
SQL을 자주 안쓰다보니 자꾸 잊어버리게 되는것 같습니다. 공부했던 것을 토대로 다시 정리해서 공부해보려 합니다.
본 내용은 책 <이것이 MySQL이다>를 토대로 진행하였습니다.
🌜 SELECT 문
SELECT...FROM
- 어떤 테이블로 부터(FROM) 선택(SELECT)하는 구문입니다.
- 원하는 데이터를 가져와주는 가장 기본적인 구문.
SELECT {컬럼} FROM {테이블} WHERE {조건}- 선택된 DB가
employees라면 다음 두 쿼리는 동일합니다.
SELECT * FROM employees; -- 테이블의 모든 행 선택 및 진입
SELECT * FROM employees.employees; -- DB안의 Table 선택 및 진입employees테이블 안의 특정 컬럼을SELECT합니다.
SELECT last_name, first_name FROM employees;SELECT...FROM...WHERE
특정 조건의 데이터만 조회합니다.
WHERE
조건에 부합하는 대상을 SELECT 합니다.
SELECT {컬럼} FROM {테이블} WHERE {조건식};
-- EXAMPLE
SELECT * FROM usertbl WHERE name='김경호';관계 연산자
OR연산자 : '~또는'AND연산자 : '~면서'- 조건 연산자 (
=,<,>,<=,>=,!=등) - 관계 연산자 (
NOT,AND,OR등)
SELECT userId, name FROM usertbl WHERE birthYear >= 1970 AND height > 180;BETWEEN...AND
데이터가 숫자로 구성되어 있으며 연속적인 값을 조회할때 사용합니다.
SELECT * FROM usertbl WHERE height BETWEEN 180 AND 190;IN(...)
여러 값의 조건 안에서 조회할 때 사용합니다
SELECT * FROM usertbl WHERE addr IN ('서울', '경기', '경남');LIKE
- 문자열의 내용 중 부분별 내용을 검색합니다.
%는 무엇이든 허용합니다_한 글자와 매치
SELECT * FROM usertbl WHERE name LIKE '%경호'; -- 김경호, 남궁경호 등
SELECT * FROM usertbl WHERE name LIKE '_경호'; -- '○경호' 만 조회
SELECT * FROM usertbl WHERE name LIKE '%경%'; -- '경'자가 들어간 모든 이름서브쿼리
- SubQuery : 하위 쿼리
- 쿼리문 안에 또 쿼리문이 있는 개념입니다.
- 서브쿼리의 결과가 둘 이상이 되면 에러가 발생하니 주의해야 합니다.
SELECT height FROM usertbl WHERE name = '김경호'; -- 이름이 '김경호'인 사람의 height
SELECT * FROM usertbl WHERE height >= 177; -- height가 177 이상
-- 위의 두 조건을 서브쿼리로 합친 결과
SELECT *
FROM usertbl
WHERE height >= (SELECT height FROM usertbl WHERE name ='김경호');ANY/SOME
- 서브쿼리의 여러 결과 중 한가지만 만족해도 조회되어집니다.
SOME은ANY와 동일한 의미로 사용합니다.= ANY(서브쿼리)는IN(서브쿼리)와 동일한 의미입니다.
ALL
- 서브쿼리의 결과 중 모든 결과를 모두 만족해야 합니다.
-- 서울인 사람들이 다수임으로 ANY를 사용해야 합니다.
SELECT *
FROM usertbl
WHERE height >= ANY(SELECT height FROM usertbl WHERE addr='서울');원하는 순서대로 정렬
ORDER BY
- 원하는 순서대로 정렬하여 출력합니다.
- default 값은 오름차순(
ASC)입니다. - 내림차순으로 정렬하기 위해서는
DESC를 사용합니다.
-- height를 기준으로 오름차순 정렬.
SELECT * FROM usertbl ORDER BY height;
-- 컬럼의 번호(순서)를 적어서 정렬할 수 있다.
SELECT * FROM usertbl ORDER BY 7;
-- ORDER BY 구문을 혼합하여 사용.
SELECT name, height FROM usertbl ORDER BY height DESC, name ASC;DISTINCT
- 중복된 것을 골라서 세기 어려울 때 사용하는 구문입니다.
- 중복된 것은 1개만 보여주면서 출력하며 테이블의 크기가 클수록 효율적입니다.
SELECT DISTINCT addr FROM usertbl;LIMIT
- 전체에서 상위 n개만 조회하는 구문입니다.
