, 시스템의 모듈들의 상호작용을 모두 생각하기도 어렵습니다. 설계 시에는 시스템이 어떻게 바뀔 수 있는지를 염두에 두고 확장의 여지를 남겨둘 필요가 있습니다.
Sometimes Overly Verbose
일반적으로, 클린 아키텍처의 표준(canonical) 구현은 편리한 것은 아니며, 가끔은 고통스럽습니다. 프로젝트가 작다면, 클린 아키텍처의 완전한 구현에 실제 구현보다 오히려 더 많은 노력이 들어갈 수 있습니다.
예산과 마감일을 고려한다면 설계적인 타협이 필요할 수 있습니다. 타협안이 정확히 무엇을 의미하는지 예제를 보여드리겠습니다.
Can Make Onboarding More Difficult
클린 아키텍처의 완전한 구현은 필요로 하는 지식이 많기에, 초기에는 무척 어려울 수 있습니다.
만약 프로젝트의 시작부터 over-engineer한다면 신규 개발자들이 진입하기가 어려울 것입니다. 이를 명심하고 코드를 간소화해야합니다.
Can Increase the Amount of Code
프론트엔드에서 클린 아키텍처를 채택했을 때 한정적으로 생기는 문제로는 최종 번들(final bundle)에 포함된 코드의 양이 증가할 수 있다는 점입니다. 코드의 양이 증가할 수록, 브라우저는 많은 코드를 다운로드하고, 분석(parse)하고, 해석(interpret)해야합니다.
코드의 양에 유의하며 어떻게 절충할 것인지를 결정해야합니다:
- 유스 케이스를 조금 단순화 시키기
- 유스 케이스 없이 어댑터에서 도메인 기능에 바로 접근하기
- 코드 분할(code splitting)을 수정하기(tweak) 등
How to Reduce Costs
절충하거나, 아키텍처의 "청결성(cleanliness)"을 희생시킴으로써 시간과 코드의 양을 줄일 수 있습니다. 저는 일반적으로 급진적인 접근법을 좋아하지 않지만, 규칙을 어기는 것이 더 실용적이라면(예: 잠재적인 비용보다 이점이 크다면) 규칙을 어길 것입니다.
문제가 없는한 클린 아키텍처의 일부를 수정할 수 있습니다. 그러나 최소한 지켜줘야하는 규칙이 2가지가 있습니다.
Extract Domain
추출된(extrated) 도메인은 우리가 무엇을 설계하고, 어떻게 동작하는지 이해를 높여줍니다. 뿐만 아니라, 어플리케이션과 그것에 속한 엔티티들 그리고 엔티티들의 관계를 신규 개발자들이 이해하기 쉽게 만들어 줍니다.
만약 다른 레이어들을 구현하지 않았더라도, 코드 전체에 도메인을 흩뿌리는 것보다는 도메인을 추출하는 것이 작업하거나 리팩터링하기 쉬울 것입니다.
Obey Dependency Rule
지켜줘야하는 두번째 규칙은 의존성 규칙입니다. 정확히는 의존성의 방향이죠. 외부 서비스들이 우리의 필요에 맞춰야하며, 반대는 안됩니다.
만약 검색 API를 사용하기 위해 당신의 코드를 “파인 튜닝(fine-tuning)”하고 있다면, 무언가 잘못된겁니다. 문제가 커지기 전에 어댑터를 작성하세요.
Designing the Application
이제 이론 이야기는 그만하고 실전으로 넘어가겠습니다. 쿠기 가게의 아키텍처를 설계해 보겠습니다.
쿠기 가게는 다양한 성분을 가지는 여러 종류의 쿠기들을 판매합니다. 유저들은 쿠키들을 고르고, 주문하며, 서드 파티 결제 서비스를 통해 결제할 것 입니다.
홈페이지에서는 구매 가능한 쿠키들을 전시합니다. 로그인했다면, 쿠키를 구매할 수 있습니다. 로그인 버튼은 로그인 페이지로 이동시킵니다.
가게의 메인 페이지
(디자인은 신경쓰지마세요. 우린 웹 디자이너가 아니니까요😅)
로그인을 성공했다면, 장바구니에 쿠키들을 넣을 수 있습니다.
쿠기들이 담긴 장바구니
장바구니에 쿠키들을 담았다면, 주문이 가능합니다. 결제 후에는 장바구니를 비우고, 목록에 새로운 주문을 추가합니다.
우리는 계산(checkout) 유스 케이스들을 구현할 것입니다. 나머지 유스 케이스들은 이 소스 코드에서 찾아보세요.
먼저 광범위하게 어떤 종류의 엔티티들, 유스 케이스들 및 기능이 있는지 정의할 것입니다. 그러고 나서는 각각이 어디 레이어에 속할지를 결정할 것입니다.
Designing Domain
어플리케이션에게 가장 중요한 것은 도메인입니다. 도메인에는 어플리케이션의 메인 엔티티들과 그들의 데이터 변환이 존재합니다. 저는 당신의 코드에서 어플리케이션의 도메인 지식을 정확하게 표현할 수 있도록 도메인부터 작성하는 것을 권장합니다.
가게의 도메인은 이런 내용을 포함할 수 있습니다:
- 각 엔티티의 데이터 타입들: user, cookie, cart, order
- 각 엔티티들 생성하는 팩토리들, 혹은 OOP로 적는다면 클래스들
- 각 데이터를 변환하는 함수
변환 함수들(transformation functions)은 도메인에서의 규칙들에만 의존해야 한다. 예를 들어, 이런 함수들이 있을 수 있습니다:
- 총 금액을 계산하는 함수
- 유저의 맛 선호 탐지
- 장바구니에 아이템이 존재하는지 확인 등
도메인 엔티티들의 다이어그램
Designing Application Layer
어플리케이션 레이어는 유스 케이스들을 포함합니다. 유스 케이스는 반드시 행위자(actor), 행동(action) 그리고 결과(result)를 가져야 합니다.
가게라면 이런 유스 케이스들을 찾을 수 있습니다:
- 물건 구매 시나리오
- 서드파티 결제 시스템을 이용한 결제
- 주문과 물건의 상호작용: 갱신, 탐색
- 역활에 따른 페이지 접근
유스 케이스들은 일반적으로 주제 영역(subject area)의 관점에서 설명됩니다. 예를 들어, "계산(checkout)" 시나리오는 실제로 다음과 같은 몇 가지 단계로 구성됩니다:
- 장바구니로 부터 아이템을 가져와 새로운 주문을 만듭니다.
- 주문에 대해 결제합니다.
- 만약 결제가 실패한다면, 유저에게 알립니다.
- 장바구니를 비우고 주문 내역을 보여줍니다.
유스 케이스 함수들은 이 시나리오를 묘사하는 코드가 될 것입니다.
또한 어플리케이션 레이어에는 외부와 소통하는 인터페이스인 포트들이 존재합니다.
