Application Service 메소드 시그니처 설계
Application Service 메소드 시그니처 설계의 2가지 방식을 먼저 비교해 보자.
2가지 방식 비교
Application Service의 메소드를 설계하는 2가지 방법이 있다.
1. 서비스를 Delegator 라고 여기고 설계하기
2. 서비스를 고수준 레이어로 바라보고 설계하기
2번에 중점적으로 설명을 하려 한다.
이후 2번 설계방식이 헥사고날 아키텍처의 어떤 부분과 닿아있는지도 알아보겠다.
1. 서비스를 Delegator 라고 여기고 설계하기
컨트롤러는 서비스에 모든걸 위임하는 패턴이다.
Service 메소드 시그니처가 Req와 Res 를 반환 한다.
따라서 컨트롤러가 가볍다.
// Controller method
@GetMapping
Response get(Request req) {
return service.get(req); // 컨트롤러 코드가 가볍다
}대신 다음과 같이 Service가 좀더 무겁다.
Req를 해석해서 Creteria를 만들어야 하고, Res를 완성해서 반환 해야 한다.
// Service method
Response get(Request req) {
DomainModel model = find(Creteria.from(req)); // Req를 질의객체로 해석
return Response.from(model); // Res로 변환처리
}2. 서비스를 고수준 레이어로 바라보고 설계하기
presentation 계층의 모델을 주고받지 않도록 한다.
Service 메소드 시그니처 에는 Req와 Res가 존재하지 않는다.
때문에 Result 라는 별도의 dto를 반환하고, Controller에서 다시 Response객체로 변환 해야 한다.
// Controller method
@GetMapping
Response get(Request req) {
Result result = service.get(Creteria.from(req));
return Resopnse.from(result);
}Service 레이어 에서는 Req, Res 에 대한 의존성이 없으며 import조차 할수 없도록 한다.
기왕이면 모듈로 완벽히 의존성 방향을 정해두는것이 좋다.
Result와 Creteria는 모두 Service 레이어에 있는 객체다.
// Service method
Result get(Creteria creteria) {
DomainModel model = find(creteria);
return Result.from(model);
}두 방식의 차이점 정리
기본적으로 코드의 총량은 1번 방식이 간결하다.
컨트롤러가 많은 일을 하는 패턴은 MVC 패턴이 익숙한 사람이라면 낯설어 하는 편 인것 같다.
모델이란것이 Controller 내부에 여기저기 돌아다니고 있기 때문일까?
그러나 내생각은 좀 다르다.
헥사고날 아키텍처이나 어니언 아키텍처 같은 Domain Model 을 보호하는 아키텍처 패턴 이라면 의존성 방향을 중시한 설계 어색하지 않다.
고수준의 레이어인 어플리케이션 레이어를 지키기 위한 완충제 (ACL, adaptor) 역할을 하기 위해 어쩔수 없는 변환 처리가 수반된다.
나는 고수준 이라는 용어에 촛점을 맞추고 싶다.
2번 방식은 Inbound 과정에서 고수준을 보호하는 방법이다.
고수준 설계란?
위에서 2번 방식을 통해 Inbound 과정에서 고수준을 보호하는 방법을 알아봤다.
Inbound란 컨트롤러 -> 서비스 호출되는 과정이다.
이제 Outbond 과정에서 고수준을 보호하는 방법 을 알아보자.
Outbound란 서비스 -> 리파지토리 (or 도메인서비스, 외부 호출 등) 과정이다.