SELECT * FROM usertbl LIMIT 3;
-- 3번부터 5개의 데이터를 출력 (4,5,6,7,8)
SELECT * FROM usertbl LIMIT 3, 5;GROUP BY 및 HAVING 그리고 집계 함수
GROUP BY
- 그룹으로 묶어주는 역할을 합니다.
- 집계 함수와 함께 사용됩니다.
- 효율적으로 데이터를 그룹화할 수 있습니다.
-- 각 사용자별로 구매한 개수를 합쳐서 출력
SELECT userId, SUM(amount) FROM buytbl GROUP BY userId;집계 함수
GROUP BY와 함께 자주 사용되는 집계 함수
| 함수명 | 설명 |
|---|---|
| SUM() | 합계 |
| AVG() | 평균 |
| MIN() | 최소값 |
| MAX() | 최대값 |
| COUNT() | 개수를 카운트 |
| COUNT(DISTINCT) | 개수 카운트 (중복은 1개만 인정) |
| STDEV() | 표준편차 |
| VAR_SAMP() | 분산 |
-- 전체 구매자가 구매한 물품의 개수 평균
SELECT AVG(amount) AS "구매한 수량 평균" FROM buytbl;HAVING
WHERE과 비슷한 개념이지만 집계 함수에 대해서 필터링을 하는 개념입니다.GROUP BY에서는WHERE을 쓸 수 없으며 대신HAVING을 사용해야 합니다.HAVING절은 반드시GROUP BY절 다음에 나와야 합니다.
SELECT userId, SUM(amount*price) AS "총 구매액"
FROM buytbl
GROUP BY userId
HAVING SUM(price*amount) >= 1000;ROLLUP
- 총합 또는 중간 합계(소계)가 필요할때 사용합니다.
GROUP BY절과 함께WITH ROLLUP문을 사용합니다.
-- 분류(groupName) 별로 합계 및 그 총합 구하기
SELECT num, groupName, SUM(price*amount) AS '비용'
FROM buytbl
GROUP BY groupName, num WITH ROLLUP;SQL의 분류
- DML(Data Manipuation Language : 데이터 조작 언어)
- 데이터를 조작하는데 사용되는 언어.
SELECT,INSERT,UPDATE,DELETE구문이 해당.- 트랜잭션이 발생하는 SQL도 포함.
- DDL(Data Definition Language: 데이터 정의 언어)
CREATE,DROP,ALTER자주 사용- DDL은 트랜젝션 발생X (취소 불가)
- DCL(Data Control Language: 데이터 제어 언어)
- 사용자에게 권한을 부여하는 언어
GRANT(권한 부여),REVOKE(권한 회수),DENY
🌜 데이터의 변경
INSERT
INSERT [INTO] 테이블[(colum1, column2, ...)] VALUES (value1, value2 ... )테이블 이름 다음에 나오는 열은 생략이 가능하지만, 생략할 경우에 VALUES 다음에 나오는 값들의 순서 및 개수가 테이블이 정의된 열 순서 및 개수와 동일해야 합니다.
-- 가장 일반적인 형식
INSERT INTO testtbl1 VALUES (1, '홍길동', 25);
INSERT INTO testtbl1 (id, username) values (2, '설현');
INSERT testtbl1(username, age, id) VALUES ('하늬', 26, 3);INSERT INTO ... SELECT
- 대량의 샘플 데이터를 생성할 때 사용합니다.
- 다른 테이블의 데이터를 가져와 대량으로 입력할 수 있는 방법입니다.
SELECT문의 열의 개수 =INSERT할 테이블의 열의 개수- 테이블 정의까지 생략하려면
CREATE TABLE ... SELECT구문을 사용해야 합니다.
INSERT INTO tablename (column1, column2, ...)
SELECT ... ;-- EXAMPLE
INSERT INTO testtbl4
SELECT emp_no, first_name, last_name
FROM employees.employees;UPDATE
데이터를 수정하는 구문입니다.
UPDATE {테이블이름}
SET {column1=value1, ...}
WHERE {조건};WHERE 절은 생략 가능하나 생략하면 테이블의 전체 행이 변경되므로 반드시 주의해야 합니다.
UPDATE testtbl4 SET lname='없음' WHERE id = 10005;
UPDATE buytbl SET price=price*1.5 WHERE prodName='모니터';DELETE FROM
- 행 단위로 데이터를 삭제하는 구문입니다.
WHERE절이 생략되면 전체 데이터가 삭제되니 주의해야 합니다.
