CoreData
코어 데이터는 모델 편집기를 통해 데이터의 유형과 관계를 정의하고 해당 클래스의 정의를 자동으로 생성할 수 있다.
또한 다음과 같은 기능을 수행해준다.
Persistence
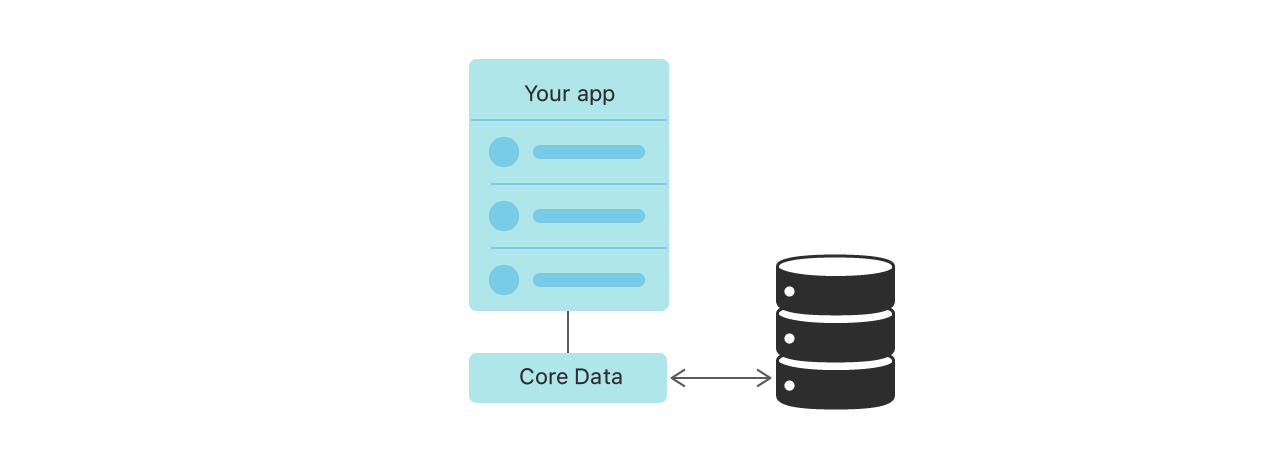
코어 데이터는 객체를 저장소에 매핑하는 세부사항을 추상화하여 데이터 베이스를 직접 관리하지 않아도 쉽게 저장 가능하도록 만들어준다.
여기서 추상화해준 세부사항은 데이터 저장소 타입 관리, 객체 관계 매핑, 데이터 일관성 및 무결성, Managed Object Context를 통한 변경사항 관리 등이 있다.
개발자가 데이터를 생성하거나 수정할 경우 먼저 MOC에 저장된다. 이후 MOC에서 PSC(Persistent Store Coordinator)를 통하여 PS(Persistent Store)와 상호작용한다.
PS는 실제로 데이터를 저장하는 저장소로 SQLite가 가장 일반적이며 이는 주로 기기의 디렉토리(ex.Libarary/ApplicationSupport)에 저장된다.
Undo and Redo
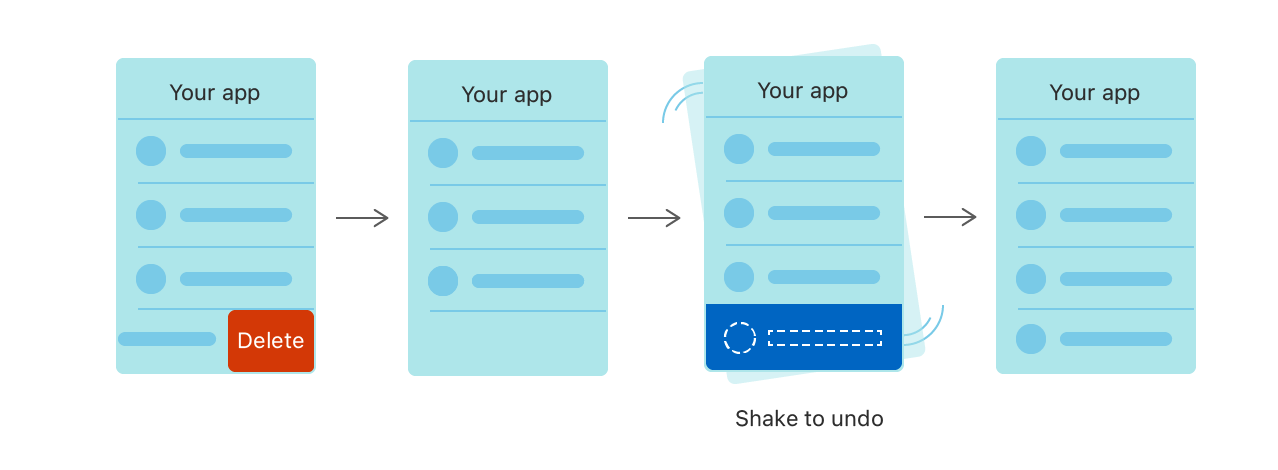
변경 사항을 추적하여 개별적으로 또는 그룹 단위로 또는 전부 다 되돌릴 수 있다.
이 덕분에 간단하게 실행 취소와 되돌리기 기능을 만들어낼 수 있다.
Background data task