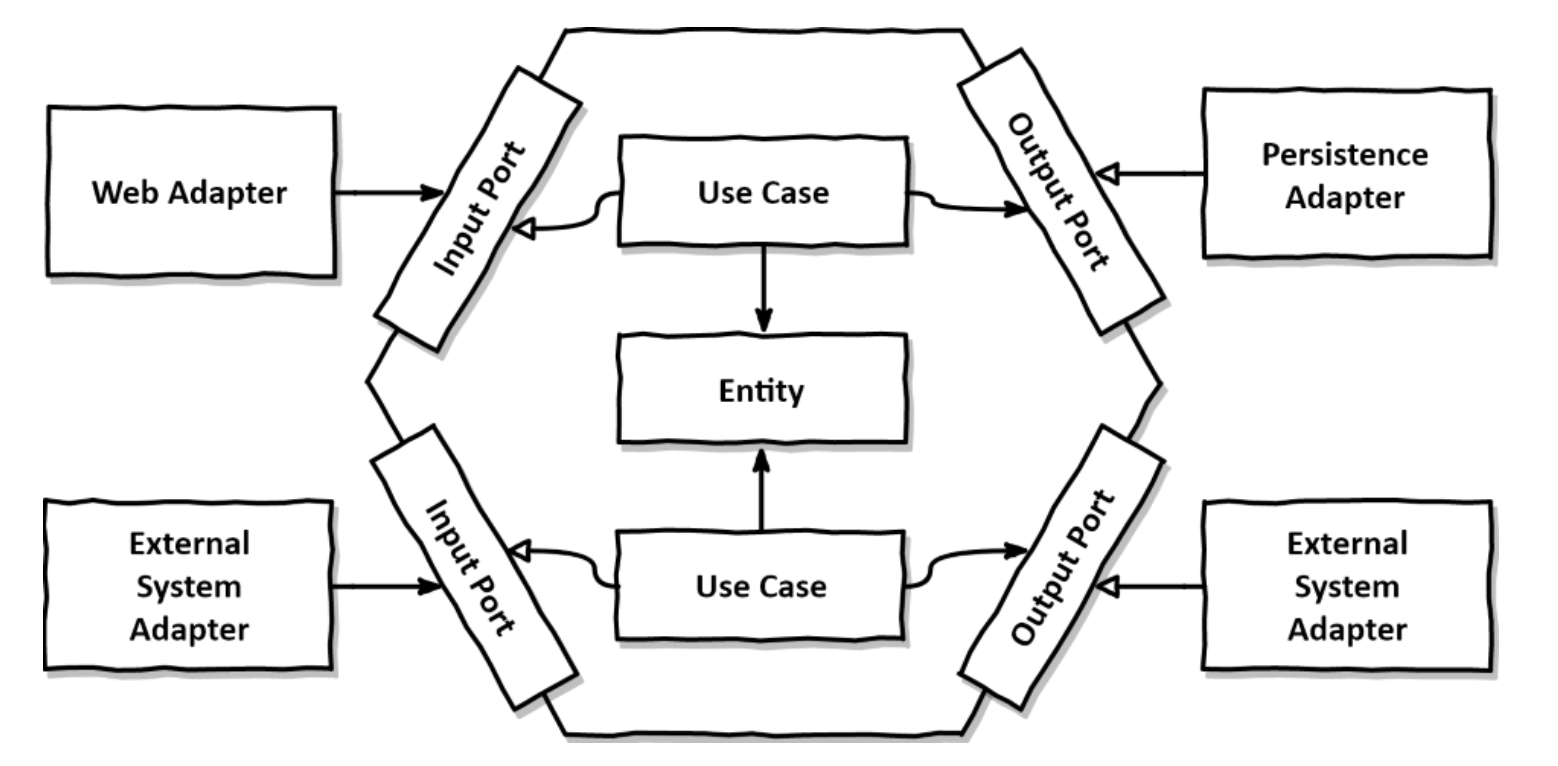
그림 출처 : https://www.dineshonjava.com/a-practical-example-of-hexagonal-architecture-in-java/
adaptor는 port를 의존 한다.
또한 outbound 에서는 의존성 역전.
보통 Service + Impl 구조를 갖고 있다면 Port & Adaptor 를 이미 구현하고 있다고 볼수 있다.
Port의 위치는 Applicaiton 레이어에 있는게 좋은데, 위치는 그다지 중요하지 않다.
메소드 시그니처가 어떤 수준으로 작성되어있느냐가 핵심이다.
이외에 고수준으로 Applicaiton 을 써 내려가는것이 아니라 세부적인것에 의존하는 케이스들을 모아본다.
Case1. 세부적인 쿼리 핸들링
다음과 같이 2번의 조회를 하고 한번에 업데이트를 한다고 하자.
// Bad
void doSomething() {
List<Model> part1 = repository.get(조회조건1);
List<Model> part2 = repository.get(조회조건2);
concat(part1, part2).foreach(x -> update(x));
}이것은 repository를 dao로 바라봤기 때문이다.
세세한걸 핸들링 하지 말고 다음과 같이 필요한걸 말하면 된다.
// Good
void doSomething() {
List<Model> all = repository.get(조회조건1, 조회조건2); // "내가 필요한걸 줘"
all.foreach(x -> update(x));
}Case2. 묻지말고 말하라
Case1과 비슷하다.
아래는 아무 의미없는 imperfects 를 일단 범용적인 쿼리로 가져온뒤 필요한 도메인모델로 가공하는 작업이다.
// Bad
void 주문별_아이템_목록_조회(조회조건) {
List<Order> imperfects = repository.get(조회조건);
Map<주문아이디, List<Item>> perfects = imperfects
.필터처리()
.값객체로_매핑()
.주문아이디별_아이템_toMap(Item_정렬조건());
}이 로직은 "Order목록을 줘. 어떤어떤건 걸러야해. aggregate 전체가 필요한건 아니고 Item 값객체만 필요해. 그런데 주문아이디별로 볼수 있게 Map 으로 반환할거야. Item 정렬은.." 라고 읽을수 있다.
