
AWS RDS
RDS 개요
-
RDS => 관계형 데이터베이스 서비스의 약자
-
DB관리를 AWS가 함(PostgreSQL, MySQL, MariaDB, Oracle Microsoft SQL Server, Aurora)
-
EC2 인스턴스마다 자체 DB를 사용하는것보다 RDS로 관리하는게 효율적임(관리형 서비스임)
-
데이터베이스 프로비저닝과 기본 운영체제 패치가 완전 자동화되어 있음 => 지속적으로 백업이 생성되므로 특정 타임스탬프, 즉 특정 시점으로 복원가능.
-
RDS 스토리지 오토스케일링 => 예를들어 스토리지리를 20GB로 설정했는데 데이터베이스 용량이 부족해지면 알아서 자동으로 스토리지 확장해줌(DB다운..필요없음)
RDS 읽기전용복제본 VS 다중 AZ
RDS 읽기전용복제본
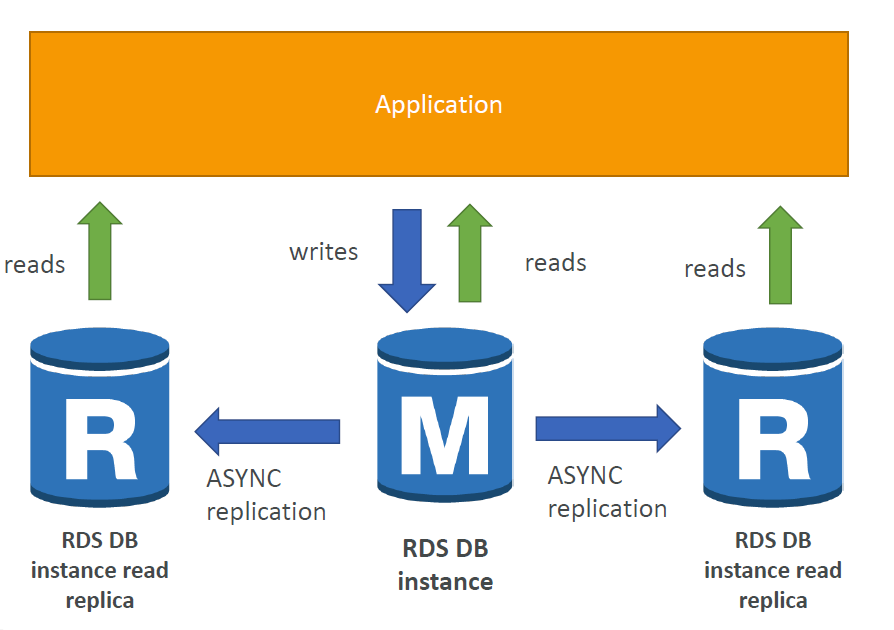
-
RDS DB 인스턴스는 읽기 쓰기역할을 동시에 수행. 하지만, MAIN 인스턴스가 너무 많은 요청을 받아서 충분히 스케일 할 수 없는 경우 읽기전용 복제본 인스턴스를 생성
-
동일한 가용역역 또는 가용영역 REGION을 걸쳐서 생성될 수 있다.
-
일관적 비동기식 복제 : 읽기가 일관적으로 유지되도록 DB인스턴스 복제
-
읽기 뿐만 아니라 데이터베이스로도 승격시켜서 사용 가능
-
읽기전용은 SELECT 쿼리문만 사용 가능
-
AWS에서는 하나의 가용역역에서 다른 가용영역으로 데이터가 이동할 때 비용이 발생함.
-
하지만 관리형서비스에서는 예외가 존재함. 동일한 리전내에 있을 때는 비용이 발생하지 않음
(즉 us-east-1a에 RDS DB 인스턴스가 있고 그에 대한 읽기 전용 복제본은 us-east-1b에 있다고 치면 이는 비동기식 복제로 읽기 전용 복제본의 복제 트래픽이 하나의 AZ에서 다른 AZ로 넘어가더라도 RDS가 관리형 서비스이기 때문에 해당 트래픽은 비용 없이 무료로 이동할 수 있음.)
