[PintOS] PROJECT4: VIRTUAL MEMORY(Stack Growth, Memory Mapped Files, Swap In/Out) - 4주차 WIL (1)
정글

이번주에 한 것
- 파일의 내용을 물리 페이지에 매핑하고 관리하는 것 구현
- 파일 매핑 관련해서 mmap_file 이라는 구조체를 만들고 이 구조체에 어떤 페이지부터 시작인지(가상 주소 시작 주소를 저장, 그리고 어떤 file을 저장했는지 file을 저장하고, 해당 데이터를 올릴 페이지를 연결리스트로 관리했다) 그리고 mmap_file은 매핑 create 요청과 매핑 destroy 요청이 가상 주소 기반으로 오므로 가상 주소를 기반으로 찾기 위해 hash_table을 이용했다.
- 이와 관련한 fork()시에 복사와 exit()시에 데이터 해제가 복잡했다.
- Swap IN/Out 구현
- 페이지 종류에 따라 다르게 구현된다. Annon 페이지의 swap-out은 swap-disk에 작성하고, File-backed-page는 dirty-bit를 확인해서 이를 file에 반영한다.
- file_process execute 와 exit과 fork시에 swap-disk에 있는 데이터를 어떻게 할 것인과 관련 문제가 복잡했다.
- swap-disk의 해당 슬롯에 데이터를 쓸 수 있는 영역인지 없는 영역인지 확인하고, 전체swap-disk 영역을 어떤 식으로 관리할 까에 대해 비트맵을 사용하기로 했다. 어차피 페이지 단위로 swap-disk 영역에 써지니까 swap-disk는 512바이트로 4096바이트인 페이지의 1/8 이므로 disk_sector라는 인덱스의 8개 단위당 하나의 비트로 만들어 관리하고 이에 쓸 수 있는 영역인지 없는 영역인지를 true, false로 관리했다.
- 어떤 페이지를 swap-out 시킬 것인지에 대해서는 lru 알고리즘 + 더티 비트 체킹 전략을 택했다.
- lru 알고리즘을 취하되, dirty 비트가 세팅되어 있다면 file 에 써야 하는 부담이 있으므로 이를 제외한다. 단 한바퀴를 돌았을 때도 같은 상태라면 (swap-slot에 올라온 페이지가 모두 dirt bit 가 세팅 페이지라는 뜻이므로) 해당 페이지를 swap-out 한다.
정리
- stack growth 시에 rsp의 위치에 대한 의문과, rbp 사용에 대한 이해는 다음 글에 정리했다.
- fork()시에 부모의 swap-out된 페이지까지도 모두 자식에서는 물리메모리에 올리는 전략을 선택하게 된 이유는 다음 글에 정리했다.
그 외 알게 된 내용에 대해서는 아래에 정리했다.
파일 매핑된 페이지 exit()시에 매핑 해제의 시점이 중요하다
-
구현하면서 돌아가는데 왜 되는지 몰랐던 것들
-
우리조가 구현한 pintOS에는 파일을 페이지에 매핑한 페이지(Memory Mapped Files)에 대해서는 전역변수로 frame-list를 선언하고, 이로 관리했다.
- frame-list에 구조체 frame이 연결리스트로 관리되고, (frame은 실제로 물리메로리에 올라온 데이터의 물리주소를 담고있는 구조체다) 이를 초기화, 삭제를 해줘야했다.
-
이를 삭제해주는 위치 때문에 문제가 발생했다.
