Spring Batch는 대용량 데이터 처리 위한 프레임워크.
Scehduler와 함께 주기적은 작업도 실행할 수 있으므로 정산 업무에 적합하다고 판단했다.
배치 : 대량 데이터 일괄 처리
스케쥴러 : 특정 주기마다 작업 실행
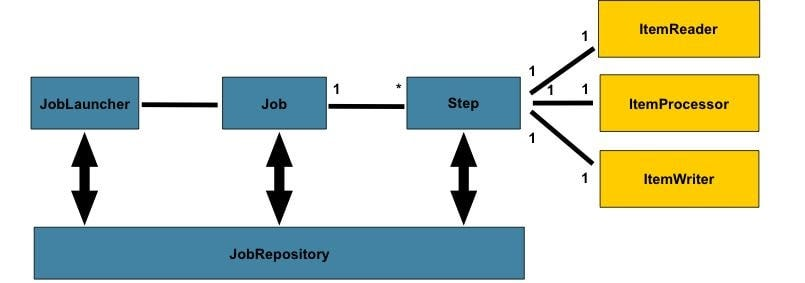
Spring Batch 구조
Job
전체 배치 과정 추상화한 개념.
한개 이상의 step 포함하고 스프링 배치에서 가장 상위 계층.
고유한 이름으로 JobInstance(Job의 실제 인스턴스) 구별.
Step
Job의 하위 단계로 실제 배치 처리 작업 이뤄지는 단위.
Step 내부에서 ItemReader, ItemProcessor, ItemWriter 사용하는 tasklet 갖는다.
JobRepository
배치작업 관련한 모든 정보 - Job 실행정보(JobExecution), Step 실행정보(StepExecution), Job 파라미터(JobParameters) 등 저장하고 관리.
JobLauncher
Job과 JobParamerters 받아 잡 실행하는 역할.
전반적 Job 생명 주기 관리하고 JobRepository 통해 실행상태 유지.
ItemReader
배치 작업에서 처리할 아이템 읽어오는 역할
데이터에 따라 다양한 구현체 제공.
mySettlement 프로젝트에서는 JPA를 사용하기 위해 RepositoryItemReader를 사용했다.
ItemProcessor
쓰기 이전 ItemReader로부터 읽은 아이템 처리(가공).
ItemWriter
ItemProcessor에서 처리된 데이터 최종적으로 기록.
리더와 마찬가지로 다양한 형태의 구현체를 사용할 수 있음.
원하는 형태에 맞게 커스텀 라이터를 작성해 사용할 수 있다.
public class SettlementListWriter implements ItemWriter<List<Settlement>> {
...스프링 배치는 배치 작업 상태를 관리하기 위해 메타 데이터 저장 테이블이 필요하다.
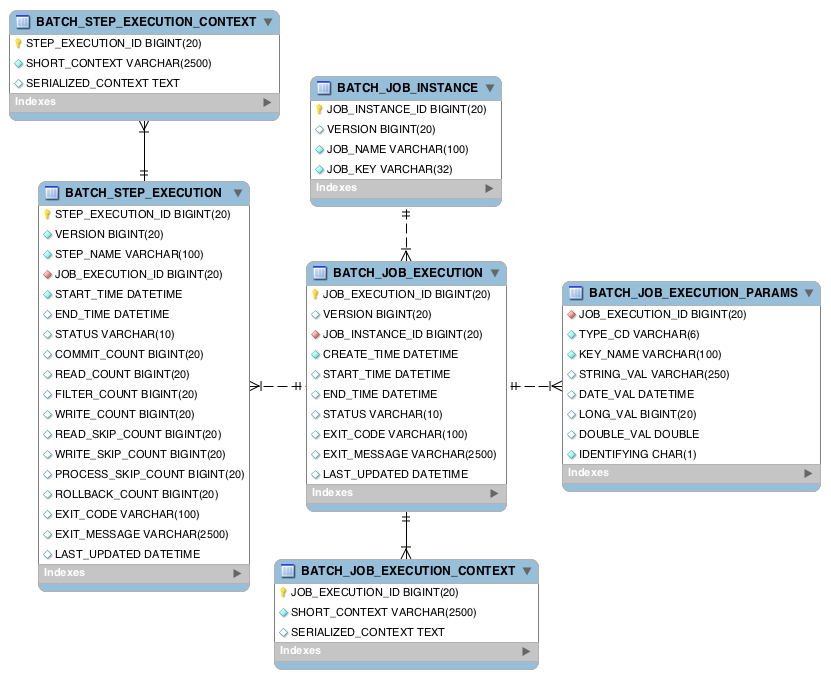
라이브러리에서 schema-mysql.sql 파일을 열어 테이블을 생성하자.
