최단경로 문제 (BFS와 다른가?)
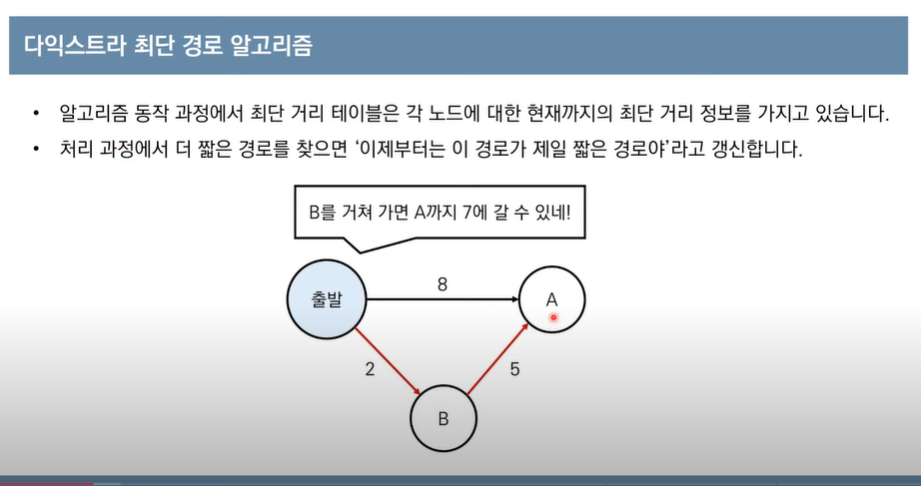
다익스트라(Dijkstra) 최단경로 알고리즘 (그리디)
- 음의 간선이 없을때 정상작동
- 매 상황에서 가장 비용이 적은 노드를 선택
동작과정
-출발노드 설정
-최단거리 테이블 초기화
-방문하지 않은 노드중에서 최단거리가 가장 짧은 노드 선택
-해당노드를 거쳐 다른노드로 가는 비용을 계산하여 최단거리 테이블을 갱신
-3,4번 반복

import sys
input = sys.stdin.readline
INF = int(1e9)
# 여기가 왜 에러일까....
n, m = map(int, input().split())
start = int(input())
# 주어지는 그래프 정보 담는 N개 길이의 리스트
graph = [[] for _ in range(n+1)]
visited = [False] * (n+1) # 방문처리 기록용
distance = [INF] * (n+1) # 거리 테이블용
for _ in range(m):
a, b, c = map(int, input().split())
graph[a].append((b, c))
# 방문하지 않은 노드이면서 시작노드와 최단거리인 노드 반환
def get_smallest_node():
min_value = INF
index = 0
for i in range(1, n+1):
if not visited[i] and distance[i] < min_value:
min_value = distance[i]
index = i
return index
# 다익스트라 알고리즘
def dijkstra(start):
# 시작노드 -> 시작노드 거리 계산 및 방문처리
distance[start] = 0
visited[start] = True
# 시작노드의 인접한 노드들에 대해 최단거리 계산
for i in graph[start]:
distance[i[0]] = i[1]
# 시작노드 제외한 n-1개의 다른 노드들 처리
for _ in range(n-1):
now = get_smallest_node() # 방문X 면서 시작노드와 최단거리인 노드 반환
visited[now] = True # 해당 노드 방문처리
# 해당 노드의 인접한 노드들 간의 거리 계산
for next in graph[now]:
cost = distance[now] + next[1] # 시작->now 거리 + now->now의 인접노드 거리
if cost < distance[next[0]]: # cost < 시작->now의 인접노드 다이렉트 거리
distance[next[0]] = cost
dijkstra(start)
for i in range(1, n+1):
if distance[i] == INF:
print('도달 할 수 없음')
else:
print(distance[i])
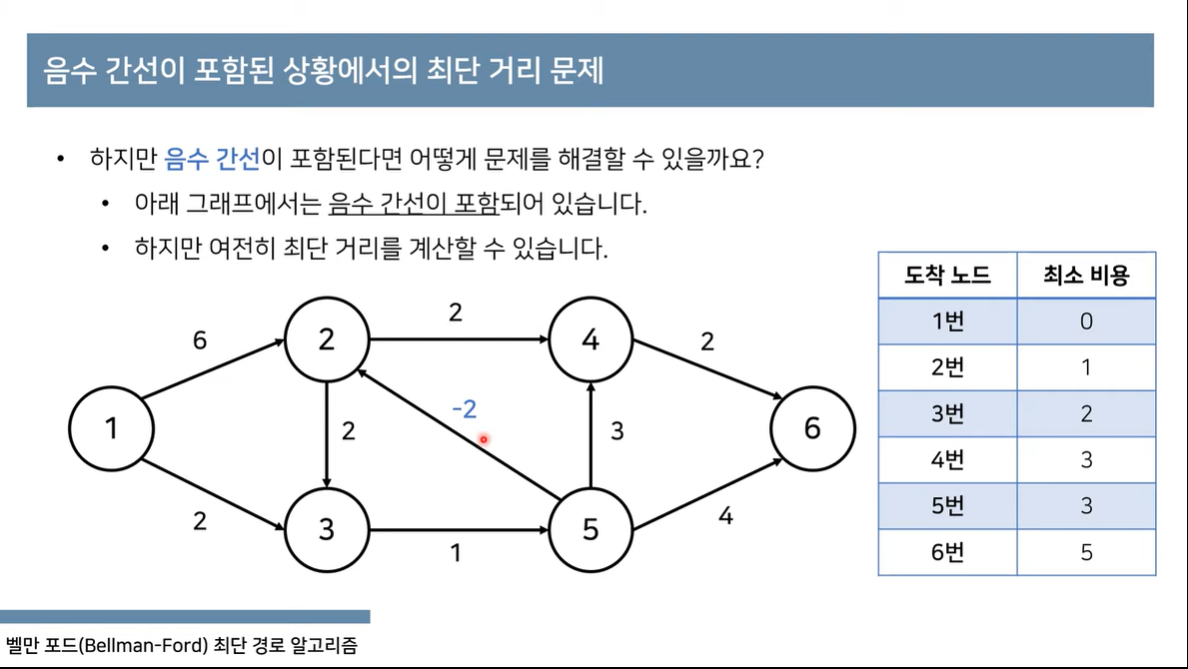
벨만포드 알고리즘: 음수간선이 포함된
BOJ 타임머신문제





#벨만포드
import sys
input=sys.stdin.readline
INF=int(1e9) #무한: 10억
def bf(start):
dist[start]=0
# 매 반복마다 모든간선 확인
for i in range(n):
for j in range(m):
cur=edges[j][0]
next_node=edges[j][1]
cost=edges[j][2]
# 현재간선을 거쳐서 다른노드로 이동하는 거리가 더 짧은 경우
if dist[cur] !=INF and dist[next_node] >dist[cur]+cost:
dist[next_node]=dist[cur]+cost
if i==n-1:
return True
return False
# 노드갯수, 간선갯수
n,m=map(int, input().split())
edges=[]
# 최단거리 테이블을 모두 무한으로 초기화
dist=[INF]*(n+1)
# 모든 간선정보
for _ in range(m):
a,b,c=map(int, input().split())
# a번노드에서 b번노드로 가는 비용이 c라는 의미
edges.append((a,b,c))
