-
다중선형회귀: mse를 최소화하는 w,b 찾아야 함
-
딥러닝 loss function에서 과적합 방지시에 제약조건으로도 사용
-
회귀모델의 정규화( feature 수 감소=> overfitting 방지) . mse+ regular-term
-
L1(라쏘) : w의 '절대값'의 합이 0. 0값도 있음.
알파가 너무 작으면 복잡도가 커서 overfitting, 너무 크면 underfitting: 알파는 cross_val을 통해서 설정
- 일반화 가능/ 0인값은 특성에서 제외됨. 해석력이 증가. 희소모델화(sparse model) -
L2(릿지: 능형회귀): '제곱의 합'이 최소. 과적합 방지. 가중치가 0이 되진 않음. feature가 비슷하게 중요하면 릿지가 better
-
에라스틱넷(elastic net)
: 추정계수의 절대값/ 제곱합 둘 다 최소화. 큰 데이터셋이라면 릿지/라쏘 효과 둘다 반영됨
- 주성분분석(PCA) : 비지도학습
https://sjpyo.tistory.com/6?category=956366
-
VALIDATION : CROSS_VAL, K-FOLD,OUT OF FOLD, LEARNING CURVE, GRIDSEARCH
https://sjpyo.tistory.com/47?category=956366
- K-FOLD: train 수가 부족하면 fold갯수를 늘릴것
- 경험상 일반 k값:10 / 대규모 dataset: 5
- 중복없이 k fold로 랜덤하게 나눔- k개의 성능 추정을 통해 모델평균 성능 계산
- starified k-fold cross-val: 각 fold에서 label 비율이 전체비율을 유지
- k개의 성능 추정을 통해 모델평균 성능 계산
import numpy as np
from sklearn.model_selection import StratifiedKFold
kfold = StratifiedKFold(n_splits = 10, random_state = 1, shuffle = True).split(X_train, y_train)
scores = []
for k, (train, test) in enumerate(kfold):
pipe_lr.fit(X_train[train], y_train[train])
score = pipe_lr.score(X_train[test], y_train[test])
scores.append(score)
print(f"폴드: {k+1}, 클래스 분포: {np.bincount(y_train[train])}, 정확도: {round(score, 3)}")
print(f"CV 정확도: {np.mean(scores)} +/- {np.std(scores)}")
'''sklearn kfold cv'''
from sklearn.model_selection import cross_val_score
scores = cross_val_score(estimator = pipe_lr, X = X_train,
y = y_train, cv = 10, n_jobs = -1)
print(f"CV 정확도 점수 : {scores}")
print(f"CV 정확도: {np.mean(scores)} +/- {np.std(scores)}")
'''평가 지표 설정 후 train, test 데이터 점수'''
from sklearn.model_selection import cross_validate
scores = cross_validate(estimator = pipe_lr, X = X_train,
y = y_train, scoring = ['accuracy'],
cv = 10, n_jobs = -1, return_train_score = False)
print(f"CV 정확도 점수 : {scores['test_accuracy']}")
print(f"CV 정확도: {np.mean(scores['test_accuracy'])} +/- {np.std(scores['test_accuracy'])}")- oof(out of fold)
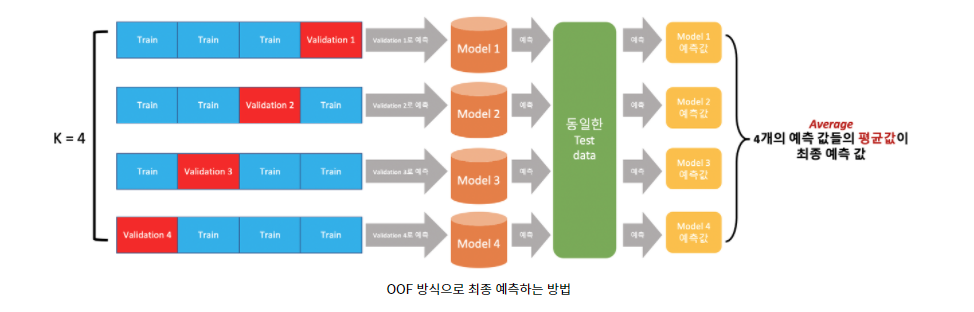
- 4개의 예측값들의 평균을 취하여 최종 예측값 계산 => dacon kaggle 같은 대회에서 자주 사용
파이프라인


