
⭐️TIL (2024.11.25) - 고객 코호트 분석 SQL
📝 주제: 2011년 12월 첫 주문 고객의 연도별 매출 분석
오늘은 이커머스 데이터 분석에서 2011년 12월에 첫 주문한 고객을 대상으로 연도별 매출 관련 지표를 집계하는 SQL 문제를 학습했다. 문제를 해결하며, 고객 데이터를 집계하는 과정에서 고려해야 할 다양한 사항과 SQL의 활용 방법을 다시 확인할 수 있었다.
학습 내용
1️⃣ 문제 정의
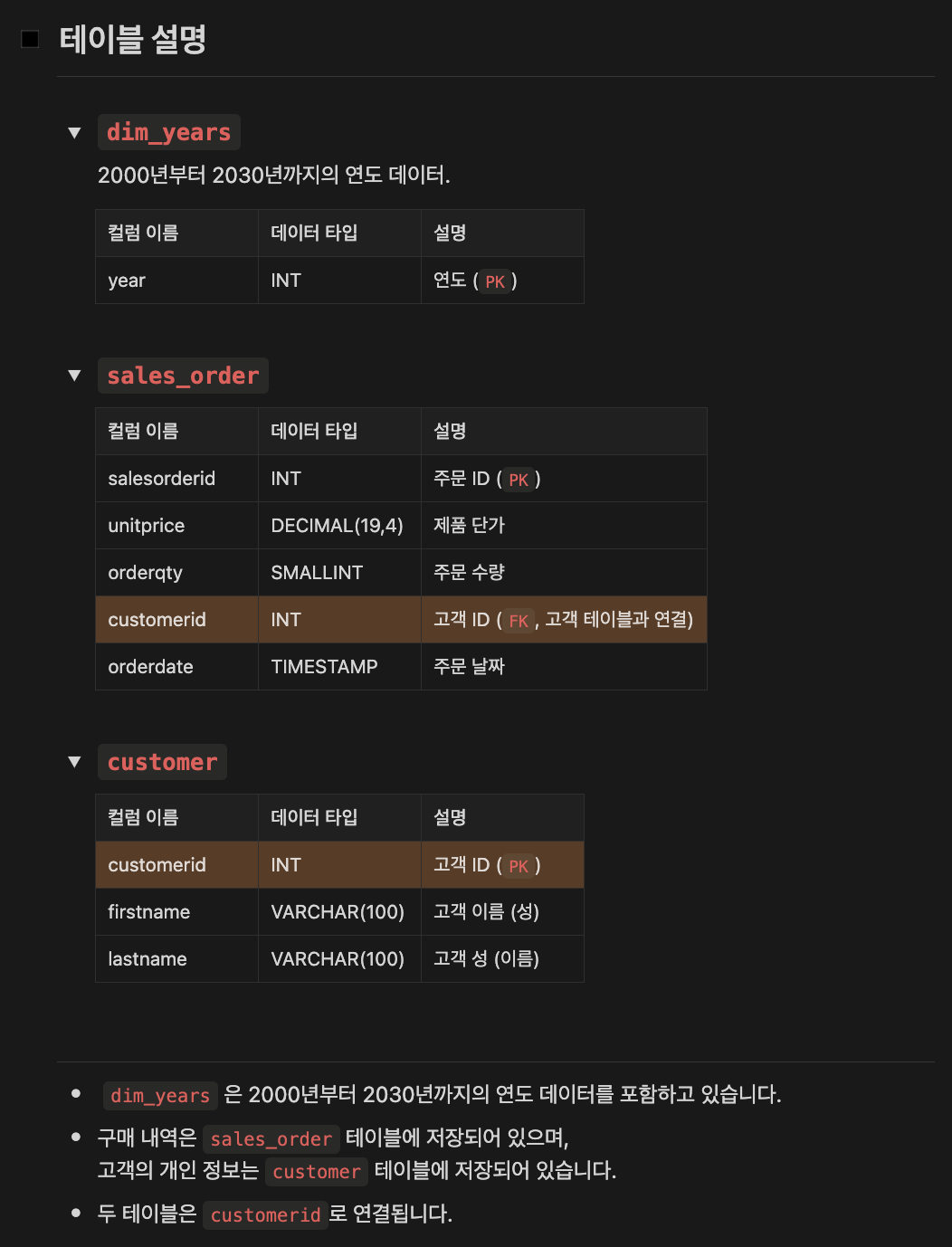
목표: 특정 고객 그룹(2011년 12월 첫 주문 고객)에 대해 연도별 매출 지표 집계.
필요한 데이터:
- 고객 ID와 이름
- 고객별 연평균 매출(GMV)
- 최대 주문 수와 해당 연도
- 특이 사항: 고객이 주문하지 않은 연도의 매출은 0으로 처리해야 함.
2️⃣ 내 풀이의 한계
내가 작성한 SQL에서 문제가 발생한 이유:
고객의 첫 주문과 마지막 주문 연도 사이의 모든 연도를 포함하지 못함.