# 벨만포드 알고리즘 수행
negative_cycle=bf(1) # 1번노드가 시작노드
if negative_cycle:
print("-1")
else:
# 1번노드를 제외한 다른 모든 노드로 가기위한 최단거리출력
for i in ragne(2, n+1):
#도달불가: -1, 도달가능: 거리
if dist[i]==INF:
print("-1")
else:
print(dist[i])
우선순위 큐( priority queue)
- 우선순위가 가장 높은 데이터를 가장 먼저 삭제
| 자료구조 | 추출되는데이터 |
|---|---|
| 스택 | 가장 나중에 삽입 |
| 큐 | 가장 먼저 삽입 |
| 우선순위 큐 | 가장 우선순위 높은 |
힙 : 우선순위 큐를 구현하기 위해 사용되는 자료구조
- 최소힙, 최대힙이 있다
| 우선순위큐 구현방식 | 삽입시간 | 삭제시간 |
|---|---|---|
| 리스트 | O(1) | O(N) |
| 힙 | O(logN) | O(logN) |
최소힙
import heapq
# 오름차순 힙 정렬(heap sort)
def heapsort(iterable):
h=[]
result=[]
# 모든원소 차례대로 힙에 삽입
for value in iterable:
heapq.heappush(h,value)
# 힙에 삽입된 모든원소 차례대로 꺼내담기
for i in range(len(h)):
result.append(heapq.heappop(h))
return result
result=heapsort([1,3,5,7,9,2,4,6,8,0])
print(result)[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
다익스트라 알고리즘: 개선된 구현방법
-
단계마다 방문하지 않은 노드중에서 최단거리가 가장 짧은 노드를 선택하기 위해 힙 자료구조 이용
-
현재 가장 가까운 노드 저장하기 위해 힙자료구조를 추가적 이용
-
다익스트라 알고리즘에서 함수만 다름 , visited 없음
import heapq
import sys
input = sys.stdin.readline
INF = int(1e9) #무한을 의미하는 값으로 10억 설정
# 노드의 개수, 간선의 개수를 입력받기
n , m = map(int,input().split())
# 시작 노드 번호를 입력받기
start - int(input())
# 각 노드에 연결되어 있는 노드에 대한 정보를 담는 리스트 생성
graph = [[] for i in range( n + 1)]
# 최단 거리 테이블을 모드 무한으로 초기화
distance = [INF] * (n +1)
# 모든 간선 정보를 입력받기
for _ in range(m):
a,b,c = map(int, input().split())
# a번 노드에서 b번 노드로 가는 비용이 c라는 의미
graph[a].append((b,c))
--------------
def dijkstra(start):
q = []
# 시작 노드로 가기 위한 최단 거리는 0으로 설정하여, 큐에 삽입
heapq.heappush(q, (0, start))
distance[start] = 0
while q: # 큐가 비어있지 않다면
#가장 최단 거리가 짧은 노드에 대한 정보 꺼내기
dist, now = headpq.heappop(q)
#현재 노드가 이미 처리된 적이 있는 노드라면 무시
if distance[now] < dist:
continue
#현재 노드와 연결된 다른 인접한 노드들을 확인
for i in graph[now]:
cost = dist + i[1]
# 현재 노드를 거쳐서 다른 노드로 이동하는 거리가 더 짧은 경우
if cost < distance[i[0]]:
distance[i[0]]: cost
heapq.heappush(q, (cost, i[0]))
# 다익스트라 알고리즘을 수행
dijkstra(start)
# 모든 노드로 가기 위한 최단 거리를 출력
for i in range(1, n + 1):
# 도달할 수 없는 경우, 무한이라고 출력
if distance[i] == INF:
print("INFINITY")
# 도달할 수 있는 경우 거리를 출력
else:
print(distance[i])