위 방식 보다는 그냥 use case 에 최적화 하여 가져오면 된다.
세부적인건 implement를 보면 된다.
// Good
void getByUseCase(조회조건) {
Map<주문아이디, List<Item>> perfects = repository.getByUseCase(조회조건); // "주문별 Item 목록 줘"
}예시를 repository가 아니라 domain service라고 생각하면 좀 덜 어색할수 있다.
repository를 얼마나 고수준의 컴포넌트로 보느냐에 따라 논란이 될수 있다.
요약
table gateway 인지? repository pattern 인지?
전자라면 쿼리를 잘게 분해하여 SRP 를 지키도록 한다.
후자라면 서비스를 얇게 하게 유지하도록 하자. 불필요한 로직은 세부 구현영역으로 숨기자.
정리
고수준에서 저수준으로 흐르는 설계를 하다보면 자연스럽게 헥사고날 아키텍처가 된다.
또한 외부 계층과 루즐리 커플링이 되고 테스트 용이성이 좋아지며 유연함이 좋아지고 복잡성이 낮아진다.
부록
부록1 - Application Service가 Entity를 주고 받아도 되는가?
Applicaiton Service는 어플리케이션 내부의 모든 모델을 표현해도 되지 않을까?
adaptor 계층을 제외한 어플리케이션 내부의 모든 언어를 써도 될까?
이것은 레이어의 측면에 그럴듯 해 보인다.
하지만 개인적으로 적극 반대하는 몇가지 이유가 있다.
1. Entity는 Immutable 하지 않다.
2. Entity는 lazy loading을 지원해야 한다.
컬렉션지향 vs 영속성 지향 비교.
암시적 추적이라고 표현하고 있는데 JPA 의 더티체킹정도를 떠올리면 된다
두 문제 모두 Entity가 기술적 용어인 @Transacional과 밀접한 커플링이 있다는데 있다.
먼저 1번의 이유로는 JPA Entity인 컬렉션지향 레포지토리의 암시적 추적 특성 때문 이다. (사실 2번도 컬렉션지향의 특성 때문에 발생)
아래는 의도치 않은 delete가 발생한다.
class OrderService {
Order getOrder() {
Order order = find(id);
return order;
}
}
class Component {
private fianl OrderService orderService;
@Transaciontal
void 로그가_포함된_사소한_작업() {
Order order = orderService.getOrder();
List<LineItem> 라인_아이템 = order.lineItems();
// 단순히 일부 로깅을 해본건데 의도치 않은 delete 발생
List<LineItem> 부분_라인_아이템 = list.removeAll(제외_시키고싶은_리스트);
log.info(부분_라인_아이템);
}
}
물론 로그가포함된사소한_작업 메소드의 delete dml은 @Transactional 이 없다면 정상동작하지 않을것이다.
하지만 @Transactional 이 있을때만 동작하고, 없을땐 제대로 동작하지도 않는다는것은 아이러니 하게도 강한 의존성을 갖고 있다고 볼수 있다.
@Transactional 을 가질수 없는 계층으로 반환 하는것은 책임질 수 없는 일을 하는것이다.
부록2 - @Transactional이 안티 패턴이 될수있는 이유
부록1에서 설명한 2가지 문제를 설명했다.
가장 고수준인 Application Service와 Domain Service를 보호하기 위해 트랜잭션 처리과정을 AOP 로 기술적인것을 눈에 안보이게 하는데는 성공했다.
그러나 컬렉션 지향 repository를 지원하는데 가장 핵심적인 기능이 되었고, 아이러니하게 커플링을 만들게 되었다.
다른 맘에 들지 않는 점으로는 ACID의 달콤함에 빠지게 된다.
all or nothing은 매우 매력적인데, 모든 command 로직을 한 트랜잭션으로 묶고 싶은 욕구가 생기게 된다.
이는 다음과 같은 문제가 생긴다.
- command 메소드는 안에는 여러 Aggregate 액세스가 필요하게 되고 복잡도가 증가한다.
- event로 분리하거나 아예 별도 서비스로 분리할때 어렵다.
- 부분실패가 정답인 경우가 많다.
- 의외로 all or nothing 을 반드시 만족하지 않아도 되는 기획도 가능하다. 보통 개발자들이 더욱 두려워 한다.
이벤트 드리븐으로 작성하여 커맨드 로직을 얇게 하게 유지하는 법은 추후 정리 해야겠다.
