
📖 학습한 내용
- project : 유튜브 조회수 예측 모델
📖 핵심내용
📌 project : 유튜브 조회수 예측 모델
유튜브 스크립트 분석
- 최자로드와 먹을텐데 크롤링으로 스크립트 수집
- 영문 스크립트를 분석

전처리
- 각종 특수문자 제거
- HTML의 문법 기호 제거
- 소문자 변환
- 공백 제거
- 숫자 제거, 서수 제거
- 돈 단위 제거
- 불용어 제거
- IDF 구해서 보고 제거
- 조회수를 정규화. (영상 조회수)/(채널의 최대조회수)
TF-IDF 적용 프로세스
-
TF-IDF로 각 스크립트의 단어를 벡터로 변환
-
단어들과 조회수와 상관관계를 구함
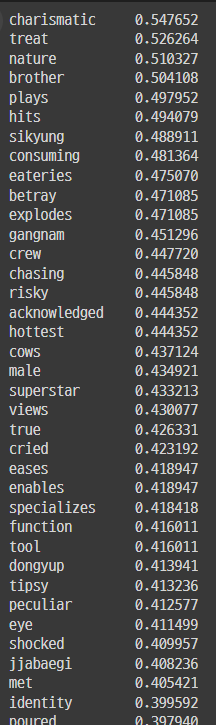
연예인 및 유명인 ('sikyung', 'dongyup', 'superstar') : 연예인이 출연하는 콘텐츠는 조회수와 상관관계가 있어보인다.
음식 관련 단어 ('eateries', 'cows', 'jjabaegi', 'offal', 'oxtail', 'entrials'): 고기나 특이한 식재료를 사용하는 음식이 조회수와 상관이 있어보인다.
음료 및 파티 문화 ('booze', 'tipsy', 'bottoms', 'hungover'): 음주와 관련된 콘텐츠가 조회수와 연관이 있을거라 생각된다. -
영상별 TF-IDF 높은 점수 단어 추출
추출하는 개수를 달리하면서 변화를 봄
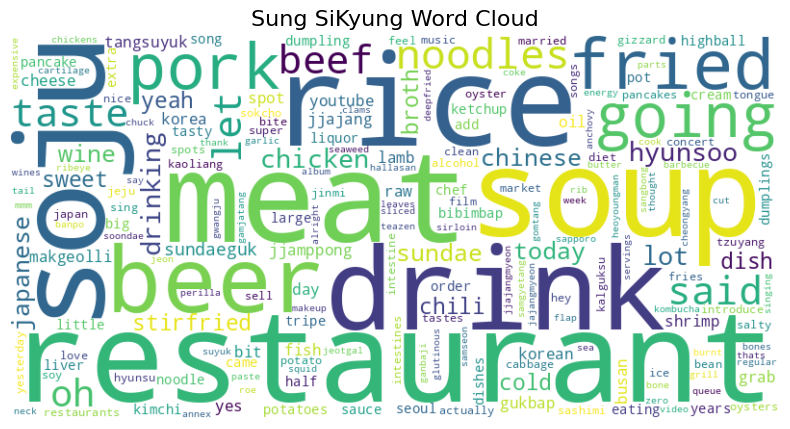
-> 영상별 어떤 말을 많이 했는지 파악 -
추출한 단어를 GPT 임베딩
추출한 단어를 GPT임베딩으로 임베딩하여서 의미상 비슷한 공간에 위치 -
클러스터링
영상별 단어들의 집합들이 서로 비슷한 것끼리 군집. 클러스터링의 개수는 실루엣 점수를 이용하여 정함.

-
클러스터링한 군집들과 조회수와의 관계를 살펴봄
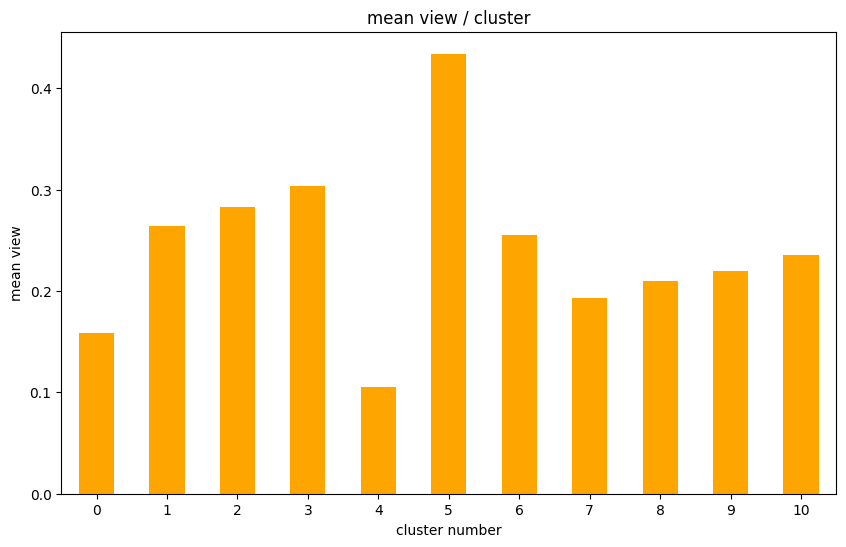
-> 군집에 속하는 영상들의 평균조회수를 측정 -
조회수와 관계가 높은 군집의 특징을 살펴봄
조회수와 관계가 높은 군집의 특성이 곧 조회수에 영향을 많이주는 특성이라고 간주할 수 있다.- 해산물 음식에 관련된 단어가 조회수와 많은 연관이 있을 것으로 추정
'jeotgal', 'flatfish', 'eel', 'sashimi', 'salt', 'busan', 'doenjang', 'fish', 'restaurant', 'hof', 'curry', 'chicken' - 음료와 술에 관련된 단어가 조회수와 많은 연관이 있을 것으로 추정
'beer', 'drink', 'wine', 'fridge', 'ice'
- 해산물 음식에 관련된 단어가 조회수와 많은 연관이 있을 것으로 추정
📖 흥미로운 점 / 새로 알게된 점
- 전처리할때 순서가 중요한 것을 알았다. 예를들면, 특수문자를 먼저 지우고 다른 이상한 문구를 지우려면 지워지지 않았다. '\\'n을 지우려 했지만 특수문자를 먼저 지워서 '\'이 지워져버려 'n'만 남았다. 그리고 이 n이 자연스럽게 단어처럼 행동해서 분석에 혼란을 줬다.
📖 어려운 부분
- 이름이나 메뉴이름은 고유명사인데, 띄어쓰기가 되어있는 경우 골치아팠다. 예를들면 성시경은 'Sung Si Kyung'으로 되어있는데 나중에 'Kyung'이 너무 많이 잡혀서 분석에 방해를 주는 요인이 되었다. 마찬가지로 조회수에 영향을 주고 있는만큼 이름을 잡아내는 것이 중요했는데, spacy의 NER로 PERSON을 잡아내려했지만, 정말 이상한 것을 많이 알려줘서 걸러내느라 시간이 오래걸렸다. 결국에는 내가 수작업으로 일일히 했어야했다. 띄어쓰기가 섞인 고유명사의 띄어쓰기를 없애느라 상당히 공이 많이 들어갔다.

📖 이후 학습 계획
- LDA로 주제 탐색 활용

설계엔지니어의 변신