
📎
몬디... 왜 나만 모르는데... 궁금하면 알아내야 직성에 풀리는 사람의 디깅 기록.
⚖️ 같은 결과값, 뭐가 다르지?
오라클로 데이터베이스 연습문제를 풀던 중,
-- 3. emp table
-- 1) deptno 20, 30
-- 2) sal > 2000
-- a. 집합 연산자를 사용하지 않은 방식 / b. 집합 연산자를 사용한 방식으로 나눠서 작성
--a.
select empno, ename, job, sal, deptno
from emp
where deptno IN (20, 30)
and sal > 2000;
--b.
select empno, ename, job, sal, deptno
from emp
where deptno IN (20, 30)
INTERSECT
select empno, ename, job, sal, deptno
from emp
where sal > 2000;여기서 바로 b번! 집합 연산자를 사용한 방식으로 도출하는 과정에서
나의 답과 모범 답안(선생님 답안)이 달랐다.
나는 부서 조건과 월급 조건을 따로 구해서 합쳐야겠다는 생각으로 교집합을 사용했는데,
모범답안은 아래와 같이 UNION을 사용했던 것.
select empno, ename, job, sal, deptno
from emp
where deptno = 20
and sal > 2000
UNION
select empno, ename, job, sal, deptno
from emp
where deptno = 30
and sal > 2000;물론 결과 값은 동일하게 산출된다.
동일 값을 도출하기 위한 방법이 여러 개 있을 수 있다는 건 알지만,
왜 모범답안은 하필이면 UNION을 썼을까?
더 효율적인 방법인걸까?
🤔 혼자 고민해보기
내 방식은
1) 부서 20, 30에 해당하는 모든 데이터 조회
2) 급여 2000 초과 데이터 모두 조회
3) 1과 2의 겹치는 부분만 출력→ 필요한 정보 외에 출력해야 하는 데이터가 너무 많다.
반면, UNION을 이용하면
1) 부서 20이면서 급여 2000 초과인 데이터만 조회
2) 부서 30이면서 급여 2000 초과인 데이터만 조회
3) 1과 2의 데이터 합쳐서 출력→ 애초에 필요한 정보만 뽑아서 합치는 방식.
연습문제의 경우엔 예시 데이터가 적어서 크게 차이는 안 나지만,
데이터가 훨씬 많아진다고 가정하면 내가 썼던 방식은 너무 비효율적이라는 생각이 들었다.
🧠 AI에게 물었다
이럴 때 필요한 AI!
perplexity야 알려죠...
📌 집합 연산자 요약
INTERSECT (교집합)
- 두 쿼리 결과에서 공통된 레코드만 반환
- 자동으로 중복 제거 + 정렬
- 정확한 교집합이 필요할 땐 좋지만, 쿼리 실행 속도는 느릴 수 있음
UNION (합집합)
- 두 쿼리 결과를 합쳐서 중복 제거
UNION ALL은 중복 허용 → 그래서 훨씬 빠름- 대부분의 상황에서는
UNION ALL이 성능 면에서 유리함
🚀 성능 비교 정리
| 연산자 | 중복 제거 | 정렬 발생 | 성능(일반적으로) |
