Dataset
주어진 Vanilla Data를 모델이 좋아하는 형태의 Dataset으로
Pre-processing
모델링도 중요하긴 하지만, 좋은 데이터에서 좋은 학습결과가 나온다. 그렇기 때문에 데이터 전처리 과정은 엄청 중요한 과정이기에, Data Science에서 큰 부분을 차지한다. 오히려 모델링이 더 적은 부분을 차지한다. 실제로 일을 하게 되면, 대부분의 시간을 전처리에 쓰게 된다.

Competition Data는 보통 그 품질이 양호한 편이다. (Noise, Null 값이 거의 없거나 적다.) 가끔 이런 Noise를 고려한 대회가 열리기도 한다.
Bounding box
차량을 식별하는 과정에서 사실 차량을 제외한 부분들은 Noise로 볼 수 있다. 그렇기 때문에 차의 정확한 부분을 Bounding box로 표시한다.

Resize
계산의 효율을 위해 적당한 크기로 사이즈 변경
센서가 입력받는 이미지는 실제로 해상도가 매우 높다. 그러나 그런 높은 해상도의 이미지로 모델을 훈련시키게 되면 학습에 너무 많은 시간이 소요된다. 300 x 300 이미지라도 90,000 개의 픽셀이 있는데 실제 사진은 이 해상도 보다도 높다. 그렇기 때문에 적당한 크기로 사이즈를 조절하는 작업은 필수적이다.
"도메인, 데이터 형식에 따라 정말 다양한 Case가 존재"
그 밖에도 도메인이나 데이터 형식에 따라 전처리를 해줘야 하는 부분이 굉장히 다양하다.
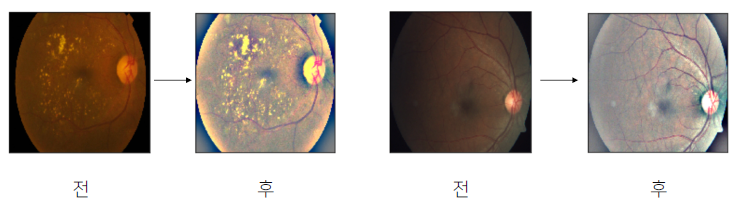
의료 데이터를 예로 들어보자. 한국의 경우 좋은 의료기기들이 있어 양질의 데이터가 추출되지만, 의료 기기들이 별로 좋지 않은 경우에는 위 사진의 전 데이터처럼 어두운 이미지가 추출될 수 있다. 이런 경우 모델이 좀 더 사진에서 문제가 있는 부분을 파악하기 쉽도록, 밝기를 조절하는 전처리 방법이 존재한다.
Generalization
Bias & Variance
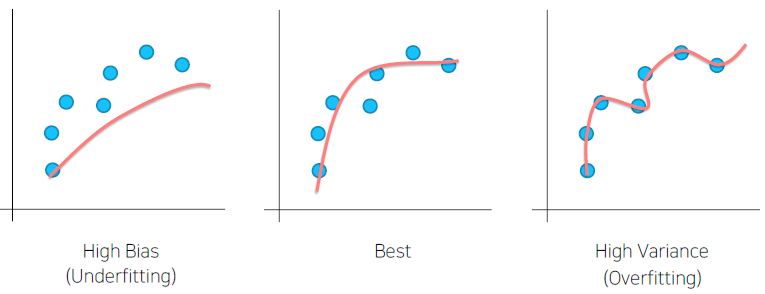
모델이 overfitting 되면, 실제로 의미가 없는 Noise 데이터도 분류에 이용할 수 있다. 즉, 훈련 데이서에 대해서 overfitting이 되지 않고 일반적인 데이터에도 잘 적용되도록 학습이 되야한다.
Train / Validation
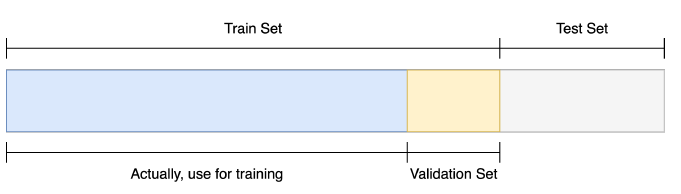
모델이 겪지 못한 상황에 대해서도, 잘 예측할 수 있어야 한다. 그렇기 때문에 훈련 데이터를 나누고, validation set에서도 예측 결과가 좋은지 확인해야 한다.
Data Augmentation
주어진 데이터가 가질 수 있는 Case(경우), State(상태)의 다양성