- 노드를 하나씩 꺼내서 검사하는 while 밥녹문은 노드갯수 v이상의 횟수로는 처리되지 않음
- 직관적으로 전체과정은 E개의 원소를 우선순위 큐에 넣었다가 모두 빼내는 연산과 유사함
** 다시 들어보는게 좋겠다....
플로이드 워셜 알고리즘(Floyd_Warshall)
- 모든 노드에서 다른 모든 노드까지의 최단경로를 모두 계산
- 단계별로 거쳐가는 노드를 기준으로 알고리즘 수행 (매 단계마다 방문하지 않은 노드 중에 최단거리를 갖는 노드 찾는 과정은 필요치 않음)
- 다이나믹 프로그래밍 유형에 속함

INF = int(1e9) # 무한을 의미하는 값으로 10억을 설정
# 노드의 개수 및 간선의 개수를 입력받기
n = int(input())
m = int(input())
# 2차원 리스트(그래프 표현)를 만들고, 모든 값을 무한으로 초기화
graph = [[INF] * (n + 1) for _ in range(n + 1)]
# 자기 자신에서 자기 자신으로 가는 비용은 0으로 초기화
for a in range(1, n + 1):
for b in range(1, n + 1):
if a == b:
graph[a][b] = 0
# 각 간선에 대한 정보를 입력 받아, 그 값으로 초기화
for _ in range(m):
# A에서 B로 가는 비용은 C라고 설정
a, b, c = map(int, input().split())
graph[a][b] = c
# 점화식에 따라 플로이드 워셜 알고리즘을 수행
for k in range(1, n + 1):
for a in range(1, n + 1):
for b in range(1, n + 1):
graph[a][b] = min(graph[a][b], graph[a][k] + graph[k][b])
# 수행된 결과를 출력
for a in range(1, n + 1):
for b in range(1, n + 1):
# 도달할 수 없는 경우, 무한(INFINITY)이라고 출력
if graph[a][b] == 1e9:
print("INFINITY", end=" ")
# 도달할 수 있는 경우 거리를 출력
else:
print(graph[a][b], end=" ")
print()전보 문제

import heapq
import sys
input = sys.stdin.readline
INF = int(1e9) # 무한을 의미하는 값으로 10억을 설정
# 노드의 개수, 간선의 개수, 시작 노드를 입력받기
n, m, start = map(int, input().split())
# 각 노드에 연결되어 있는 노드에 대한 정보를 담는 리스트를 만들기
graph = [[] for i in range(n + 1)]
# 최단 거리 테이블을 모두 무한으로 초기화
distance = [INF] * (n + 1)
# 모든 간선 정보를 입력받기
for _ in range(m):
x, y, z = map(int, input().split())
# X번 노드에서 Y번 노드로 가는 비용이 Z라는 의미
graph[x].append((y, z))