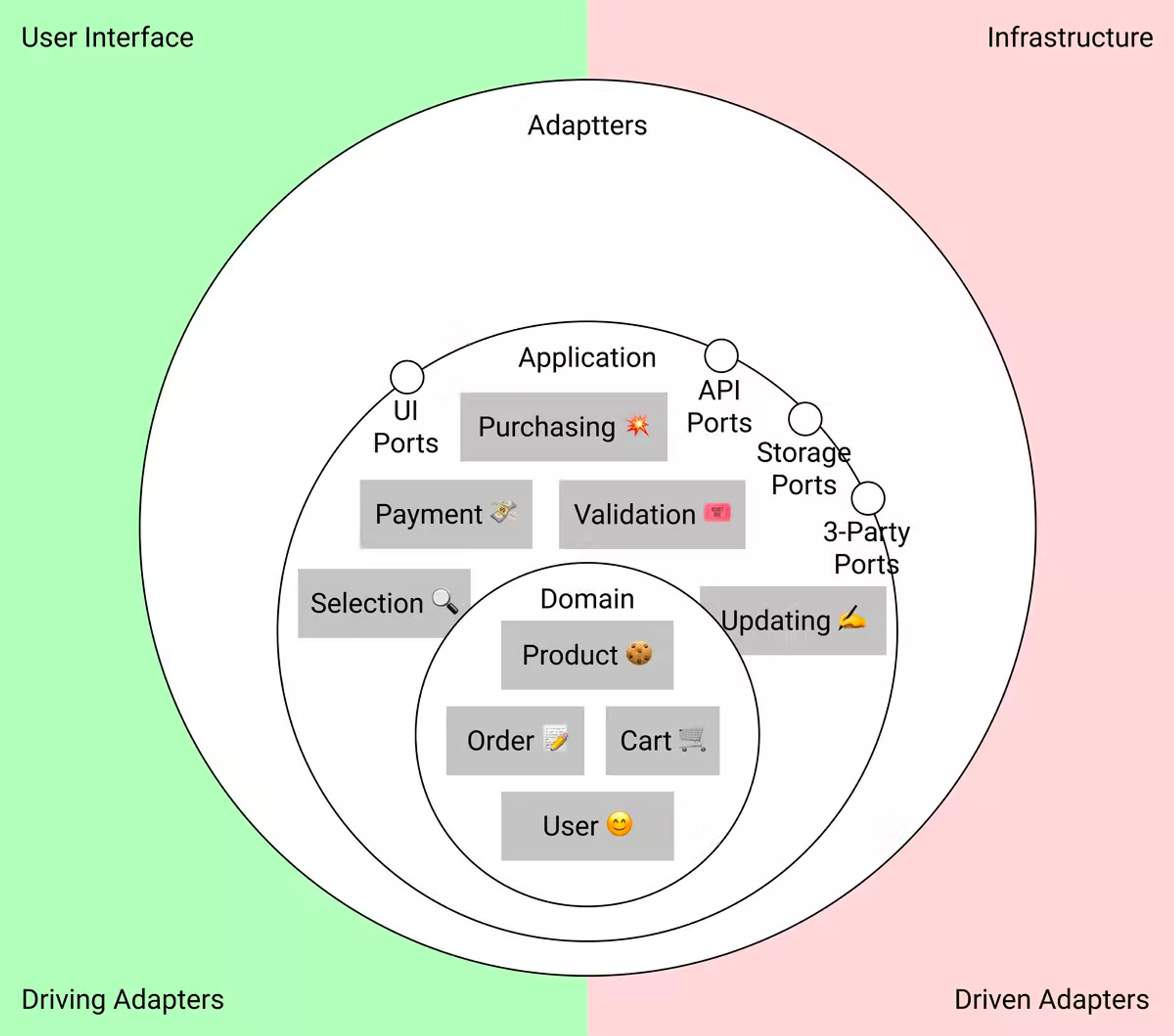
유스 케이스들과 포트들이 추가된 다이어그램
Designing Adapters Layer
어댑터 레이어에서는, 외부 서비스로의 어댑터들을 정의합니다. 어댑터들은 서드파티 서비스의 호환되지 않는 API들을 우리 시스템에 호환되도록 합니다.
프론트엔드에서는, 어댑터들은 보통 UI 프레임워크와 API 서버 요청 모듈에 사용됩니다. 우리의 경우에는 이런 곳에 사용합니다:
- UI 프레임워크
- API 요청 모듈
- local storage를 위한 어댑터
- API 응답에서 어플리케이션 레이어로의 어댑터 및 컨버터
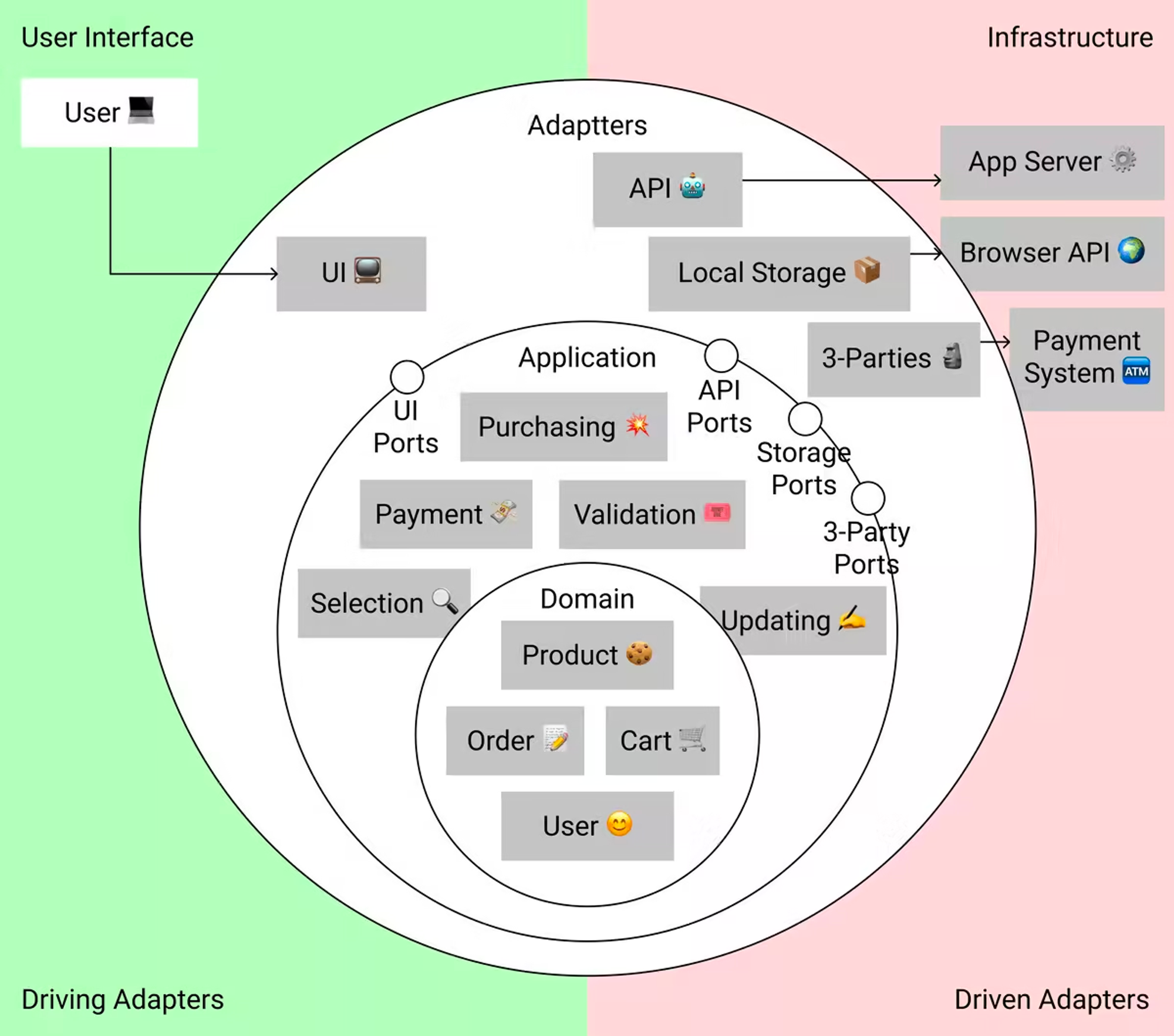
driving과 driven 어댑터들로 나눠 추가한 다이어그램
명심하세요. 기능이 더 “service-like”라면 다이어그램의 중앙으로부터 멀어집니다.
Using MVC Analogy
가끔은 몇몇 데이터들이 어디 레이어에 속하는지 파악하기가 어려울 수 있습니다. 별건 아니지만(그리고 불완전하지만!) MVC로의 비유가 도움이 될 수 있습니다:
- 모델(model)들은 보통 도메인 엔티티들입니다.
- 컨트롤러(controller)들은 도메인 변환 그리고 어플리케이션 레이어입니다.
- 뷰(view)는 driving 어댑터들입니다.
이 개념들은 정확하지는 않지만 꽤나 비슷합니다, 그리고 이 비유는 도메인과 어플리케이션 코드를 정의하는 데에 있어 사용될 수 있습니다.
Into Details: Domain
어떤 엔티티들이 필요한지 결정했다면, 우리는 엔티티들이 어떻게 동작하는지 정의함으로써 시작할 수 있습니다.
프로젝트의 코드 구조를 바로 보여드리겠습니다. 명확성을 위해, 코드를 folders-layers로 나눴습니다.
src/
|_domain/
|_user.ts
|_product.ts
|_order.ts
|_cart.ts
|_application/
|_addToCart.ts
|_authenticate.ts
|_orderProducts.ts
|_ports.ts
|_services/
|_authAdapter.ts
|_notificationAdapter.ts
|_paymentAdapter.ts
|_storageAdapter.ts
|_api.ts
|_store.tsx
|_lib/
|_ui/도메인은 domain/ 폴더에, 어플리케이션 레이어는 application/ 에 어댑터들은 services/ 에 존재합니다. 이 코드 구조의 대안들에 대해서는 끝에서 다시 이야기 하겠습니다.
Creating Domain Entities
우리는 도메인에 4개의 모듈을 둘 것입니다:
- product
- user
- order
- shopping cart
main actor는 유저입니다. 우리는 세션동안 유저에 대한 데이터를 저장할 것입니다. 이 데이터를 입력해야므로, 도메인 유저 타입을 생성할 것입니다.