결과적으로 주문하지 않은 연도의 GMV를 0으로 처리하지 못해 연평균 GMV 계산에 오류가 발생해버렸다.
3️⃣ 해결 방안: Divide & Conquer 접근법
강사님의 SQL 풀이를 통해 효율적인 접근법을 배울 수 있었다. 주요 과정은 다음과 같다:
1) 고객 첫/마지막 주문 연도 계산
MIN()과 MAX()를 활용해 고객의 첫 주문 연도와 마지막 주문 연도를 계산.
필터 조건으로 2011년 12월 첫 주문 고객만 추출.
SELECT
customerid,
CONCAT(firstname, ' ', lastname) AS customer_name,
MIN(YEAR(orderdate)) AS first_order_year,
MAX(YEAR(orderdate)) AS last_order_year
FROM sales_order
GROUP BY customerid
HAVING DATE_FORMAT(MIN(orderdate), '%Y-%m') = '2011-12'2) 첫 주문 ~ 마지막 주문 연도 포함
모든 연도를 포함시키기 위해 dim_years 테이블과 조인.
고객이 주문하지 않은 연도를 포함하기 위해 LEFT JOIN 사용.
SELECT
customerid,
customer_name,
year
FROM customer_order_range
LEFT JOIN dim_years
ON year BETWEEN first_order_year AND last_order_year3) 연도별 GMV 및 주문 수 계산
각 연도별 GMV와 주문 수량을 계산하고, COALESCE를 사용해 데이터가 없을 경우 0으로 처리.
SELECT
customerid,
customer_name,
year,
COALESCE(SUM(unitprice * orderqty), 0) AS gmv,
COALESCE(SUM(orderqty), 0) AS orders
FROM customer_years
LEFT JOIN sales_order
ON customerid = sales_order.customerid AND YEAR(orderdate) = year
GROUP BY customerid, customer_name, year4) 연평균 GMV 계산
AVG() 함수와 ROUND()를 사용해 연평균 GMV를 소수점 둘째 자리까지 계산.
SELECT
customerid,
customer_name,
ROUND(AVG(gmv), 2) AS avg_yearly_gmv
FROM customer_gmv
GROUP BY customerid, customer_name
5) 최대 주문 수량 및 연도 추출
ROW_NUMBER()를 활용해 고객별 최대 주문 수량을 가진 연도를 찾음.
동일한 최대 주문 수량이 여러 연도에서 발생할 경우, 더 최근 연도를 우선.
SELECT customerid, customer_name, year, orders
FROM (
SELECT
customerid,
customer_name,
year,
orders,
ROW_NUMBER() OVER (PARTITION BY customerid ORDER BY orders DESC, year DESC) AS order_rank
FROM customer_gmv
) a
WHERE order_rank = 15) 최종 데이터 병합
연평균 GMV와 최대 주문 연도를 병합하여 최종 결과 생성.
SELECT
a.customerid,
a.customer_name,
a.avg_yearly_gmv,
m.year AS max_order_year,
m.orders AS max_order_count
FROM avg_gmv_orders a
INNER JOIN max_orders_per_year m
ON a.customerid = m.customerid
ORDER BY a.customerid;
전체 답안
-- divide and conquer
WITH customer_order_range AS (
-- 첫 주문과 마지막 주문 연도 계산
-- 고객 이름 = 이름 + 성
-- Filter: 2011년 12월에 첫 주문한 고객
SELECT
c.customerid,
