S3란?
Amazon S3는 객체 스토리지 서비스로, 인터넷에서 언제든지 데이터를 저장하고 검색할 수 있도록 설계되었다. S3는 간단한 API를 사용하여 파일을 저장하고 검색할 수 있으며, 클라이언트 측의 복잡한 로직이나 데이터베이스를 사용하지 않아도 된다. 또한 S3는 가용성과 내구성이 뛰어나며, 필요에 따라 자동으로 확장할 수 있다. 위와 같은 CRA로 만들어진 프로젝트를 S3를 이용하여 정적 웹 사이트로 호스팅하는 방법에 대해 설명하겠다.
1. 버킷 생성
- 버킷 이름과 서비스를 원하는 지역을 선택한다.
- 객체 소유권은 기본 값으로 설정된 ACL 비활성화됨(권장)을 선택한다.

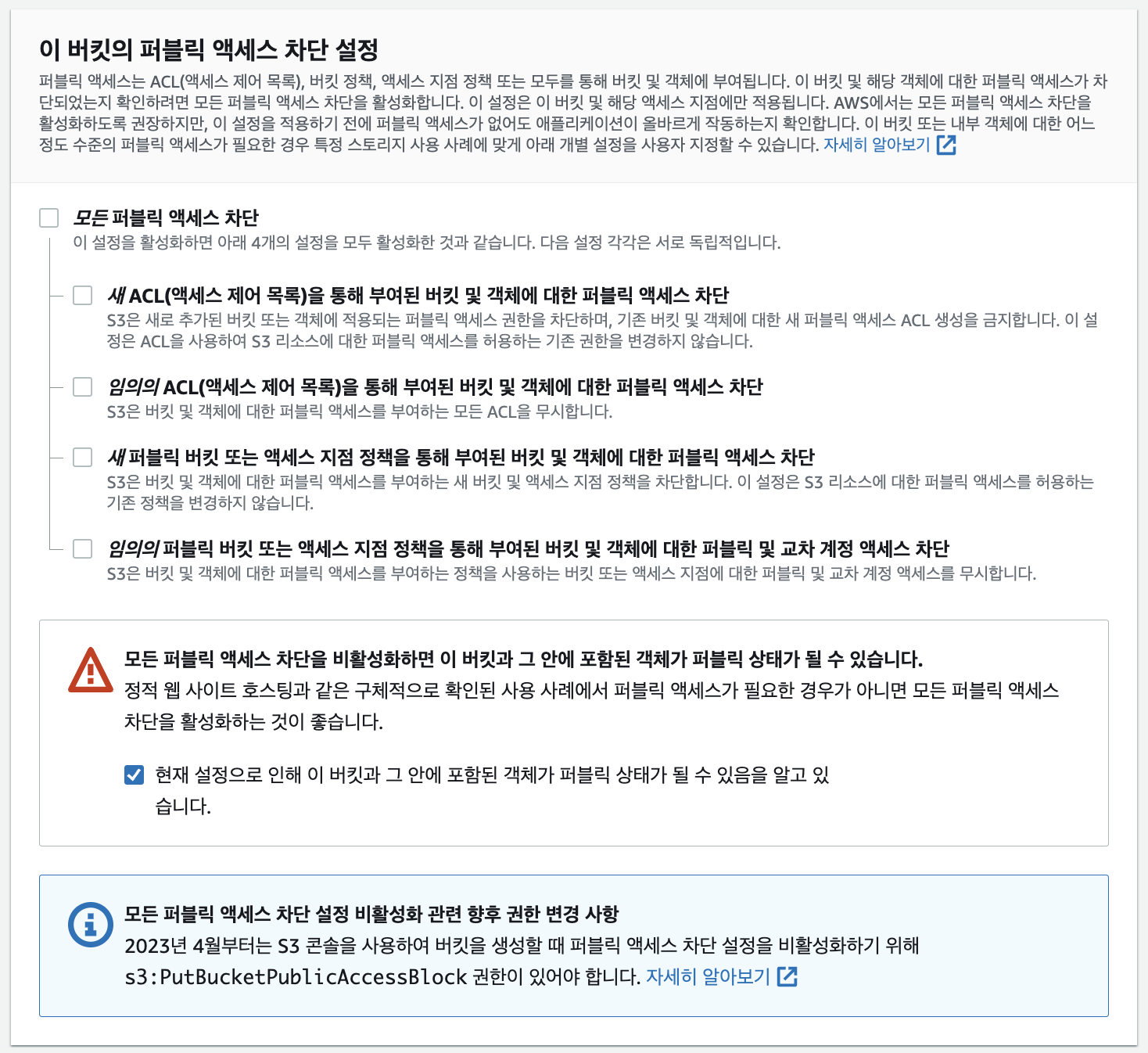
- 기본 값으로는 Block이다 즉, 모든 전체 접근을 막으며 이후 필요한 경우에만 접근 권한을 부여하여 보안을 유지한 는 것이 보안의 기본이다.