스프링 배치에서 Job은 하나 이상의 Step의 모음으로 구성되고, 각 스텝은 특정 비지니스 로직 처리 단위이다.
Step 구성하는 Tasklet과 Chunk 지향 처리
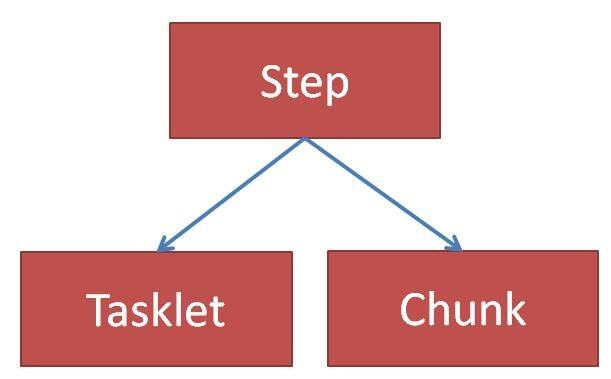
Job은 Step들을 순차적으로 수행하는데, Step은 주로 Tasklet 방식과 chunk 방식이 존재.
Tasklet 방식
Tasklet은 기본적으로 하나의 작업 수행하는 방식으로 단순한 수행에 적합.
@Configuration
public class TaskletStepConfiguration {
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Bean
public Step taskletStep() {
return stepBuilderFactory.get("taskletStep")
.tasklet((contribution, chunkContext) -> {
// 여기에 Tasklet 로직 작성
System.out.println("Tasklet step executed");
return RepeatStatus.FINISHED;
})
.build();
}
}Tasklet은 작업의 단순, 명확성이 장점이지만, 복잡하거나 대량 데이터 처리에는 Chunk 방식이 적합하다.
mySettlement 프로젝트에서도 Chunk 방식을 사용하였다.
Chunk 방식
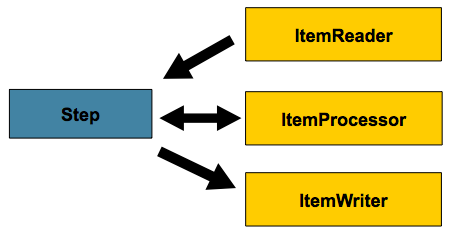
Chunk 방식을 대용량 데이터 효과적 처리 위해 사용.
큰 데이터를 일련의 작은 청크로 나누고, 각 청크를 개별적 트랜잭션 범위 내에서 처리.