다중 AZ
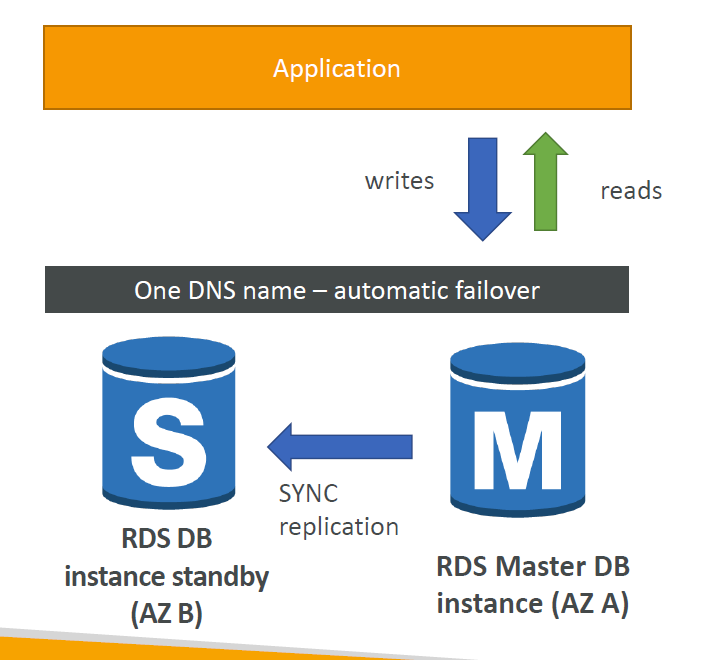
-
재해복구에 사용
-
동기식 복제 방식 => 마스터 데이터베이스에 쓰이는 변경사항이 대기 인스턴스에도 그대로 복제됨.
-
즉 하나의 DNS 이름을 갖고 애플리케이션 또한 하나의 DNS 이름으로 통신하며 마스터에 문제가 생길 때에도
스탠바이 데이터베이스에 자동으로 장애 조치가 수행됨. -
전체 AZ 또는 네트워크가 손실될 때에 대비한 장애 조치이자 마스터 데이터베이스의 인스턴스 또는 스토리지에 장애가 발생할 때 스탠바이 데이터베이스가 새로운 마스터가 될 수 있도록 함.
-
재해복구를 대비해서 읽기전용 복제본을 다중 AZ로 설정 가능? => 가능하다.
-
단일 AZ에서 다중 AZ로 데이터베이스 전환이 가능한가? => 데이터베이스를 중지할 필요가 없다.
-
기본 데이터베이스의 RDS가 자동으로 스냅샷을 생성, 이 스냅샷은 새로운 스탠바이 데이터베이스에 복원됨.
-
스탠바이 데이터베이스가 복원되면 두 데이터베이스 간 동기화가 설정되므로 스탠바이 데이터베이스가
메인 RDS 데이터베이스 내용을 모두 수용하여 다중 AZ 설정 상태가 됨.
RDS CUSTOM
-
RDS는 데이터베이스 전체를 관리합니다 운영 체제와 나머지는 AWS에서 관리하고 여러분은 아무 것도 하지 않아도 됨.
-
RDS Custom은 Oracle 및 Microsoft SQL Server에서만 사용할 수 있습니다 그리고 기저 운영 체제와 데이터베이스에 대한 관리자 권한 전체를 갖게 됨.
Aurora
-
Aurora => aws 고유기술 postgres와 mysql에 호환됨.
-
오토스케일링 가능함, 15개의 읽기전용 복제본 생성가능
-
마스터는 하나고, 복제본은 여럿이며 스토리지가 복제됨
-
그리고 작은 블록 단위로 자가 복구 또는 확장이 일어납니다
-
클러스터 => 오토스케일링이 커져있는경우 application 입장에서는 복제본이 어디있고, url은 무엇이고 어떻게 연결하는지 파악하기 어려울 수 있다.
-
리더 엔드포인트가 존재(Reader) : 라이터 엔드포인트와 정확히 같은 기능을 함. 연결 로드밸런싱에 도움을 줌, 읽기전용 복제본과 자동으로 연결됨.
-
복제본 오토스케일링 : 리더 엔드포인트에서 많은 읽기요청이 발생할 때 => Aurora DB의 cpu사용량이 증가함. => 복제본 오토스케일링을 통해 Aurora 복제본을 생성하고 cpu 사용량을 분산시킴.
-
사용자 지정 엔드포인트 : 어떤 복제본은 다른 복제본보다 사이즈가 크다. => 리더 엔드포인트는 사용자 지정 엔드포인트를 정의한 후 사용되지 않음
-
서버리스 : 실제 사용량에 따라 자동화된 데이터베이스 인스턴스화 및 오토 스케일링을 제공합니다
-
멀티마스터 : Aurora 클러스터에서 모든 Aurora 인스턴스는 라이터 노드입니다. 모든 Aurora 인스턴스가 쓰기를 받을 수 있다는 뜻임.
-
일반적인 Aurora 클러스터와는 다름 하나의 새 마스터가 있고 그 마스터가 실패할 경우 새 것이 새로운 마스터로 승격됩니다.