- 이번에 진행하는 것은 React 프로젝트를 S3에 배포하는 것이므로, Block 설정을 해제하고 진행한다.
- AWS에서 제공하는 기본 설정값을 활용하여 진행한다.
- 마지막으로 버킷생성을 눌러 생성 해준다.
2. Objects 설정
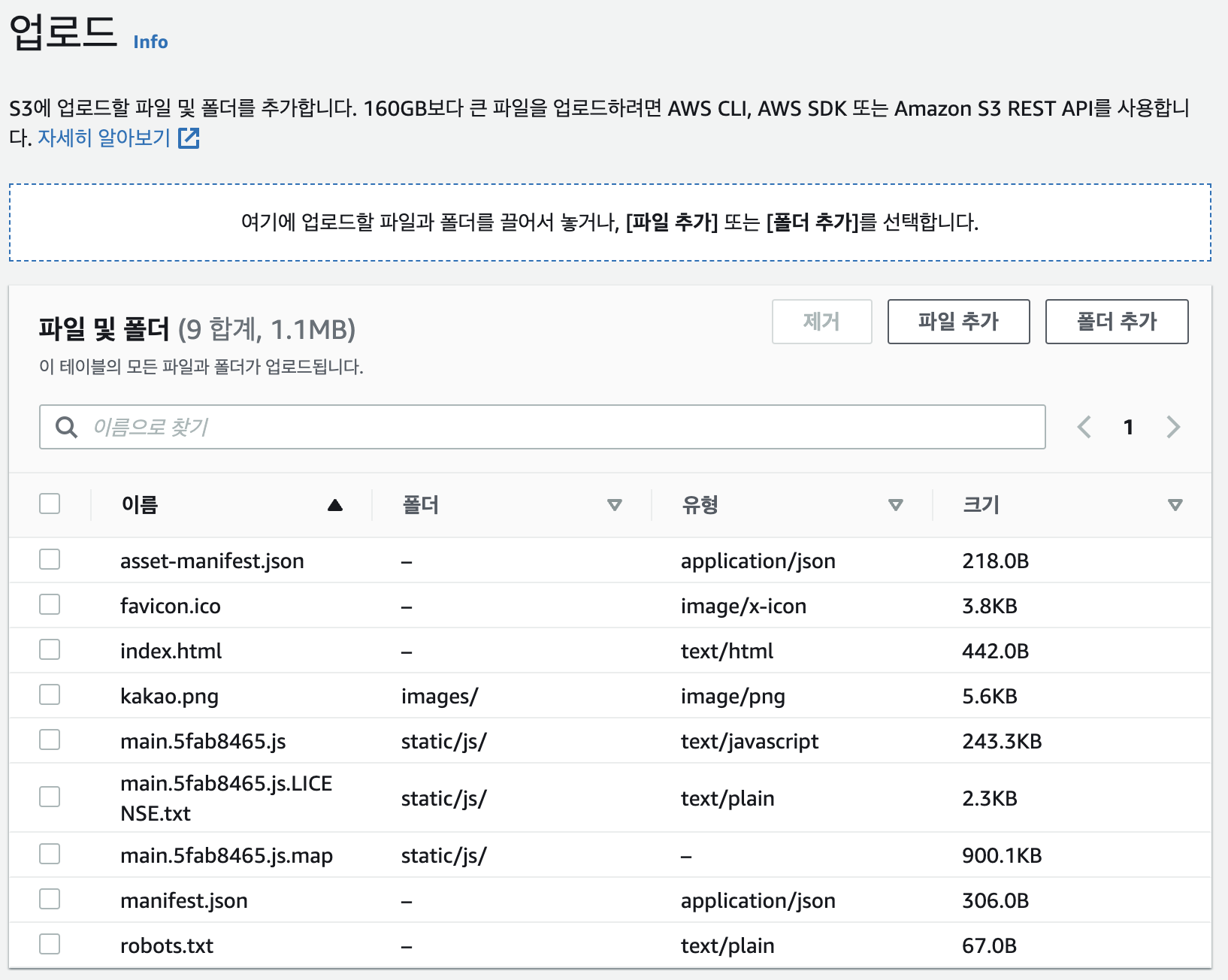
- S3 버킷 내에 저장되는 모든 파일을 객체(Object)라고 부른다.
