0. 링크
https://spring.io/blog/2018/09/24/spring-data-jdbc-references-and-aggregates
0. 관련된 호눅스 수업
https://velog.io/@bongf/codesquad-lecture-210427-banchan-2-2-jdbc
1. Aggregate root로 묶인 예시 : PurchaseOrder과 Order
- aggregate root는 purchaseOrder.
- purchaseOrder는 orderItem을 Set로 갖느다
class PurchaseOrder {
private @Id Long id;
private String shippingAddress;
private Set<OrderItem> items = new HashSet<>();
void addItem(int quantity, String product) {
items.add(createOrderItem(quantity, product));
}
private OrderItem createOrderItem(int quantity, String product) {
OrderItem item = new OrderItem();
item.product = product;
item.quantity = quantity;
return item;
}
}class OrderItem {
int quantity;
String product;
}- 여기서 repository는 purchaseOrder만 갖는다.
- orderItem에 접근하려면 purchaseorder에 접근해야 한다.
interface OrderRepository extends CrudRepository<PurchaseOrder, Long> {
@Query("select count(*) from order_item")
int countItems();
}Also, if you delete the PurchaseOrder, all its items should get deleted as well. Again, that’s the way it is.
- purchaseOrder를 삭제하면 그것의 아이템들(orderItem)도 삭제된다. orderItem의 생명주기는 purchaseOrder에 의존하게 된다.
…
repository.delete(saved);
assertThat(repository.count()).isEqualTo(0);
assertThat(repository.countItems()).isEqualTo(0);
}2. Many To Many 관계 : Book과 Author : 하나의 aggregate root로 묶일 수 없는 관계
- Book도 여러 명의 작가를 set으로 가진다.
class Book {
// …
Set<Author> authors = new HashSet<>();
}When a Book goes out of print, you delete it. And gone are all the Authors. Certainly not what you intended, since some of the Authors probably wrote other books as well. Now, this doesn’t make sense. Or does it? I think it does.
- 하지만 작가는 여러 책을 쓸 수 있다. 그러면 Book을 삭제했을 때 작가가 삭제되면 안되는 문제가 발생한다. 같은 aggregate root로 묶을 수가 없다.
An aggregate is a cluster of objects that form a unit, which should always be consistent. Also, it should always get persisted (and loaded) together. It has a single object, called the aggregate root, which is the only thing allowed to touch or reference the internals of the aggregate. The aggregate root is what gets passed to the repository in order to persist the aggregate.
- 어그리게잇은 강한 일관성이 있어야 하는 데이터의 집합니다. (예. 주문과 재고사이)
This brings up the question: How does Spring Data JDBC determine what is part of the aggregate and what isn’t? The answer is very simple: Everything you can reach from an aggregate root by following non-transient references is part of the aggregate.
With this in mind, the behavior of the OrderRepository makes perfect sense. OrderItem instances are part of the aggregate and, therefore, get deleted. Author instances, conversely, are not part of the Book aggregate and, therefore, should not get deleted. So they should simply not get referenced from the Book class.
3. 그러면 Book과 Author는 어떻게 묶지?
- This applies to all kinds of many-to-x relationships.
If multiple aggregates reference the same entity, that entity can’t be part of those aggregates referencing it since it only can be part of exactly one aggregate. Therefore any Many-to-One and Many-to-Many relationship must be modeled by just referencing the id.
-
여러 개의 aggregates가 하나의 entity를 참조할 때 그 entity는 그 어그리케이트들의 part가 될 수 없다.
-
many to one과 many to many관계는 id로 참조해야 한다.
- 그리고 이때는 consistency를 지원해주지 않는다.
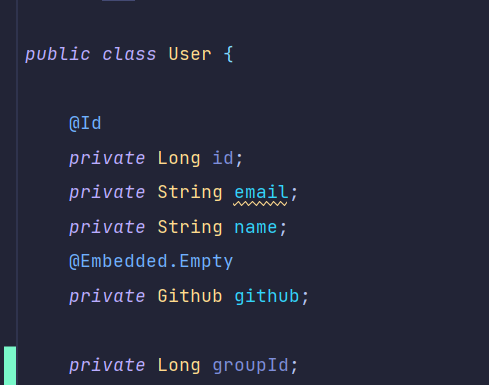
- 참고. many-to-one ) 호눅스 수업에서 group과 user가 mamy - to - many 관계이다. 그래서 user가 group을 id로 갖는다.