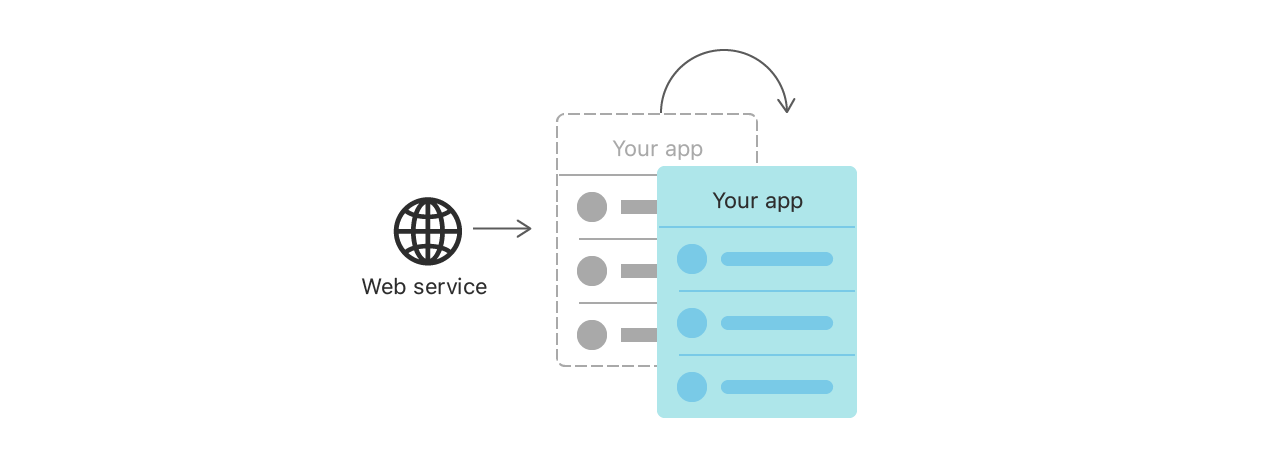
JSON 객체를 파싱하는 것처럼 UI를 중단시킬 수 있는 작업을 백그라운드에서 처리할 수 있게 해준다. 또 결과를 캐싱하거나 저장하여 서버 왕복 요청을 줄일 수 있으며 이번에 사용하게 될 포켓몬 api의 사용 설명에도 불필요한 요청을 줄일 수 있게 캐싱을 하라고 적혀있었다.
View synchronization
테이블 뷰 및 컬렉션 뷰 등에 데이터 소스를 제공하여 데이터와 뷰의 동기화 상태를 유지하는데 도움을 줄 수 있다.
Setting up Core Data
코어 데이터는 프로젝트 생성 시 저장소 관련 옵션에서 선택하여 관련 파일과 코드를 생성한 채로 시작할 수 있다.
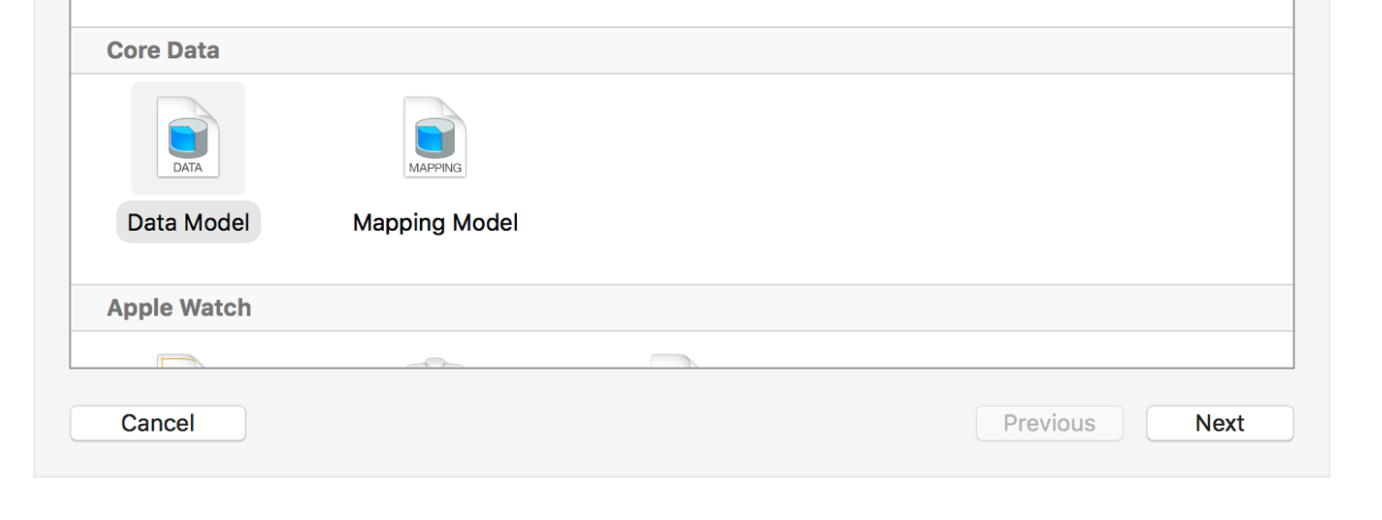
만약 코어데이터가 없는 기존 파일에 추가하고 싶다면 새 파일 만들기에서 DataModel 템플릿의 파일을 하나 생성하고 이후 작업을 처리하면 된다.
Core data Stack
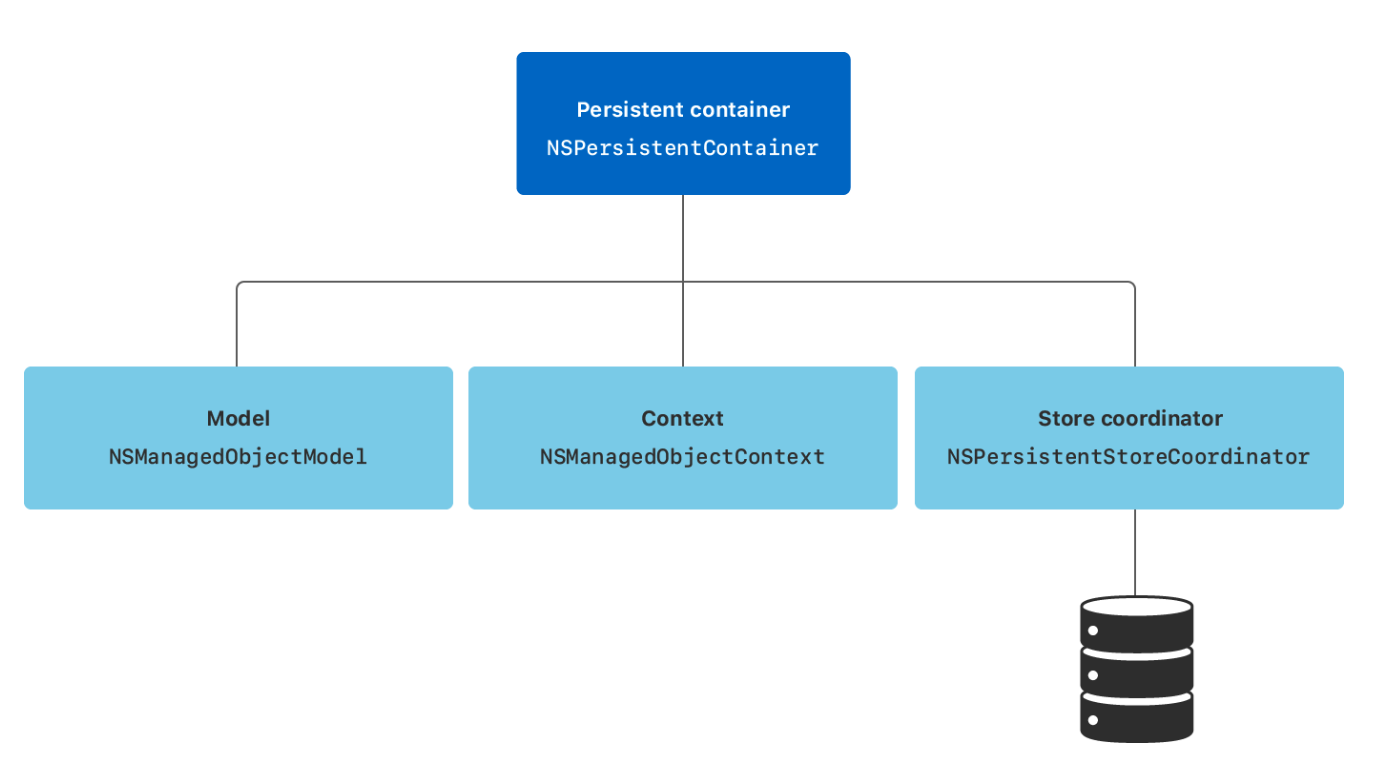
Core Data Stack이란 앱의 모델 계층을 공동으로 지원하는 클래스로 다음과 같은 요소들로 이루어져있다.
NSManagedObjectModel