-
글로벌 Aurora : 재해복구에 유용함. region간 복제본이 있는 경우임, 한 리전에서 데이터베이스가 중단되는 경우 재해복구를 위해 다른 리전을 활성화하면 복구시간을 줄일 수 있다.
-
"Aurora 글로벌 데이터베이스의 데이터를 리전간에 복제하는데 평균 1초 미만이 소요됨"
RDS 백업
-
RDS 서비스가 자동으로 매일 데이터베이스의 전체 백업을 수행함. => 5분마다 트랜잭션 로그 백업됨.
-
수동백업기능도 존재
-
예를 들어 RDS 데이터베이스가 있는데, 한 달에 2시간만 사용하는 걸 알고 있다고 가정하고, 데이터베이스를 중지한다고 해보죠, 하지만 스토리지 비용은 데이터베이스를 중지하더라도 계속 지불해야 함.
-
따라서 두 시간 동안 사용한 후 스냅샷을 만든 다음, 원본 데이터베이스를 삭제하면됩니다
-
스냅샷은 RDS 데이터베이스의 실제 스토리지 비용보다 훨씬 저렴합니다
-
찍은 스냅샷은 복원가능 => 새로운 데이터베이스 생성함. S3에도 복원가능.
RDS 보안
-
RDS 및 Aurora 데이터베이스에 저장된 데이터를 암호화할 수 있습니다 => 데이터가 볼륨에 암호화됨
-
마스터 즉 주 데이터베이스를 암호화하지 않았다면 읽기 전용 복제본을 암호화할 수 없음
-
클라이언트와 데이터베이스 간의 전송 중 데이터 암호화가 있습니다
-
RDS 및 Aurora의 각 데이터베이스는 기본적으로 전송 중 데이터 암호화 기능을 갖추고 있음
-
따라서 클라이언트는 AWS 웹사이트에서 제공하는 AWS의 TLS 루트 인증서를 사용해야 함.
-
IAM을 통해 보안그룹 관리가능(포트 IP 보안그룹 허용 차단가능)
RDS 프록시
-
Amazon RDS 프록시를 사용하면 애플리케이션이 데이터베이스 내에서 데이터베이스 연결 풀을 형성하고 공유할 수 있습니다
-
애플리케이션을 RDS 데이터베이스 인스턴스에 일일이 연결하는 대신 프록시에 연결하면 프록시가 하나의 풀에 연결을 모아 RDS 데이터베이스 인스턴스로 가는 연결이 줄어듭니다.
-
인스턴스 연결이 많은 경우 리소스 사용을 최소화, 완전한 서버리스, 오토스케일링 가능함.
-
다중 AZ지원.. 장애조치 발생하면 => 대기인스턴스로 실행됨. 장애시간을 66% 줄일 수 있음.
-
메인 RDS 데이터베이스 인스턴스에 애플리케이션을 모두 연결하고 장애 조치를 각자 처리하게 하는 대신
장애 조치와 무관한 RDS 프록시에 연결하는 겁니다 RDS 프록시가 장애 조치가 발생한 RDS 데이터베이스 인스턴스를 처리하므로장애 조치 시간이 개선됨. -
IAM인증 강제 인증을 통해서만 RDS에 연결하도록 설정 가능
정리하면 RDS 프록시를 사용하면
RDS 데이터베이스 인스턴스의 연결을 최소화할 수 있고
장애 조치 시간을 최대 66%까지 감소시킬 수 있습니다
데이터베이스에 IAM 인증을 강제하는 데 사용되고
자격 증명은 Secrets Manager 서비스에 안전히 저장됩니다
ElasticCache
-
캐싱 기술인 Redis 또는 Memcached를 관리할 수 있도록 도와줍니다
-
일반적인 쿼리는 캐시저장 => 캐시에서 데이터베이스 결과 검색가능 => 운ㅇ영체제, 패치, 최적화, 구성,
-
반면 Memcached는 분산되어 있는 순수한 캐시입니다, 데이터가 손실되어도 괜찮은 경우고 Redis는 복제되는 캐시라고 생각하세요, 가용성과 내구성이 뛰어남.
-
보안: 예를 들어 EC2 인스턴스와 클라이언트가 있는 경우 Redis AUTH를 사용하여 Redis 클러스터에 연결할 수 있죠, Redis 보안 그룹에 의해 보호되죠, 또한 인플라이트 암호화를 사용하거나, 또는 예를 들어 Redis에서 IAM 인증을 활용할 수 있죠
-
ElasticCache에 데이터로드하는 방법 3가지
-
지연로딩 : 모든 데이터가 캐시되고 데이터가 캐시에서 지체될 수 있음
-
지연 로딩이라고 불리는 이유는, 캐시 히트가 없는 경우에만 데이터를 Amazon ElastiCache에 로드하기 때문입니다
