weight and bias tutorial
weight and bias example
- Build better models more efficiently with Weights & Biases experiment tracking.
- official document
W&B Platform
-
Experiments
- 머신러닝 모델 실험을 추적하기 위한 Dashboard 제공.
-
Artifacts
- Dataset version 관리와 Model version 관리.
-
Tables
- Data를 loging하여 W&B로 시각화하고 query하는 데 사용.
-
Sweeps
- Hyper-parameter를 자동으로 tuning하여 최적화 함.
-
Reports
- 실험을 document로 정리하여 collaborators와 공유.
Step 1)
1) https://wandb.ai/site, wandb 홈페이지에 들어가 회원가입을 합니다 (API key 생성위함)
2) (커맨드라인) pip install wandb , wandb 패키지를 설치합니다.
3) wandb 연동하기 , 최초 1회 회원가입시 발급받은 api key를 이용하여, wandb repo와 local 컴퓨터를 연결합니다.
+ 또는 python script 안에 wandb를 포함한 코드가 있을시 그때 api key 요청이 들어오면 해도 됩니다.
Step 2) 기본 코드 세팅
1) wandb.init() : wandb 프로젝트를 생성하고 초기화 합니다.
+ ex) wandb.init(project="my-awesome-project") 명령 실행시, wandb 레포에 my-aswesome-project 폴더가 생성됩니다.2) wandb.finish() : wandb 프로젝트가 끝날시 종료명령을 내립니다.
3) wandb.log() : 사용자가 추적하고 싶은 metric을 반복스탭마다 저장합니다.
+ ex) wandb.log({'mean_reward': np.mean(reward_buffer),
'mean_error': np.mean(error_buffer)})
+ dictionary type으로, 저장이름 : scalar 값을 줘야 합니다.
+ 그림을 저장하고 싶을 경우(matplotlib), wandb.log({file_name: wandb.Image(fig)}) wandb.Image로 wrapping 해줘야 합니다.
Step 3) Code example
- see example : https://wandb.ai/bongseokking/dc-dc-converter?workspace=user-bongseokking
- 기본적인 큰 틀은 wandb.init() -> wandb.log() -> wandb.finish()로 이어집니다.
- 세부적인 사항은 official documnet를 참조하시길 바랍니다. (하이퍼 파라미터 베이지안 오토 튜닝 등)
# argument parser
parser = argparse.ArgumentParser()
parser.add_argument("--window_size", default=4, type=int)
