chunk size
chunk size : 한번에 처리될 트랜잭션 단위
chunk 단위로 실패할 경우엔 해당 chunk 만큼 rollback되고,
이전 커밋된 트랜잭션 범위까지는 반영됨
JPA Page Size는 한번에 조회할 Item의 양.
chunk size는 page size와 같아야 함.
<예시>
1억만건의 파일을 db에 저장하는 배치 프로세스를 구현해야 함.
chunk size는 어떻게 하는게 좋을까?
방법 1. chunk size를 작게 하여 안전하게 커밋하면서 배치를 돌림.
-> BAD!
커밋은 비용(리소스, 시간) 큰 작업. 되도록 커밋 적게 하는것이 비용을 줄일 수 있음
방법 2. 커밋을 줄이려고 chunk size를 1억으로 한다.
-> BAD!
커밋은 메모리에 객체를 올려놓고 하는 것. out of memory 발생할 것.
시스템 구성과 배치 특성에 따라 알맞게 정의해야 함.
보통 금융권에서 2000-3000 정도로 사용?
스프링 배치 병렬 처리
배치를 병렬적으로 실행하려면 자동으로 배치 실행 x, 직접 정의해야 함.
1만 건의 데이터가 있을 때 5000건 씩 병렬적으로 배치를 실행한다고 해보자.
방법 1. 다중 스레드 스텝
스프링 배치에서 step은 단일 처리로 처리됨.
병렬 시행을 위해서는 다중 스레드 스텝을 사용해야 함.
다중 스레드 스텝 -> : job 내부의 step 내에서 chunk 단의로 다중 스레드 작업을 하는 방식
다중 스레드 스텝 -> step 내의 chunk들이 자체 스레드에서 실행됨.
TaskExecutor 사용.
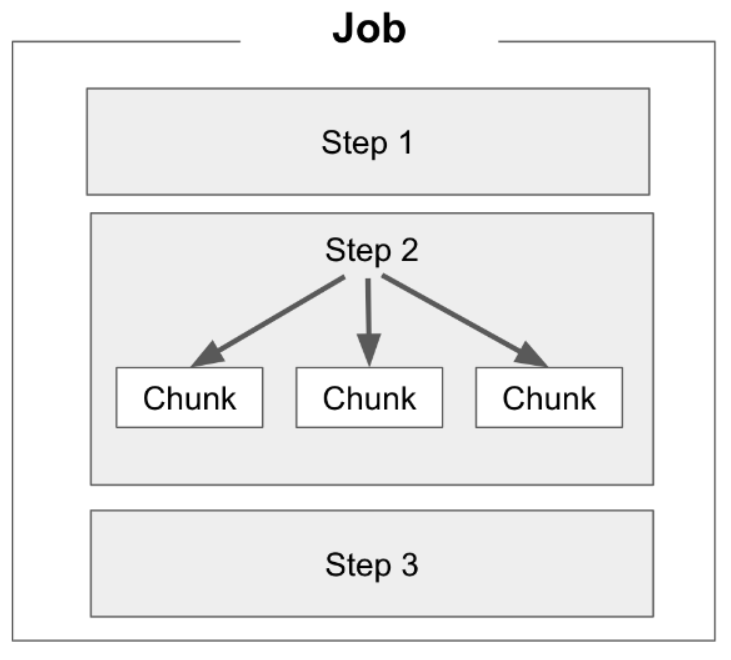
각 chunk는 독립적으로 처리 됨.
- 하나의 스텝을 여러개의 스레드로.
- 각 스레드는 동일한 스텝 실행, 작업 분할해 병렬 처리하기 떄문에 시간 단축
방법 2. 병렬 스텝
다중 스레드 스텝과 달리 스텝 자체를 병렬 처리. (내가 구현한 방식)
마찬가지로 TaskExecutor 사용.
- 여러 독립적 스텝 동시에 실행
- 각 스텝은 서로 다른 작업 수행
- 여러개의 스텝 동시에 실행
@Bean
public Job jpaPageFlowJob_batchBuild() {
Flow flow1 = new FlowBuilder<Flow>("flow1")
.start(jpaPageJob_1_batchStep1())
.build();
Flow flow2 = new FlowBuilder<Flow>("flow2")
.start(jpaPageJob_2_batchStep1())
.build();
Flow parallelStepFlow = new FlowBuilder<Flow>("parallelStepFlow")
.split(new SimpleAsyncTaskExecutor())
.add(flow1, flow2)
.build();
return jobBuilderFactory.get("jpaPageFlowJob")
.start(parallelStepFlow)
.build().build();
}
// 병렬로 (parallel) 실행될 배치 두 세트
// 10000건의 배치를 두 세트로 쪼개서 처리
// 스텝
@Bean
public Step jpaPageJob_1_batchStep1() {
return stepBuilderFactory.get("JpaPageFlowJob_1_Step")
.<Dept, Dept2>chunk(chunkSize)
.reader(jpaPageJob_1_dbItemReader())
.processor(jpaPageJob_1_processor())
.writer(jpaPageJob_1_dbItemWriter())
.build();
}<비교>
다중 스레드 스텝 방식 : 하나의 스텝에서 작업 병렬로 처리
병렬 스텝 방식 : 여러개의 독립적 스텝 동시에 실행