유저 타입은 ID, 이름, 메일, 선호와 알러지에 대한 리스트를 포함될 것입니다.
// domain/user.ts
export type UserName = string;
export type User = {
id: UniqueId;
name: UserName;
email: Email;
preferences: Ingredient[];
allergies: Ingredient[];
};유저들은 쿠키를 장바구니(cart)에 담습니다. 장바구니와 물건을 위한 타입도 추가해보죠. 물건은 ID와 이름, 가격(센트 ¢로) 그리고 성분의 목록이 포함될 것입니다.
// domain/product.ts
export type ProductTitle = string;
export type Product = {
id: UniqueId;
title: ProductTitle;
price: PriceCents;
toppings: Ingredient[];
};장바구니에는, 유저가 집어 넣은 물건들의 목록만 가지고 있을 것입니다.
// domain/cart.ts
import { Product } from "./product";
export type Cart = {
products: Product[];
};성공적으로 결제가 끝났다면, 새로운 주문이 생성됩니다. 주문에 대한 엔티티 타입도 추가해보죠.
주문 타입은 유저의 ID, 주문한 물건의 리스트, 생성된 시간과 날짜, 주문 상태, 그리고 전체 금액을 포함할 것입니다.
// domain/order.ts
export type OrderStatus = "new" | "delivery" | "completed";
export type Order = {
user: UniqueId;
cart: Cart;
created: DateTimeString;
status: OrderStatus;
total: PriceCents;
};Checking Relationship Between Entities
이러한 방식으로 엔티티 타입을 설계했을 때의 장점은 그들의 관계 다이어그램이 현실과 일치하는지 확인할 수 있다는 것입니다:
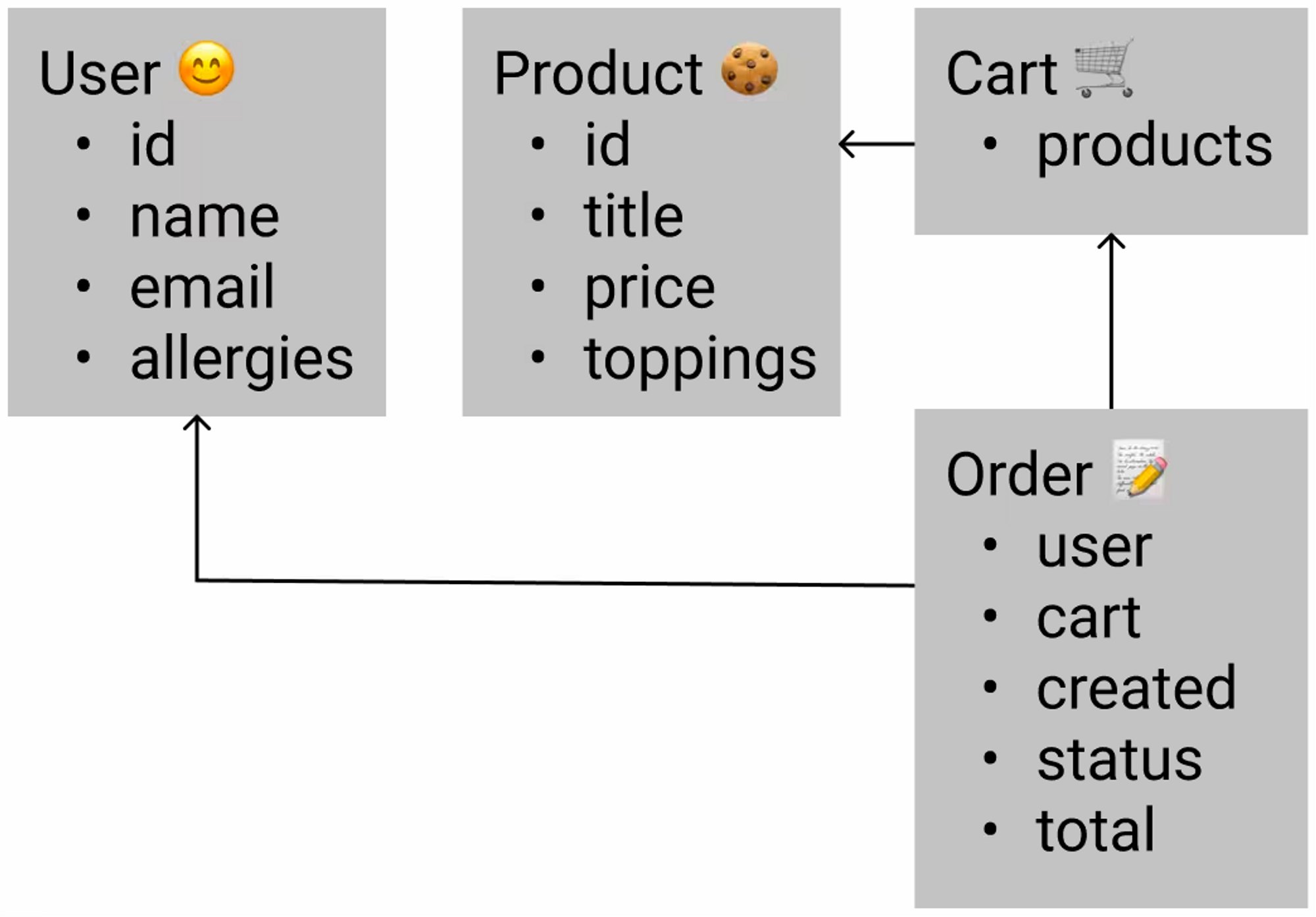
엔테티 관계 다이어그램(Entity Relationship Diagram)
우리는 이제 보고 확인할 수 있습니다:
- main actor가 정말로 유저인지
- 주문에 충분한 정보가 존재하는지
- 몇몇 엔티티들이 확장될 필요가 있는지
- 미래의 확장성에 문제는 없는지
Creating Data Transformations
우리가 방금 설계한 유형의 데이터에는 여러 가지 일이 발생할 것입니다. 아이템들을 장바구니에 추가하고, 비우거나, 아이템이나 유저의 이름을 업데이트 하는 등. 우리는 이러한 모든 변환을 위해 분리된 함수들을 만들 것입니다.
예를 들어, 유저가 어떤 성분이나 선호에 대해 알러지가 있는지 확인하기 위해서는 hasAllergy 와 hasPreference 함수를 작성할 수 있습니다:
// domain/user.ts
export function hasAllergy(user: User, ingredient: Ingredient): boolean {
return user.allergies.includes(ingredient);
}
export function hasPreference(user: User, ingredient: Ingredient): boolean {
return user.preferences.includes(ingredient);
}함수 addProduct와 contains 는 아이템을 장바구니에 추가하고 존재하는지 확인하기 위해 사용됩니다:
// domain/cart.ts
export function addProduct(cart: Cart, product: Product): Cart {
return { ...cart, products: [...cart.products, product] };
}
export function contains(cart: Cart, product: Product): boolean {
return cart.products.some(({ id }) => id === product.id);
}물건들의 리스트에서 총액을 계산하기 위해 totalPrice 함수도 작성할 것입니다. 만약 필요하다면, 시즌 할인이나 프로모션 코드와 같은 다양한 조건을 계산하기 위한 함수도 추가할 수 있습니다.
// domain/product.ts
export function totalPrice(products: Product[]): PriceCents {
return products.reduce((total, { price }) => total + price, 0);
}유저들이 주문을 생성할 수 있도록, createOrder 함수도 생성할 것입니다. 이 함수는 특정 유저와 유저의 장바구니에서 새로운 주문을 반환할 것입니다.
// domain/order.ts
export function createOrder(user: User, cart: Cart): Order {
return {
cart,
user: user.id,
status: "new",
created: new Date().toISOString(),
total: totalPrice(products),
};
}명심하세요. 모든 함수들에서 데이터를 편리하게 변환할 수 있도록 API를 구축합니다. 인수(argument)들을 받고 우리가 원하는 결과를 돌려줍니다.
설계 단계에서는 외부적인 제약이 아직 없습니다. 이것은 주제 도메인(subject domain)에 가능한만큼 유사하게 데이터 변환을 반영할 수 있게 해줍니다. 그리고 현실과 변환이 유사할 수록 우리의 작업을 확인하기가 쉬워집니다.
Into Detail: Shared Kernel
도메인 타입들을 설계할 때 몇가지 특이한 타입들이 있었습니다. 예를 들어 Email, UniqueId, DateTimeString. 이것들은 타입 별칭(type-alias)입니다:
// shared-kernel.d.ts
type Email = string;
type UniqueId = string;
type DateTimeString = string;
type PriceCents = number;저는 보통 기본형에 대한 집착(primitive obsession)을 줄이기 위해 타입 별칭을 사용합니다.