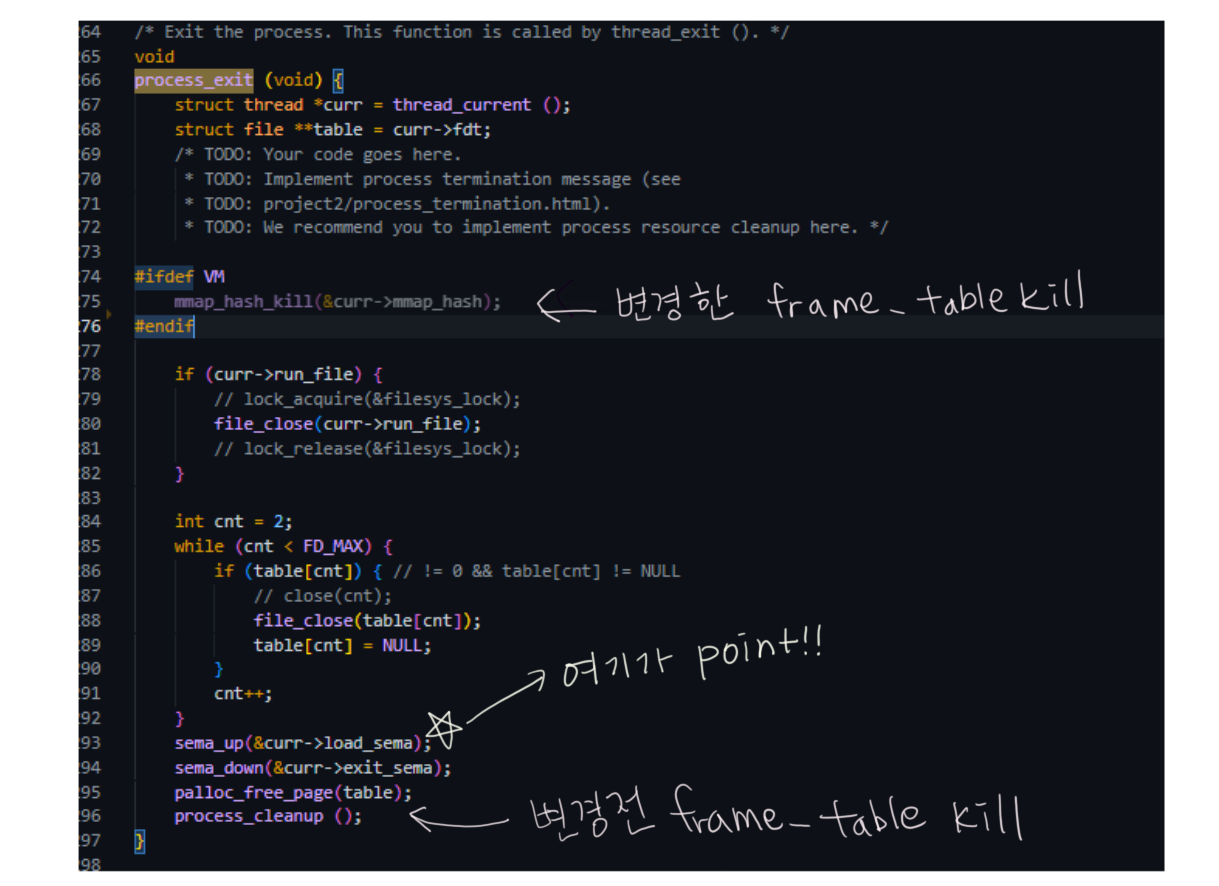
-
처음에는 프로세스가 종료될 때 호출되는
process_exit()함수에서process_cleanup()을 호출하고 이process_cleanup()에서 해당 매핑을 해제하고, 매핑 테이블(frme table)을 삭제했다.- 이는 mmap_has_kill(); 함수로 작성했다.
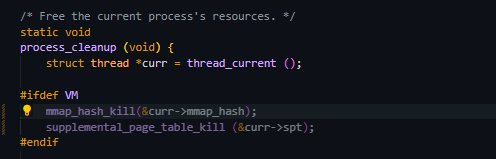
- 이는 mmap_has_kill(); 함수로 작성했다.
-
그렇지만, TEST에서 자식을 종료후 부모가 동일 파일을 확인했을 때 부모가 변경된 내용을 읽지 못하는 일이 발생했다. 왜 그런지 이런 저런 시도를 해보다가 매핑을 해제하는 (변경이 있으면 파일에 써주는 작업을 해주는) 함수를 더 일찍 선언했더니 통과되었다.