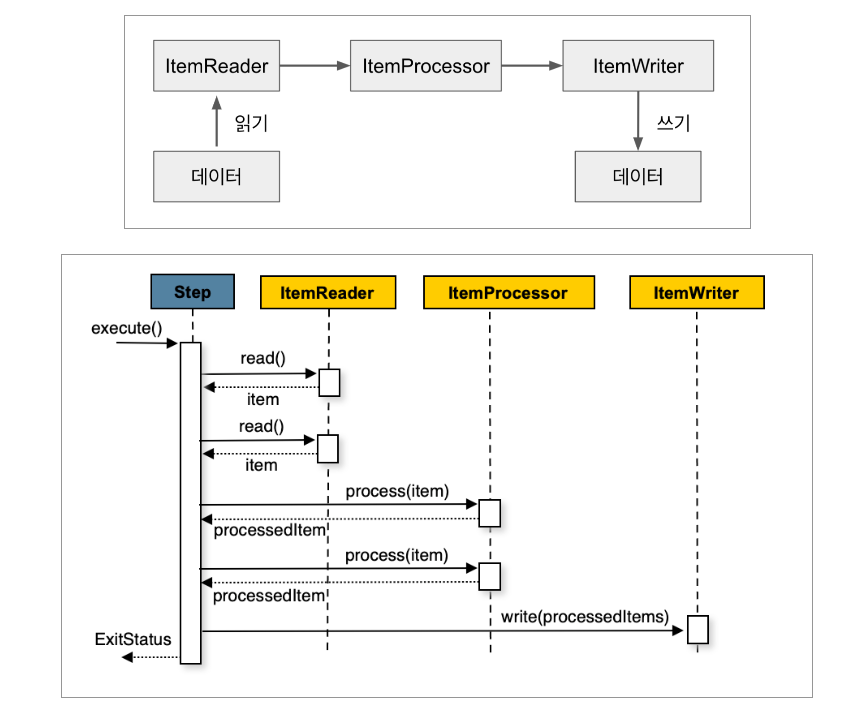
각 청크 처리는 리더, 프로세서, 라이터 3단계로 구성.
@Slf4j
@RequiredArgsConstructor
@Configuration
@EnableBatchProcessing
public class SettlementJobConfig {
private static final int chunkSize = 10;
private final SettlementRepository settlementRepository;
private final RevenueRepository revenueRepository;
private final ContractFeignClient contractFeignClient;
private final DistributorFeignClient distributorFeignClient;
private final OstFeignClient ostFeignClient;
private final ProducerFeignClient producerFeignClient;
// job
@Bean
public Job settlement_batchBuild(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
System.out.println("잡");
return new JobBuilder("settlement_batchBuild0320", jobRepository)
.start(settlement_batchStep(jobRepository, transactionManager))
.build();
}
// step
@Bean
@JobScope
public Step settlement_batchStep(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
System.out.println("스텝");
return new StepBuilder("settlement_batchStep0320", jobRepository)
// I, O
.<Revenue, List<Settlement>>chunk(chunkSize, transactionManager)
.reader(settlementReader())
.processor(getFeeProcessor())
.writer(settlementWriter())
.build();
}
// reader
// RepositoryItemReader, Writer
// https://velog.io/@alstn_dev/게시판-프로젝트-스프링-배치-적용1
@Bean
@StepScope
public RepositoryItemReader<Revenue> settlementReader() {
System.out.println("1. 리더 실행");
return new RepositoryItemReaderBuilder<Revenue>()
.name("settleReader")
.repository(revenueRepository)
// 리스트가 아닌 페이지 리턴해야 함
// repository의 메소드
.methodName("findByThisMonth")
// 이전에 설정한 chunk와 동일한 사이즈
.pageSize(chunkSize)
// 매개변수
.arguments(LocalDate.now())
.sorts(Collections.singletonMap("id", Sort.Direction.ASC))
.build();
}
// processor
@Bean
@StepScope
// input output
// Revenue 타입 리더에서 읽고 프로세서에서 프로세스 후 Settlement 타입으로 라이터에게 리턴
public ItemProcessor<Revenue, List<Settlement>> getFeeProcessor() {
System.out.println("2. 프로세서 실행");
return revenue -> {
RevenueDto dto = RevenueDto.builder()
.contractId(revenue.getContractId())
.fee(revenue.getFee())
.date(revenue.getDate())
.build();
System.out.println("리더에서 받은 revenue : ");
log.info("(processor!) revenue.getId() = " + revenue.getId());
// return dto;
// 계약서
// Contract contract = dto.getContract();
// log.info("contract.getId() = {}", contract.getId());
ContractFeignResponse contractFeignResponse = contractFeignClient.findByContractId(dto.getContractId());
// 수익 원금액
Double fee = dto.getFee();
log.info("fee = " + fee);
// 4개 settlement 객체 저장할 리스트
List<Settlement> settlementList = new ArrayList<>();
// 1. 유통사 정산
// Double distributorRate = contract.getDistributor().getPercent() * 0.01;
Long distributorId = contractFeignResponse.getDistributorId();
DistributorFeignResponse distributorFeignResponse = distributorFeignClient.findDistributorById(distributorId);
Double distributorRate = distributorFeignResponse.getPercent() * 0.01;
log.info("distributorRate = {}", distributorRate);
Double distributorFee = fee * distributorRate;
