Building Airbnb Categories with ML and Human-in-the-Loop
Airbnb Categories Blog Series — Part I
출처: https://medium.com/airbnb-engineering/building-airbnb-categories-with-ml-and-human-in-the-loop-e97988e70ebb
😈 데이터블로그 챌린지 2일차😈 입니다.
데이터사이언스 블로그를 운영하는 '에어비앤비(Airbnb)'의 에어비앤비 카테고리 서비스 시리즈1 편을 알아보았습니다.
요약
- 에어비앤비에서는 여행자가 검색할 생각을 하지 못했던 독특하고 특별한 숙소를 예약할 수 있도록 유도하고자 사용자 여행검색 경험을 혁신함
- 에어비앤비에 존재하는 모든 숙소 리스트를 56개의 카테고리로 분류 하기로 함. 이 과정에서 human-in-the-loop system을 활용한 머신러닝 모델을 도입
- 숙소 상품에 특정 카테고리에 해당하는 빈도가 높을수록 고득점 => 카테고리 점수가 높다면 사람이 검토 => 코사인 유사도를 활용하여 10개의 이웃을 동일 카테고리에 할당 => 잘못 할당된 카테고리는 다시 ML모델에 반환하여 재할당 ( quality ML, cover image ML 등 다양한 모델과 로직을 사용 )
- 내 생각: 고객에게 맞춤형으로 특별한 경험을 선사하기 위해 이런 기능을 만들어냈다는것이 놀랍다. CX(customer experience) 및 개인화에도 부합하는 멋진 도전이라고 생각한다.
특히, 머신러닝 모델을 완벽하게 만드는데 집착하는 것이 아니라, 사람의 개입을 최소화하면서도 다양한 카테고리 기준과 랭킹 알고리즘을 통해 서비스를 고도화함으로써 기존에는 없던 차별화된 검색기능을 완성했다.