NSManagedObjectModel은 애플리케이션의 데이터 모델을 정의하는 객체로 엔티티, 속성, 관계 등의 정보를 포함한다. 이는 데이터 베이스의 스키마와 같은 역할을 한다는 뜻.
관리 객체 모델은 .xcdatamodeld파일에서 설정되며 런타임 시 로드되어 NSManagedObjectModel 객체로 변환된다.
NSManagedObjectContext
NSManagedObjectContext는 CoreDataStack의 작업 공간으로, 변경 사항을 추적하고 필요할 경우 save()를 호출하여 영구 저장소에 저장한다.
여러 컨텍스트를 동시에 처리할 수 있어 병렬 처리와 작업 분리 등에 유리하다고 한다.
NSPersistentStoreCoordinator
NSPersistentStoreCoordinator는 데이터 저장소를 추가 및 관리하며 관리 객체 컨텍스트의 요청을 실제 저장소와 전달하고 상호작용한다. 이 덕에 SQLite 같은 저수준 데이터 베이스에 대한 직접적인 조작 없이도 데이터를 처리할 수 있다.
또한 SQLite와 inMemory를 동시에 사용하는 등 여러 저장소를 동시에 사용할 수도 있다.
NSPersistentContainer
NSPersistentContainer는 CoreDataStack의 설정을 단순화하고 관리하기 위한 고수준 API로 앞서 말한 요소를 모두 포함하고 초기화 할 수 있도록 돕는다.
CoreDataStack의 생성과 접근, 관리 객체 컨텍스트에 대한 접근, 비동기 초기화 등이 가능하다.