log.info("distributorFee = {}", distributorFee);
fee -= distributorFee;
log.info("fee2 = {}", fee);
Settlement distributorSettlement = Settlement.builder()
.contractId(contractFeignResponse.getContractId())
.type(DISTRIBUTOR)
.memberId(distributorId)
.settleDate(LocalDateTime.now())
.fee(distributorFee)
.revenue(revenue)
.build();
log.info("distributorSettlement.getFee() = {}", distributorSettlement.getFee());
log.info("distributorSettlement.getSettleDate() = {}", distributorSettlement.getSettleDate());
settlementList.add(distributorSettlement);
// 2. 가창자 정산
Double singerRate = contractFeignResponse.getSingerPercent() * 0.01;
Double singerFee = fee * singerRate;
fee -= singerFee;
log.info("contractFeignResponse.getOstId() = {}", contractFeignResponse.getOstId());
OstFeignResponse ostFeignResponse = ostFeignClient.findOstById(contractFeignResponse.getOstId());
log.info("ostFeignResponse = {}", ostFeignResponse);
Settlement singerSettlement = Settlement.builder()
.contractId(contractFeignResponse.getContractId())
.type(SINGER)
.memberId(ostFeignResponse.getSingerId())
.settleDate(LocalDateTime.now())
.fee(singerFee)
.revenue(revenue)
.build();
settlementList.add(singerSettlement);
// 제작사 정산
ProducerFeignResponse producerFeignResponse = producerFeignClient.findProducerById(ostFeignResponse.getProducerId());
Double producerRate = contractFeignResponse.getProducerPercent() * 0.01;
log.info("producerRate = {}", producerRate);
Double producerFee = fee * producerRate;
log.info("producerFee = {}", producerFee);
fee -= producerFee;
Settlement producerSettlement = Settlement.builder()
.contractId(contractFeignResponse.getContractId())
.type(PRODUCER)
.memberId(producerFeignResponse.getProducerId())
.settleDate(LocalDateTime.now())
.fee(producerFee)
.revenue(revenue)
.build();
settlementList.add(producerSettlement);
// 본사 정산
Settlement companySettlement = Settlement.builder()
.contractId(contractFeignResponse.getContractId())
.type(COMPANY)
.memberId(0L)
.settleDate(LocalDateTime.now())
.fee(fee)
.revenue(revenue)
.build();
settlementList.add(companySettlement);
// 정산이 완료된 `Settlement` 객체 리스트 반환
return settlementList;
};
}
// RepositoryItemWriter는 하나의 엔티티 저장
// but Revenue 하나 당 Settlement 객체 4개 담긴 리스트 저장해야 하므로 커스텀 ItemWriter 사용
@Bean
@StepScope
public SettlementListWriter settlementWriter() {
System.out.println("3. 라이터");
return new SettlementListWriter(settlementRepository);
}
}Paging Size와 Chunk Size
ItemReader와 ItemWriter에서 페이징 처리는 대용량 데이터 처리에 효과적.
Chunk는 스프링 배치에서 트랜잭션 범위 설정하는 방법.
Chunk Size는 한번에 처리(커밋)될 데이터의 수.
위의 경우에서는 각 트랜잭션이 10개의 데이터를 처리.
Paging Size가 5이고 Chunk Size가 10이면, 2번의 리드가 이뤄지고 한번의 트랜잭션이 수행됨.
-> 1번 트랜잭션 위해 2번의 퀴리가 수행되므로 효율 Bad!
-> 사이즈 같게 설정하자.
@Bean
@StepScope
public RepositoryItemReader<Revenue> settlementReader() {
return new RepositoryItemReaderBuilder<Revenue>()
.name("settleReader")
.repository(revenueRepository)
.methodName("findByThisMonth")
// 이전에 설정한 chunkSize와 동일한 사이즈
.pageSize(chunkSize)
...<참고>