CONCAT(c.firstname, ' ', c.lastname) customer_name,
MIN(YEAR(so.orderdate)) AS first_order_year,
MAX(YEAR(so.orderdate)) AS last_order_year
FROM
qcc.customer c
INNER JOIN qcc.sales_order so ON c.customerid = so.customerid
GROUP BY c.customerid
HAVING DATE_FORMAT(MIN(so.orderdate), '%Y-%m') = '2011-12'
), customer_years AS (
-- 첫 주문과 마지막 주문 사이
SELECT
c.customerid,
c.customer_name,
dy.year
FROM
customer_order_range c
LEFT JOIN qcc.dim_years dy
ON dy.year BETWEEN c.first_order_year AND c.last_order_year
), customer_gmv AS (
-- 고객 별 연도 별 GMV, 주문수
SELECT
cy.customerid,
cy.customer_name,
cy.year,
COALESCE(SUM(so.unitprice * so.orderqty), 0) AS gmv,
COALESCE(SUM(so.orderqty), 0) AS orders
FROM
customer_years cy
LEFT JOIN qcc.sales_order so ON cy.customerid = so.customerid AND YEAR(so.orderdate) = cy.year
GROUP BY cy.customerid, cy.customer_name, cy.year
), avg_gmv_orders AS (
-- 고객 별 연평균 GMV
SELECT
customerid,
customer_name,
ROUND(AVG(gmv), 2) AS avg_yearly_gmv
FROM
customer_gmv
GROUP BY customerid, customer_name
), max_orders_per_year AS (
-- 고객 별 연 최대 주문 수, 최대 주문 수의 연도
SELECT customerid, customer_name, year, orders
FROM (
SELECT
customerid,
customer_name,
year,
orders,
ROW_NUMBER() OVER (PARTITION BY customerid ORDER BY orders DESC, year DESC) AS order_rank
FROM
customer_gmv
) a
WHERE order_rank = 1
)
SELECT
a.customerid,
a.customer_name,
a.avg_yearly_gmv,
m.year AS max_order_year,
m.orders AS max_order_count
FROM
avg_gmv_orders a
INNER JOIN
max_orders_per_year m ON a.customerid = m.customerid
ORDER BY
a.customerid;출력 결과
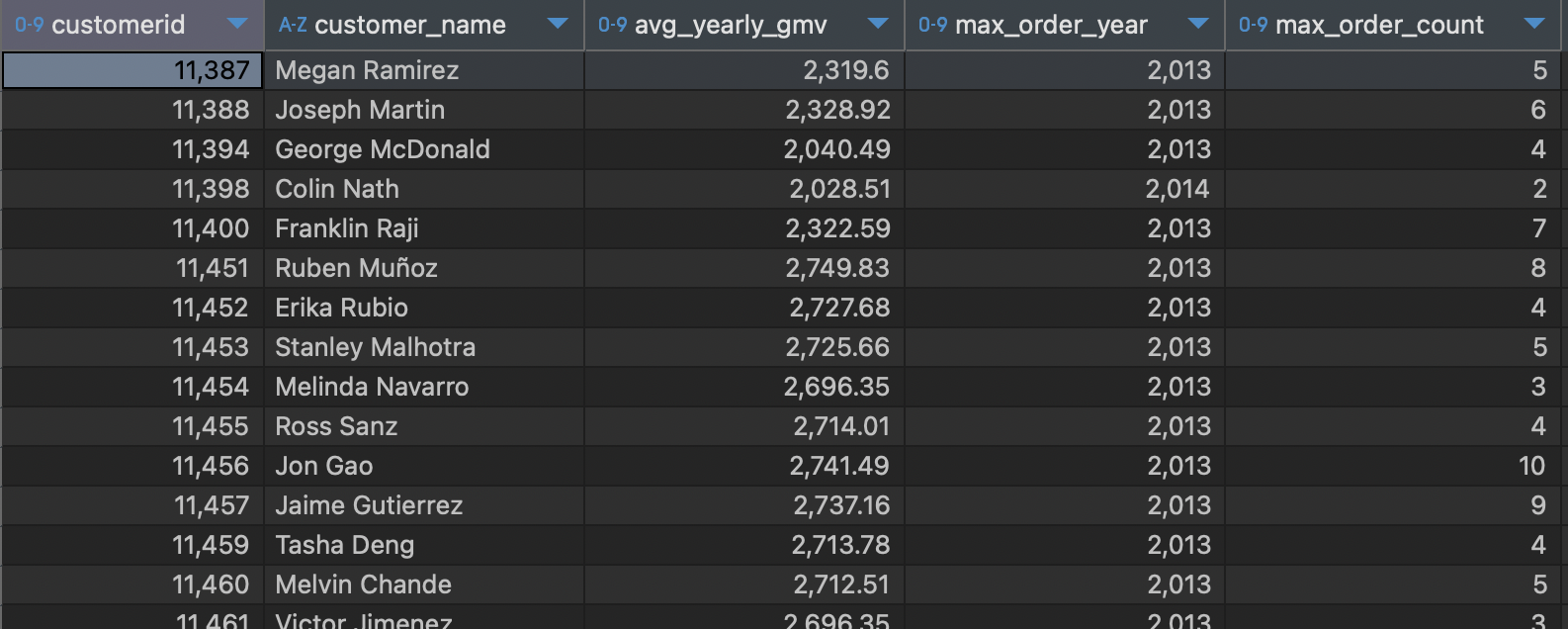
⭐️ 배운 점
- 누락 데이터 처리: 고객이 주문하지 않은 연도를 포함하고 0으로 처리하기 위해 보조 테이블(dim_years)과 LEFT JOIN을 활용하는 방법을 배움.
- 가독성 있는 SQL 작성: SQL 쿼리를 단계별로 분리하여 가독성을 높이고, 각 단계에서의 결과를 명확히 확인할 수 있음.
- 고객 분석의 세부 사항: 특정 이벤트(첫 주문)에 기반한 분석에서는 데이터 필터링 및 집계 논리가 중요함.
- ROW_NUMBER() 활용: 최대값 또는 조건에 맞는 데이터를 효율적으로 추출할 수 있는 방법.
⭐️ 적용 방안
앞으로 데이터 분석 시, 누락 데이터를 포함하거나 특정 기간을 확장해야 할 경우, 이와 같은 방식으로 해결할 수 있을 것.
SQL을 사용할 때 가독성과 재사용성을 높이기 위해 쿼리를 논리적으로 나누는 습관을 길러야겠다.