어제 살펴본 쏘카AI세차에서도 주관적이다/애매하다 라는 한계 때문에 기준을 정하고 시스템을 정의하기가 어려웠다. 오늘 살펴 본 에어비앤비에서는 '점수화'하여 점수가 높을 때만 사람이 판단하는 단계가 존재하고, 부적절한 경우 반환하여 재학습하는 단계가 있으며, 사진등급을 보조해주는 머신러닝 모델도 구축되어 있기 때문에 중요한 최종판단을 사람에게 맡기면서도 최소한으로 개입하도록 설계하여 알고리즘의 효율과 정확도를 높였다는 점이 인상적이다.
내용
에어비앤비 기존 카테고리별 검색:
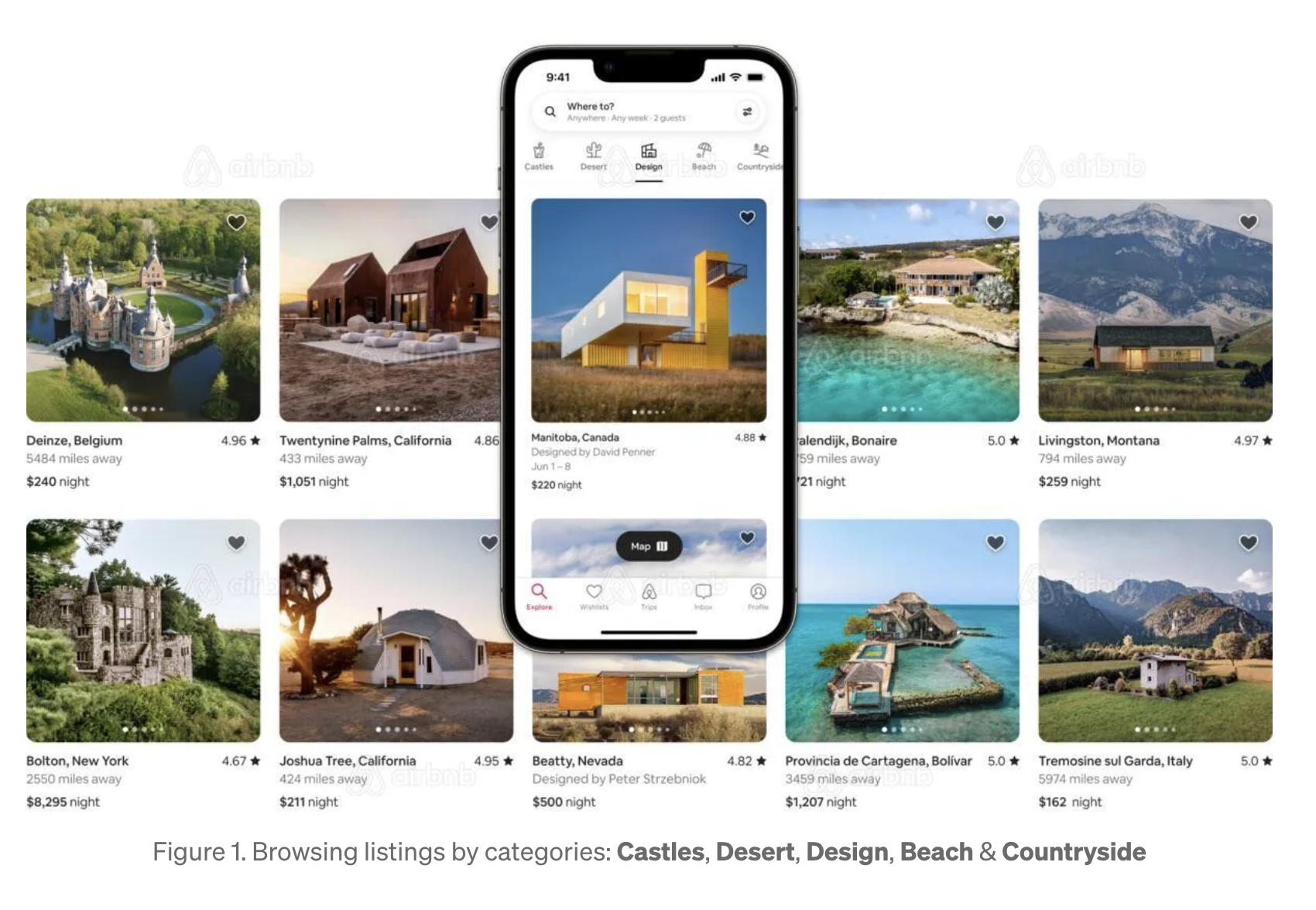
- 전통적인 여행지 검색: 목적지, 날짜, 인원 수
- 에어비앤비의 개선된 필터링 및 개인화 기능: 유연한 날짜 검색, 근처 위치 제안
but, 여행자가 특정 목적지를 지정해야함
최근 릴리즈 된 기능
알려지지 않은 특별한(unique) 숙소 정보를 제공
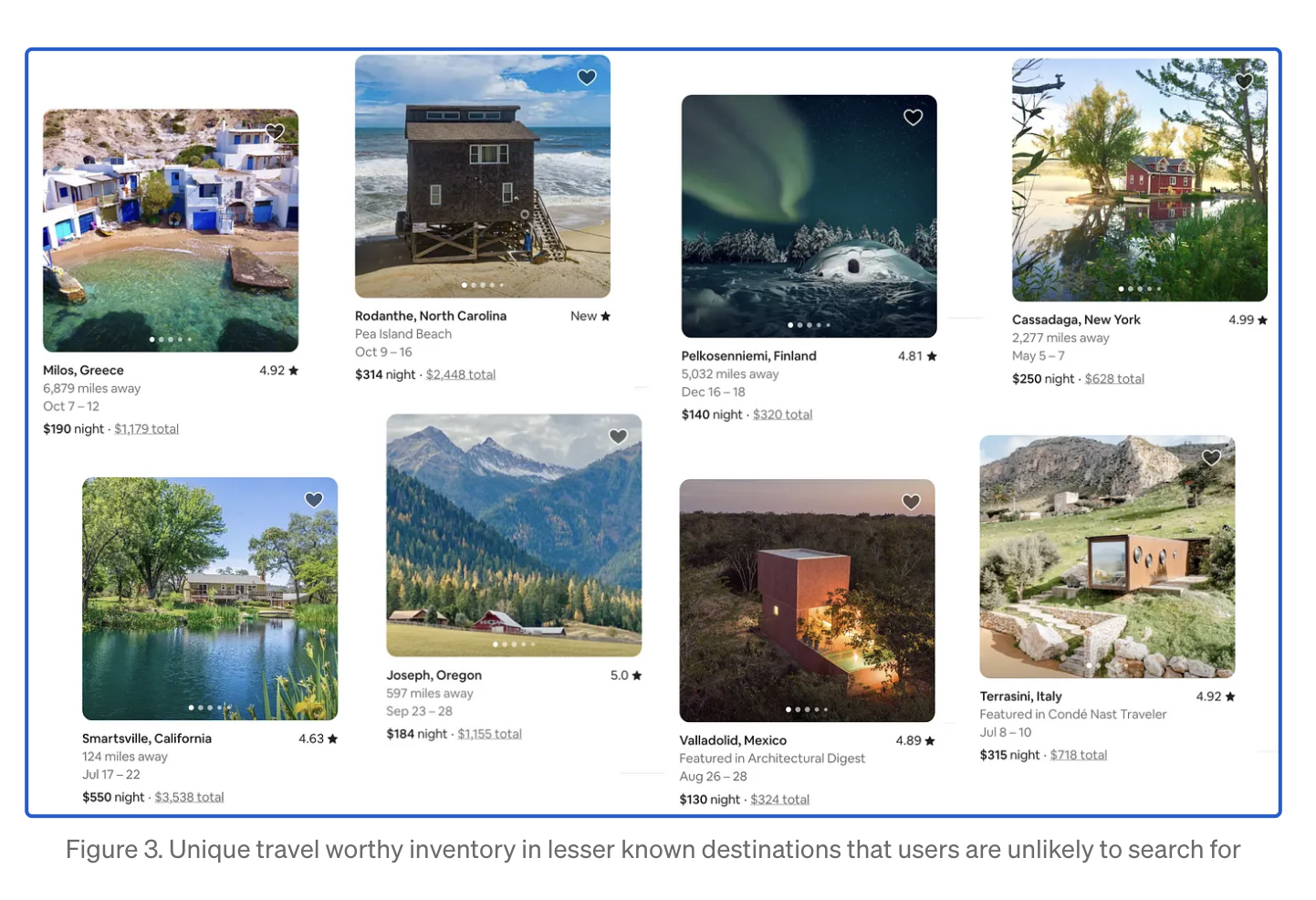
숙소 리스트를 카테고리로 그룹화 하게 된 배경
- 특별한 숙소 목록을 위해 새로운 '에어비앤비 카테고리' 구축