- 빌드된 React 파일을 S3 버킷에 업로드한다.
- 빌드 폴더 전체를 업로드하는 것이 아니라, 해당 폴더 내용을 업로드하여
index.html이 노출되도록 한다.

3. Properties 설정
정적 웹사이트로 사용하기 위한 설정
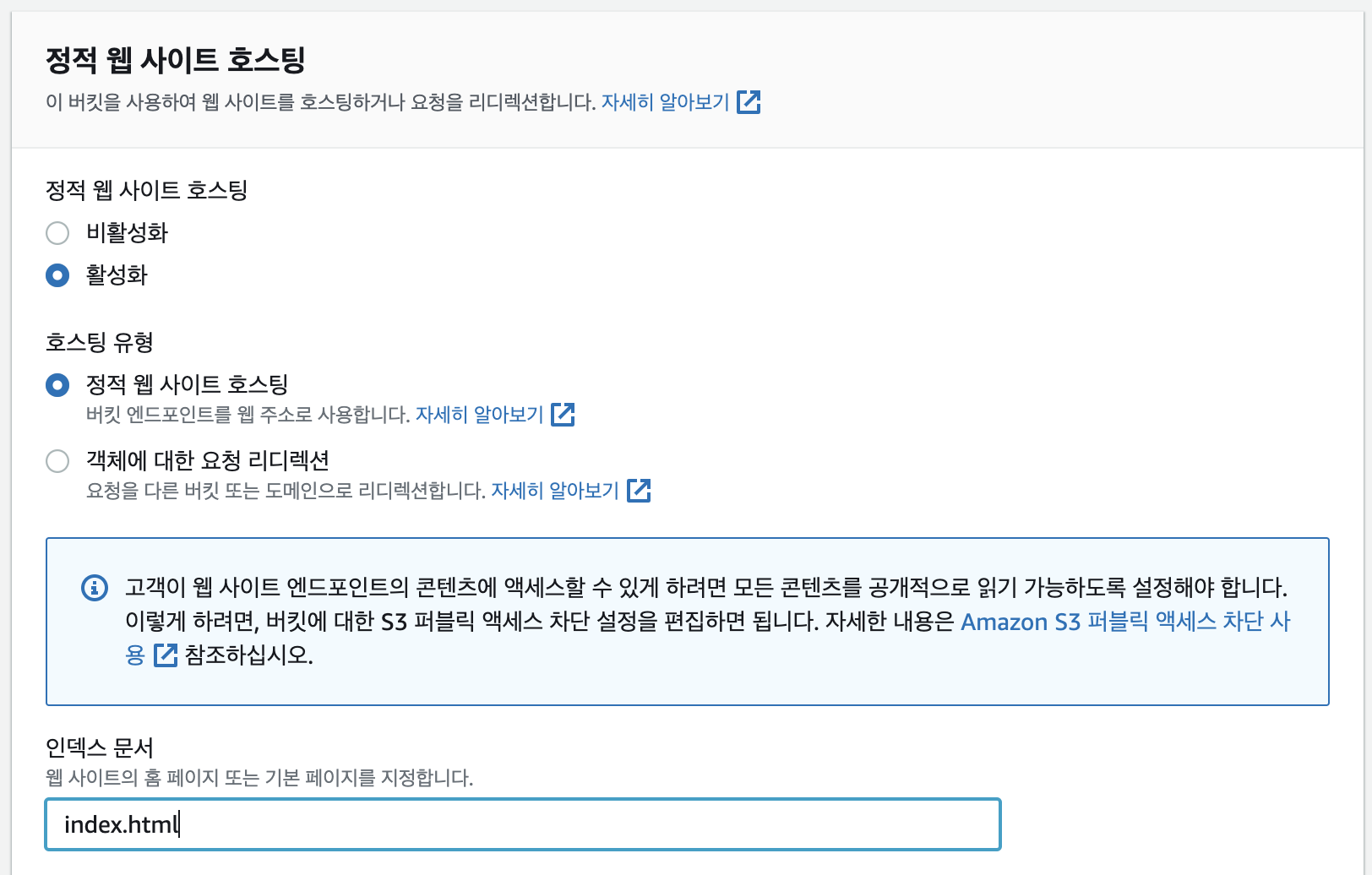
- 호스팅 유형에서 정적 웹사이트 호스팅을 선택하고 저장한다.