DELETE FROM {table} WHERE {condition};
DELETE FROM testtbl4 WHERE fname='Aamer';🌜 WITH절과 CTE
WITH 절과 CTE 개요
WITH절은CTE(Common Table Expression: 공통 테이블 표현)를 표현하기 위한 구문입니다.CTE는 기존의 뷰, 파생 테이블, 임시 테이블 등을 대신할 수 있으며 간결한 식으로 보여집니다.- CTE는
비재귀적 CTE,재귀적 CTE가 있지만 주로 비재귀적 CTE가 사용됩니다.
비재귀적 CTE
단순한 형태, 복잡한 쿼리문장을 단순화하는데 적합합니다.
WITH CTE_테이블이름(열 이름)
AS
(
<쿼리문>
)
SELECT 열 이름 FROM CTE_테이블이름;- 뷰는 계속 존재해서 다른 구문에서도 사용 가능하지만, CTE와 파생 테이블은 구문이 끝나면 소멸되는 차이가 있습니다.
- 중복 CTE이 허용됩니다.
🌜 MySQL의 데이터 형식
MySQL에서 지원하는 데이터 형식의 종류
숫자 데이터 형식
가장 자주 사용되는 숫자 데이터 형식은 아래와 같습니다.
| 데이터형식 | 바이트 | 설명 |
|---|---|---|
| SMALLINT | 2 byte | 정수 |
| INT | 4 byte | 정수 |
| BIGINT | 8 byte | 정수 |
| FLOAT | 4 byte | 소수점 아래 7자리까지 표현 |
| DOUBLE | 8 byte | 소수점 아래 15자리까지 표현 |
| DECIMAL(m,[d]) | 5~17 byte | 전체 자리수(m), 소수점이하 자릿수(d)를 가진 숫자형 |
- decimal(5,2)는 전체 자릿수를 5자리로 하되 그중 소수점 이하를 2자리로 설정
문자 데이터 형식
가장 자주 사용되는 문자 데이터 형식은 아래와 같습니다.
| 데이터형식 | 바이트 수 | 설명 |
|---|---|---|
| CHAR(n) | 1~255 | 고정길이 문자형. 해당 n을 1~255까지 지정. char(1)이 기본값 |
| VARCHAR(n) | 1~65535 | 가변길이 CHAR |
| LONGTEXT | 최대 4GB | 텍스트 데이터값 |
| LONBBLOB | 최대 4GB | BLOB(Binary Large OBject) 데이터 값 |
날짜/시간 데이터 형식
가장 자주 사용되는 날짜/시간 데이터 형식은 아래와 같습니다.
| 데이터형식 | 바이트 | 설명 |
|---|---|---|
| DATE | 3 byte | YYYY-MM-DD의 형식으로 사용 |
| DATETIME | 8 byte | YYY-MM-DD HH:MM:SS의 형식으로 사용 |
기타 데이터 형식
| 데이터형식 | 바이트 | 설명 |
|---|---|---|
| GEOMETRY | N/A | 공간 데이터 형식 (지도 등) |
| JSON | 8 byte | JSON 문서를 저장 |
변수의 사용
SQL에서도 변수를 선언하고 사용할 수 있습니다.
SET @변수이름 = 변수의 값; -- 변수의 선언 및 값 대입
SELECT @변수이름; -- 변수의 값 출력- 첫문장이 숫자가 될 수 없습니다.
- 워크벤치가 꺼질때까지 메모리에 할당되어 있기 때문에 워크벤치를 재시작할 때까지는 계속 유지됩니다.
-- example
SET @myVar1 = 5;
SET @myVar2 = 3;
SET @myVar3 = 4.25;
SET @myVar4 = '가수이름->';
SELECT @myVar1; -- 5
SELECT @myVar2 + @myVar3; -- 7.2500000000000000
SELECT @myVar4, Name FROM usertbl WHERE height > 180; -- 가수이름-> OOO
-- myquery 라는 쿼리변수를 만들고 명령어를 삽입, ?안에 변수 사용.
PREPARE myquery FROM 'select name, height from usertbl order by height limit ?';
-- myquery를 변수myvar1를 사용하여 실행
EXECUTE myquery USING @myvar1;데이터 형식과 형 변환
데이터 형식 변환 함수
CAST(),CONVERT()함수를 가장 일반적으로 사용합니다.- 데이터 형식 중에서 가능한 것은
BINARY,CHAR,DATE,DATETIME,DECIMAL,JSON,SIGNED INTEGER,TIME,UNSIGNED INTEGER가 있습니다.