-
이 문서에 나온 예시 (many-to-many)
Purchase_Order (
id
shipping_address
)
Order_Item (
purchase_order
quantity
product
);
Book (
id
title
)
Author (
id
name
)
Book_Author (
book
author
)-
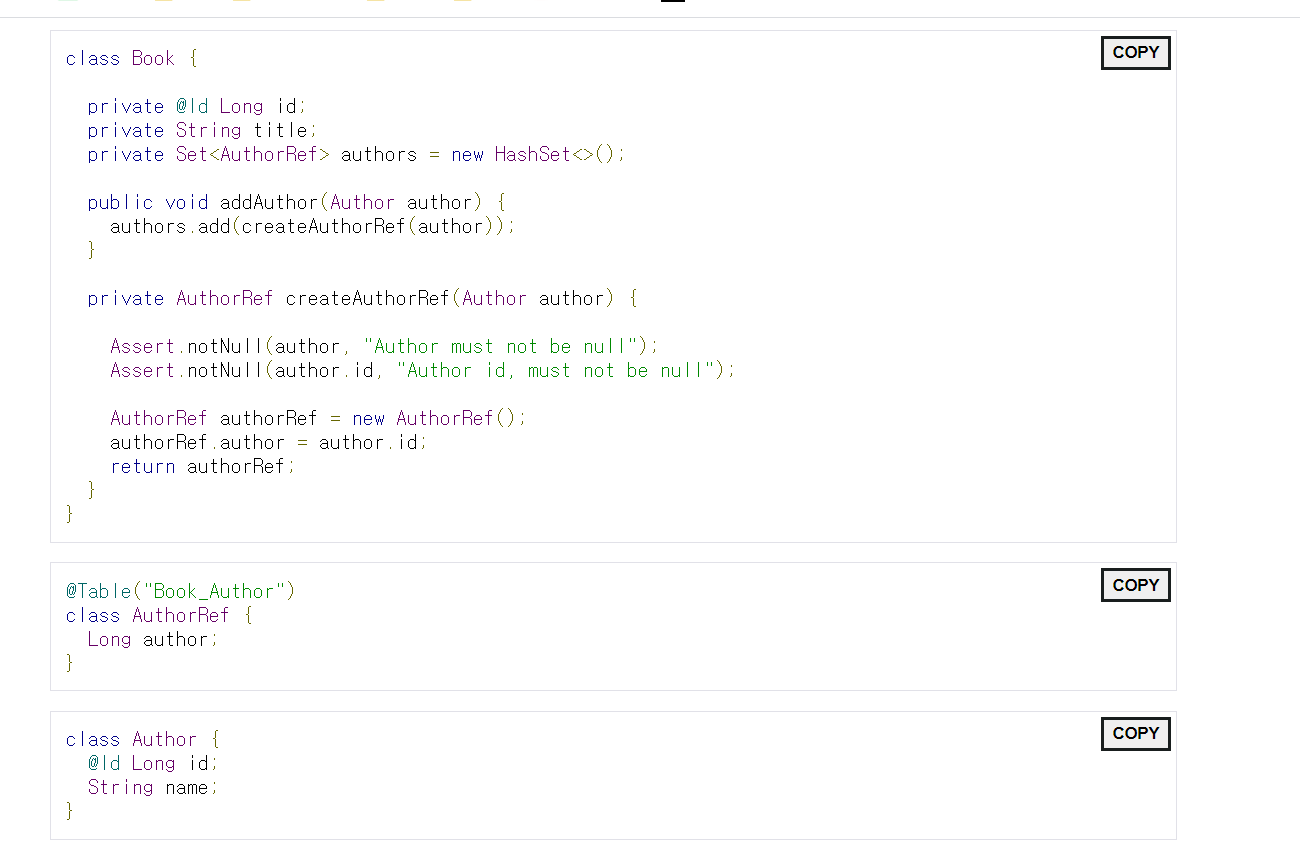
AuthorRef라는 새로운 클래스를 만든다. 이는 Author의 id를 갖도록 한다. 그리고 이 Book을 AuthorRef를 Set으로 갖는다.
-
그리고 Book이 AuthorRef를 생성하는 메소드를 private으로 갖는다. addAuthor을 하면 AuthorRef를 생성해서 이를 set으로 갖는 방식
-
그러면 아래와 같이 사용된다.
@Test
public void booksAndAuthors() {
Author author = new Author();
author.name = "Greg L. Turnquist";
author = authors.save(author);
Book book = new Book();
book.title = "Spring Boot";
book.addAuthor(author);
books.save(book);
books.deleteAll();
assertThat(authors.count()).isEqualTo(1);
}To wrap it up: Spring Data JDBC does not support many-to-one or many-to-many relationships. In order to model these, use IDs.
- 요약 Spring Data JDBC는 many-to-many, many-to-many를 지원하지 않는다. id를 사용해라