|---|---|---|---|
| UNION ALL | ❌ | ❌ | ★★★★★ (최고) |
| UNION | ✅ | ✅ | ★★★☆☆ |
| INTERSECT | ✅ | ✅ (2회) | ★★☆☆☆ (느림) |
🔍 쿼리 실행 흐름을 시각화하면?
쿼리 내부 동작을 시각화하면 이렇다:
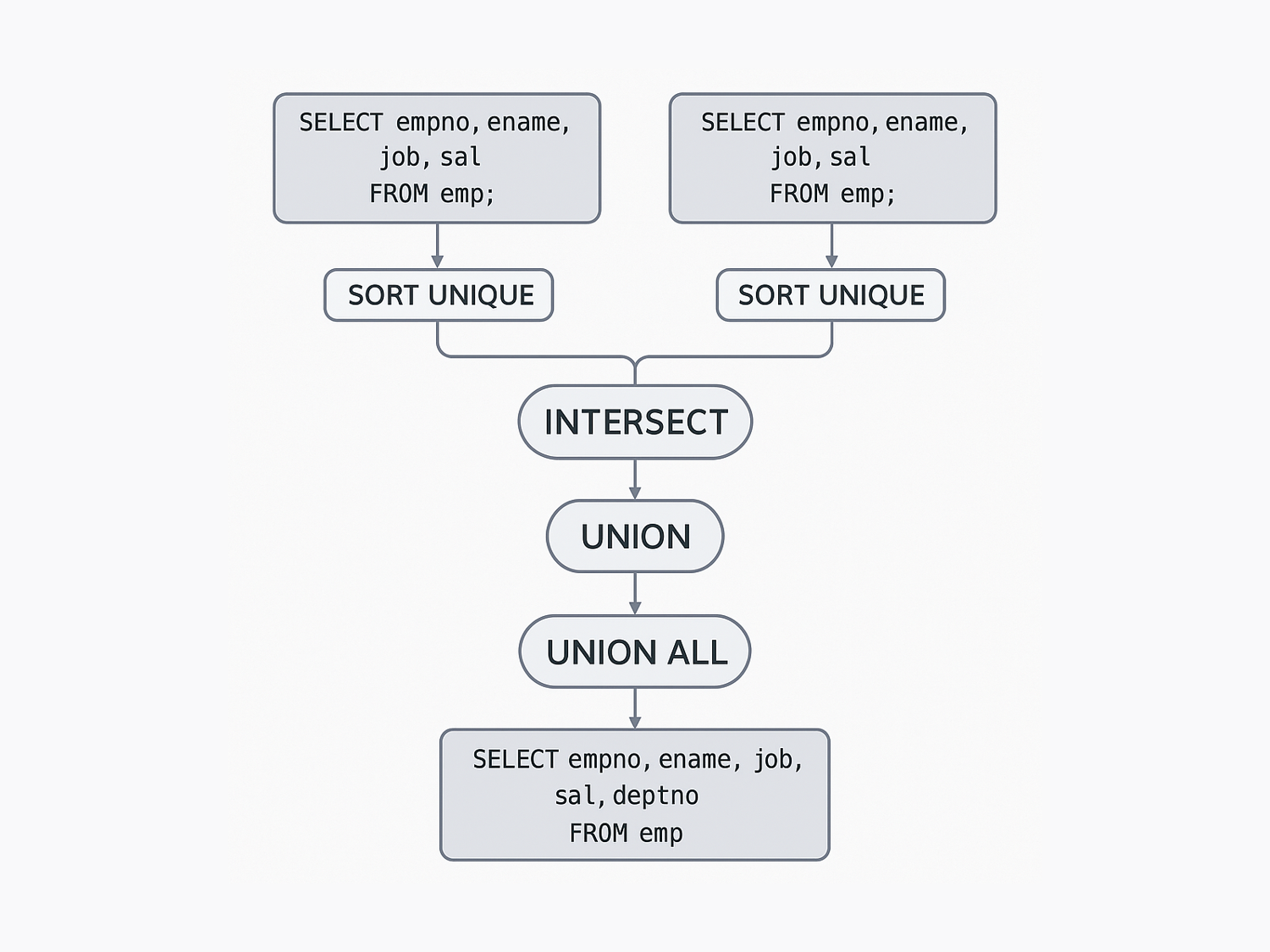
→ INTERSECT는 정렬 + 조인 등 처리량이 많고,
→ UNION은 그나마 단순하고,
→ UNION ALL은 말 그대로 가장 날 것 그대로 붙임
🧩 INTERSECT가 느린 이유
내가 찾아본 바로는, INTERSECT는 단순 비교가 아니라 다음 과정을 거친다:
- 각각의 SELECT 결과를 정렬(SORT UNIQUE)
- 그걸 다시 MERGE JOIN 또는 HASH JOIN으로 병합
즉, 정렬 두 번 + 조인 한 번의 부담이 생긴다.
쿼리 실행 계획(Explain Plan)상에서도 확실히 복잡해 보임.
반면 UNION은 정렬 한 번, UNION ALL은 정렬도 생략됨.
데이터가 많아질수록 성능 차이는 꽤 클 수밖에 없다.
🧪 직접 비교는 못 해봤지만...
내가 테스트한 건 아니지만,
다른 사람들이 비교한 예시들 보면
- INTERSECT 평균 실행 시간: 약 450ms
- WHERE 조건만 사용한 방식: 약 110ms
이라는 결과도 있음. 단순 조건 조합 쿼리가 4배 빠른 셈.
결과만 같다고 해서 효율도 같다고 착각하면 안된다는 것!
🧱 실수 방지 포인트
✅ INTERSECT, UNION, MINUS는
컬럼 개수, 순서, 타입이 완전히 같아야 한다.
-- 아래는 에러
SELECT empno, ename FROM emp
INTERSECT
SELECT empno FROM emp;→ 쿼리 잘 짰는데 실행 안 되면 이거부터 의심해봐야 한다.
🧭 상황별 쿼리 선택 가이드
| 상황 | 추천 방식 | 이유 |
|---|---|---|
| 단순 조건 조합 (AND / OR) | WHERE | 인덱스 타기 좋고 빠름 |
| 조건 나눠서 각자 조회 후 합치기 | UNION / UNION ALL | 중복 제거 여부에 따라 선택 가능 |
| 정확한 교집합 필요할 때 | INTERSECT | 단, 느릴 수 있음 |
| 교집합이긴 한데 성능이 중요할 때 | EXISTS / IN 서브쿼리 | 옵티마이저가 잘 튜닝함 |
📝 내가 정리한 핵심 요약
1) 결과가 같다고 효율도 같은 건 아니다.
2) INTERSECT는 정확한 비교엔 좋지만 비용이 크다.
3) 가능한 경우 WHERE 또는 UNION ALL을 먼저 고려하자.
4) 쿼리를 짤 땐 "이렇게도 되네?"보다 "이게 더 낫나?"를 먼저 생각하자.✅ 결론적으로
-
가능하면 UNION ALL을 먼저 고려하자.
→ 중복 제거 필요 없으면 이게 제일 빠름 -
INTERSECT는 정확하지만, 무겁다.
→ EXISTS나 IN으로 대체할 수 있으면 그렇게 하자 -
조건이 단순하면 WHERE로 끝내는 게 가장 효율적이다.