저는 문자열이 어떻게 사용되는지 분명히 하기 위해서 그저 string을 사용하는 대신 DateTimeString을 사용합니다. 타입이 주제 영역에 더 가까울 수록 에러가 발생했을 때 대처하기가 더 쉬워집니다.
명시된 타입들(specified types)은 shared-kernel.d.ts 파일에 존재합니다. 공유된 커널(Shared kernel)은 모듈들 사이에 결합도를 증가시키지 않는 코드와 데이터입니다. 이에 대한 더 자세한 내용은 "DDD, Hexagonal, Onion, Clean, CQRS, ...How I put it all together"에서 찾아보세요.
실제로, 공유된 커널은 다음과 같이 설명될 수 있습니다. 우리는 Typescript를 사용하며, 표준 타입 라이브러리를 사용합니다, 그러나 그들을 종속성으로 생각각하지 않습니다. 그 이유는 이를 사용하는 모듈들이 서로에 대해 아무것도 모르고 분리된 상태로 남아 있을 수 있기 때문입니다.
모든 코드들이 공유된 커널 처럼 분류될 수 있는 것은 아닙니다. 주요하고 가장 중요한 제한은 이러한 코드가 시스템의 모든 부분과 호환되어야 한다는 것입니다. 만약 어플리케이션의 일부가 Typescript로 작성되고 다른 부분이 다른 언어로 작성되었다면, 공유된 커널은 두 부분 모두에서 사용 가능한 코드들만 포함할 수 있습니다. 예를 들어, JSON 형식의 엔티티 명세는 괜찮지만 TypeScript helpers는 그렇지 않습니다.
우리의 경우에는 전체 어플리케이션이 Typescript로 작성되므로, built-in 타입들에 대한 타입 별칭들은 공유된 커널로 분류할 수 있습니다. 이렇게 전역적으로 이용 가능한 타입들은 모듈들 간의 결합도를 상승시키지 않으며, 어플리케이션의 어느 부분에서도 사용될 수 있습니다.
Into Detail: Application Layer
이제 도메인을 파악했으므로 어플리케이션 레이어로 이동할 수 있습니다. 이 레이어에는 유스 케이스들이 포함되어 있습니다.
코드에서는 시나리오들의 기술적인 세부 사항을 설명합니다. 유스 케이스는 계산 진행시나 장바구니에 물건 담기 이후 어떤 일이 데이터에게 일어날지에 대한 설명입니다.
유스 케이스들은 외부와의 상호작용, 즉 외부 서비스들에 대한 이용을 포함합니다. 외부와의 상호작용은 부작용(side-effect)입니다(디비나 통신이 들어가면 에러가 발생할 수 있음을 의미함). 우리 부작용(외부의 변수)가 없는 시스템들혹은 함수들로 작업하거나 디버그하는 것이 쉽다는 것을 압니다. 우리의 도메인 함수들의 대부분은 이미 순수 함수들로 작성되었습니다.
순수한 변환들과 상호작용을 불순한 세상(부작용이 존재할 수 있는)과 결합하려면, 어플리케이션 레이어를 불순한 맥락(impure context)에서 사용할 수 있습니다.
Impure Context For Pure Transformations
순수한 변환을 위한 불순한 맥락은 다음과 같은 코드 조직입니다:
- 우리는 최초로 몇몇 데이터를 가져오기 위해 부작용을 수행한다.
- 그 이후 데이터에 순수한 변환(pure transformation)을 수행한다.
- 그리고 결과를 전달하거나 저장하기 위해 부작용을 다시 수행한다.
“장바구니에 아이템을 담는다”라는 유스 케이스에서는 다음과 같을 수 있습니다:
- 최초로, 핸들러가 저장소로부터 장바구니의 상태를 얻습니다.
- 그 이후 추가될 아이템을 전달 받아 장바구니 갱신 함수를 호출합니다.
- 그리고 갱신된 장바구니를 저장소에 저장합니다.
전체 과정이 “샌드위치”와 비슷합니다: 부작용, 순수 함수, 부작용. 메인 로직은 데이터 변환(순수한 변환)에 반영되며, 외부와의 모든 소통은 명령 쉘(imperative shell)에 격리되어 있습니다.

Functional architecture: side-effect, pure function, side-effect
불순한 맥락은 종종 명령 쉘의 기능적 핵심으로 불립니다. 이에 대해서는 Mark Seemann이 그의 블로그에 적은 글이 있습니다. 이러한 접근법으로 유스 케이스 함수들을 작성할 것입니다.
Designing Use Case
결제 유스 케이스를 설계해볼 것입니다. 이는 비동기적이며 많은 서드파티 서비스들과 상호작용하기에 가장 대표적인 예시입니다. 나머지 시나리오와 전체 어플리케이션 코드는 깃허브에서 찾아보세요.
이 유스 케이스에서 우리의 목표를 생각해봅시다. 유저는 쿠키들이 담긴 장바구니를 지니고 있을 것이며, 유저가 계산 버튼을 누른다면:
- 새로운 주문을 생성해야합니다.
- 새로운 주문에 대한 서드파티 결제 시스템을 통한 결제가 일어나야 합니다.
- 결제가 실패했다면, 유저에게 실패 사실을 알려야 합니다.
- 결제가 성공했다면, 주문을 서버에 저장해야합니다.
- 화면에 보여주기 위해 주문을 로컬 데이터 저장소에 추가해야합니다.
API와 함수 시그니처(function signature)의 관점에서, 우리는 유저와 장바구니를 인수로 넘기고 다른 모든 것은 함수 스스로 하기를 원합니다.
type OrderProducts = (user: User, cart: Cart) => Promise<void>;이상적으로, 당연하겠지만 유스 케이스는 2개의 다른 인수를 받아서는 안되며 모든 입력 데이터를 자체적으로 내부에 캡슐화하는 명령을 사용해야합니다. 하지만 우리는 코드의 양이 불어나는 것을 원치 않기 때문에, 내버려 둡시다.
Writing Application Layer Ports
유스 케이스들의 단계를 자세히 살펴보겠습니다: 주문 생성 자체는 도메인 함수 입니다. 그 외의 우리가 사용하는 모든 것은 외부 서비스들입니다.
다시 한번 강조하자면, 외부 서비스들의 우리의 필요에 맞춰야하지 그 반대가 되서는 안됩니다. 그러므로 어플리케이션 레이어에서는 유스 케이 자체 뿐만이 아니라 외부 서비스들에 대한 인터페이스인 포트들에 대해서도 설명할 것입니다.
포트들은 우선적으로 우리 어플리케이션에 편리해야 합니다. 외부 서비스들의 API가 우리의 필요와 호환되지 않는다면, 어댑터를 작성해야 합니다.
우리가 필요로 하는 서비스들에 대해 생각해보죠:
- 결제 시스템
- 에러와 이벤트를 유저에게 알리는 서비스
- 로컬 저장소에 데이터를 저장하는 서비

우리가 필요한 서비스들
중요한 것은 현재로썬 이러한 서비스들의 구현이 아닌 인터페이스들에 대해 이야기하고 있다는 것입니다. 이번 장에서는, 요구된 행동들을 기술하는 것이 중요합니다. 왜냐하면 시나리오를 설명할 때 어플리케이션 계층에서는 이 행동들에 의존하기 때문입니다.
이 행동이 정확히 어떻게 구현될지는 아직 중요하지 않습니다. 따라서 어떤 외부 서비스를 사용할지에 대한 결정을 마지막 순간까지 연기할 수 있으며, 이로 인해 코드가 최소한으로 결합됩니다. 구현은 나중에 처리하도록 하겠습니다.
또한 인터페이스를 기능별로 나눈다는 점에 유의하세요. 결제와 관련된 모든 것은 한 모듈에 있고, 스토리지와 관련된 모든 것은 다른 모듈에 있습니다. 이렇게 하면 서로 다른 서드 파티 서비스들의 기능이 혼동되지 않도록 하는 것이 더 쉬워집니다.
Payment System Interface
쿠키 가게는 샘플 어플리케이션입니다, 그러므로 결제 시스템이 매우 단순합니다. 결제해야하는 총 금액을 수락하고, 결제가 성공적으로 끝났다면 확인을 응답으로 보내주는 tryPay 메소드를 사용합니다.
// application/ports.ts
export interface PaymentService {
tryPay(amount: PriceCents): Promise<boolean>;
}에러 핸들링은 따로 적어야 할만큼 내용이 방대하기에, 에러 핸들링은 적지 않겠습니다.
물론, 결제는 서버에서 처리되어야 하지만 예제이기 때문에 클라이언트에서 모든 것을 처리하겠습니다. 결제 시스템과 직접 연결하는 대신 우리의 API를 통해 쉽게 통신할 수 있습니다. 참고로 이 변경은 이번 유스 케이스에만 영향을 미치고 나머지 코드는 건들지 않습니다.