def dijkstra(start):
q = []
# 시작 노드로 가기 위한 최단 경로는 0으로 설정하여, 큐에 삽입
heapq.heappush(q, (0, start))
distance[start] = 0
while q: # 큐가 비어있지 않다면
# 가장 최단 거리가 짧은 노드에 대한 정보를 꺼내기
dist, now = heapq.heappop(q)
if distance[now] < dist:
continue
# 현재 노드와 연결된 다른 인접한 노드들을 확인
for i in graph[now]:
cost = dist + i[1]
# 현재 노드를 거쳐서, 다른 노드로 이동하는 거리가 더 짧은 경우
if cost < distance[i[0]]:
distance[i[0]] = cost
heapq.heappush(q, (cost, i[0]))
# 다익스트라 알고리즘을 수행
dijkstra(start)
# 도달할 수 있는 노드의 개수
count = 0
# 도달할 수 있는 노드 중에서, 가장 멀리 있는 노드와의 최단 거리
max_distance = 0
for d in distance:
# 도달할 수 있는 노드인 경우
if d != 1e9:
count += 1
max_distance = max(max_distance, d)
# 시작 노드는 제외해야 하므로 count - 1을 출력
print(count - 1, max_distance)미래도시 문제

- n의 크기가 최대 100이므로 플로이드 워셜 알고리즘 이용
INF = int(1e9) # 무한을 의미하는 값으로 10억을 설정
# 노드의 개수 및 간선의 개수를 입력받기
n, m = map(int, input().split())
# 2차원 리스트(그래프 표현)를 만들고, 모든 값을 무한으로 초기화
graph = [[INF] * (n + 1) for _ in range(n + 1)]
# 자기 자신에서 자기 자신으로 가는 비용은 0으로 초기화
for a in range(1, n + 1):
for b in range(1, n + 1):
if a == b:
graph[a][b] = 0
# 각 간선에 대한 정보를 입력 받아, 그 값으로 초기화
for _ in range(m):
# A와 B가 서로에게 가는 비용은 1이라고 설정
a, b = map(int, input().split())
graph[a][b] = 1
graph[b][a] = 1
# 거쳐 갈 노드 X와 최종 목적지 노드 K를 입력받기
x, k = map(int, input().split())
# 점화식에 따라 플로이드 워셜 알고리즘을 수행
for k in range(1, n + 1):
for a in range(1, n + 1):
for b in range(1, n + 1):
graph[a][b] = min(graph[a][b], graph[a][k] + graph[k][b])
# 수행된 결과를 출력
distance = graph[1][k] + graph[k][x]
# 도달할 수 없는 경우, -1을 출력
if distance >= 1e9:
print("-1")
# 도달할 수 있다면, 최단 거리를 출력
else:
print(distance)이진탐색
- 순차탐색: 앞에서부터 하나씩 확인
- 이진탐색: 탐색범위를 좁혀가며 탐색 (시작점 중간점 끝점)
- 단계마다 탐색범위를 2로 나누는것과 동일하므로 연산횟수는 log2N, 시간복잡도는 O(logN)
이진탐색 소스코드 (재귀적 구현)
# 이진탐색 소스코드 구현( 재귀 함수 )
def binary_search(array, target, start, end):
if start > end:
return None
mid= (start+end)//2
# 찾았으면 중간점 인덱스 반환
if array[mid] == target:
return mid
# 중간점 값보다 찾고자 하는 값이 작으면 왼쪽
elif array[mid]>target:
return binary_search(array, target, start, mid-1)
# 중간점 값보다 찾고자 하는 값이 크면 오른쪽 ( m+1)
else:
return binary_search(array, target, mid+1, end)
# n(원소의 개수)과 target(찾고자 하는 값)을 입력받기
n, target= list(map(int, input().split()))
# 전체원소 입력받기
array= list(map(int, input().split()))
# 이진탐색 수행결과 출력
result=binary_search(array, target, 0, n-1)
if result==None:
print('원소없음')
else:
print(result+1)10 7
1 3 5 7 9 11 13 15 17 19
4
10 7
1 3 5 6 9 11 13 15 17 19
원소없음
bisect 문제: 파이썬 이진탐색 라이브러리
- bisect_left(a,x): 정렬된 순서를 유지하면서 배열a에 x를 삽입할 가장 왼쪽 인덱스 반환
- bisect_right(a,x): 정렬된 순서를 유지하면서 배열a에 x를 삽입할 가장 오른쪽 인덱스 반환
from bisect import bisect_left, bisect_right
a=[1,2,4,4,8]
x=4
print(bisect_left(a,x))
print(bisect_right(a,x))bisect : 값이 특정 범위에 속하는 데이터 갯수
from bisect import bisect_left, bisect_right
# 값이 [left_value, right_value]인 데이터의 갯수 반환
def count_by_range( a, left_value, right_value):
right_idx=bisect_right(a, right_value)
left_idx=bisect_left(a, left_value)
return right_idx- left_idx
a=[1,2,3,3,3,3,4,4,8,9]
# 값이 4개인 데이터 갯수 출력
print(count_by_range(a,4,4))
# 값이 [-1,3] 범위에 있는 데이터 갯수 출력
print(count_by_range(a,-1,3))