parser.add_argument("--episode_num", default=3000,type=int)
parser.add_argument("--test_num", default=100,type=int)
parser.add_argument("--batch_size", default=128,type=int)
parser.add_argument("--alpha", default=0.0001,type=float)
parser.add_argument("--beta", default=0.0001,type=float)
parser.add_argument("--buffer_size", default=1000000,type=int)
parser.add_argument("--update_interval", default=5,type=int)
args = parser.parse_args()
# experiment
total_run = 5
for run in range(total_run):
experiment_id = datetime.datetime.now().strftime("%Y_%m_%d_%H_%M")
experiment_id
directory = './'+experiment_id
try :
if not os.path.exists(directory) :
os.makedirs(directory)
except OSError :
print ('Error: Creating directory. ' + directory)
agent = Agent(alpha=args.alpha, beta=args.beta,
input_dims=[args.window_size*3], tau=0.01, batch_size=args.batch_size,
layer1_size=64, layer2_size=64,max_size=args.buffer_size, chkpt_dir=directory,
noise=0.05, n_actions=1,warmup=1000,update_actor_interval=args.update_interval)
Env= env()
# project 생성, name : 실험 이름
wandb.init(
project='dc-dc-converter',
name = f'experiment_{experiment_id}',
)
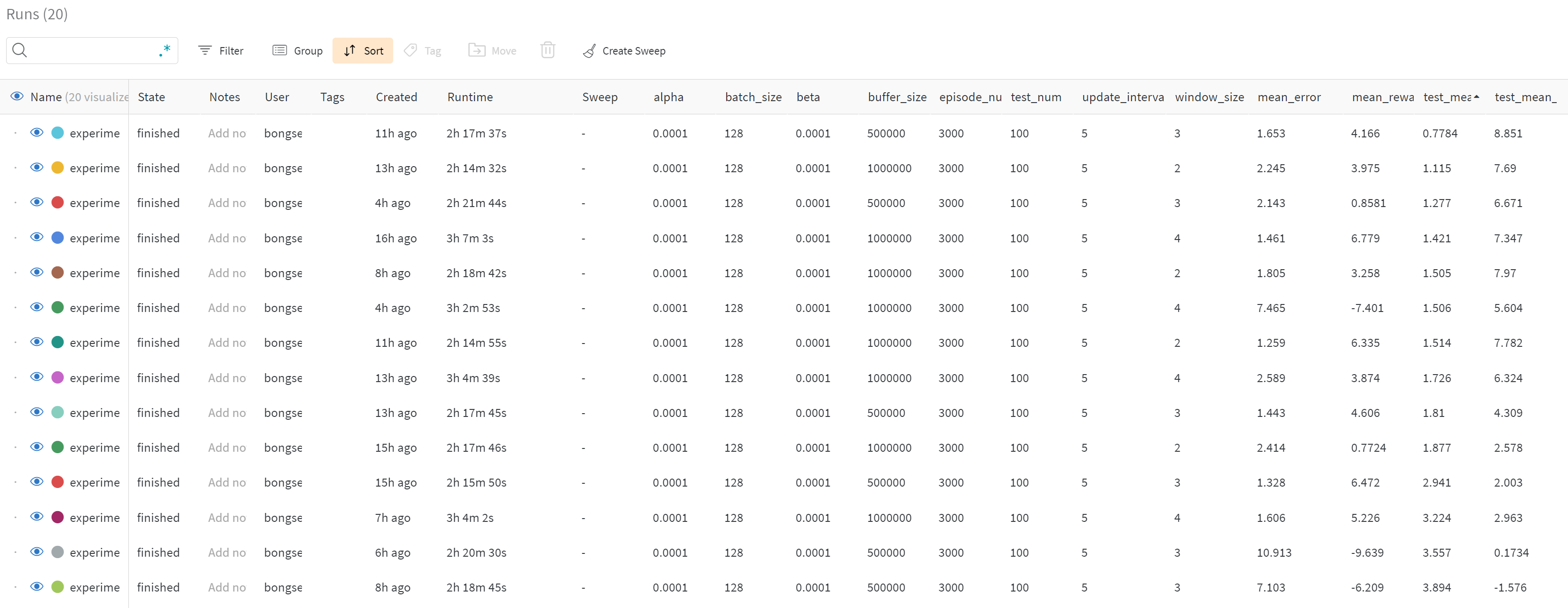
# argument parser로 입력한 parameter 값들을 config에 추가함 -> 프로젝트 실험페이지에 파라미터 세팅 정보를 업데이트 할 수 있음
wandb.config.update(args)
epi_reward,epi_action,epi_state = train(Env=Env, agent=agent,args=args)
plot_result(epi_reward,epi_action,epi_state)
agent.load_models()
test_epi_reward, test_epi_action,test_epi_state= test(Env=Env, agent=agent,args=args)