=> 56개의 카테고리를 정의하고 , 전체 숙소 상품 리스트를 카테고리에 맞게 할당해야 함
=> but, 시간과 비용이 많이 소모 됨 & 인간이 설정한 Label 없이 정확한 머신러닝 모델 생성 불가능
=> 인간 참여형(human-in-the-loop) ML모델을 만들자 !
1. 관심장소(POI- place of interest) 중심 (ex) 해안, 호수, 북극, 사막)
2. Activity 활동 중심 ( ex) 골프, 캠핑, 스쿠버, 와인 시음)
3. home type 주택 유형 중심 ( ex) 풍차, 통나무집, 동굴 )
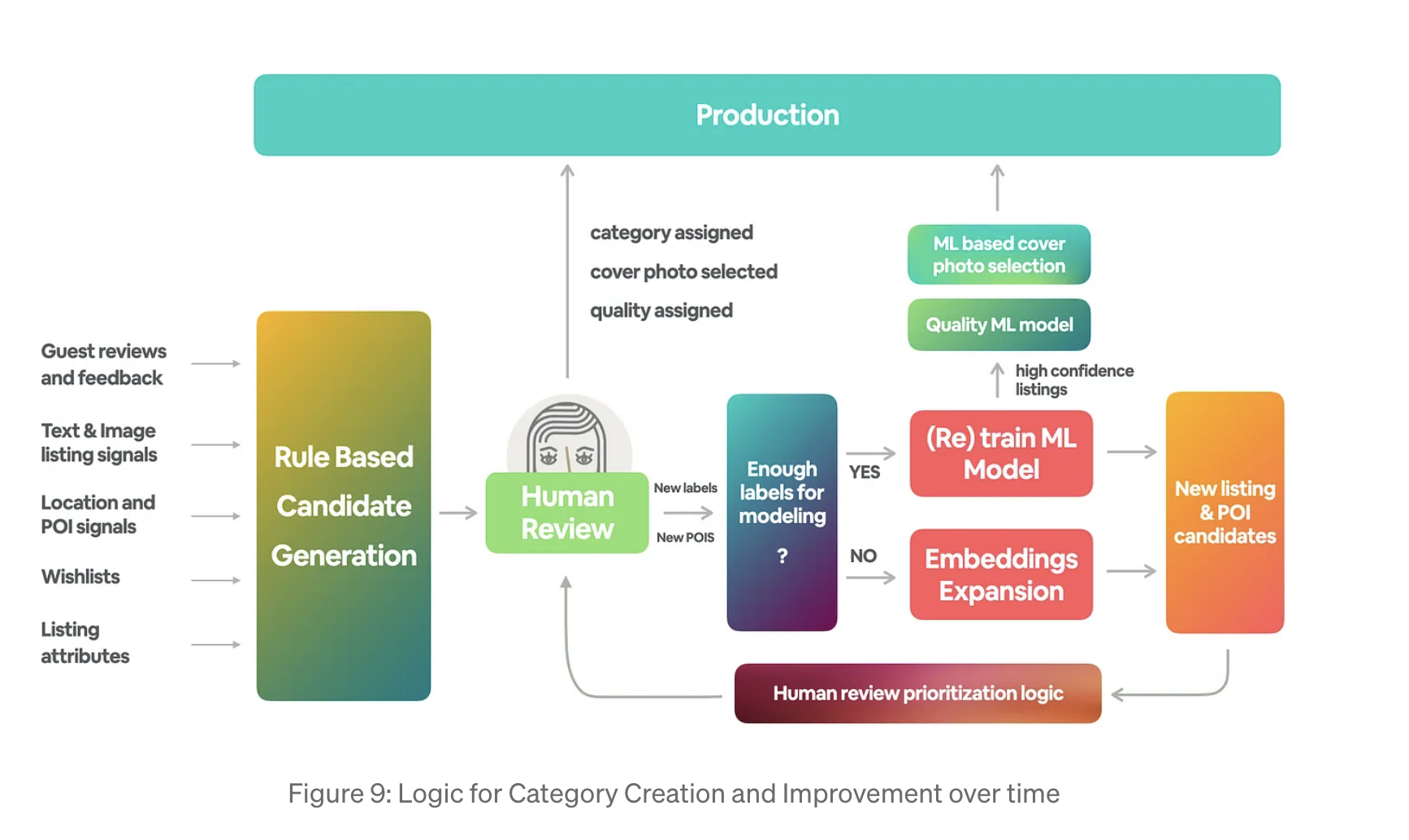
4. home amenity 주택 편의시설 중심 (ex) 수영장, 그랜드 피아노, 고급 주방) HITL system을 위한 여러단계 : Rule Based Candidate Generation