2
6
파라메트릭 서치(parametric search)
- 최적화 문제를 결정문제(예, 아니오)로 바꿔 해결
- 코테에서는 파라메트릭서치문제는 이진탐색으로 해결
떡볶이 떡 만들기
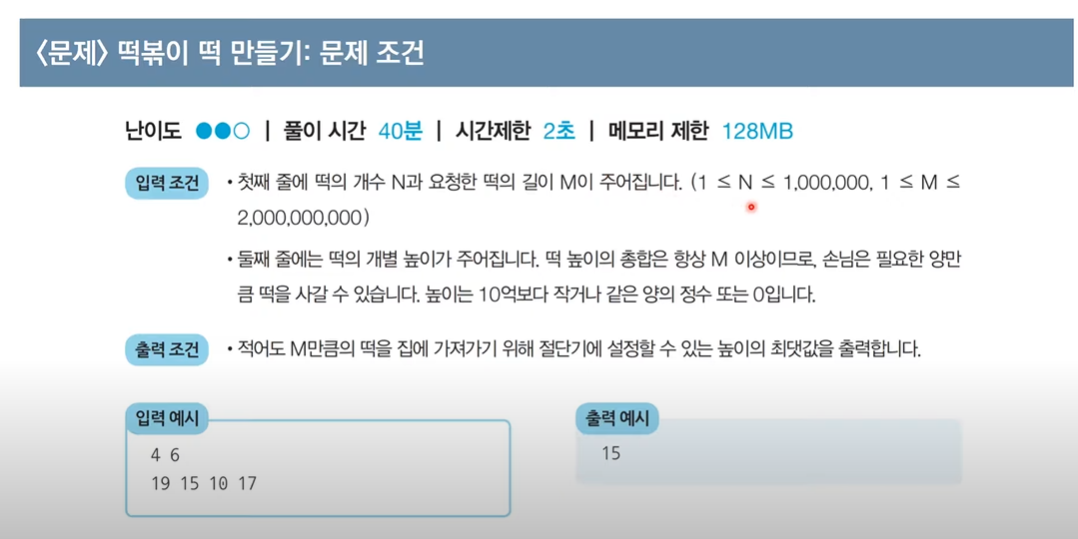

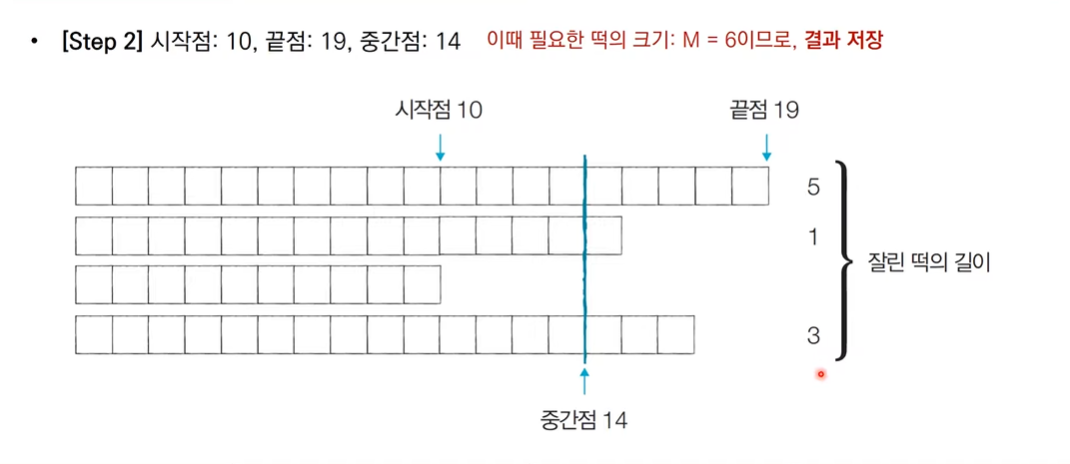
- 절단기의 높이가 0~10억까지 (큰 탐색범위) -> 이진탐색
- 중간점: 시간이 지날수록 '최적화된 값'
n,m=list(map(int,input().split(' ')))
# 떡의 개별 높이
array= list(map(int, input().split()))
#이진탐색을 위한 시작점과 끝점
start=0
end=max(array)
# 이진탐색 수행(반복적)
result=0
while(start<=end):
total=0
mid=(start+end)//2
for x in array:
# 잘랐을때의 떡의 양 계산
if x>mid:
total+=x-mid
# 떡의 양이 부족한 경우, 더 많이 자르기( 왼쪽부분 탐색)
if total<m:
end=mid-1
# 떡의 양이 충분한 경우, 덜 자르기 (오른쪽부분 탐색)
else:
# 최대한 덜 잘랐을때가 정답, 여기에서 result에 기록
result=mid
start=mid+1
print(result)
정렬된 배열에서 특정 수의 개수 구하기: bisect 코드 참조
- 시간복잡도가 O(logN)이므로 알고리즘 설계 필요(시간초과)
- 선형탐색 : X
- 정렬된 데이터이므로 이진탐색
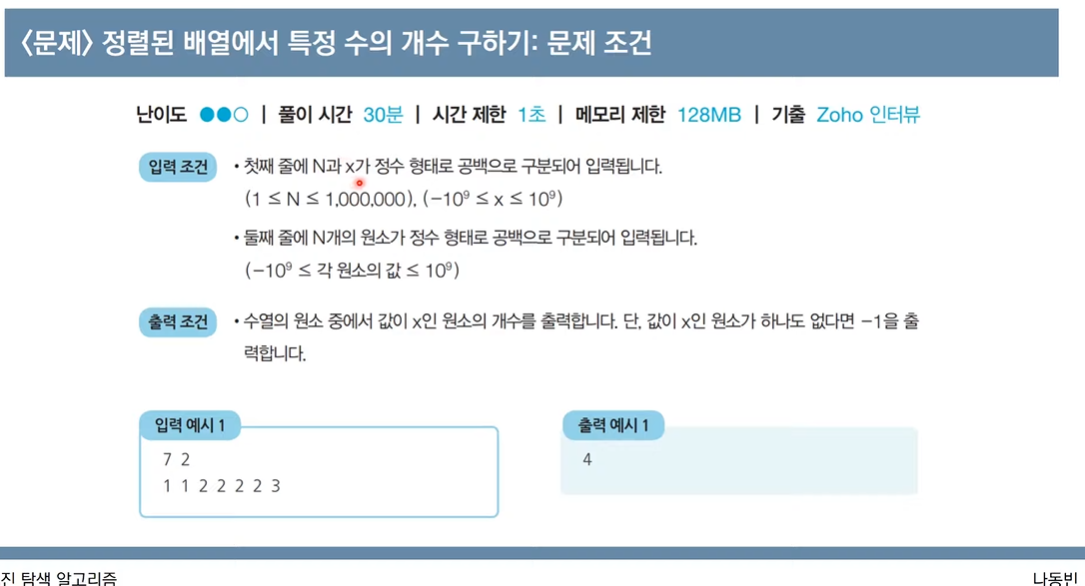
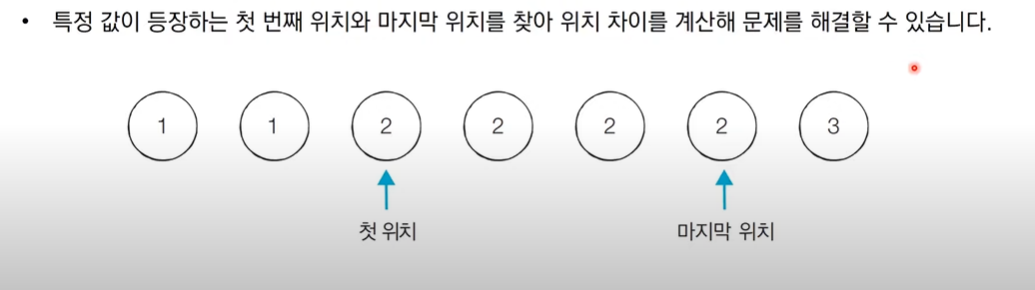
from bisect import biest_left, bisect_right
# 값이 [left_value, right_value]인 데이터의 갯수를 반환하는 함수
def count_by_range(array, left_value, right_value):
right_idx=bisect_right(array, right_value)
left_idx=bisect_left(array, left_value)
return right_idx- left_idx
n,x=map(int,input().split())
array=list(map(int,input().split()))
# 값이 [x,x] 범위에 있는 데이터의 개수 계산
count=count_by_range(array, x, x)
# 값이 x인 원소가 존재하지 않는다면
if count==0:
print(-1)
# 값이 x인 원소가 존재한다면
else:
print(count)정렬
선택정렬
- 가장 작은 데이터를 선택하여 맨 앞에 있는 데이터와 바꿈
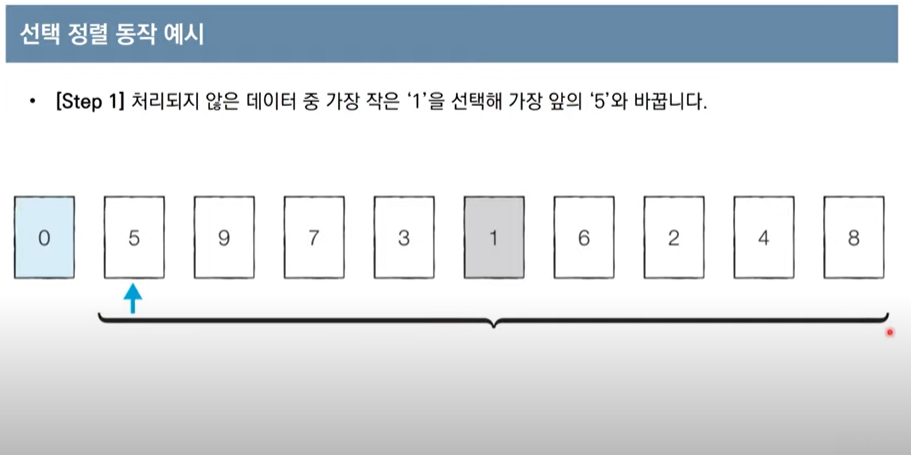
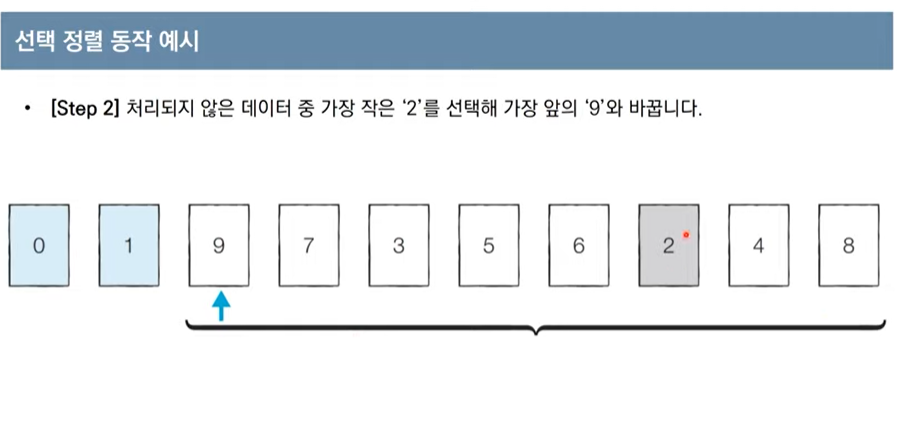
array=[7,5,9,0,3,1,6,2,4,8]
for i in range(len(array)):