plot_result(test_epi_reward, test_epi_action,test_epi_state, train=False)
# 실험 종료
wandb.finish()
if __name__=="__main__":
main()
code log 남기기
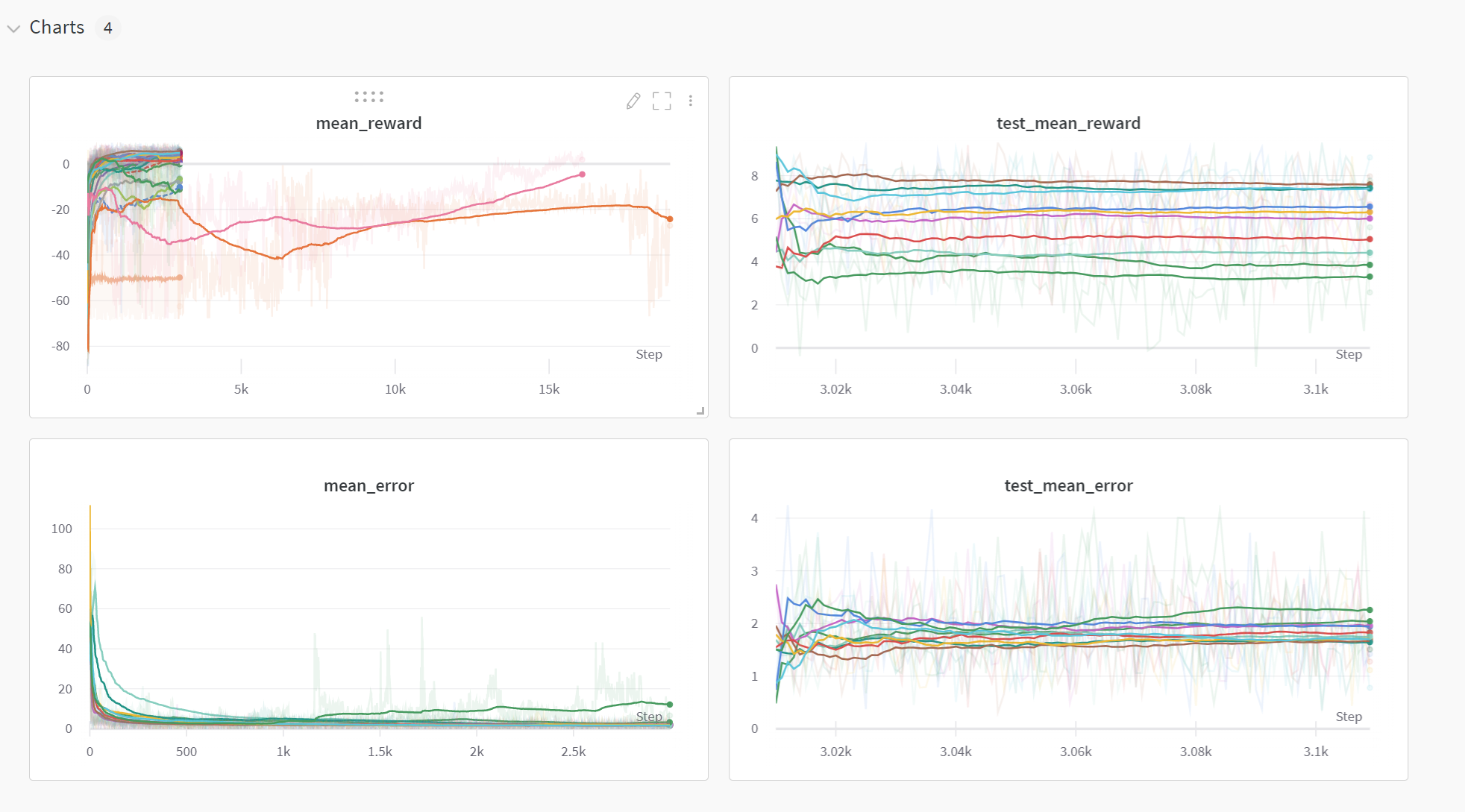
- 원하는 메트릭 scalar 값을 매 iteration마다 넘겨줘야하며, 이는 실시간으로 wandb 프로젝트 홈페이지에서 확인이 가능합니다
for j in range(episode num):
state_concate = np.concatenate(state_representation)
il,v,target =state
error = abs(v-target)
error_buffer.append(error)
state_buffer.append(state)
act = agent.choose_action(state_concate)
next_state, reward, done = Env.step(action=np.clip(a=act[0],a_min=0,a_max=1))
state_representation.append(next_state)
new_state_concate = np.concatenate(state_representation)
reward_buffer.append(reward)
action_buffer.append(np.clip(a=act[0],a_min=0,a_max=1))
agent.remember(state_concate, act, reward, new_state_concate, done)
agent.learn()
if done :
epi_reward.append(np.sum(reward_buffer))
epi_state.append(state_buffer)
epi_action.append(action_buffer)
epi_error.append(np.mean(error_buffer))
avg_reward = np.mean(epi_reward[-30:])
print(f'epi: {i}, avg_reward :{avg_reward:.3f} final_state : {state} final_action:{act}, final time_t :{j}, avg_error = {np.mean(epi_error):.3f}')
break
if i >30 and avg_reward > best_score :
print(f"--------------- save model :{avg_reward :.3f} , best:{best_score :.3f} --------------------- ")
best_score = avg_reward
agent.save_models()
state = next_state
# 매 episode가 끝날시 log를 저장합니다
wandb.log({'mean_reward': np.mean(reward_buffer),
'mean_error': np.mean(error_buffer)})