CAST ( expression AS 데이터형식 [ ( 길이 ) ] )
CONVERT ( expression, 데이터형식 [ ( 길이 ) ] )-- 평균 구매 개수를 구하는 쿼리문
SELECT CAST(AVG(amount) AS SIGNED INTEGER) AS "평균 구매 개수" FROM buytbl;
SELECT CONVERT(AVG(amount), SIGNED INTEGER) AS "평균 구매 개수" FROM buytbl;
SELECT AVG(amount) AS '평균 구매 개수' FROM buytbl;SELECT CAST('2021/12/12' AS DATE);
SELECT CAST('2021%12%12' AS DATE);
SELECT
num,
CONCAT(
CAST(price AS CHAR(10)),
'X',
CAST(amount AS CHAR(4)),
'='
) AS '단가X수량',
price*amount AS '구매액'
FROM buytbl;묵시적 형변환
CAST()나 CONVERT() 함수를 사용하지 않고 형이 변환되는 것을 말합니다.
-- example
SELECT '100' + '200'; -- 300 출력 (정수로 변환되어 연산)
SELECT CONCAT('100', '200'); -- 100200 출력 (문자로 처리)
SELECT CONCAT('100', 200); -- 100200 출력 (정수가 문자로 변환되어 문자로 처리)
SELECT 1 > '2mega'; -- 문자는 0으로 취급하기 때문에 FALSE
SELECT 0 = 'mega0'; -- 문자는 0으로 취급하기 때문에 TRUEMySQL 내장 함수
흐름 함수, 문자열 함수, 수학 함수, 날짜/시간 함수, 전체 텍스트 검색 함수, 형 변환 함수, XML 함수, 비트 함수, 보안/압축 함수, 정보 함수, 공간 분석 함수, 기타 함수 등이 있습니다.
제어 흐름 함수
-
프로그램의 흐름을 제어하는 함수입니다.
-
IF (수식, 참, 거짓): 수식이 참인지 거짓인지 결과에 따라서 2중 분기하여 반환합니다.
SELECT IF (100>200, '참이다', '거짓이다'); -- '거짓이다' 출력IFNULL(수식1, 수식2)- 수식1이
!= NULL이면 수식1을 반환,== NULL이면 수식2를 반환합니다.
- 수식1이
SELECT IFNULL(NULL, '널이군요'), IFNULL(100, '널이군요');NULLIF(수식1, 수식2): 수식1과 수식2가 같으면 null을 반환, 다르면 수식1을 반환합니다.
SELECT NULLIF(100,100), IFNULL(200,100);CASE ~ WHEN ~ ELSE ~ END:CASE는 내장 함수는 아니며 연산자로 분류됩니다.
SELECT CASE 10
WHEN 1 THEN '1입니다'
WHEN 5 THEN '5입니다'
WHEN 10 THEN '10입니다'
ELSE '알 수 없습니다'
END AS 'CASE 연습';
-- 해당 케이스는 10이므로 '10입니다' 반환문자열 함수
문자열을 조작하는 함수이며 활용도가 높습니다.
ASCII(아스키 코드): 해당 문자의 아스키코드 값을 반환합니다.CHAR(숫자): 아스키 코드 값에 해당하는 문자로 반환합니다.
SELECT ASCII('A'), CHAR(65);BIT_LENGTH(문자열): 할당된 bit 크기 또는 문자 크기를 반환합니다.CHAR_LENGTH(문자열): 문자의 개수를 반환합니다.LENGTH(문자열): 할당된 byte 수를 반환합니다.
SELECT BIT_LENGTH('abc'), CHAR_LENGTH('abc'), LENGTH('abc'); -- 24, 3, 3 반환
SELECT BIT_LENGTH('가나다'), CHAR_LENGTH('가나다'), LENGTH('가나다'); -- 72 , 3 , 9 반환CONCAT(str1, str2, ...): 문자열을 이어줍니다.CONCAT_WS(구분자, str1, str2): 구분자와 함께 문자열을 이어줍니다.
SELECT CONCAT_WS('/', '2015', '01', '01');
-- 2015/01/01 반환FIELD(찾을문자열, 문자열1, 문자열2, ...): 찾을 문자열의 위치를 찾아 반환합니다, 없으면 0을 반환합니다.FIND_IN_SET(찾을문자열, 문자열리스트): 찾을 문자열을 문자열 리스트에서 찾아 위치 반환합니다. (문자열 리스트는 콤마로 구분되어있어야 하며 공백이 없어야 합니다)INSTR(문자열, 찾을문자열): 기준 문자열에서 부분 문자열을 찾아 그 시작 위치를 반환합니다.LOCATE(찾을문자열, 문자열):INSTR과 동일하지만 파라미터의 순서만 반대입니다.