애플 공식 문서처럼 CoreDataStack을 직접 선언하는 경우엔 싱글톤 패턴으로 만드는 경우가 일반적이라고 한다.
일반적으론 프로젝트를 만들 때 CoreData를 선택하면 자동으로 생성해주는 NSPersistentContainer를 사용해도 되지만
- 더 세부적인 제어가 필요한 경우(편의 메서드나 확장 기능을 추가할 때)
- 이전 버전 운영체제를 지원하기 위한 경우
- 커스터 마이징이 필요한 경우
- SRP를 준수하고 코드 가독성을 높이고 싶은 경우
위와 같은 경우엔 직접 정의하여 사용하는 것이 더 좋다.
CoreData 스택을 설정할 때는 데이터 모델의 버전관리와 데이터 일관성 유지 등을 고려애햐 하고 CoreDataStack의 구성 요소들은 앱의 생명주기와 밀접하게 관련있기 때문에 앱의 시작과 종료 시점에서 적절한 초기화와 정리 작업이 필요하다.
그래야 데이터의 무결성을 유지하고 안정적인 동작을 보장할 수 있기 때문.
How to use
CoreDataStack을 사용하기 위해 파일을 새로 만들고 싱글톤으로 만든 뒤 여러 편의 메서드를 정의해보겠다.
CoreDataStack에서 NSPersistentContainer를 따로 정의해줄 것이기 때문에 자동으로 생성되었던 NSPersistentContainer는 삭제해준다.
NSPersistentContainer