- 제플린
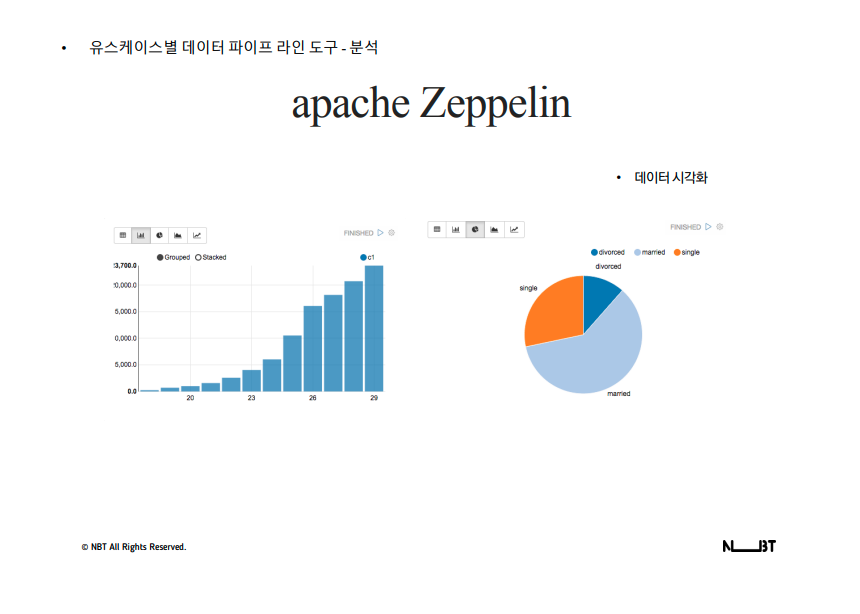

- 엘라스틱서치

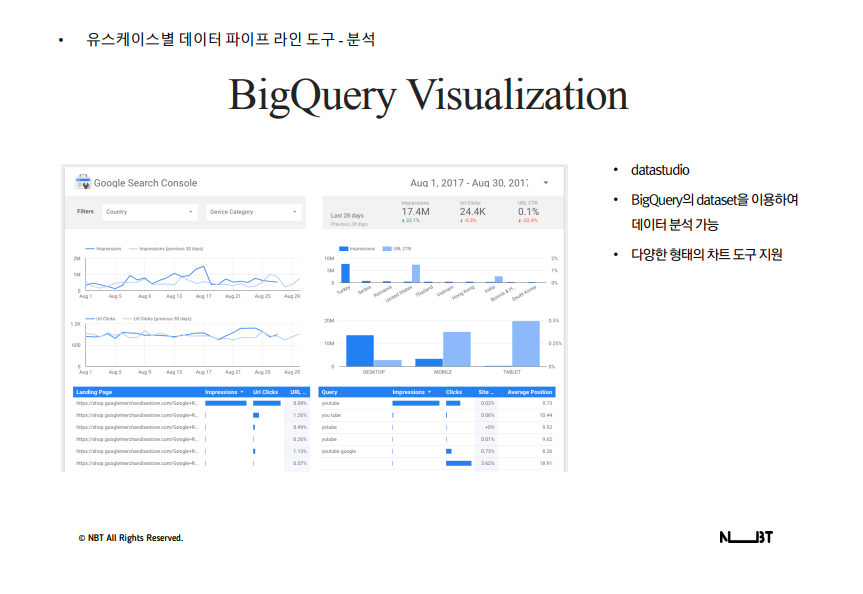
- 구글 빅쿼리






데이터분석