SELECT
FIELD('둘', '하나', '둘', '셋'), -- 2 반환
FIND_IN_SET('둘', '하나,둘,셋'), -- 2 반환
INSTR('하나둘셋', '둘'), -- 3 반환
LOCATE('둘', '하나둘셋'); -- 3 반환FORMAT(숫자, 소수점 자릿수): 숫자를 소수점 아래 자릿수까지 표현합니다.
SELECT FORMAT(123456.123456, 4); -- 123,456.1235 반환 (천단위마다 콤마 표시)INSERT(기준 문자열, 위치, 길이, 삽입할 문자열): 기준 문자열의 위치부터 길이만큼 지우고, 삽입할 문자열을 끼워넣는다.
SELECT INSERT('abcdefghi', 3, 4, '@@@@'); -- ab@@@@ghi 3번째부터 4개 삭제 (cdef)
INSERT('abcdefghi', 3, 2, '@@@@'); -- ab@@@@efghi 3번째부터 2개 삭제 (cd)LEFT(문자열, 길이): 왼쪽에서 시작하여 길이만큼 반환합니다.RIGHT(문자열, 길이): 오른쪽에서 시작하여 길이만큼 반환합니다.
SELECT
LEFT('abcdefghi', 3), -- 'abc' 반환
RIGHT('abcdefghi', 3); -- 'ghi' 반환UPPER(문자열): 소문자를 대문자로 변경합니다.LOWER(문자열): 대문자를 소문자로 변경합니다.
LPAD(문자열, 길이, 채울 문자열),RPAD(문자열, 길이, 채울 문자열): 문자열을 길이만큼 늘린 후에 채웁니다.
LTRIM(문자열),RTRIM(문자열): 왼쪽/오른쪽의 공백을 제거합니다. 중간 공백은 제거되지 않습니다.
TRIM(문자열): 문자열의 앞뒤 공백을 모두 제거합니다.TRIM(방향 '자를문자열' FROM '문자열')- '방향'은
LEADING(앞),BOTH(양쪽),TRAILING(뒤)으로 표시.
- '방향'은
SELECT
TRIM(' 앞뒤공백이있어요 '), -- '이것이' 반환
TRIM(BOTH 'ㅋ' FROM 'ㅋㅋㅋ꿀잼ㅋㅋㅋ'); -- '꿀잼' 반환REPEAT(문자열, 횟수): 문자열을 횟수만큼 반복합니다.
REPLACE(문자열, 원래문자열, 바꿀문자열): 문자열 안에서원래문자열을 찾아서바꿀문자열로 바꿔줍니다.
SELECT REPLACE ('여기는 장마입니다', '장마', '가뭄'); -- '여기는 가뭄입니다' 반환REVERSE(문자열): 문자열의 순서를 거꾸로 바꿉니다.
SPACE(길이): 길이 만큼 공백을 반환합니다.
SELECT CONCAT('여기부터', SPACE(10), '여기까지공백'); -- '여기부터 여기까지공백' 반환**SUBSTRING(문자열, 시작위치, 길이)****SUBSTRING(문자열 FROM 시작위치 FOR 길이)**: 시작위치부터 길이만큼 문자를 반환합니다. 길이가 생략되면 문자열의 끝까지 반환합니다.
SELECT SUBSTRING('abcdef', 3, 2); -- 'de' 반환
SELECT SUBSTRING('대한민국만세', -3, 2); -- '국만' 반환SUBSTRING_INDEX(문자열, 구분자, 횟수)- 문자열에서 구분자가 왼쪽부터 횟수번째까지 나오면 그 이후의 오른쪽은 버립니다.
- 횟수가 음수면 오른쪽부터 세고 왼쪽을 버립니다.
SELECT
SUBSTRING_INDEX('cafe.naver.com', '.', 2), -- 'cafe.naver' 반환
SUBSTRING_INDEX('cafe.naver.com', '.', -2); -- 'naver.com' 반환수학 함수
ABS(숫자): 숫자의 절대값을 반환합니다.CEILING,FLOOR,ROUND: 올림, 내림, 반올림 반환을 반환합니다.
MOD: n % n 와 같은 역할을 합니다.
SELECT MOD(157, 10), 157 % 10, 157 MOD 10; -- 모두 '7' 반환POW(숫자1, 숫자2): 제곱값을 반환합니다.SQRT(숫자): 제곱근을 반환합니다.
SELECT
POW(2,3), -- 2의 3승 '8' 반환
SQRT(9); -- '3' 반환RAND( )- 0 이상 1 미만의 랜덤 실수를 반환합니다.
m <= 임의의 정수 < n를 구하기 위해서FLOOR(m + (RAND() * (n-m))처럼 사용할 수 있습니다.