Notification Service Interface
무언가 잘못됐다면, 유저에게 전달해줘야 합니다.
유저는 다양한 방법으로 알림을 받을 수 있습니다. UI나 글자 혹은 유저의 폰이 진동(제발 그러지마세요)하는 방법으로 알릴 수 있습니다.
일반적으로는 알림 서비스는 추상화되는 것이 더 좋습니다, 그러므로 지금은 구현에 대해서는 생각하지 않겠습니다.
메세지를 받아서 유저에게 어떻게든 알려봅시다:
// application/ports.ts
export interface NotificationService {
notify(message: string): void;
}Local Storage Interface
로컬 레포지토리에 새 주문을 저장할 것 입니다.
이 저장소는 무엇이든 될 수 있습니다: Redux, MobX, whatever-floats-your-boat-js. 레포지토리는 다른 엔티티들을 저장하는 마이크로-저장소(micro-stores)로 나뉠 수도 있고, 모든 어플리케이션 데이터를 저장하는 하나의 큰 레포지토리가 될 수도 있습니다. 현재로써는 중요하지 않습니다. 왜냐하면 그러한 내용들은 자세한 구현에 해당하기 때문입니다.
저는 저장소 인터페이스들을 각 엔티티 별로 분리하는 것을 좋아합니다. 유저 데이터 저장소를 위한, 장바구니를 위한, 주문 저장소를 위한 분리된 인터페이스처럼.
// application/ports.ts
export interface OrdersStorageService {
orders: Order[];
updateOrders(orders: Order[]): void;
}이번 예시에서는 주문 저장소 인터페이스만을 만들 것입니다. 나머지는 소스 코드에서 확인하세요.
Use Case Function
만들어진 인터페이스들과 존재하는 도메인 기능들을 사용함으로써 유스 케이스를 만들 수 있을지 알아보죠. 이전에 설명했듯이, 스크립트는 다음과 같은 단계를 거칩니다:
- 데이터를 검증한다.
- 주문을 생성한다.
- 주문에 대해 결제한다.
- 문제에 대해 알린다(실패 시).
- 주문 결과를 저장한다.
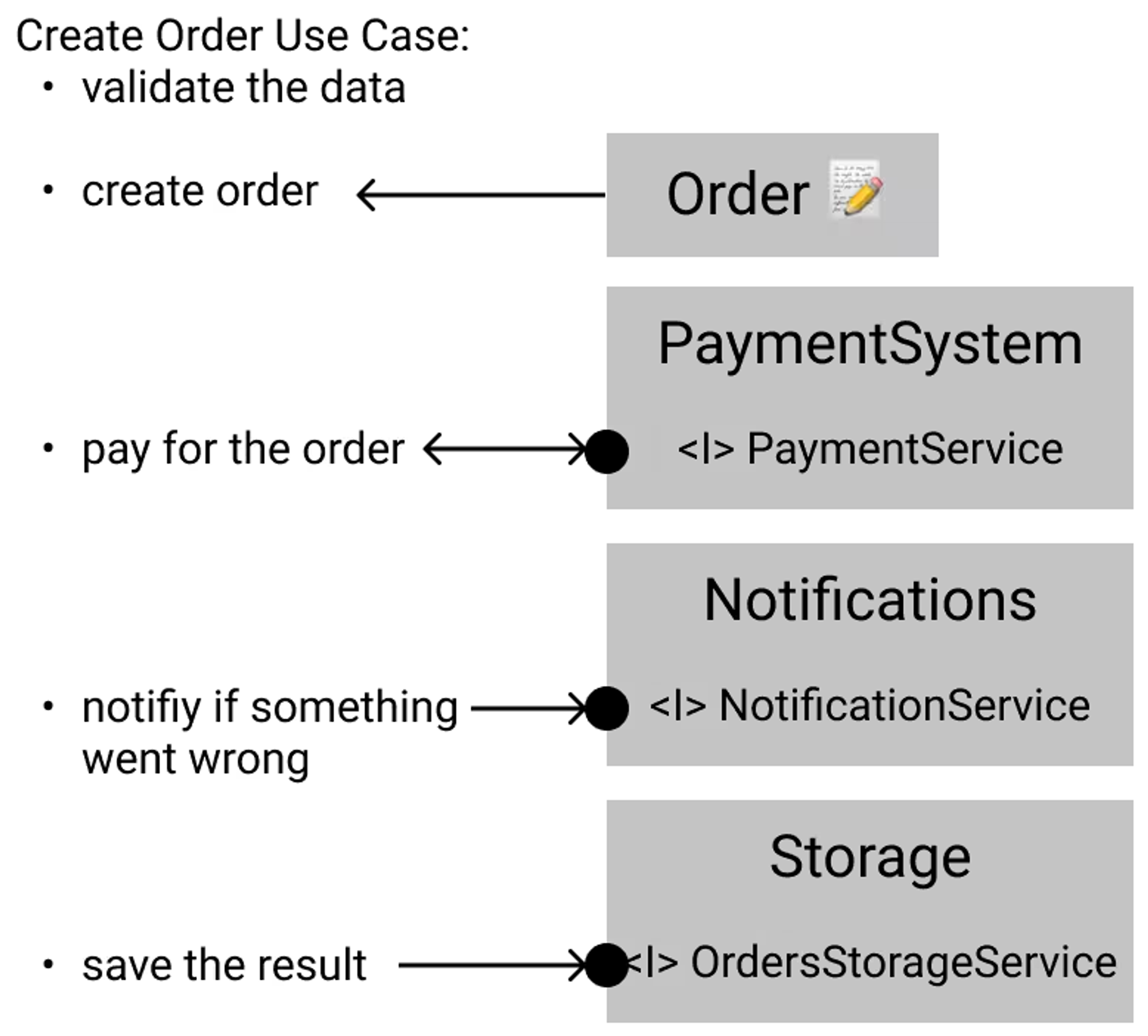
사용자 정의 스크립트에서의 모든 단계에 대한 다이어그램
우선, 우리가 사용할 서비스들에 대한 스텁(stub)들을 선언합시다. Typescript는 우리가 적절한 변수의 인터페이스들을 구현하지 않았다고 경고할 것이지만, 현재로서는 문제가 되지 않습니다.
// application/orderProducts.ts
const payment: PaymentService = {};
const notifier: NotificationService = {};
const orderStorage: OrdersStorageService = {};이제 우리는 스텁들을 실제 서비스인 것 처럼 만들 것입니다. 우리는 그들의 필드들에 접근 가능하며 메소드들을 호출 할 수 있습니다. 이것은 비즈니스 언어에서 소프트웨어 언어로 유스 케이스를 "번역"할 때 유용합니다.
이제 orderProducts 라는 함수를 만들어 봅시다. 내부에서 가장 먼저 하는 일은 새 주문을 만드는 것입니다:
// application/orderProducts.ts
//...
async function orderProducts(user: User, cart: Cart) {
const order = createOrder(user, cart);
}여기서 우리는 인터페이스가 행동을 위한 약속이라는 사실을 이용합니다. 이것은 미래에 스텁들이 실제로 우리가 현재 기대하는 동작을 수행할 것이라는 것을 의미합니다:
// application/orderProducts.ts
//...
async function orderProducts(user: User, cart: Cart) {
const order = createOrder(user, cart);
// Try to pay for the order;
// Notify the user if something is wrong:
const paid = await payment.tryPay(order.total);
if (!paid) return notifier.notify("Оплата не прошла 🤷");
// Save the result and clear the cart:
const { orders } = orderStorage;
orderStorage.updateOrders([...orders, order]);
cartStorage.emptyCart();
}명심하세요. 유스 케이스들은 서드 파티 서비스들을 직접 호출하지 않습니다. 그것은 인터페이스들에 설명된 행동들에 의존합니다, 그러므로 인터페이스가 동일하게 유지된다면, 어떤 모듈인지 혹은 어떻게 동작하는지에 대해서는 신경쓸 필요가 없습니다. 이는 모듈들을 교체 가능하게 만들어 줍니다.
Into Detail: Adapters Layer
우리는 Typescript로 “번역된(비즈니스 언어에서)” 유스 케이스들을 가지고 있습니다. 이제 현실이 우리의 요구와 일치하는지 확인해보죠.
보통은 일치하지 않습니다. 그러므로 외부 세계를 우리의 요구에 맞도록 어댑터들을 통해 변경해야합니다.
