https://drhongdatanote.tistory.com/category/%ED%86%B5%EA%B3%84%20%EB%85%B8%ED%8A%B8
http://www.kocw.net/home/cview.do?cid=2df9143b54dbea7d
http://www.kocw.net/home/cview.do?cid=a18b9d7b0240ab17
- CLT, RANDOM EFFECT, GENERALIZED LINEAR MODEL 중요개념
- 통계전공이면 중심극한정리 물어본다고 한당
- 중심극한정리https://gaussian37.github.io/math-pb-central_limit_theorem/
기술통계(descriptive), 추론통계(inferential)
- 기술통계: mean, mode, median, quartile, , validation, std ,,,
- 추론통계: 수집 데이터 바탕으로 예측
- 빅데이터 3v: velocity, volume, variety
통계 기본 ( 기술통계)
- 양적자료: 숫자로 표현 (numberical)= quantitative
- 질적자료: 숫자로 표현불가(categorical)=(qualitative)
- 개체(item): 연구대상
- 요인(factor): 개체의 중요한 특성
- 변수(variable): ex) 신체조건: 키 몸무게 시력 혈액형 etc..
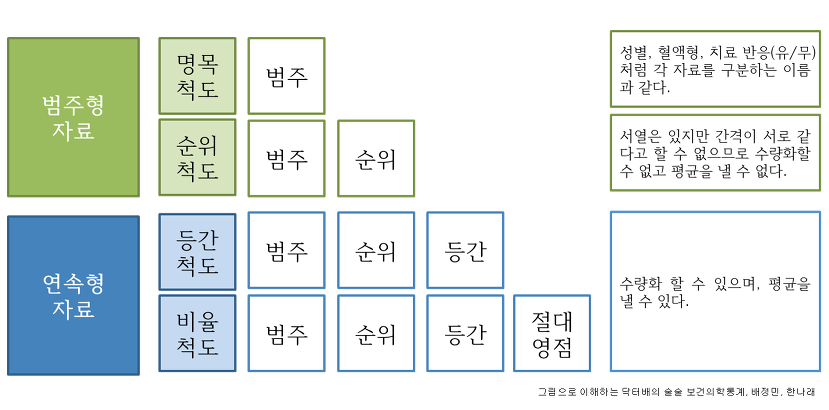
질적자료: categorical: 범주형자료
- 명목척도(nominal): 순서 없음 (구분의 의미)
- 순위척도(ordinal): 순서 있음
양적자료: numerical: 수치형자료, 연속형자료
- 등간척도(interval) : 균일 간격 (ex) 온도)
- 비율척도(ratio): 절대영점이 있음 (ex)무게, 시간): 사칙연산, 평균
독립변수: independent variable: 연구자가 의도적으로 변화
종속변수: dependent variable: 독립변수에 따라 변화
- IQ(독립변수)에 따른 시험성적(종속변수) 연구
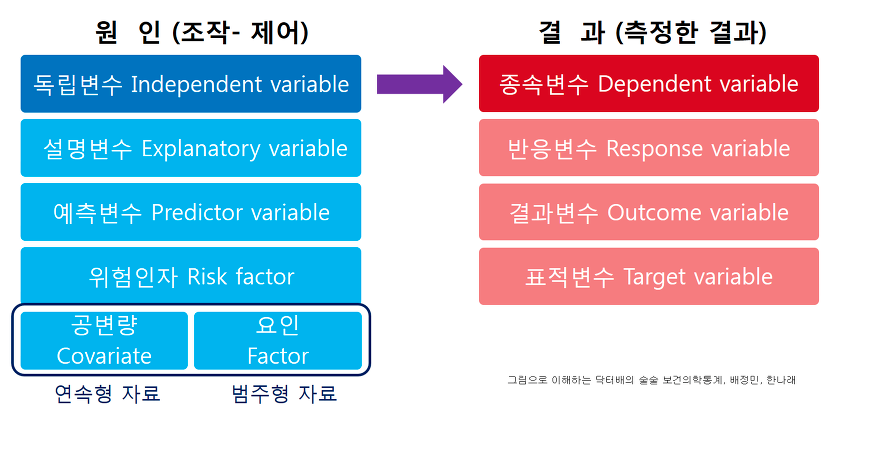
- numerical: covariance
- categorical: factor
- 도수분포표:frequency table: 빈도표: 데이터의 전체분포 파악
- 일반적으로 5~15구간 (min~ max). 되도록이면 정수, 짝수, 5의배수
- 히스토그램: 도수분포표를 bar chart로 표현
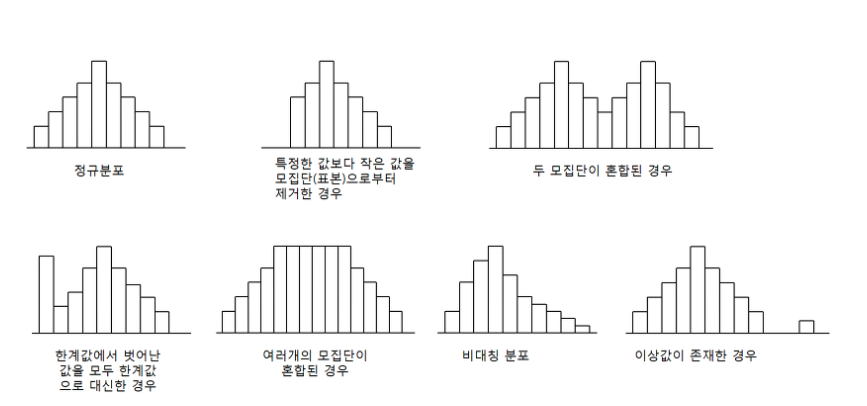
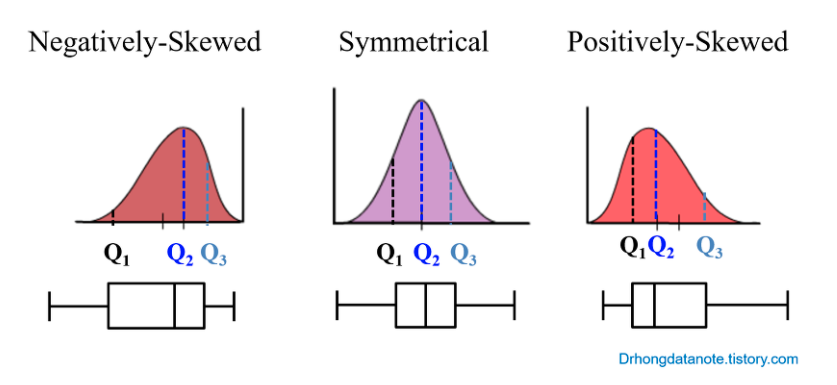
- 정규분포, tweedie(쌍봉), skewness(왜도),kurtois(첨도)
- positive skewnewss: 왼쪽으로 치우침: right skewed
- negative skew: 오른쪽으로 치우침 : left skewed
- 첨도 0: 정규분포
- 왜도 3 미만, 첨도 7 미만 => 신뢰 가능한 데이터
중심화경향: 대표값
- 평균값(mean): 정량자료 대표값
- 중앙값(median) : 순위자료 대표값
- 최빈값(mode): 명목자료 대표값