-- 주사위 만들기
SELECT FLOOR(1 + ( RAND() * 6 ) );SIGN(숫자)- 숫자가 양수, 0, 음수인지 판별하는 함수입니다.
- 양수라면
0, 음수라면-1, 0 이라면0을 반환합니다.
TRUNCATE(숫자, 정수): 소수점 n자리까지만 반환합니다.
SELECT
TRUNCATE(12345.12345, 2), -- 12345.12
TRUNCATE(12345.12345, -2); -- 12300날짜 및 시간 함수
ADDDATE(날짜, 차이),SUBDATE(날짜, 차이): 날짜를 기준으로 차이를 더하거나 뺀 날짜를 구합니다.
SELECT
ADDDATE('2025-01-01', INTERVAL 31 DAY),
ADDDATE('2025-01-01', INTERVAL 1 MONTH); -- '2025-02-01'
SELECT
SUBDATE('2025-01-01', INTERVAL 31 DAY),
SUBDATE('2025-01-01', INTERVAL 1 MONTH); -- '2024-12-01'ADDTIME(날짜/시간, 시간),SUBTIME(날짜/시간, 시간): 날짜/시간을 기준으로 시간을 더하거나 뺀 결과를 구합니다.
SELECT
ADDTIME('2025-01-01 23:59:59', '1:1:1'), -- 2025-01-02 01:01:00
ADDTIME('15:00:00', '2:10:10'); -- 17:10:10
SELECT
SUBTIME('2025-01-01 23:59:59', '1:1:1'), -- 2025-01-01 22:58:58
SUBTIME('15:00:00', '2:10:10'); -- 12:49:50CURDATE(): Current Date ('yyyy-mm-dd' 형식)CURTIME(): Current Time ('hh:mm:ss' 형식)NOW(),SYSDATE(): 현재 날짜 및 시간 ('yyyy-mm-dd hh:mm:ss' 형식)YEAR(날짜),MONTH(날짜),DAYOFMONTH(날짜)HOUR(시간),MINUTE(시간),SECOND(시간),MICROSECOND(시간)
SELECT YEAR(CURDATE()), MONTH(CURDATE()), DAYOFMONTH(CURDATE());
SELECT HOUR(CURTIME()), MINUTE(CURRENT_TIME()), SECOND(CURRENT_TIME), MICROSECOND(CURRENT_TIME);
SELECT DATE(NOW()), TIME(NOW());DATEDIFF(날짜1, 날짜2): 날짜1 - 날짜2의 일수TIMEDIFF(날짜 또는 시간1, 날짜 또는 시간2): 시간1 - 시간1 ('hh:mm:ss' 형식)
SELECT
DATEDIFF('2025-01-01', NOW()), -- 928
TIMEDIFF('23:23:59', '12:11:10'); -- 11:12:49DAYOFWEEK(날짜): 해당 날짜가 주에서 몇일인지 반환합니다. (일요일이 1)MONTHNAME(날짜): 이번달은 무슨 달인지 반환합니다.DAYOFYEAR(날짜): 일년 중 몇번째 날짜인지 반환합니다.
SELECT
DAYOFWEEK(CURDATE()), -- 7
MONTHNAME(CURDATE()), -- June
DAYOFYEAR(CURDATE()); -- 169LAST_DAY(날짜): 주어진 날짜의 마지막 날짜를 구합니다.
SELECT LAST_DAY('2025-02-01');MAKEDATE(연도, 정수): 연도에서 정수만큼 지난 날짜를 구합니다.MAKETIME(시, 분, 초): 시, 분, 초를 이용하여 'hh:mm:ss' 형식으로 반환합니다.
SELECT MAKEDATE(2025, 32);
SELECT MAKETIME(12, 11, 10);PERIOD_ADD(연월, 개월수): 해당 연월에서 개월수만큼의 개월이 지난 연월을 구합니다.PERIOD_DIFF(연월1, 연월2): 연월1 - 연월2의 개월수를 구합니다.
SELECT
PERIOD_ADD(202501, 11), -- 202512
PERIOD_DIFF(202501, 202312); -- 13QUARTER(날짜): 날짜가 네분기 중에서 몇 분기인지를 구합니다.
SELECT QUARTER('2025-07-07'); -- '3' 반환 (3분기)TIME_TO_SEC(시간): 시간을 초 단위로 구하여 반환합니다.