먼저 NSPersistentContainer에 .xcdatamodeld파일의 이름을 넣어 기반이 데이터 모델을 연결해준다.
NSPersistentContainer 객체를 만드는 과정에서 메서드 loadPersistentStores를 사용한다.
이 메서드는 영구저장소를 초기화 하고 데이터 모델과 실제 저장소 파일을 연결해준다.
또한 용량 부족이나 권한 문제 등으로 저장소 파일이 없거나 접근 불가할 때 에러를 반환해준다.
(간단히 영구저장소를 준비하는 과정으로 실제 배포 앱에선 에러가 발생한 경우 사용자에게 알리거나 복구를 시도하는 등 적절하게 에러처리를 해주어야 한다고 기본 코드에 적혀있다.)
추가로 이 과정에서 기본 viewContext가 생성된다.
viewContext

다음으론 context를 설정해준다. 앞서 나왔던 MOC로 PersistentContainer가 가진 viewContext를 할당해줄 건데 viewContext는 다음과 같은 특징이 있다.
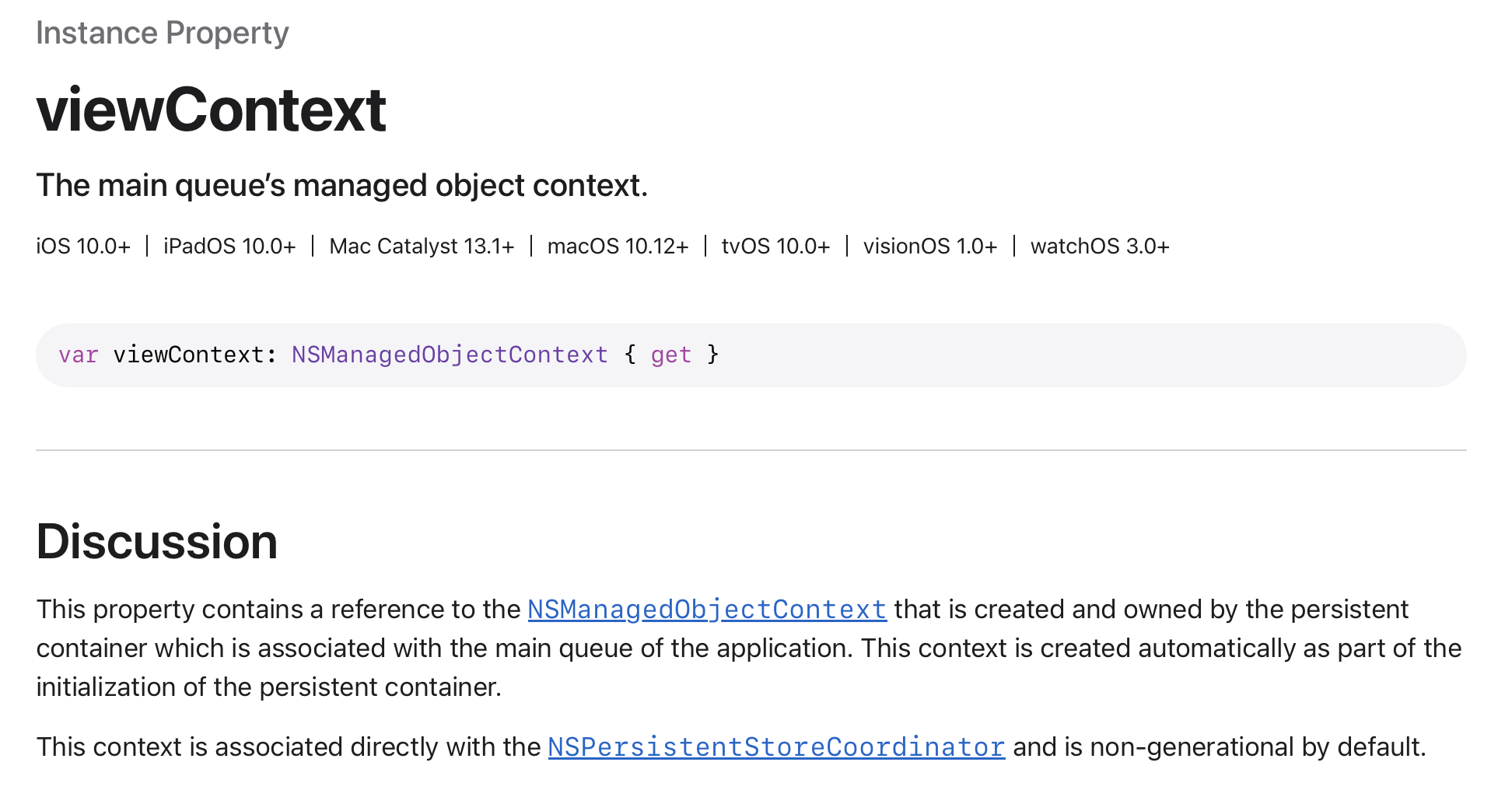
앞서 말했듯 persistent contianer를 초기화 하는 과정에서 자동으로 생성된다.
그리고 NSPersistentStroeCoordinator와 연결되어있으며 앱의 메인 큐와 연관되어 있다. 즉 메인 스레드에서 처리된다는 의미이고 UI와 관련된 작업에 적합하다는 뜻이 된다.
또한 PSC와 연결되어 있기 때문에 이를 통한 데이터 작업이 가능하다.
context.save()
이제 context가 가진 save()와 다른 속성들을 이용해 변경 사항을 저장하는 메서드를 만들어야 한다.
save()의 선언부를 들어가보면 다음과 같이 throws가 적혀있다.
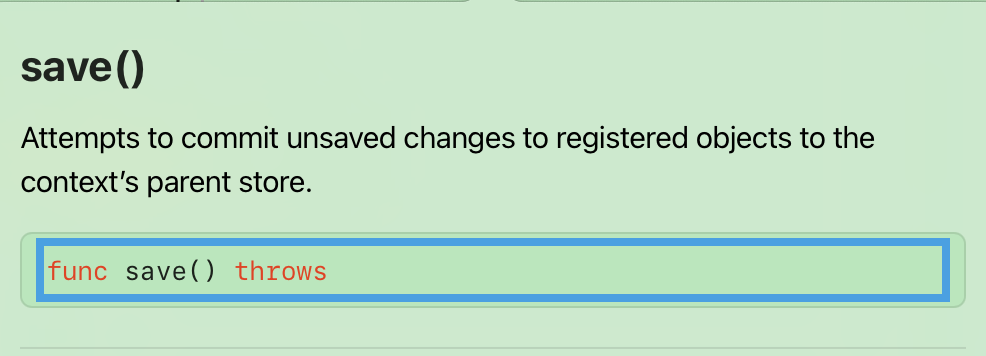
이는 데이터 저장 작업이 여러 외부 요인에 의존하기 때문에 예상치 못하게 실패할 가능성이 많기 때문이다.
실패 요인은 필수 속성 값이 nil이거나 영구 저장소에 접근할 수 없거나 동일한 데이터를 동시에 변경하려고 시도했거나 데이터 모델이 저장소의 스키마와 동일하지 않는 등의 이유가 있다.
다양한 요인을 알고 있어야 각 상황에 맞는 적절한 에러처리가 가능하기 때문에 실패 요인을 숙지하는 것도 앱의 완성도를 높이는데 중요한 부분 중 하나인 거 같다.

