- 사회 연결망 분석 기법을 텍스트 내 단어의 관계에 적용한 것
n-gram
import nltk
nltk.download('punkt')
from nltk import word_tokenize, bigrams
sentence = 'I am studying semantic network analysis.'
tokens = word_tokenize(sentence)
bgram = bigrams(tokens)
bgram_list = [x for x in bgram]
print(bgram_list)
어휘 동시 출연 빈도의 계수화
- 동시 출현은 두 개 이상의 어휘가 일정한 범위나 거리 내에서 함게 출현하는 것
- 단어간 동시 출현 관계를 분석하면 두 단어가 유사한 의미를 가졌는지 등의 추상화된 정보 얻는다
from nltk import ConditionalFreqDist
sentences = ['I am studying semantic network analysis.', 'I am studing Machine Learning', 'i love coding']
tokens = [word_tokenize(x) for x in sentences]
bgrams = [bigrams(x) for x in tokens]
token = []
for i in bgrams:
token += ([x for x in i])
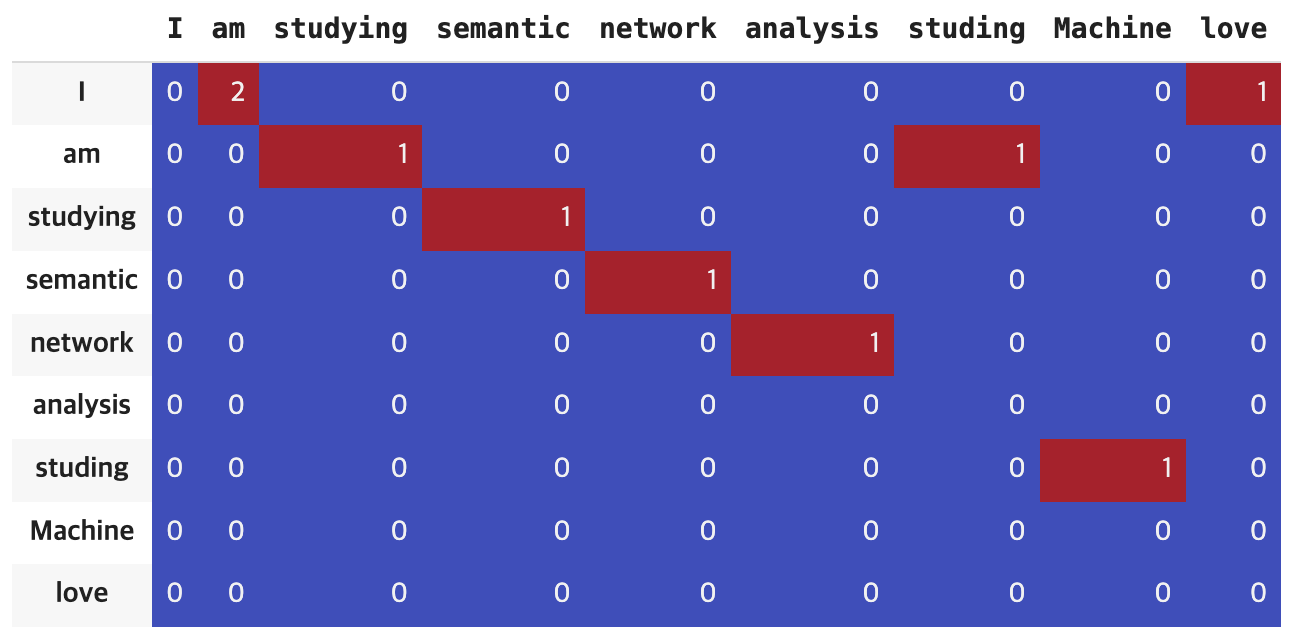
cfd = ConditionalFreqDist(token)
cfd.conditions()
token의 노드와 엣지는 다음과 같이 표현된다.