- weighted sum of indicators: 숙소 상품 리스트에 특정 지표가 많을수록 특정 카테고리에 속할 확률이 높아짐
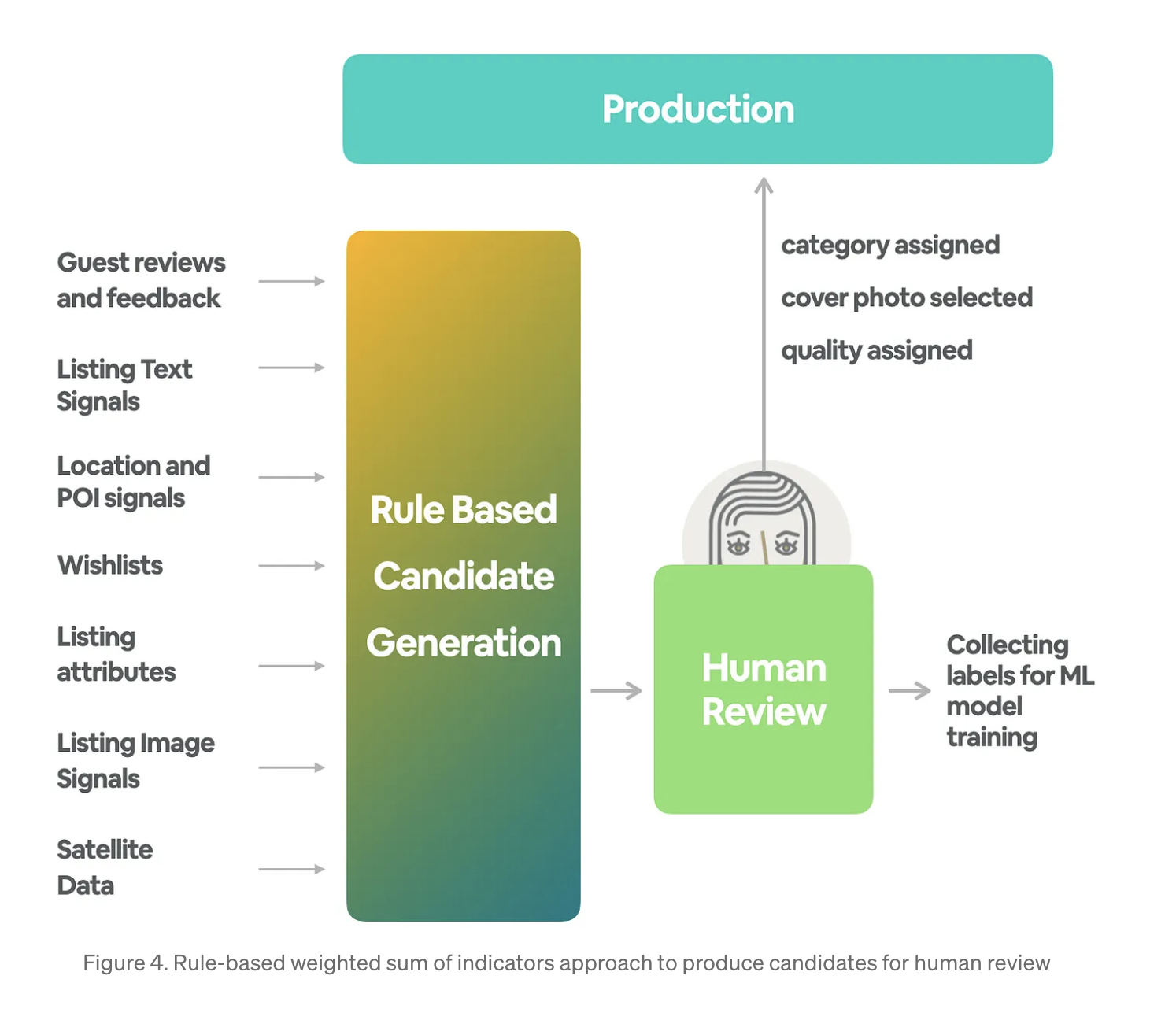
( ex) 호수 POI에서 100m 이내에 위치하고, 숙소 제목과 투숙객 리뷰에 '호숫가'라는 키워드가 언급되고, 숙소 사진에 호수 전망이 나타나며, 근처에서 여러 카약을 즐길 수 있는 숙소 => Lakefront 카테고리 점수가 높다
=> 숙소 리스트- 카테고리 쌍이 사람이 검토할 강력한 후보가 될 것 )
- human review
- 숙소 리스트에 할당된 카테고리를 확인하거나 거절함
- 카테고리를 가장 잘 나타내는 사진을 선택함 (표지 이미지)
- 사진의 품질등급을 결정 ( 최고품질, 고품질, 보통 품질, 저품질)
- 데이터베이스에서 누락된 POI 추가 가능
- candidate expansion