지금은 동작을 구현해보는 게 우선이라 프린트문만 적어서 처리해보았다.
add
이제 context를 통해 데이터 작업을 할 수 있게 되었으니 기본적인 데이터 조작에 관한 메서드를 만들어서 사용하면 된다.

이번에 본 강의에서는 위와 같은 형식으로 Entity와 context를 바탕으로 새로운 객체를 생성하고 key를 통해 해당 값을 지정해주는 방식으로 배웠다.
그러나 String을 하드코딩으로 넣어주는 방식을 개선하기 위한 방법을 알아보다 다음과 같은 선언을 보게 되었다.

이는 NSManagedObject의 서브클래스를 사용하는 방식으로 .xcdatamodeld파일에서 자동으로 만들어주는 파일을 보면 다음과 같이 NSManagedObject를 상속받고 있다.

이렇게 생성한 객체의 속성은 @NSManaged를 통해 제공되기에 문자열 하드코딩을 피할 수 있게 된다.

오류 발생 시점이 런타임에서 컴파일타임으로 변경되었고 유지보수가 쉬우며 간결해진 코드로 가독성 또한 증가한다.
또한 초기화 시 context: context로 NSManagedObjectContext를 주입해주기 때문에 추가설정 없이 해당 컨텍스트를 바로 사용할 수 있다.
다만 완벽히 대체되는 것은 아니다.
엔티티 이름이 런타임에서 동적으로 변경되어야 하거나
하위 호환성을 위해서 또는 직관적으로 객체 생성의 동작 원리가 어떻게 되는지 보다 쉽게 이해하기 위해서 등의 이유로 기존 방식을 차용해야 할 수 있다.
그러나 대체적으로는 좀 더 현대적인 스위프트 스타일인 서브클래스 활용으로 코딩한다고 한다.
fetch
데이터를 가져오는 메서드도 작성해보겠다.

강의에서도 컨텍스트에 존재하는 fetch()에다 자동 생성 된 fetchRequest()를 활용했다.
자동 생성 된 부분을 살펴보면 다음과 같이 정의되어 있다.

데이터와 연결 되어야 하는 엔티티 네임을 넣어주어 생성한 NSFetchRequest<ContactData>를 반환해준다.

반환되는 타입에 대한 퀵 헬프를 보면 NSPersistentStoreRequest를 상속하고 ResultType는 NSFetchRequestResult를 준수해야 한다고 되어있다.
NSPersistentStoreRequest를 준수하였기에 영구저장소와 통신할 수 있다.
추가적으로 준수해야 하는 NSFetchRequestResult는 NSManagedObject의 정의를 찾아갔을 때 준수하고 있다는 것을 확인할 수 없었다.

