
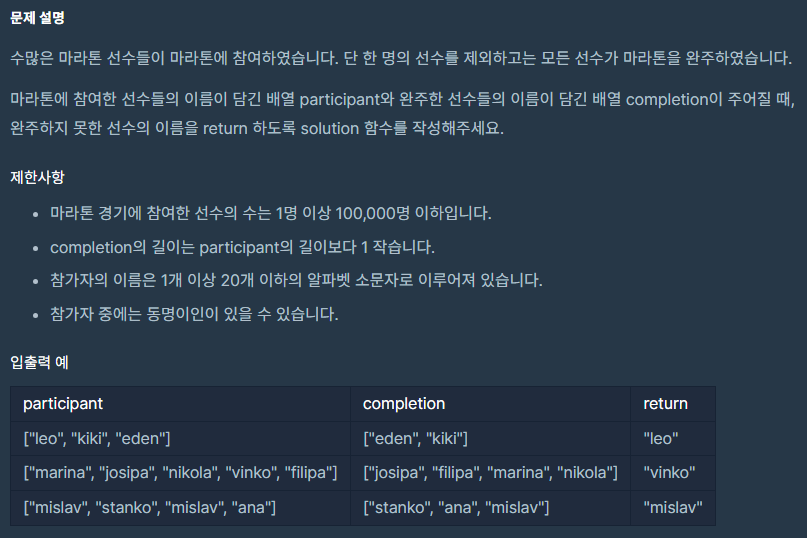
문제
| 문제 | 레벨 | 정답률 |
|---|---|---|
| 완주하지 못한 선수 | Lv.1 | 57% |
My Code
import java.util.*;
class Solution {
public String solution(String[] participant, String[] completion) {
HashMap<String, Integer> hashMap = new HashMap<>();
HashMap<String, Integer> hashMap2 = new HashMap<>();
for(int i = 0; i<completion.length; i++){
if(hashMap.containsKey(completion[i])){
int num = hashMap.get(completion[i]);
hashMap.put(completion[i],++num);
}else{
hashMap.put(completion[i], 1);
}
}
for(int i = 0; i<participant.length; i++){
if(hashMap2.containsKey(participant[i])){
int num = hashMap2.get(participant[i]);
hashMap2.put(participant[i],++num);
}else{
hashMap2.put(participant[i], 1);
}
}
for(String str : participant){
boolean b = (hashMap.get(str) == hashMap2.get(str));
if(!hashMap.containsKey(str) || b != true){
return str;
}
}
return "";
}
}** 참고로 정확성은 통과되었으나, 효율성 테스트를 통과하지 못한 코드입니다 ,,ㅎ
일단 결과는 정확히 나오는데 효율적이지 않은 이유를 찾아보니 해시맵을 두 번 사용해서 불필요한 복잡도를 만들어낸 게 원인이었다.
전체 로직은 다음과 같다.
-
해시맵 두 개를 만들어 participant와 completion를 각각 저장
이때 key로는 사람 이름을, value로는 동일이름의 개수를 저장 -
participant 배열을 돌면서 해당 문자열이 참가자 명단에 없거나, 해당 문자열을 두 개의 해시맵에서 찾아봤을 때 value가 동일하지 않으면 그 문자열 반환
개선 코드
import java.util.*;
class Solution {
public String solution(String[] participant, String[] completion) {
HashMap<String, Integer> hashMap = new HashMap<>();
// 참가자 배열의 각 원소를 해시맵에 추가
for (String p : participant) {
hashMap.put(p, hashMap.getOrDefault(p, 0) + 1);
}
// 완료 배열의 각 원소를 해시맵에서 제거
for (String c : completion) {
hashMap.put(c, hashMap.get(c) - 1);
}
// 해시맵에서 값이 1인 키를 찾기
for (String key : hashMap.keySet()) {
if (hashMap.get(key) > 0) {
return key;
}
}
return "";
}
}
두 개의 해시를 사용하는 대신, 하나의 해시를 사용하고 완주한 사람을 해시맵에서 제거하는 방식으로 풀어나갔다.
ㄴ 진짜 생각하지 못한 쉬운 방식..
그래서 마지막까지 값이 1인 사람을 return 하는 방식이다.
hash를 코드에 내가 필요에 의해 사용해본적이 없어서 그런지 아직 효율적인 코드를 짜는게 어려운 것 같다.
이것도 처음에 다른 자료구조 쓰려다가 해시 문제길래 해시 한 번 사용해봄 ㅎ
A형 따려면 알고리즘 공부도 열심히 합시다 ... ☆*: .。.

Developer's Logbook