🌜 조인(JOIN)
두 개 이상의 테이블을 서로 묶어서 하나의 결과 집합으로 만들어 내는 것으로, INNER JOIN, OUTER JOIN, CROSS JOIN, SELF JOIN이 있습니다.
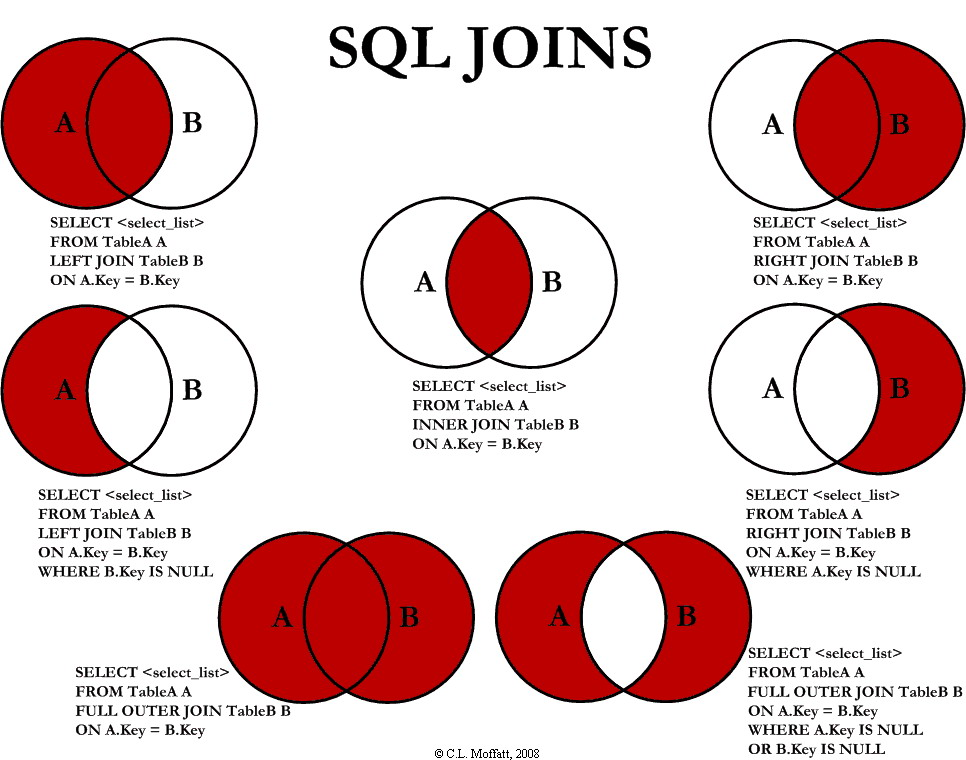
INNER JOIN(내부 조인)
- 가장 많이 사용되는 조인의 형태로,
JOIN만 사용하면 디폴트 값으로INNER JOIN이 사용됩니다. - 테이블의 공통된 행에 있는 데이터만 출력합니다.
1) EQUI JOIN (등가 조인) : 조인 조건에=연산자를 이용
2) NON EQUI JOIN (비등가 조인) : 조인 조건에=이외의 연산자 사용
3) NATURAL JOIN (자연 조인) : 공통된 행이 1개이고, 이름이 동일한 경우ON조건 생략 가능
SELECT {열 목록}
FROM {첫번째 테이블}
INNER JOIN {두번째 테이블}
ON {조인될 조건}
WHERE {검색조건};-- example
SELECT *
FROM buytbl b
JOIN usertbl u
ON b.userId = u.userId
WHERE b.userId = 'JYP';OUTER JOIN(외부 조인)
테이블에 공통된 행 뿐만 아니라, 공통되지 않은 데이터도 포함하여 출력합니다.
SELECT 열목록
FROM 테이블1 -- LEFT
(LEFT || RIGHT || FULL) OUTER JOIN 테이블2 -- RIGHT
ON 조인될조건
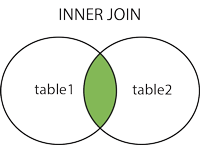
WHERE 검색조건;LEFT OUTER JOIN
- 왼쪽 테이블의 것을 모두 출력시킵니다.
- 줄여서
LEFT JOIN으로 사용할 수 있습니다.
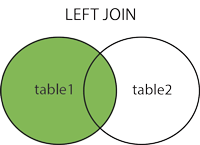
RIGHT OUTER JOIN
- 오른쪽 테이블의 것을 모두 출력시킵니다.
- 줄여서
RIGHT JOIN으로 사용할 수 있습니다.