대신 이 메서드와 NSFetchRequest의 제네릭 타입 조건을 이용해 NSManagedObject가 NSFetchRequestResult를 준수하고 있다는 걸 간접적으로 알 수 있다.
처음엔 NSManagedObject에 정의 된 fetchRequest()만 보고 NSManagedObject와 fetchRequest()의 반환 타입이 NSFetchRequestResult를 준수해야 하는 것이 무슨 관련이 있다는 건지 이해를 못했으나 가장 위에서 fetchRequest가 구현된 부분을 보고 왜 간접적으로 준수하고 있다는 게 증명되는지 알 수 있었다.
만약 NSManagedObject가 NSFetchRequestResult를 준수하고 있지 않았다면 return NSFetchRequest<ContactData>(entityName: "ContactData")에서 컴파일 에러가 발생했을 것이다.

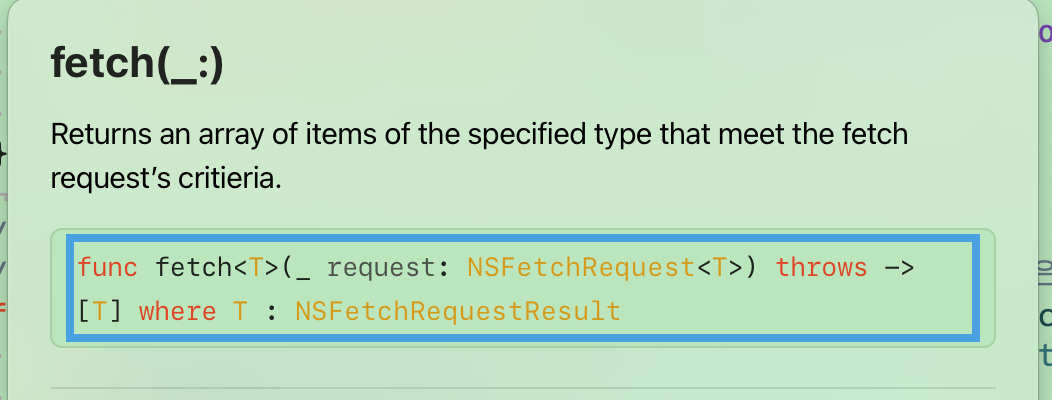
이제 fetchRequest를 활용하여 context가 가진 fetch()를 사용한다.
fetch는 context와 연결 된 PSC와 연관 된 영구 저장소에서 객체를 가져오며 context에 등록한다.
따로 조건이 없다면 지정된 엔티티의 모든 인스턴스를 반환해준다.
추가로 주의할 점이 몇 가지 있다.
- 각 객체의 메모리 상태(in memory state)를 평가하는데 때문에 변경이 저장되지 않은 객체도 조건에 따라 포함되거나 포함되지 않을 수 있다.
- 컨텍스트에서 삭제 된 객체는 저장소에 삭제 여부가 반영되지 않았더라도 검색 결과에서 제외된다.
- 메모리에 이미 로드 된 객체나 변경 중인 객체에 대해선 새로운 인스턴스를 생성하지 않는다. 이미 fetch를 실행하고 수정한 후 다시 fetch를 수정하더라도 새로운 객체가 아닌 메모리에 올라간 객체를 반환받는다는 말.
update
다음은 기존 값을 새로운 값으로 수정하는 메서드를 작성해볼 간것이다.
그 전에 새로운 데이터를 저장할 때나 업데이트 할 때 만약 수정해야 할 속성이 많아진다면 그 많은 속성을 전부 매개변수로 받는 게 맞는가 하는 의문이 들었다.
클린 코드에서는 매개변수를 늘리지 않는 것이 좋다고 적혀있기도 했고 실제로 내가 사용하며 느끼기에도 3~4개가 되면 많다고 생각됐다.
처음엔 바로 ContactData 객체를 만들어 전달하면 안 되나 생각했지만 ContactData는 NSManagedObject를 준수하고 있어서 컨텍스트에 대한 의존성이 존재하고 잘못된 컨텍스트로 연결하면 오류가 발생할 수도 있으며 유효성 검증 로직도 따로 작성해주어야 한다고 한다.
대안으로 딕셔너리 전달, 요청에 대한 속성을 캡슐화 한 구조체, 빌더 패턴 등이 존재했다.
구조체를 만드는 건 ContactData를 바로 생성하는 대신 필요한 속성만을 가진 구조체를 새로 정의하여 사용하는 방식이다.
모든 속성을 캡슐화하는 과정이 조금 더 시간이 소요된다.
빌더 패턴은 객체 생성과 수정을 처리하는 클래스를 새로 정의하는 것으로 좀 더 규모가 큰 프로젝트에서 자주 사용된다고 한다.
내 프로젝트는 너무 작고 작지만 그래도 새로운 패턴을 겪어보는 것이 좋으니 빌더 패턴에 대해서 중점적으로 알아보고 사용했다.
builder
빌더 클래스를 코어데이터와 연계하여 사용하기 위해 빌더의 이니셜라이저를 통해서 컨텍스트를 주입 받아 컨텍스트와의 의존성을 낮추고 경우에 따라 새로운 NSManagedObject 서브 클래스 객체를 만들거나 기존 객체전달 받고 내용을 업데이트하여 다시 반환할 것이다.
빌더는 객체의 속성을 정의하는 메서드를 점표기법을 이용한 체이닝 방식으로 사용할 수 있게 제공하며 최종적으로 객체를 반환하는 build() 메서드를 포함한다.
이를 코드로 작성하면 다음과 같다.