- 인덱스 문서에서
index.html을 지정하여 기본 페이지를 설정하고 저장한다.
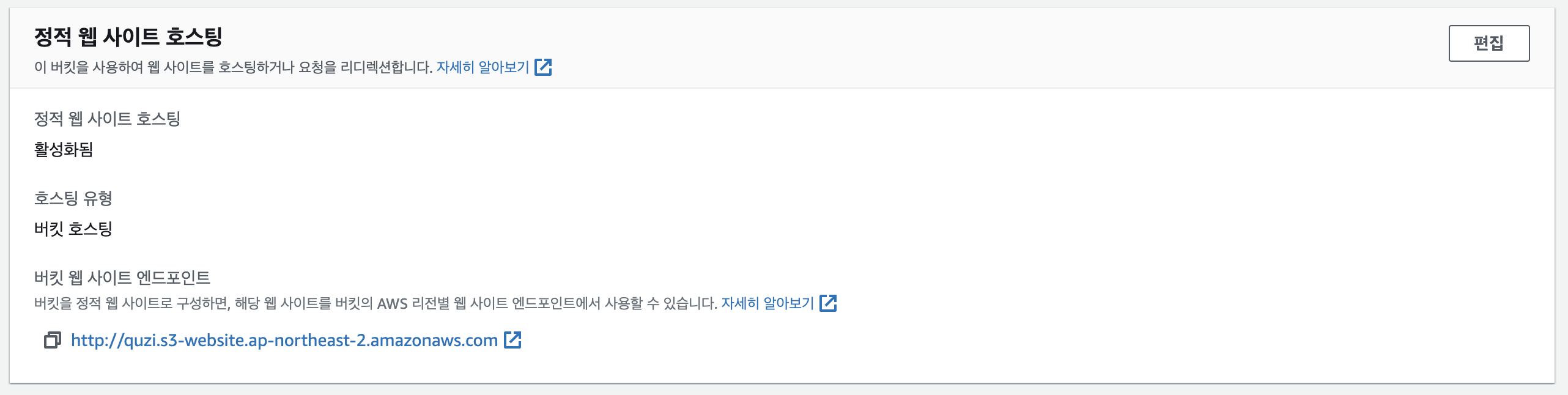
- 사이트 주소를 알려주지만 접근하면 403 오류가 발생한다

401, 403의 차이
401(인증)
- "인증되지 않은 사용자"가 접근하려고 할 때 발생
403(인가)
- "권한이 없는 사용자"가 접근하려고 할 때 발생. 사용자가 누구인지는 알고 있지만, 해당 리소스에 접근할 권한이 없는 것
버킷을 생성하기 전에 퍼블릭 엑세스 차단을 허용했지만 접근이 불가능 한 이유
- 퍼블릭 엑세스 차단 허용은 우리에게 허용 여부를 물어보는 것이며, 별도의 권한 설정이 필요하다.
4. Permissions
권환설정
- 권한 설정을 위해서는 버킷 정책을 JSON 형태로 작성해야 한다.
Resource에는 버킷 ARN을 지정한다.

- 코드
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PublicReadGetObject",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::<bucket-name>/*"
}
]
}
// 설명
{
"Version" : 2012-10-17의 문법을 사용해 설정
"Statement" : [
{
"Sid" : 여러개의 Statement의 부르는 이름(유니크한 이름)
"Effect" : 허용또는 거부(허용)
"Principal" : 모두
"Action" : s3에서 object파일을 get하는 걸 허용
"Resource" : 권환의 대상(버킷 이름)
}
]
}- 권한 설정이 완료되면 URL 요청을 통해 웹 사이트에 접근할 수 있게 된다.
배포 후 프로젝트를 수정하고 재배포를 하려면?
만약 프로젝트를 수정하거나 업데이트하여 다시 배포해야 하는 경우, objects에 있는 모든 파일을 삭제한 후 새로 빌드된 파일을 업로드해야 하는 불편함이 있다. 이를 해결하기 위한 자동화 방법에 대해 다음 포스트에서 작성하겠다.
출처
https://docs.aws.amazon.com/ko_kr/AmazonS3/latest/userguide/WebsiteHosting.html
원티드 프리온보딩 9차 참여 과정

사람들에게 하나의 문화를 선물해줄 수 있는 프로그램을 개발하고 싶습니다.