사전 훈련된 목록 임베딩을 활용하여, 사람이 숙소 리스트가 특정 카테고리에 속한다는 확인을 끝내면, 코사인 유사도를 통해 유사한 숙소 리스트를 찾을 수 있음
코사인 유사도에서 가장 가까운 10개의 이웃이 동일 카테고리에 대한 좋은 후보인 경우가 많음

- Training ML Models
숙소 리스트가 특정 카테고리에 속하는지 여부를 예측하는 이진분류 모델을 학습.
holdout 세트를 사용하여 PR(precision-recall) 커브를 이용하여 모델 성능을 평가.
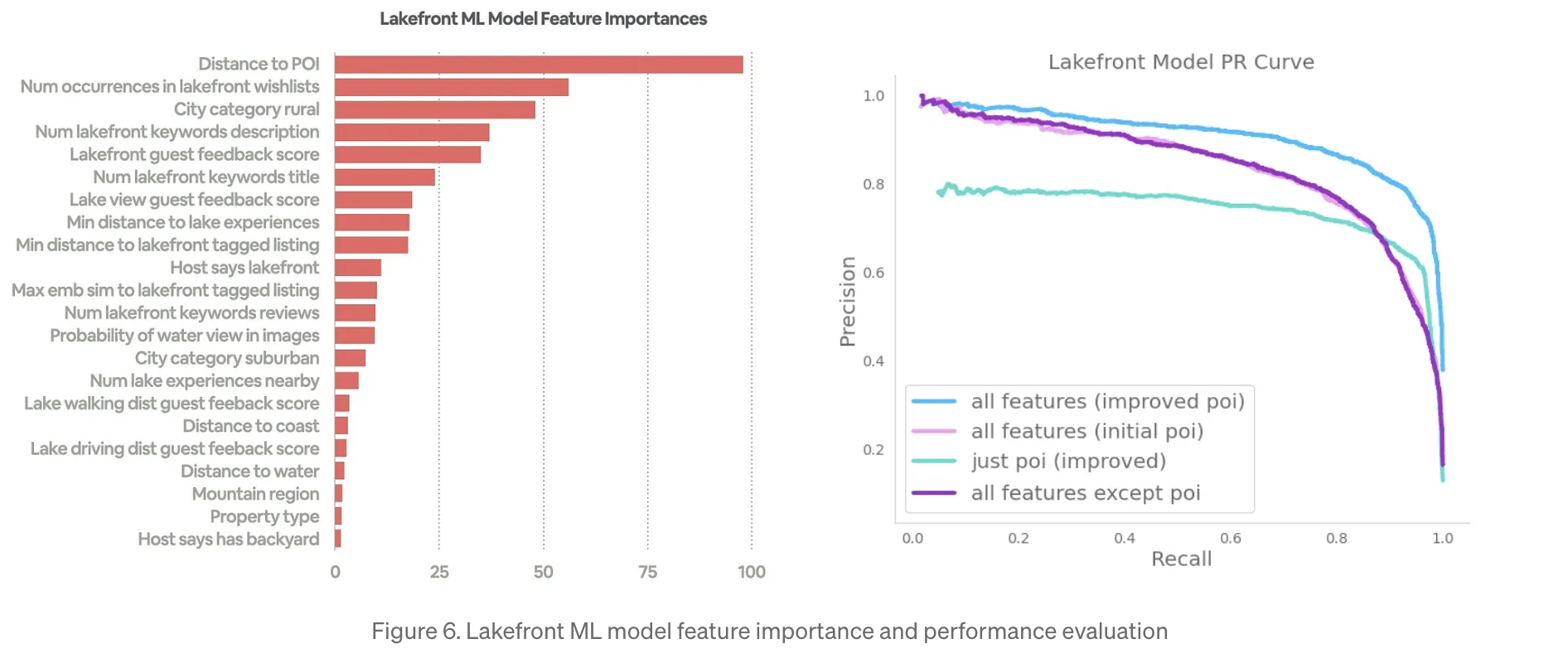
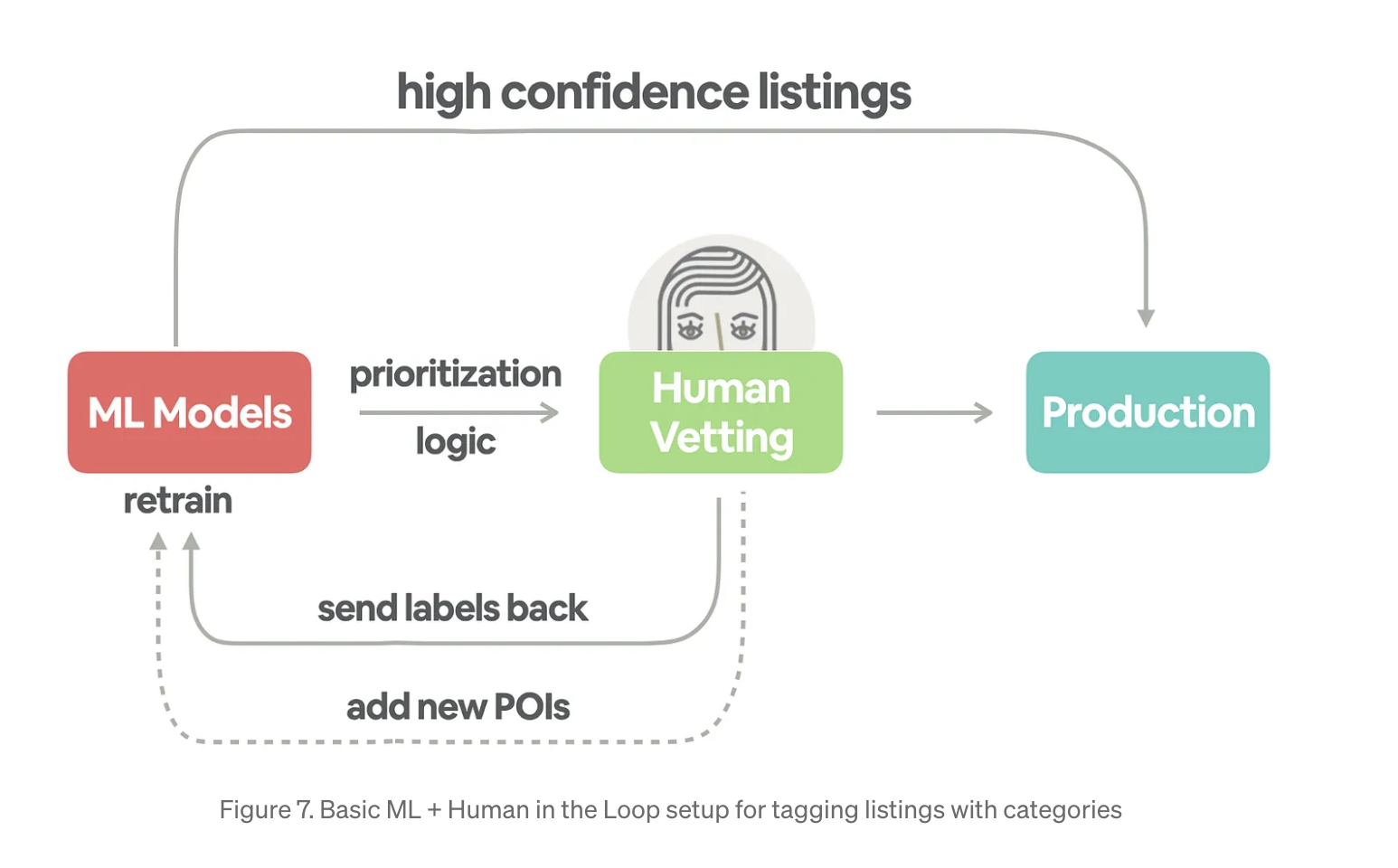
- Sending confident listings to production
PR curve에서 90% 정밀도를 달성하는 임계값을 설정
Lakefront의 경우, 90% precision, 76% recall 달성. 즉,실제 Lakefront 목록의 76%를 캡쳐 가능!