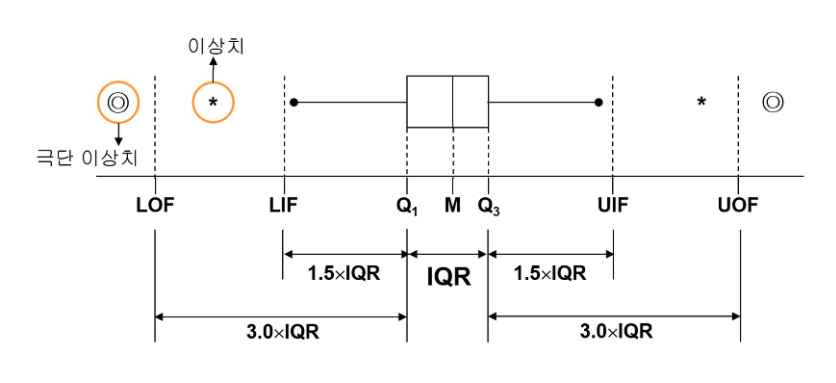
분산도: 데이터의 분포를 설명: range, quantile, variance, std
- range(최대- 최소)
- quantile: 크기순으로 정렬 => 중앙부에서 전체의 50%를 포함한 범위의 반
- deviation(편차) : '전체 평균'과 개별 데이터의 차이
- variance(분산): 편차의 제곱의 합의 평균: 편차의 합이 0이 되는것을 막기위해,,,
- std: 분산의 제곱근(단위를 위해)
** 왜 절대값의 평균을 구하지 않고 제곱의 합의 루트를 구하나?
=> 제곱이 수식계산에 용이

