
💾 데이터베이스
데이터를 저장 및 보존하는 시스템
- file 과는 달리 접근 및 관리가 편하다.
- 메모리는 휘발성이기 때문에,
DB에 영구적으로 저장해 메모리(속도↑)에서 읽어 가공처리해 사용한다. - 데이터베이스에는 관계형 데이터베이스와 비관계형 데이터베이스가 있다.
🖇 관계형 데이터베이스
관계형 데이터 란 데이터를 서로 상호관련성을 가진 형태로 표현한 데이터를 말한다.
- 모든 데이터들은 2차원 테이블로 표현되며,
각각의column(각 항목)과row(각 항목의 실제 값)로 구성된다. - 각
row는 저만의 고유 키(Primary Key)가 있다.
> 각각의 테이블은 서로 상호관련성을 가지고 서로 연결될 수 있다.
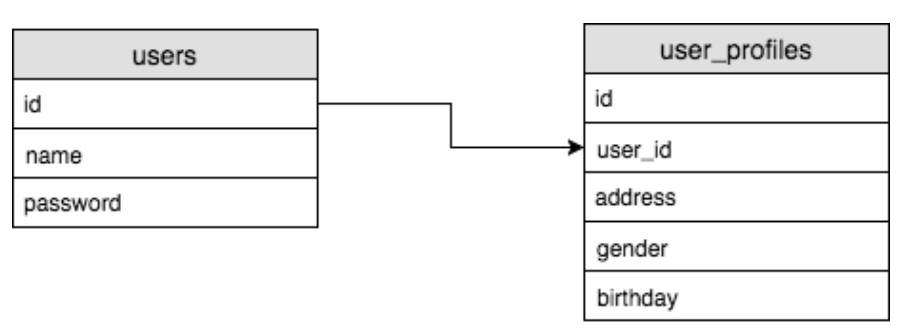
One To One
테이블 A와 row와 테이블 B의 row가 정확히 1:1 매칭이 되는 관계
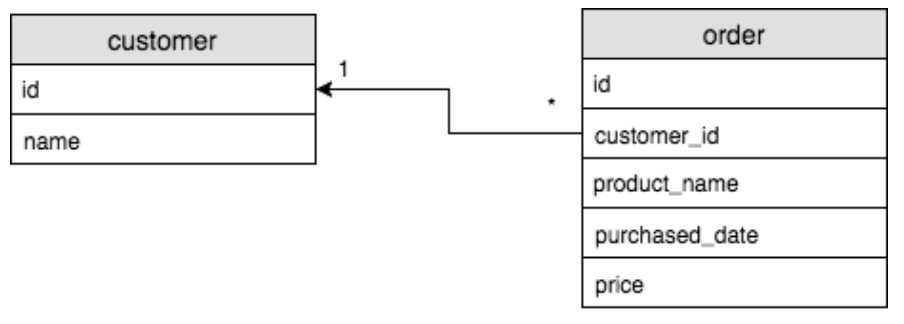
One To Many
테이블 A의 row가 테이블 B의 여러 row와 연결이 되는 관계
Many To Many
테이블 A의 여러 row가 테이블 B의 여러 row와 연결이 되는 관계
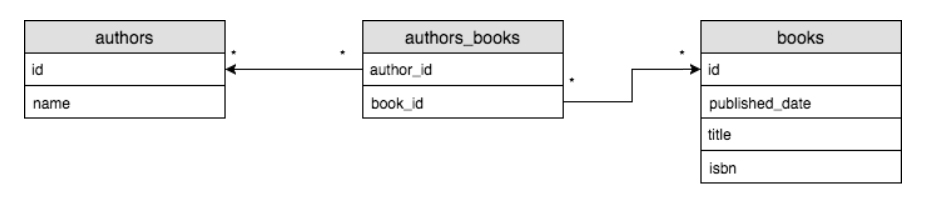
책은 여러 작가에 의해 쓰일 수 있고 작가들은 여러 책을 쓸 수 있다.
> 관계형을 쓰는 이유
하나의 테이블에 모든 정보를 넣으면 동일한 정보들이 불필요하게 중복되어 저장된다.
더 많은 디스크를 사용하게 되고 잘못된 데이터가 저장될 가능성이 높아진다.
👉 때문에 여러 테이블에 나누어서 저장한 후 필요한 테이블을 연결시켜 사용한다.
💡 normalization (정규화)
① 하나의 cell 에는 한개의 값을 가져야 한다.
② 모든 column이 pk에 속해야 한다.
③ 기본키 이외의 모든 속성간에 종속적인 관계가 없어야 하고 pk가 아닌 다른 속성이 또다른 속성에 종속된다면 별도의 테이블로 나눠야 한다.
> Transaction (트랜잭션)
일련의 작업들을 한번에 하나의 unit으로 실행하는 것 (commit & rollback)
- Atomicity (원자성)
트랜잭션과 관련된 작업들이 부분적으로 실행되다가 중단되지 않는 것을 보장하는 능력 - Consistency (일관성)
트랜잭션이 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 유지하는 것 - Isolation (격리성)
트랜잭션을 수행 시 다른 트랜잭션의 연산 작업이 끼어들지 못하도록 보장하는 것 - Durability (영속성)
성공적으로 수행된 트랜잭션은 영원히 반영되어야 함을 의미한다.
🗣 SQL vs NoSQL
💡 SQL
MySQL과 같은 관계형 데이터베이스에서 데이터를 읽거나 생성 및 수정하기 위해 사용하는 언어
> SQL
-
장점
① 관계형 데이터베이스는 데이터를 더 효율적으로 그리고 체계적으로 저장할 수 있고 관리할 수 있다.
② 미리 저장하는 데이터들의 구조를 정의 함으로써 데이터의 완전성이 보장된다.
③ 트랜잭션 -
단점
① 테이블 구조 변화에 덜 유연하다.
② 단순히 서버를 늘리는 것만으로 확장하기가 쉽지 않고 서버의 성능 자체도 높여야 한다. -
usage
정형화된 데이터들 그리고 데이터의 완전성이 중요한 데이터들을 저장하는데 유리하다.
ex. 전자상거래 정보
> NoSQL
-
장점
① 데이터의 구조 변화에 유연하다.
② 확장하기가 비교적 쉽다. (서버 수를 늘리면 됨)
③ 확장하기가 쉽고 데이터의 구조도 유연하다 보니 방대한 양의 데이터를 저장하는데 유리하다. -
단점
① 데이터의 완전성이 덜 보장된다.
② 트랜잭션이 안되거나 비교적 불안정하다. -
usage
주로 비정형화 데이터 그리고 완전성이 상대적으로 덜 유리한 데이터를 저장하는데 유리하다.
ex. 로그 데이터