min_index=i # 가장작은 원소 인덱스
for j in range(i+1, len(array)):
if array[min_index]>array[j]:
min_index=j
array[i], array[min_index]=array[min_index], array[i] #스와프
print(array) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]

삽입정렬
- 처리되지 않은 데이터를 하나씩 골라 적절한 위치에 삽입
- 선택정렬에 비해 효율적



array=[7,5,9,0,3,1,6,2,4,8]
for i in range(1, len(array)):
# 인덱스 i부터 1까지 감소
for j in range(i, 0, -1):
# 한 칸식 왼쪽으로 이동
if array[j]< array[j-1]:
array[j], array[j-1]=array[j-1], array[j]
# 자기보다 작은 데이터라면 멈춤
else:
break
print(array)퀵정렬
- 기준데이터를(pivot) 설정, 그 기준보다 큰/작은 데이터 위치 바꾸는 방법
- 병합정렬과 더불어 가장 많이 사용


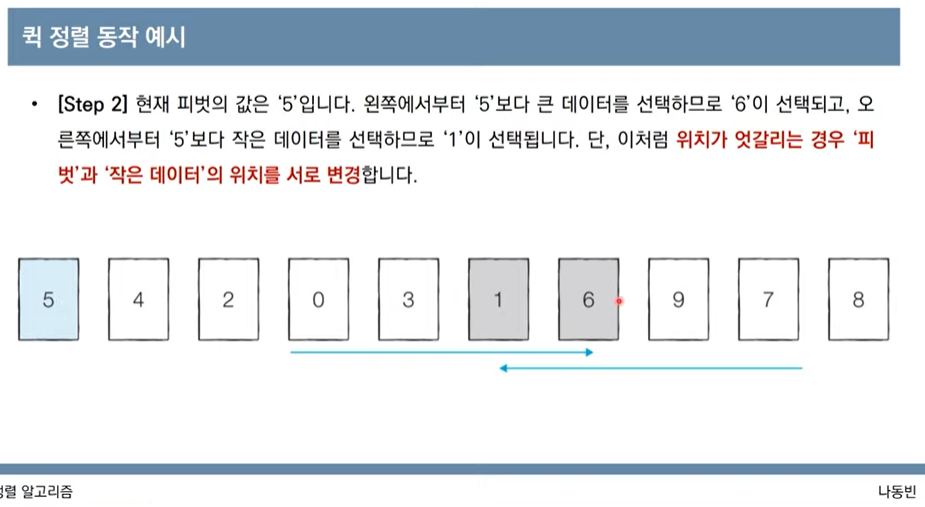
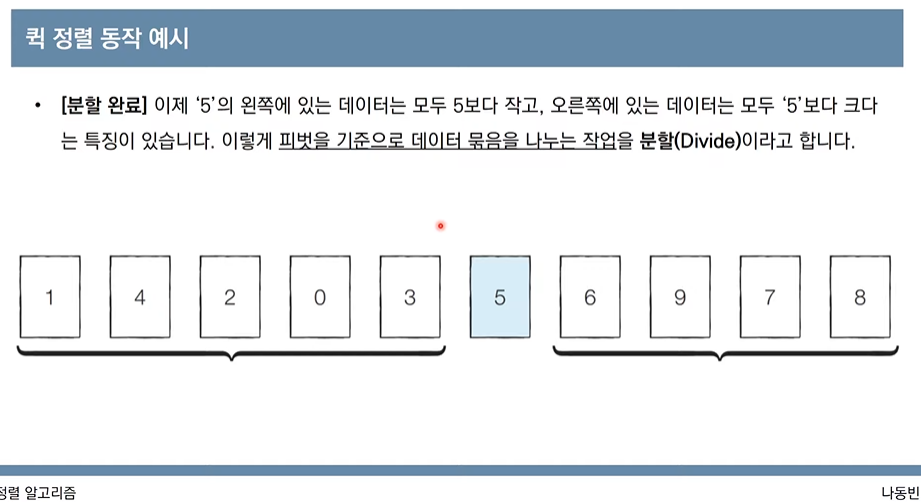
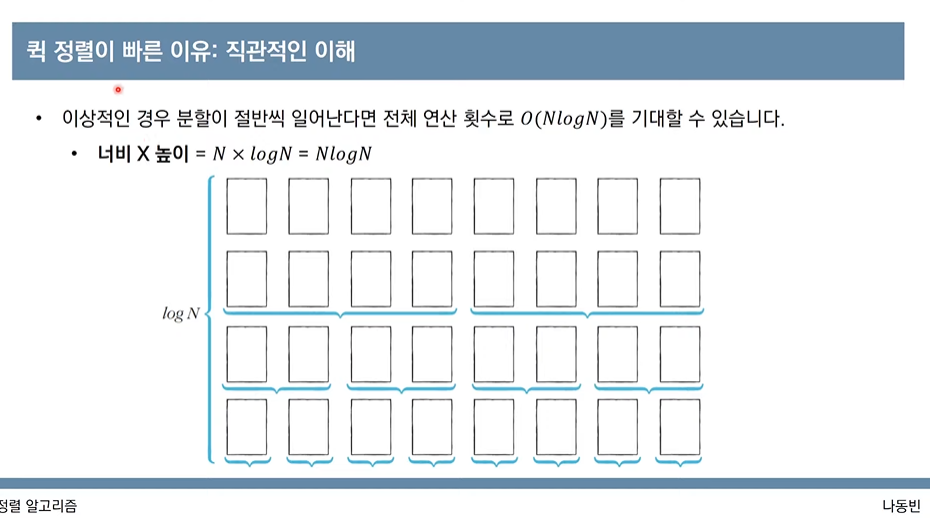
array=[7,5,9,0,3,1,6,2,4,8]
def quick_sort(array, start, end):
# 원소가 1개라면 종료한다
if start>=end:
return
pivot=start
left=start+1
right=end
while(left<=right):
# pivot보다 큰 데이터를 찾을때까지 반복
while(left<=end and array[left]<=array[pivot]):
left+=1
# pivot보다 작은 데이터를 찾을때까지 반복
while(right>start and array[right]>=array[pivot]):
right-=1
# 엇갈렸다면 작은데이터와 피벗을 교체
if(left>right):
array[right], array[pivot]= array[pivot], array[right]
# 엇갈리지 않다면 작은데이터와 큰 데이터를 교체
else:
array[left], array[right]=array[right],array[left]
# 분할 이후 왼쪽부분과 오른쪽부분에서 각각 정렬수행
quick_sort(array, start, right-1)
quick_sort(array, right+1, end)
quick_sort(array, 0, len(array)-1)
print(array) 퀵 정렬 소스코드 : 파이썬의 장점을 살린 방식
array=[7,5,9,0,3,1,6,2,4,8]
def quick_sort(array):
if len(array)<=1:
return array
pivot= array[0]
tail=array[1:]
