❔ Hadoop의 map/reduce와 spark의 RDD연산의 차이는 무엇일까?
-
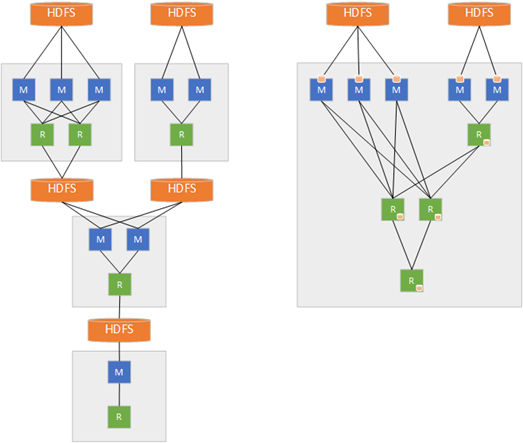
Hadoop은 mapreduce 방식으로 데이터를 분산 처리한다. 여러 곳에 분산 저장된 데이터를 처리 하기 위해 mapreduce 방식으로 데이터를 처리한다.
-
spark 역시 mapreduce 방식의 데이터처리 구조를 지원한다. spark도 여러 곳에 저장된 데이터를 처리 하기 위해 mapreduce 방식으로 데이터를 처리 할 수 있다.
- 하지만 둘의 차이는, 데이터를 메모리에 놓고 하느냐, 디스크에 놓고 하느냐.
-
Hadoop은 기본적으로 디스크로부터 map/reduce할 데이터를 불러오고, 처리 결과를 디스크로 쓴다. 따라서, 데이터의 읽기/쓰기 속도는 느린 반면, 디스크 용량 만큼의 데이터를 한번에 처리 할 수 있다.
-
반면, spark는 메모리로부터 map/reduce할 데이터를 불러오고, 처리 결과를 메모리로 쓴다. 따라서, 데이터의 읽기/쓰기 속도는 빠른 반면, 메모리 용량만큼의 데이터만 한번에 처리 할 수 있다.
결론은, spark나 hadoop이나 모두 mapreduce 방식을 지원하지만, hadoop은 디스크 기반의 mapreduce 인것이고, spark는 메모리 기반의 mapreduce 인것이다. -
Map Reduce를 사용하면 좋을 때
1) 거대한 데이터 세트의 선형처리: Hadoop Mapreduce를 사용하면 방대한 양의 데이터를 병렬로 처리 가능. 결과 데이터 세트가 사용 가능한 RAM보다 큰 경우 Hadoop MapReduce가 Spark를 능가할 수 있음.
2) 즉각적으로 결과가 필요하지 않는 경우 경제적인 솔루션이다. -
Spark를 사용하면 좋을 때:
1) 빠른 데이터 처리
2) 반복 처리
3) Spark의 RDD(Resilient Distributed Datasets)는 메모리에서 여러 맵 작업을 가능하게 하는 반면 Hadoop MapReduce는 중간 결과를 디스크에 기록해야 함.
4) 기계 학습. Spark에는 내장된 기계 학습 라이브러리인 MLlib가 있으며, MLlib에는 메모리에서도 실행되는 즉시 사용 가능한 알고리즘이 있음.
ref)
https://wooono.tistory.com/50
https://sunrise-min.tistory.com/entry/MapReduce-vs-Spark-%EB%A7%B5%EB%A6%AC%EB%93%80%EC%8A%A4%EC%99%80-%EC%8A%A4%ED%8C%8C%ED%81%AC%EC%9D%98-%EC%B0%A8%EC%9D%B4%EC%A0%90
https://3months.tistory.com/5__11