Binding UI and Usecase
첫번째 어댑터는 UI 프레임워크입니다. 그것은 네이티브 브라우져 API를 어플리케이션에 연결합니다. 주문 생성의 경우에는 “결제” 버튼 그리고 유스 케이스 함수를 실행시키는 클릭 핸들러가 UI 프레임워크에 해당합니다.
// ui/components/Buy.tsx
export function Buy() {
// Get access to the use case in the component:
const { orderProducts } = useOrderProducts();
async function handleSubmit(e: React.FormEvent) {
setLoading(true);
e.preventDefault();
// Call the use case function:
await orderProducts(user!, cart);
setLoading(false);
}
return (
<section>
<h2>Checkout</h2>
<form onSubmit={handleSubmit}>{/* ... */}</form>
</section>
);
}훅을 통해서 유스 케이스를 제공해 봅시다. 우리는 모든 서비스를 내부에서 받을 것이고(내부적으로 구현 했으므로?), 결과적으로, 유스 케이스 함수 자체를 훅에서 반환할 것이다.
// application/orderProducts.ts
export function useOrderProducts() {
const notifier = useNotifier();
const payment = usePayment();
const orderStorage = useOrdersStorage();
async function orderProducts(user: User, cookies: Cookie[]) {
// …
}
return { orderProducts };
}우리는 훅을 “비뚤어진 의존성 주입(crooked dependency injection)”처럼 사용했습니다. 우선 useNotifier, usePayment, useOrdersStorage 훅들을 서비스 인스턴스를 얻기 위해 사용했습니다, 그리고 useOrderProducts함수의 클로져(closure)를 사용해 orderProducts 함수 내부에서 서비스들을 이용 가능하게 만들었습니다.
유스 케이스 함수들이 테스트에 중요한 나머지 코드와 여전히 분리되어 있다는 점에 유의해야 합니다. 글의 마지막 부분에서 리뷰 및 리팩터링을 할 때 완전히 뽑아내어 더욱 테스트가 쉽게 만들겠습니다.
Payment Service Implementation
유스 케이스들은 PaymentService 인터페이스를 사용합니다. 그걸 구현해보죠.
결제를 위해서는 우리는 가짜 API 스텁들 사용할 것입니다. 다시 한번 말하지만, 우리는 지금 전체 서비스를 작성해야 하는 것이 아니기, 특정 기능들은 구현하기 위해 나중에 작성할 수 있습니다:
// services/paymentAdapter.ts
import { fakeApi } from "./api";
import { PaymentService } from "../application/ports";
export function usePayment(): PaymentService {
return {
tryPay(amount: PriceCents) {
return fakeApi(true);
},
};
}fakeApi 함수는 서버로부터 지연되는 응답을 모방하기 위해 450ms 이후에 발생하는 타임아웃입니다. 해당 함수는 인수로 넘긴 데이터를 그대로 돌려줍니다.
// services/api.ts
export function fakeApi<TResponse>(response: TResponse): Promise<TResponse> {
return new Promise((res) => setTimeout(() => res(response), 450));
}usePayment의 반환값(Promise<TResponse>)을 명시적으로 입력합니다. 이러한 방식으로 Typescript는 함수가 실제로 인터페이스에 선언된 모든 메서드를 포함하는 개체를 반환하는지 확인합니다.
Notification Service Implementation
알림을 간단한 alert로 정하겠습니다. 코드가 분리되어 있기 때문에 나중에 이 서비스를 다시 작성하는 것은 문제가 되지 않습니다.
// services/notificationAdapter.ts
import { NotificationService } from "../application/ports";
export function useNotifier(): NotificationService {
return {
notify: (message: string) => window.alert(message),
};
}Local Storage Implementation
로컬 저장소를 React.Context와 훅으로 정하겠습니다. 새로운 컨텍스트를 생성하고, 값을 공급자(provider)에게 전달하며, 공급자를 내보내고, 훅을 통해 스토어에 액세스하게 했습니다.
// store.tsx
const StoreContext = React.createContext({});
export const useStore = () => useContext(StoreContext);
export const Provider: React.FC = ({ children }) => {
// ...Other entities...
const [orders, setOrders] = useState([]);
const value = {
// ...
orders,
updateOrders: setOrders,
};
return <StoreContext.Provider value={value}>{children}</StoreContext.Provider>;
};각 기능에 대한 후크를 작성할 것입니다. 이런 식으로 인터페이스 분리 원칙(Interface Segregation Principle)를 깨지 않으며, 적어도 인터페이스 측면에서, 저장소들은 원자적일 것 입니다.
// services/storageAdapter.ts
export function useOrdersStorage(): OrdersStorageService {
return useStore();
}또한, 이러한 접근법은 각 저장소에 대한 추가적인 최적화를 커스터마이징할 수 있습니다 : selectors, memoization 등을 추가할 수 있습니다.
Validate Data Flow Diagram
이제 만든 유스 케이스 동안 사용자가 응용 프로그램과 통신하는 방법을 검증해 보겠습니다.
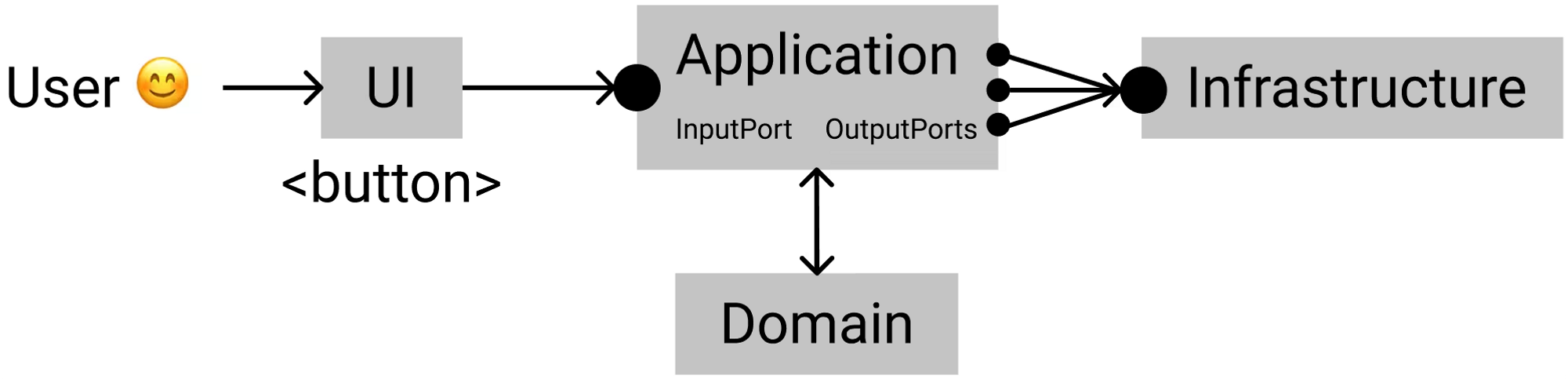
유스 케이스 데이터 플로우 다이어그램
유저는 포트들을 통해서만 어플리케이션에 접근할 수 있는 UI 레이어와 상호작용 합니다. 즉 우리가 원한다면 UI를 변경할 수 있습니다.
유스 케이스들은 어플리케이션 레이어에서 처리되므로 필요한 외부 서비스들이 정확히 무엇인지 알려주고 있습니다. 모든 주요 로직과 데이터는 도메인에 있습니다.
모든 외부 서비스들은 인프라(Infrastructure)에 숨겨져있으며, 우리의 명세에 맞춰져 있습니다. 만약 우리가 메시지를 보내는 서비스를 바꿔야 한다면, 우리가 코드에서 고쳐야 할 유일한 부분은 새로운 서비스를 위한 어댑터 뿐입니다.
이러한 설계는 코드를 교체할 수 있고, 테스트할 수 있으며, 변화하는 요구사항에 맞게 확장할 수 있게 합니다.
What Can Be Improved
전반적으로 이 정도면 클린 아키텍처를 시작하고 간단히 이해하기에 충분합니다. 하지만 저는 예시를 더 쉽게 만들기 위해 제가 단순화한 것들을 지적하고 싶습니다.
이 섹션은 선택 사항이지만 "축약되지 않은(with no cut corners)" 클린 아키텍처가 어떤 것인지에 대한 확장된 이해를 제공합니다.
저는 더 할 수 있는 몇 가지를 강조하고 싶습니다.
Use Object Instead of Number For the Price
가격을 설명하기 위해 숫자를 사용하는 것을 주목했을 것입니다. 이것은 좋은 예시가 아닙다.