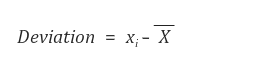

추리통계
모집단(population) : 연구자가 알고 싶어하는 집단 전체
표본(sample) : 연구자가 관찰한 집단
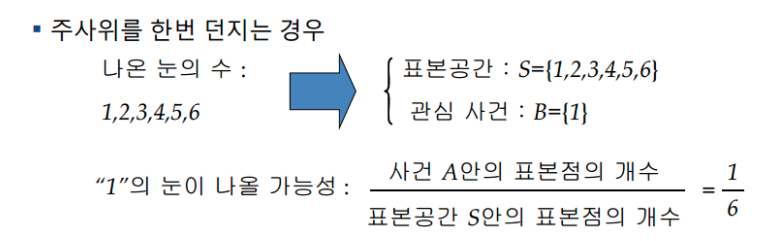
- 표본공간(sample space): 어떤 실험시 측정가능한 모든 결과들의 집합
- 사건(event): 어떤 조건을 만족하는 표본공간의 특정한 부분집합
- 확률(probability): 모든 사건에서 a사건이 일어나는 경우의 수

- 확률변수
이산확률변수(discrete random variable) : 동전/주사위 던지기
연속확률변수(continuous random variable)- 확률분포(probability distribution)
- 확률함수(probability function): 확률변수를 0~1사이에 대응


- 정규분포: 종모양(bell), 가우스분포
-- 정규분포를 이루고 있으나 평균과 표준편차가 다른 집단
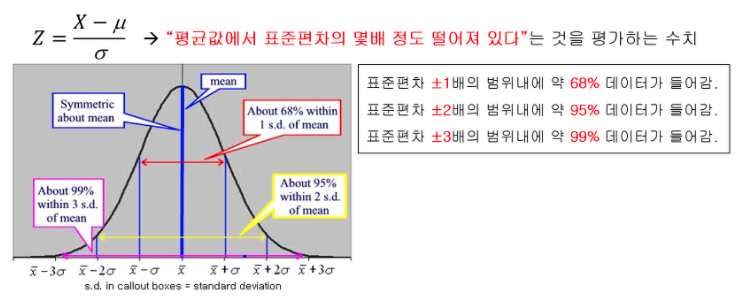
==> 다른 집단들을 비교하기 위해 표준정규분포(standard normal distribution)
: 평균 0, 표준편차 1 인 정규분포( 평균만큼 수평이동 /표준편차) => Z-score(x축)
**Z-score는 "1) 분자 부분: 어떠한 개별 데이터가 평균으로부터 얼마나 떨어져 있고 (X-\mu ), 2) 분모 부분: 그 떨어진 정도가 그 집단의 표준편차의 몇 배 정도 떨어진 것이다"- 정규분포 확률밀도 함수
정규분포는 '함수'다.
알고자하는 현상이 정규분포를 가진다면, 특정사건이 일어날 확률 예측가능- 정규분포의 확률계산 :표준정규분포로 변환한 후 적분 계산
- (Z≤1.36)

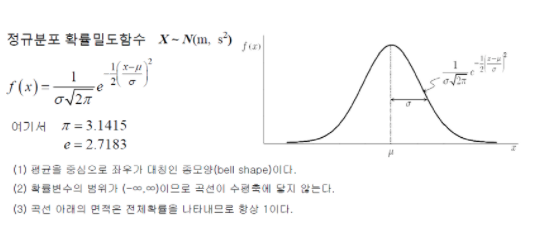
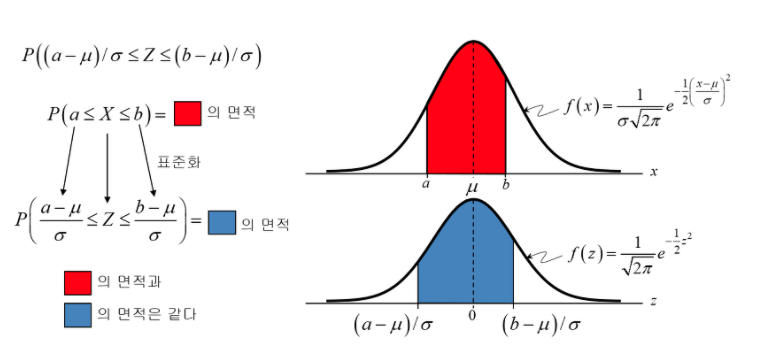

- 모집단분포
- 표본분포
중심극한정리? CTL

데이터분석