도메인에 따라서 Data Augmentation을 하는 방법은 다양하다. 위 차량 식별을 예로 들면 오후, 오전, 밤, 날씨 등에 관계 없이 차량을 식별할 수 있어야 한다. 이런 상황들을 고려하여, 상황에 맞는 Data Augmentation을 해줘야 한다.
문제가 만들어진 배경과 모델의 쓰임새를 살펴보면 힌트를 얻을 수 있다.
만약 마스크를 썼는지 안 썼는지 구분하는 모델을 만든다면 상하를 반전시킨 Augmentation은 필요하지 않다. 현실세상에는 중력을 거슬러 거꾸로 다니는 사람은 존재하지 않는다.
Image에 적용할 수 있는 다양한 함수들
Original, RandomCrop, Flip(상하좌우 반전)
Albumentations 라이브러리를 설치하면 좀 더 다양한 Augmentation을 적용할 수 있다. torchvision에 있는 Augmentation보다 전처리가 더 빨라서 실제로 많이 사용한다.
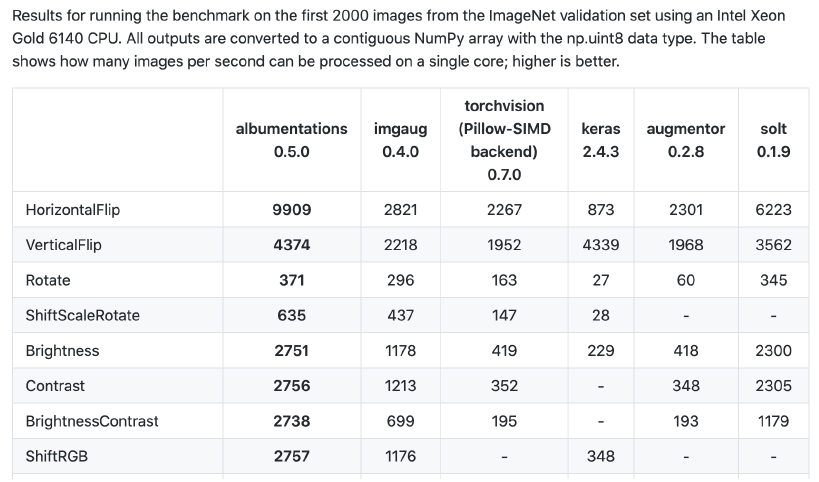
‘무조건’ 이라는 단어를 제일 조심하자.
Data Augmentation은 항상 좋은 결과를 가져다 주지는 않는다.
이러한 함수들은 여러가지 도구 가운데 하나일 뿐이고 무조건 적용 가능한 마스터키 같은 것도 사실 없다.
따라서 앞서 정의한 Problem(주제)을 깊이 관찰해서 어떤 기법을 적용하면 이러이러한 다양성을 가질 수 있겠다 가정하고 실험으로 증명해야 한다.
Data Generation
Data Feeding
위 그림처럼 설계 제작 포장을 거치는 제작 공정이 있다고 가정해보자.

이 때 물품 출하량을 더 늘리고 싶어 제작공정만 늘린다면 물품출하량이 늘어날까?

그렇지 않다. 포장 공정은 그대로이기 때문에 제작된 물품들은 포장되지 않고 쌓여만 갈 뿐이다.
모델에 데이터를 넣고 학습하는 과정도 이와 비슷하다.
Data Generator가 초당 10batch를 만든다면 model은 Data가 만들어지는 동안 쉬고 있게 된다. GPU 자원은 한정적이기 때문에 굉장히 큰 손해다. 이를 해결하려면 Data Generator가 더 빨리 Data를 만들 수 있도록 해야한다.
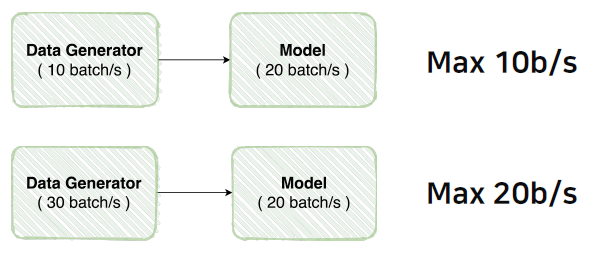
Dataset 생성 능력 비교

데이터를 만드는 과정도 생성속도 효율성에 영향이 있다.
위 1번과 2번을 보면 해상도를 그대로 회전하는 것과 회전하고 Resize하는 과정이 있다. 당연히 2번에 Resize하는 과정이 추가되어 2번이 더 느리다. 원 사이즈(300, 300) 보다 size를 더 크게 하는 Resize하는 과정인데 작은 사이즈를 먼저 회전하고 사이즈를 키우는 2번과, 사이즈를 키운 다음 회전을 하는 3번를 비교해보면 사이즈를 키워서 회전을 하는게 더 오랜 시간이 걸리는 것을 확인할 수 있다.
생각해보면 당연히 픽셀 수가 많으면 많을 수록 회전하는 픽셀이 많아 시간이 더 오래걸리게 된다.
이 처럼 데이터를 가공하는 과정도 신경쓰면 안 그래도 오래걸리는 학습 시간을 효율적으로 쓸 수 있다.
torch.utils.data
Vanilla Data를 Dataset으로 변환한다.
Dataset
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self): # 생성자
pass
def __getitem__(self, index): # Mydataset의 데이터 중 index 위치의 아이템을 리턴
return None
def __len__(self): # Mydataset 아이템의 전체 길이
return NoneDataLoader
train_loader = torch.utils.data.DataLoader(
train_set, # 데이터 셋
batch_size=batch_size, # 배치 사이즈
num_workers=num_workers, # 데이터를 불러올 때 사용하는 CPU 코어 수
drop_last=True,
)기본적으론 위와 같은 매개변수들이 존재하지만, 이 외에도 다양한 기능들이 존재한다.

num_workers는 자신의 CPU 코어 수를 확인한 뒤 적당한 값을 주는게 좋다. 컴퓨터의 CPU 중 어떤 코어는 운영체제를 유지하는데 사용되고, 어떤 코어는 시스템을 유지하는 데 사용되는 등 각자 이미 맡은 역할을 하는 CPU도 있기에 모든 코어수를 num_workers에 할당하는 것은 좋지 않다.
Dataloader에 사용되는 Dataset을 다른 Dataset으로 바꿀 수도 있다. 각자 역할이 정해져 있기 때문에 Dataset과 DataLoader는 분리되는 것이 좋다.