// shared-kernel.d.ts
type PriceCents = number;숫자는 양을 나타낼 화폐(currency)를 나타내진 못합니다. 그리고 화폐 없는 가격은 의미가 없습니다. 이상적으로, 가격은 가치(value)와 화폐(currency) 2가지 필드를 가지는 오브젝트로 만들어져야 합니다.
type Currency = "RUB" | "USD" | "EUR" | "SEK";
type AmountCents = number;
type Price = {
value: AmountCents;
currency: Currency;
};이렇게 하면 화폐를 저장하는 문제가 해결되고 가게에서 화폐를 변경하거나 추가할 때 많은 노력과 걱정을 절약할 수 있습니다. 저는 복잡하지 않기 위해 예시에서 이 타입을 사용하지 않았습니다. 그러나 실제 코드에서는 가격이 이 타입과 더 비슷할 것입니다.
별도로, 가격의 가치를 언급할 가치가 있습니다다. 저는 항상 유통되는 화폐의 가장 작은 단위에 돈의 양을 맞춥니다. 예를 들어, 달러의 경우 그것은 센트입니다.
이렇게 가격을 표시하는 것은 로 하여금 나눗셈과 분수 값에 대해 생각하지 않게 해줍다. 돈과 함께라면 부동소수점 수학의 문제를 피하기 위해 특히 중요합니다.
Split Code by Features, not Layer
폴더의 코드들은 “레이어에 의해(현재)”가 아닌 “기능에 의해” 나뉠 수 있습니다. 하나의 기능은 아래 구조도의 파이 조각 하나일 것입니다.
이 구조는 특정 기능을 개별적으로 배포할 수 있기 때문에 훨씬 더 유용합니다(MSA 비슷한건가?).
컴포넌트는 각진 파이의 한 조각이다.
그것에 대해서는 "DDD, Hexagonal, Onion, Clean, CQRS, ... How I put it all together"를 읽어보기를 추천합니다.
또한 컴포넌트 코드 분할과 개념적으로 매우 유사하지만 이해하기 쉬운 Feature Sliced를 볼 것을 제안합니다.
Pay Attention to Cross-Component Usage
시스템을 컴포넌트들로 쪼개는 것에 대해 이야기하자면, cross-component 사용도 언급할 가치가 있습니다. 다음과 같은 주문 생성 함수를 기억하시나요:
import { Product, totalPrice } from "./product";
export function createOrder(user: User, cart: Cart): Order {
return {
cart,
user: user.id,
status: "new",
created: new Date().toISOString(),
total: totalPrice(products),
};
}이 함수는 상품(product)라는 다른 컴포넌트의 totalPrice 를 사용합니다. 그런 사용법 자체는 괜찮지만, 코드를 독립적인 기능으로 나누려면 다른 기능에 직접 액세스할 수 없습니다.
"DDD, Hexagonal, Onion, Clean, CQRS, ... How I put it all together"와 Feature Sliced에서 이러한 제약을 극복할 방법을 볼 수 있을 것입니다.
Use Branded Types, not Aliases
공유된 커널을 위해 타입 대체를 사용했었습니다. 새 타입을 생성하고 string과 같은 타입을 참조시키기만 하면 되기에 사용하기 쉽습니다. 그러나 그들의 단점은 Typescript에 그들의 사용을 감시하고 강제하는 메커니즘이 없다는 것이다.
이것은 문제가 아닌 것처럼 보일 수 있습니다: 그러므로 누군가 string을 DateTimeString대신 사용하더라도 코드는 컴파일 됩니다.
이러한 문제는 더 다양한 타입이 사용되더라도 코드가 컴파일 된다는 것입니다(어려운 말로 전제 조건이 약해진다는 뜻). 이것은 무엇보다도 코드를 더 취약하게 만듭니다다. 왜냐하면 당신이 오류를 초래할 수 있도록 특별한 품질의 문자열뿐만 아니라 어떤 문자열도 사용할 수 있게 하기 때문입니다.
그 다음으로 읽기에 혼란스럽습니다. 왜냐하면 두가지 진실의 원천을 만들기 때문입니다. 당신이 정말 그곳에 날짜만 사용하면 되는지 아니면 기본적으로 어떤 문자열도 사용할 수 있는지가 불분명하기 때문입니다.
Typescript가 우리가 원하는 특정 타입을 이해할 수 있는 방법이 있습니다. branding, branded types를 사용하세요. 브랜딩은 타입이 어떻게 사용되는지 정확하게 추적 가능하게 하지만 코드를 조금 더 복잡하게 만듭니다.
Pay Attention to Possible Dependency in Domain
다음으로 거슬리는 것은 createOrder 함수에서의 날짜 생성입니다.
import { Product, totalPrice } from "./product";
export function createOrder(user: User, cart: Cart): Order {
return {
cart,
user: user.id,
// This line:
created: new Date().toISOString(),
status: "new",
total: totalPrice(products),
};
}new Date().toISOString()이 프로젝트에서 꽤 자주 반복될 것으로 예상할 수 있으며, 이를 일종의 도우미(helper)로 배치하고자 합니다:
// lib/datetime.ts
export function currentDatetime(): DateTimeString {
return new Date().toISOString();
}그리고 그 도우미를 도메인에서 사용합니다:
// domain/order.ts
import { currentDatetime } from "../lib/datetime";
import { Product, totalPrice } from "./product";
export function createOrder(user: User, cart: Cart): Order {
return {
cart,
user: user.id,
status: "new",
created: currentDatetime(),
total: totalPrice(products),
};
}하지만 도메인에서는 어떤 것에도 의존할 수 없다는 것을 기억할 것입니다. 그렇다면 어떻게 해야 할까요? createOrder는 주문에 대한 모든 데이터를 완전한 형태로 가져오는 것이 좋습니다. 날짜는 마지막 인수로 전달할 수 있습니다:
// domain/order.ts
export function createOrder(user: User, cart: Cart, created: DateTimeString): Order {
return {
user: user.id,
products,
created,
status: "new",
total: totalPrice(products),
};
}이를 통해 날짜 작성이 라이브러리에 따라 달라지는 경우 종속성 규칙을 위반하지 않을 수 있습니다. 도메인 함수 외부에 날짜를 생성하면 유스 케이스 내부에서 날짜를 생성해서 인수로 전달할 것입니다:
function someUserCase() {
// Use the `dateTimeSource` adapter,
// to get the current date in the desired format:
const createdOn = dateTimeSource.currentDatetime();
// Pass already created date to the domain function:
createOrder(user, cart, createdOn);
}이렇게 함으로써 도메인을 독립적으로 두고 테스트하기 더 쉽게 만듭니다.
예제에서는 두 가지 이유로 이것에 초점을 맞추지 않기로 선택했습니다: 주제에서 벗어날 것 같았으며 또한 언어 기능(외부 라이브러리가 아닌)만을 사용한다면 도우미에 의존하는 것이 아무런 문제가 없다고 봅니다. 이러한 도우미는 코드 중복을 줄일 뿐이기 때문에 공유 커널로 간주될 수도 있습니다.
Keep Domain Entities and Transformations Pure
createOrder 함수 내부에서 날짜를 생성할 때에 정말 좋지 않았던 점은 부작용이었습니다. 부작용으로 인한 문제는 당신이 의도한 것보다 시스템이 덜 정확하게 만든다는 것입니다. 이에 대처하는 데 도움이 되는 것은 도메인 내의 순수한 데이터 변환, 즉 부작용이 발생하지 않는 변환입니다.
날짜를 생성하는 것은 부작용입니다. 왜냐하면 Date.now()을 호출한 결과는 시간에 따라 다르기 때문입니다. 그러나 순수 함수는 똑같은 인수가 주어진다면 항상 같은 결과를 반환해야합니다.
가능한 한 도메인을 깨끗하게 유지하는 것이 좋다는 결론에 도달했습니다. 테스트가 더 쉽고, 이식 및 업데이트가 더 쉬우며, 읽기도 더 쉽습니다. 부작용은 디버깅 시 인지 부하(cognitive load)를 엄청나게 증가시키며, 도메인은 복잡하고 혼란스러운 코드를 보관하는 곳이 전혀 아닙니다.
Pay Attention to Relationship Between Cart and Order
이번 작은 예시에서는 Order가 Cart를 포함하고 있습니다. 왜냐하면 장바구니는 물건들의 목록만을 나타내기 때문입니다:
export type Cart = {
products: Product[];
};
export type Order = {
user: UniqueId;
cart: Cart;
created: DateTimeString;
status: OrderStatus;
total: PriceCents;
};Cart에 Order와 관련이 없는 추가적인 속성들이 생긴다면 작동하지 않을 수 있습니다. 이러한 경우에는 data projections 이나 intermediate DTO를 사용하는 것이 더 낫습니다.