left_side=[x for x in tail if x<=pivot]
right_side=[x for x in tail if x> pivot]
return quick_sort(left_side) + [pivot]+ quick_sort(right_side)
print(quick_sort(array))계수정렬
- 매우 빠름/ 동일값을 가지는 데이터가 여럿 등장할 때 효과적 ex) 성적
- 카운트방식 정렬 알고리즘
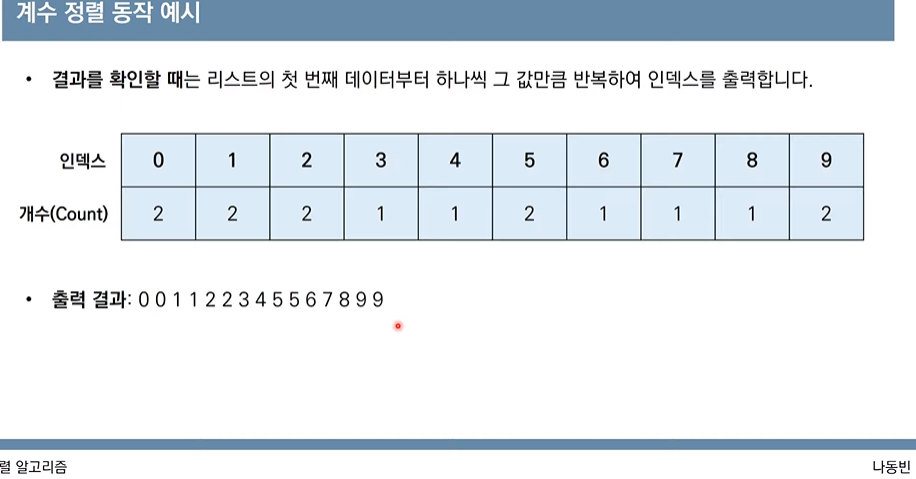
array=[7,5,9,0,3,1,6,2,4,8]
count=[0]*(max(array)+1)
for i in range(len(array)):
count[array[i]]+=1
# 리스트에 기록된 정렬 정보 확인
for i in range(len(count)):
for j in range(count[i]):
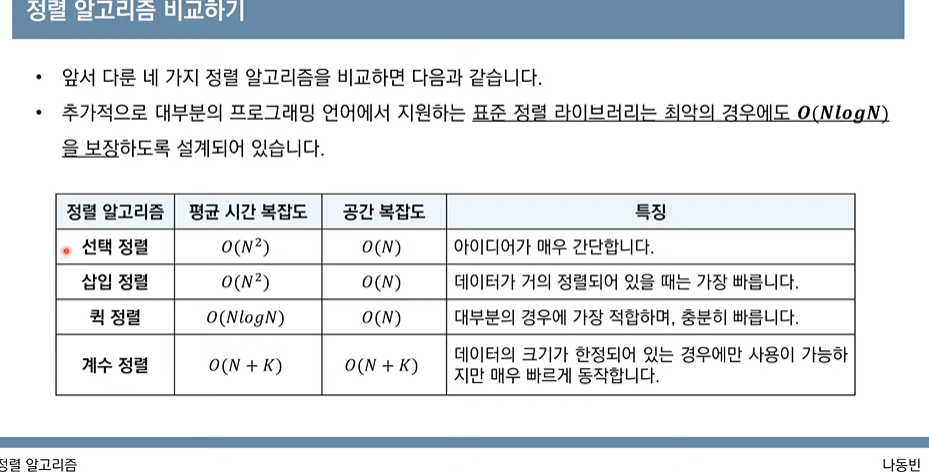
print(i, end=' ')정렬 알고리즘 비교
*버블정렬은 어디갔찡,,, 안 중요한가?
선택정렬 vs 기본정렬
from random import randint
import time
array=[]
for _ in range(10000):
array.append(randint(1, 100))
start_time=time.time()
for i in range(len(array)):
min_index=i
for j in range(i+1, len(array)):
if array[min_index] > array[j]:
min_index=j
array[i], array[min_index]=array[min_index],array[i]
end_time=time.time()
print('선택정렬 성능 측정:', end_time- start_time)
array=[]
for _ in range(10000):
array.append(randint(1,100))
start_time=time.time()
array.sort()
end_time=time.time()
print('기본정렬 라이브러리 성능 측정', end_time-start_time)선택정렬 성능 측정: 6.479999303817749
기본정렬 라이브러리 성능 측정 0.0009605884552001953
두 배열의 원소교체
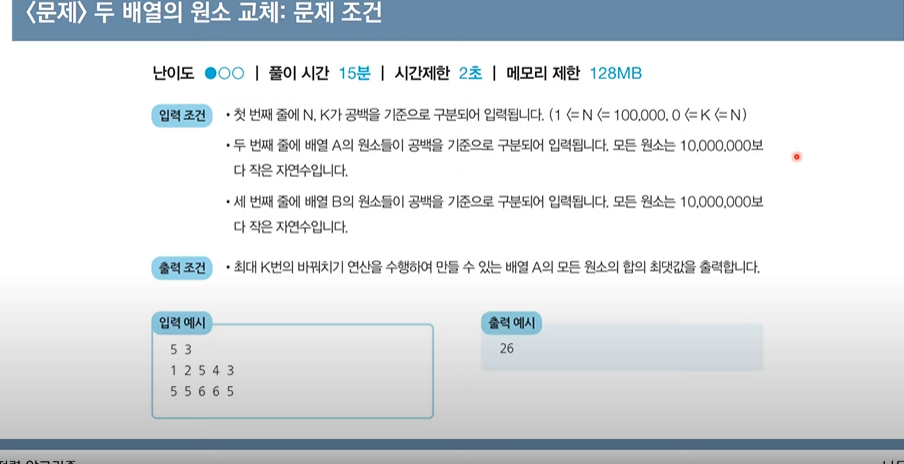


- 핵심 아이디어: 매번 배열 A에서 가장 작은 언소를 골라서, 배열 B에서 가장 큰 원소과 교체 ==> 선택정렬?
n,k=map(int, input().split())
a=list(map(int,input().split()))
b=list(map(int,input().split()))
# a는 오름차순 b는 내림차순 정렬
a.sort()
b.sort(reverse=True)
for i in range(k):
if a[i]< b[i]:
a[i], b[i]=b[i],a[i]
else: break
print(sum(a))
데이터분석