-
일단 돌아가게 하고 왜 그러는지 이해해했다.
-
핵심은 저기에 작성된
sema_up(&curr->load_sema);이었다. 지금 프로세스 종료 흐름은 자식을 fork()한 후 wait()하면 부모는 자식이 종료될 때까지 자식의 load_sema에 잠든다. 자식은 프로세스가 끝날 때 자신의 load_sema에 잠든 부모를 깨우는데sema_up(&curr->load_sema);이 때 일어난 부모가 파일을 확인하면 이전 버전에서는 아직 부모는 변경 전 파일을 읽고 있기 때문에 테스트가 실패했던 것. -
이를 위로 올려주면 부모는 변경 후의 파일을 확인하게 되므로 문제가 해결된 것이다.
-
이를 어디에 두면 될까에 대해서 생각했을 때는 부모를 깨우기 전인 load_sema up 할 때까지만 하면 된다고 생각했다.
- sema_up과 (부모를 깨운 후) sema_down(내가 잠드는) 것 전까지 하면 되지 않느냐는 동기의 질문이 있었는데 그렇게 할 시에 부모를 깨우고 내가 잠들기 전에 타임 인터럽트 등으로 내가 중단 될 경우 부모는 깨어나서 다시 내가 아직 파일에 반영하지 않는 내용들을 읽어 안될 것 같다고 답변했다.
Memory Mapping 이해 - 프로그램을 로딩하는 것도 파일 기반 페이지인데 왜 file-backed page로 관리하지 않을까 (공간 낭비 아닌가)
- 1주차에 했던 Anonymous page와 File-backed page의 구분이 잘 이해가지 않았다.
- pintOS에서는 페이지는 Anonoymous page와 File-bakced page로 구분하는데, 기본적으로 Anonymous page은 기반 파일이 없는 페이지이며 File-backed page는 파일 기반 페이지이다.
- swap-out 될 때 Anonymous-page는 swap-disk로 swap-out하고 File-backed page는 파일에 dirty bit(수정 되었느지 확인)하고 이를 변경되었다면 해당 파일을 수정하고 쫓아내는(page 정보만 남아있고, 물리 메모리에서 실제 데이터는 내쫓는)방식으로 구현했다.
- 프로그램을 로드 할 때는 기본적으로 파일에서 읽어옴에도(프로그램도 파일이니까) Anonymous page로 설정했는데 그 이유에 대해서 잘 이해가지 않았다. 파일로부터 데이터를 읽어오면 되는 것을 굳이 swap-out 디스크에서 write 하고 저장하는 오버헤드와 해당 디스크 영역을 이중으로 잡아먹는(파일이 있는 디스크 + swap disk에 올라가는 내용) 문제가 있는데 왜 그렇게 설정하는 것일까 궁금했다.
- 알아봤을 때는
프로그램 파일은 변경되면 안되는 파일이기 때문이다. - File-backed page로 관리될 경우 write 되었는지 확인(dirty 여부 확인)후 write 되었다면 이를 파일에 써야 한다.
- ELF segment 파일이 이와 같이 관리될 경우 프로그램이 손상될 수 있다. (ex. bss 경우) 그래서 이런 파일은 파일이 변경되었다고 했을 때 이를 다시 파일에 작성하면 안된다.
- 그렇기 때문에 pintOS에서는 이를 Annonymous 페이지로 관리하는 디자인을 택한 것이다.
- 여전히 낭비에 대한 의문은 있었는데 실제 linux에서는 이와 같이 관리하지 않는다고 한다. 이에 대해서
linux에서는 bss와 같은 수정이 일어나는 segment는 anonymous page로 관리하고, 다른 부분은 file-backed page로 관리한다고 한다.- 리눅스에 대한 부분과 해당 의문에 대해서 지난 기수에 이와 관련했던 질문에 대한 블로그 글을 보면서 이해했다. https://campkim.tistory.com/52