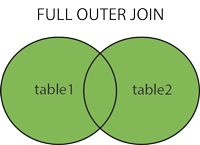
FULL OUTER JOIN
- 왼쪽 또는 오른쪽 테이블에 일치하는 항목이 있는 경우 모든 데이터를 출력합니다.
- 줄여서
FULL JOIN으로 사용할 수 있습니다.
CROSS JOIN(상호 조인)
- 한쪽 테이블의 모든 행들과 다른 쪽 테이블의 모든 행을 출력합니다.
- 조인 조건이 없기 때문에,
ON구문을 사용할 수 없습니다. - 양쪽 테이블에 모든 행이 곱해져서 출력되는 효과입니다.
CROSS JOIN의 결과 개수 = 두 테이블 개수를 곱한 개수- 대량의 데이터를 생성하기 때문에
COUNT(*)함수로 개수만 카운트할 때 쓰입니다.
SELECT * FROM buytbl
CROSS JOIN usertbl;
-- == SELECT * FROM buytbl, usertbl;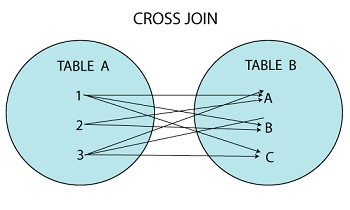
-- example
SELECT COUNT(*) AS '데이터개수'
FROM employees
CROSS JOIN titles;SELF JOIN(자체 조인)
- 하나의 테이블을 마치 2개처럼 사용하여 조인합니다. (자기 자신을 스스로 조인하는 효과)
- 테이블의 데이터가 계층적으로 구성된 경우 사용합니다.
- 분류의 용도로 자주 쓰입니다.
UNION / UNION ALL / NOT IN / IN
- 두 쿼리의 결과를 행으로 합쳐줍니다.
- 행의 개수가 같아야 합니다.
SELECT 행목록 FROM 테이블1
UNION [ALL]
SELECT 행목록 FROM 테이블2;🌜 SQL 프로그래밍
IF ... ELSE
- 조건에 따라 2중 분기하여 반환합니다.
- 한 문장 이상 처리되어야 할때
BEGIN ... END로 묶어줍니다.
IF {부울표현식} THEN
{QUERY...}
ELSE
{QUERY...}
END IF;CASE
- 조건에 따라 다중 분기합니다.
- 조건에 맞는
WHEN이 여러개더라도 먼저 조건이 만족하는 WHEN 처리됩니다. - 보통
SELECT문에서 많이 사용됩니다. - 점수로 성적을 판단하는 경우처럼 여러 단계로 분기 될 때 사용됩니다.
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN conditionN THEN resultN
ELSE result
END;WHILE 과 ITERATE / LEAVE
WHILE문- 다른 프로그래밍 언어의
WHILE과 동일한 개념으로 볼 수 있습니다. - 해당 부울식이 true인 동안에 계속 반복됩니다.
ITERATE문을 만나면WHILE문으로 이동해서 비교를 다시합니다. (다른 언어의continue개념)LEAVE문을 만나면WHILE문을 빠져나옵니다. (다른 언어의break개념)
- 다른 프로그래밍 언어의
WHILE <부울표현식> DO
{QUERY...}
END WHILE;오류 처리
DECLARE 액션 HANDLER FOR 오류조건 처리할문장;액션: 오류 발생 시에 행동을 정의합니다.CONTINUE와EXIT둘중 하나를 사용합니다.CONTINUE시처리할문장을 처리합니다.
오류조건: 어떤 오류를 처리할 것인지를 지정합니다.- MySQL의 오류 코드가 오거나
SQLSTATE'상태코드',SQLEXCEPTION,SQLWARNING,NOTFOUND등이 올 수 있습니다.
- MySQL의 오류 코드가 오거나
처리할문장- 처리할 문장이 여러개일 경우에는
BEGIN...END로 묶어줍니다.
- 처리할 문장이 여러개일 경우에는
-- example
DROP PROCEDURE IF EXISTS errorProc;
DELIMITER $$
CREATE PROCEDURE errorProc()
BEGIN
DECLARE CONTINUE
HANDLER FOR 1146
SELECT '테이블이 존재하지 않습니다' AS '메세지';
SELECT * FROM noTable; -- 없는 테이블
END $$
DELIMITER;
CALL errorProc();
-- '테이블이 존재하지 않습니다' 리턴동적 SQL
PREPARE
SQL문을 실행하지는 않고 미리 준비만 해놓습니다.
EXECUTE
- 준비한 쿼리문을 실행합니다.
- 실행 후에는
DEALLOCATE PREPARE로 문장을 해제합니다.