하나의 선택지로 “Product List” 엔티티들 사용할 수도 있습니다.
type ProductList = Product[];
type Cart = {
products: ProductList;
};
type Order = {
user: UniqueId;
products: ProductList;
created: DateTimeString;
status: OrderStatus;
total: PriceCents;
};Make the user case more testable
유스 케이스에 대해서도 논의해야 할 부분이 많습니다. 현재 orderProducts 함수는 React와 분리하여 테스트하기가 어렵습니다. 이는 좋지 않습니다. 이상적으로는 최소한의 노력을 들여 테스트할 수 있어야 합니다.
현재 구현에서의 문제는 유스 케이스에서 UI에 접근하도록 하는 훅입니다:
// application/orderProducts.ts
export function useOrderProducts() {
const notifier = useNotifier();
const payment = usePayment();
const orderStorage = useOrdersStorage();
const cartStorage = useCartStorage();
async function orderProducts(user: User, cart: Cart) {
const order = createOrder(user, cart);
const paid = await payment.tryPay(order.total);
if (!paid) return notifier.notify("Oops! 🤷");
const { orders } = orderStorage;
orderStorage.updateOrders([...orders, order]);
cartStorage.emptyCart();
}
return { orderProducts };
}표준 구현에서 유스 케이스 함수는 훅 외부에 위치하며 서비스는 마지막 인수 또는 DI를 통해 유스 케이스로 전달됩니다:
type Dependencies = {
notifier?: NotificationService;
payment?: PaymentService;
orderStorage?: OrderStorageService;
};
async function orderProducts(
user: User,
cart: Cart,
dependencies: Dependencies = defaultDependencies,
) {
const { notifier, payment, orderStorage } = dependencies;
// ...
}이렇게 하면 훅이 어댑터가 됩니다:
function useOrderProducts() {
const notifier = useNotifier();
const payment = usePayment();
const orderStorage = useOrdersStorage();
return (user: User, cart: Cart) =>
orderProducts(user, cart, {
notifier,
payment,
orderStorage,
});
}그러나 보통은 의존성 주입을 통해 자동화되고 끝납니다. 이미 마지막 인수를 통한 주입의 가장 간단한 버전을 살펴 보았지만, 더 나아가 자동 주입을 구성할 수 있습니다.
이 특수한 어플리케이션에서 저는 DI를 구성하는 데에 노력을 기울이지 않았습니다. 그것은 주제에서 벗어나 코드를 지나치게 복잡하게 만들 것입니다. React와 훅들의 경우 지정된 인터페이스의 구현을 반환하는 "컨테이너"로 사용할 수 있습니다. 네, 수동 작업이지만 진입 장을 높이지 않고 신규 개발자가 읽기 더 빠릅니다.
What Can Be More Complicated in Real Project
이 글의 예는 개량되어 있고 의도적으로 단순합니다. 현실은 이 예제보다 훨씬 더 놀랍고 복잡하다는 것은 분명합니다. 그래서 저는 클린 아키텍처로 작업할 때 발생할 수 있는 일반적인 문제에 대해서도 이야기하고 싶습니다.
Branching Business Logic
가장 중요한 문제는 우리가 지식이 부족한 주제 영역입니. 상점에 제품, 할인 제품 및 폐기 제품이 있다고 상상해 보십시오. 이러한 엔티티들을 어떻게 적절하게 설계해야 할까요?
"기반" 엔티티가 확장되어야 하나요? 이 엔티티를 정확히 어떻게 확장해야 합니까? 추가 필드가 있어야 합니까? 이러한 엔티티는 상호 배타적이어야 합니까? 단순한 엔티티가 아닌 다른 엔티티가 있는 경우 유스 케이스는 어떻게 작동해야 합니까? 중복을 즉시 줄여야 합니까?
팀과 이해 관계자 모두 아직 시스템이 실제로 어떻게 작동해야 하는지 모르기 때문에 질문과 답변이 너무 많을 수 있습니다. 가정만 있다면 분석 마비에 걸린 자신을 발견할 수 있습니다.
구체적인 해결책은 구체적인 상황에 따라 달라지는데, 몇 가지 일반적인 것만 추천할 수 있습니다.
상속을 "확장"이라고 해도 사용하지 마십시오. 인터페이스가 실제로 상속된 것처럼 보이더라도 말입니다. "글쎄요, 여기에는 분명히 계층이 있어요"처럼 보일지라도 말이죠. 잠깐만요.
코드의 복사 붙여넣기는 항상 악의적인 것이 아니라 도구입니다. 거의 동일한 두 개의 엔티티들을 만들고, 그들이 실제로 어떻게 작동하는지 보고, 관찰합니다. 어느 시점에서 여러분은 그들이 매우 달라졌다는 것을 알게 될 것입니다. 또는 그들은 정말로 한 분야에서만 다릅니다. 가능한 모든 조건 및 변형에 대한 검사를 만드는 것보다 유사한 두 엔티티를 하나로 병합하는 것이 더 쉽습니다.
아직도 뭔가를 확장해야 한다면요...
공분산, 반분산 및 불변성(covariance, contravariance, and invariance)을 명심함으로써 필요한 것보다 더 많은 작업이 발생하지 않도록 하십시오.
서로 다른 엔티티와 확장 기능 중에서 선택할 때 BEM의 블록 및 한정자와의 유사성을 사용하세요. BEM의 맥락에서 생각하면 코드가 별도의 엔티티인지 "수정자 확장(modifier-extension)"인지 결정하는 데 많은 도움이 됩니다.
Interdependent Use Cases
유스 케이스와 관련된 두번째 큰 문제는, 다른 유스 케이스를 발생시키는 이벤트입니다.
이 문제를 해결하는 유일한 방법은 유스 케이를 더 작은 원자적 사용 사례로 나누는 것입니다. 그것들은 조립하기가 더 쉬울 것입니다.
일반적으로 이러한 스크립트의 문제는 프로그래밍에서 또 다른 큰 문제인 엔티티 구성(entities composition)의 결과입니다.
개체를 효율적으로 구성하는 방법에 대해 이미 많이 쓰여져 있고, 심지어 전체 수학 섹션도 있습니다. 멀리 가지 않을 거예요, 그건 별도의 게시물에 대한 주제입니다.
Conclusions
이 게시물에서는 프런트 엔드의 깨끗한 아키텍처에 대해 간략하게 설명하고 확장했습니다.
그것은 황금률이 아니라 다양한 프로젝트, 패러다임, 언어에 대한 경험을 종합한 것입니다. 코드를 분리하고 독립적인 계층, 모듈, 서비스를 만들 수 있는 편리한 체계라고 생각합니다. 개별적으로 배포 및 게시할 수 있을 뿐만 아니라 필요한 경우 프로젝트 간에 이전할 수도 있습니다.
아키텍처와 OOP는 직교하기 때문에 OOP에 대해서는 언급하지 않았습니다. 맞아요, 아키텍쳐는 엔티티 구성에 대해 이야기하지만, 구성 단위가 무엇이어야 하는지를 지시하지는 않습니다: 객체 또는 함수. 우리가 예제에서 보았던 것처럼, 여러분은 이것을 다른 패러다임으로 사용할 수 있습니다.
OOP에 대해서는 최근 OOP와 함께 클린 아키텍처를 사용하는 방법에 대한 글을 올렸습니다. 이 글에, 우리는 캔버스에 나무 그림 생성기를 작성합니.
이러한 접근 방식을 chip slicing, hexagonal architecture, CQS 및 기타 요소와 정확히 결합할 수 있는 방법을 알아보려면 DDD, Hexagonal, Onion, Clean, CQRS, ... How I put it all together 읽어보는 것이 좋습니다. 이 글은 매우 통찰력 있고 간결하며 핵심을 잘 다룹니다.
Sources
- Public Talk about Clean Architecture on Frontend
- Slides for the Talk
- The source code for the application we're going to design
- Sample of a working application
Design in Practice
- The Clean Architecture
- Model-View-Controller
- DDD, Hexagonal, Onion, Clean, CQRS, … How I put it all together
- Ports & Adapters Architecture
- More than Concentric Layers
- Generating Trees Using L-Systems, TypeScript, and OOP Series' Articles
System Design
Books about Design and Development
Concepts from TypeScript, C#, and Other Languages
- Interface
- Closure
- Set Theory
- Type Aliases
- Primitive Obsession
- Floating Point Math
- Branded Types и How to Use It
Patterns and Methodologies
- Adapter, pattern
- SOLID Principles
- Impureim Sandwich
- Design by Contract
- Covariance and contravariance
- Law of Demeter
- BEM Methodology
끝으로
출처는 다시 한번 https://bespoyasov.me/blog/clean-architecture-on-frontend/ 입니다.
번역을 허락해준 글쓴이에게 감사합니다.
부족한 실력이므로 지적해주시면 감사하겠습니다.



3일에 걸쳐서 읽어볼게요