기준 미만의 목록은 재학습을 위해 ML 모델로 반환하므로, 시간이 지날수록 ML 모델 향상을 기대할 수 있음
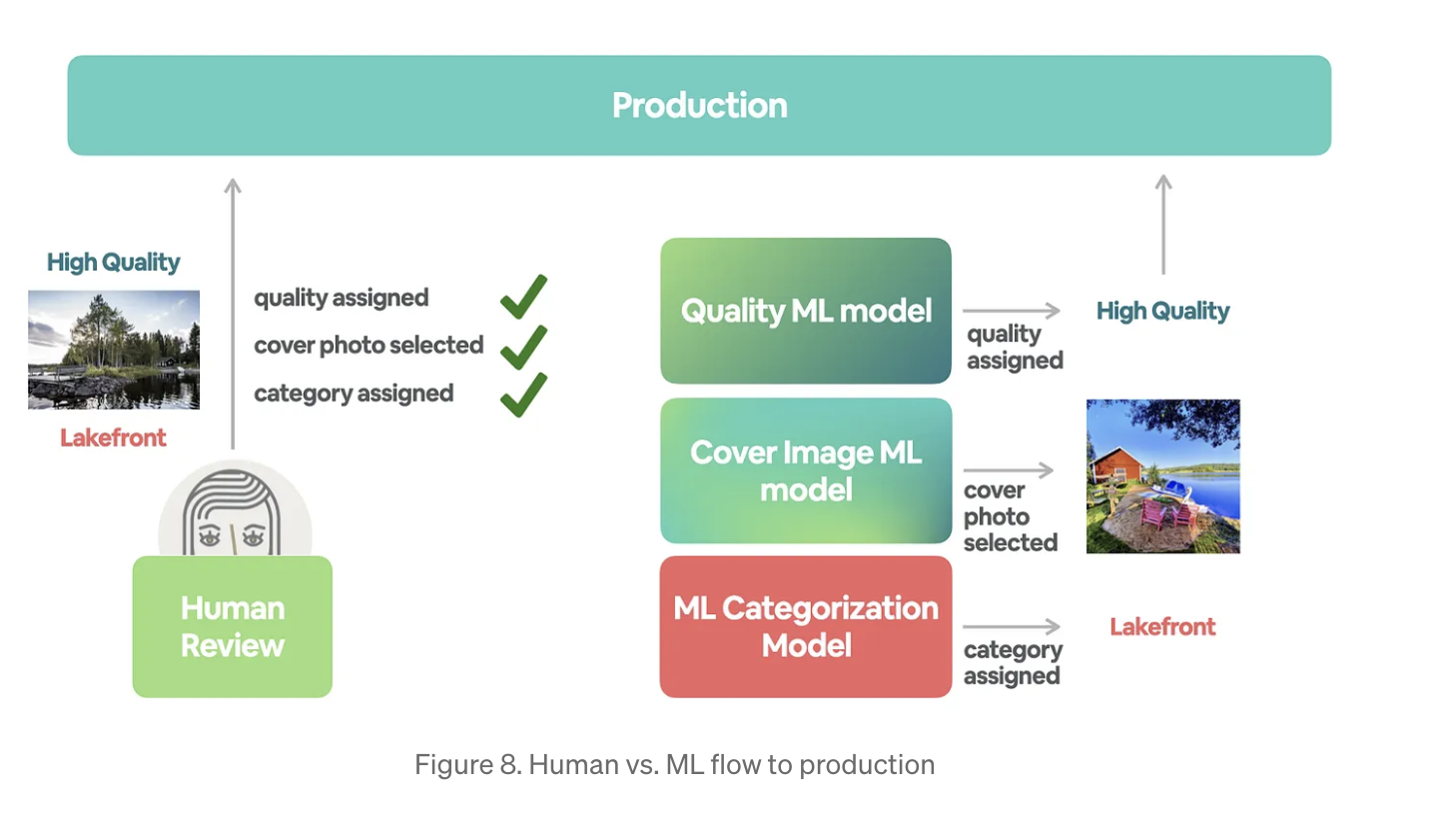
기타 (사진품질 판별 모델, 표지 대표 이미지 선택 모델)
- Quality ML모델: 모든 카테고리에 대한 글로벌 모델
- Cover Image ML 모델: 카테고리 정보를 입력신호로 사용
=> 현재, 세가지 ML 모델을 모두 사용
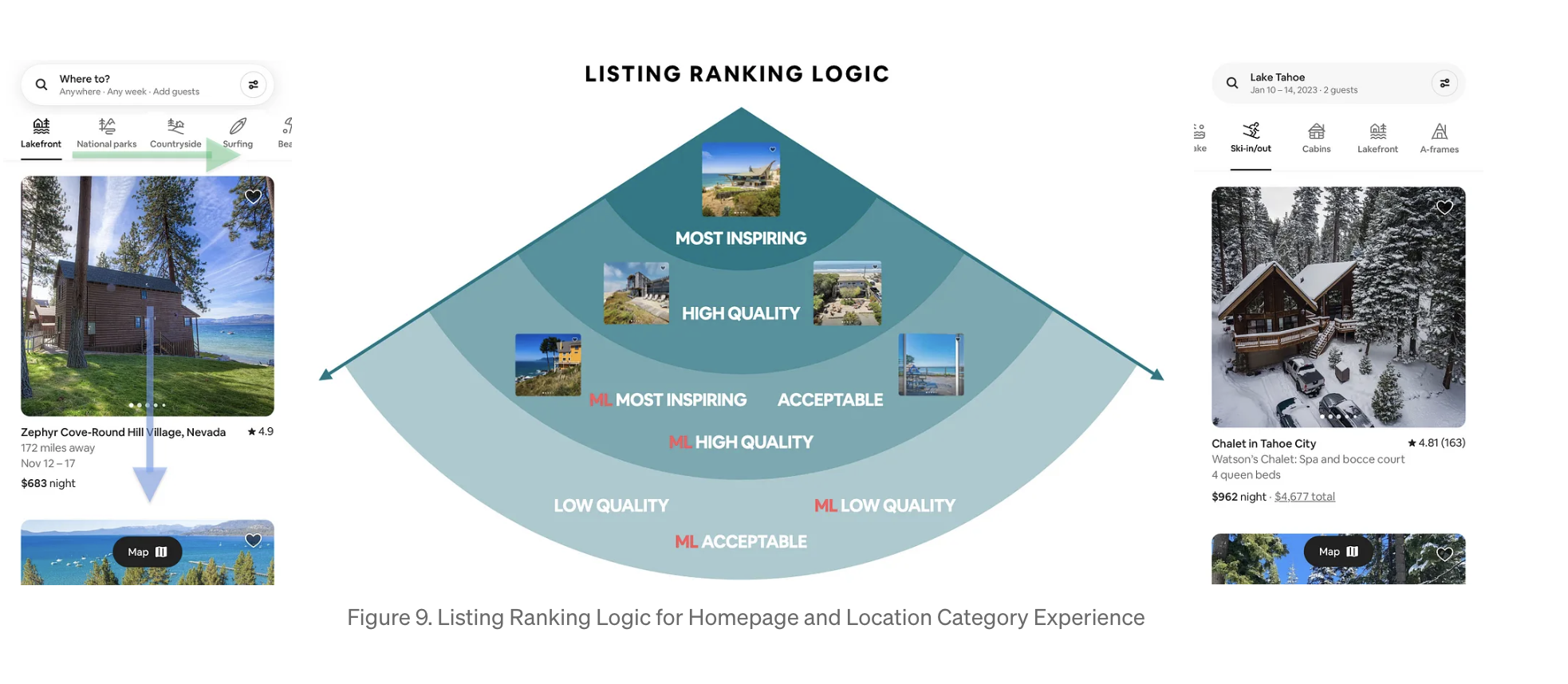
새로운 랭킹 알고리즘 2가지
-
예를 들어, lake Tahoe 위치를 검색할 경우, 관련된 카테고리인 skiing, cabins, lakefront, lake house가 노출되며, 특히 겨울철에는 skiing이 가장 먼저 노출되어야 함
-
카테고리 랭킹(초록 화살표): 사용자 출신, 계절, 카테고리 인기도, 예약율, 개인관심사에 따라 카테고리를 왼쪽에서 오른쪽으로 순위를 매김
-
목록 랭킹(파랑 화살표) : 한 카테고리에 할당된 숙소 리스트를 받아, 사람이 평가한 것은 상위노출, ML모델에 의한 것은 하위노출 하여 위에서 아래로 순위를 매김
모든 알고리즘