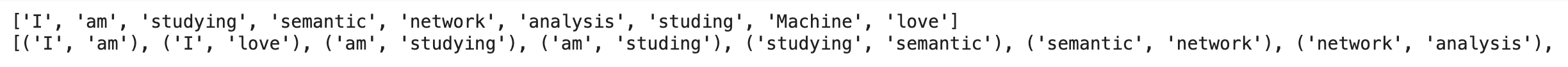
중심성(Centality) 지수
- 중심성은 전체 연결망에서 중심에 위치하는 정도를 표현하는 지표
- 특징에 따라 3개로 구분
연결 중심성(Degree Centrality)
- 텍스트에서 다른 단어와의 동시 출현 비도가 많은 특정 단어는 연결 중심성이 높다
- 주로 ( 특정 노드 i와 직접적으로 연결된 노드 수/ 노드 i와 직간접적으로 연결된 노드 수 )로 계산
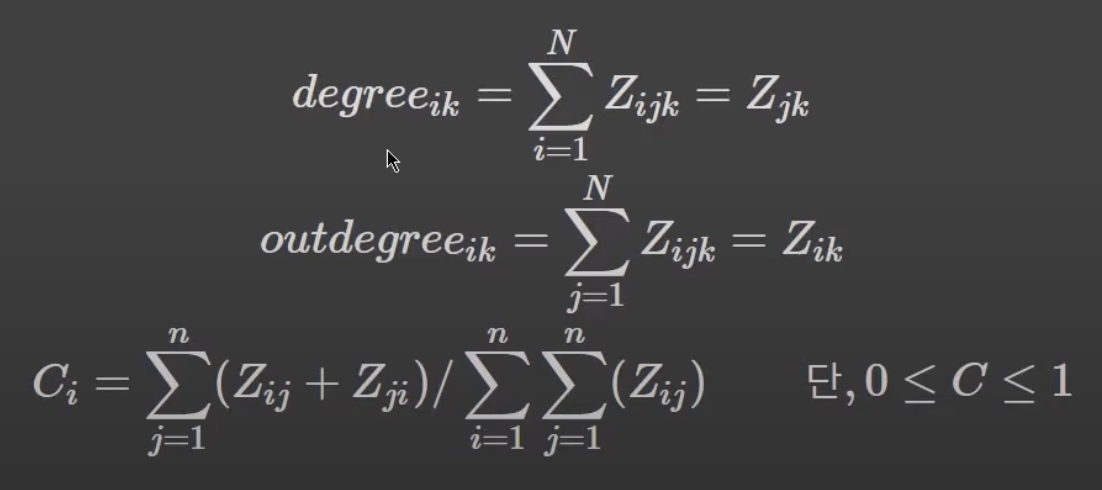
nx.degree_centrality(G)위세 중심성(Eigenvector Centrality)
- 연결된 상대 단어의 중요성에 가치
- 중요한 단어와 많이 연결되면 위세 중심성 증가
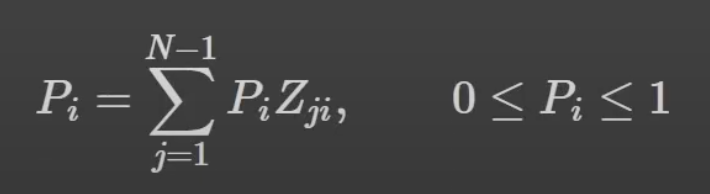
nx.eigenvector_centrality(G, weight='weight')근접 중심성(Closeness Centrality)
- 한 단어가 다른 단어에 얼마나 가깝게 있는지 측정
- 직간접적으로 연결된 모든 노드들 사이의 거리 측정
- 주로 (모든 노드 수 -1/ 특정 노드 i에서 모든 노드에 이르는 최단 경로 수를 모두 더한 수)로 계산
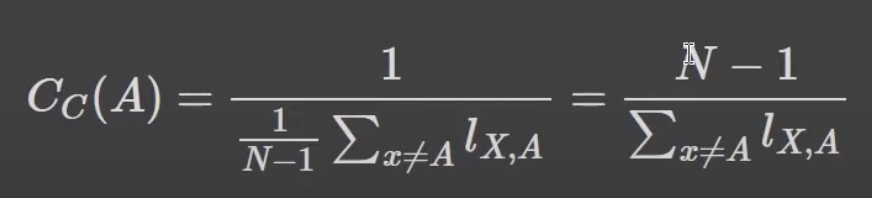
nx.closeness_centrality(G, distance='weight')매개 중심성(Betweeness Centality)
- 한 단어가 단어들과의 연결망을 구축하는데 얼마나 도움을 주는지 측정
- 모든 노드 간 최단 경로에서 특정 노드가 등장하는 횟수로 측정하며, 표준화위해 최댓값인 (N-1)*(N-2)/2로 나눈다
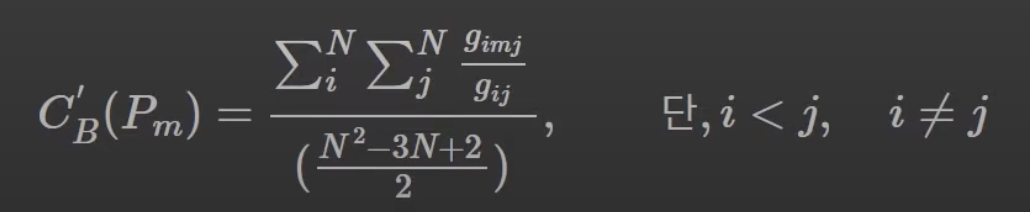
nx.current_flow_betweenness_centrality(G)페이지랭크(PageRank)
- 하이퍼링크 구조를 가지는 문서에 상대적 중요도에 따라 가중치 부여
nx.pagerank(G)
늅늅