속성을 바꾸는 메서드가 다시 자기 자신을 반환하여 체이닝 방식으로 속성을 간결하게 넣어줄 수 있다.
각 단계가 명확히 분리 되어 가독성이 좋고 속성을 선택적으로 설정할 수 있기 때문에 유연하다.
또한 하나의 인터페이스로 추가와 수정이 가능해진다.
지금처럼 작은 프로젝트에서는 과한 설계일 수 있으나 더욱 생성과 설정이 복잡해지거나 캡슐화를 반드시 해야 할 때, 재사용성과 유지보수성이 중요해지는 중대형 프로젝트 등에서는 보다 효과적인 패턴이라고 한다.
아 그리고 코어데이터와 연계하는 경우엔 반드시 build()를 사용하지 않아도 된다.
만약 코어 데이터와 독립된 객체가 필요하거나 생성한 객체를 반환할 필요가 있는 경우엔 필요하지만 컨텍스트가 정해진 객체를 빌더 내부에서 바로 생성하고 수정한 뒤 저장까지 이어지는 사용에서는 필요하지 않다.
아무튼 빌더는 위와 같은 구조로 만들어나가면 되는데 주의할 곳은 클라이언트 코드이다.
빌더를 이용해 앞서 작성했던 add 메서드를 수정하면 다음과 같아진다.

여기서만 봤을 땐 속성을 어떻게 정의해야 할지 감이 안 온다.
클로저를 사용하는 코드는 아직도 직관적으로 머리에 들어오지 않는다.ㅠ
코드를 살펴보면 매개변수로 빌더를 매개변수로 받는 클로저를 받는다.
내부에선 NSManagedObjectContext에 앞서 설정한 NSPersistentContainer의 viewContext를 넣어주어 확실히 동일한 컨텍스트에 접근되도록 한다.
이후 매개변수로 전달받은 클로저에 빌더를 넣고 실행하는데
호출하는 곳에서 클로저를 통해 속성을 지정해주면 해당 메서드들이 실행된 뒤 다시 함수로 돌아와서 saveContext()가 실행된다.
이제 해당 메서드를 다음과 같이 사용하면 된다.
CoreDataStack.shared.addContactByBuilder { builder in
builder.setName(to: "Bom")
.setPhoneNumber(to: "111-1234")
}매개변수로 전달받은 클로저에 원하는 컨텍스트 또는 객체를 넣은 뒤 클로저를 실행하여 속성을 정의한다. 계속해서 빌더 자신이 반환되기에 체이닝으로 연결한다는 장점이 잘 나타나는 것 같다.

빌더를 활용해 update 메서드도 간단히 구현했는데 살펴보면 add 메서드와 동일한 코드로 이루어져있다.
즉 중복되는 코드이기 때문에 add와 create를 하나로 합칠 수 있으나 분리하는 것이 중복되는 것보다 좀 더 맞는 선택이라 생각하여 분리했다.
delete
마지막으로 저장되어 있는 데이터를 삭제하기 위한 메서드이다.

데이터를 전달받고 컨텍스트에서 해당하는 데이터를 삭제해주는 delete()를 사용하면 간단하게 처리된다.
delete()는 위의 설명대로 컨텍스트에서 먼저 제거하고 save()를 호출하여 변경 사항이 영구 저장소에 커밋될 때 삭제가 완료된다.
혹시 relationship이 설정되어있다면 관련 객체를 삭제하는 cascade delete rule을 설정해주어 조정할 수 있다.
드디어 코어데이터를 이용한 CRUD가 끝이 났다...

13개의 댓글

교수님 저는 수강변경 할게요
와 근데 delete 저렇게 쉽게 되는 거였다고..? id 값으로 fetch request로 불러와서 지우고 난리 쳤는데😮

빌더 멋있어보여서 따라하려다가 지쳐서 포기.. 대신 교수님 덕분에 알게 된 NSManagedObjectID를 활용하는 건 해봤어요! 감사합니다 교수님
봄이 아빠님 CoreData 마스터짱!!!