Prophet을 활용한 시계열의 예측
앞선 2-2에서 우리는 서울열린데이터광장에서 날짜별 행정구의 유동 인구 자료를 크롤링하여 csv파일로 저장하였다. 그리고 이제 저장된 csv파일을 바탕으로 미래의 유동인구를 예측하는 프로그램을 만들어보도록 하겠다.
먼저, 코드를 작성하기 이전에 우리는 Prophet 알고리즘에 대해서 알아야 할 것이다. Prophet 알고리즘은 Facebook이 만든 시계열 예측 라이브러리로 R과 Python으로 사용할 수 있다. Arima 등의 다양한 시계열 모형이 존재하지만, Prophet의 사용법이 간단할 뿐만 아니라 높은 정확도를 가지며, 불규칙적인 주기를 다룰 수 있다는 점에서 우리는 Prophet을 선택하였다. 하지만 Prophet은 내부 알고리즘을 공개하지 않기 때문에 실제로 코드 내에서 어떻게 작동하는지는 알 수가 없다.
그럼 이제 Prophet을 활용하여 코드를 작성하여 보도록 하자.
import pandas as pd
import numpy as np
from fbprophet import Prophet
data = pd.read_csv(r"C:\Users\Desktop\3학년\AI\생활인구\openapi.csv")
populationDF = pd.DataFrame(columns=['date'])
def prediction(gucode,guDF):
df = pd.DataFrame({'ds':data['Date'], 'y':data[gucode]})
m = Prophet()
m.fit(df) #fit() : 데이터 훈련.
future = m.make_future_dataframe(periods=72, freq='d')
pre_future = m.predict(future)
population = pre_future[['ds', 'yhat']].tail(62)
guDF[gucode] = np.nan
guDF[gucode] = population['yhat']
guDF['date'] = population['ds']
guDF = guDF.rename({'ds':'date', 'yhat':gucode}, axis = 'columns')
prediction('11000', populationDF)
prediction('11110', populationDF)
prediction('11140', populationDF)
prediction('11170', populationDF)
prediction('11200', populationDF)
prediction('11215', populationDF)
prediction('11230', populationDF)
prediction('11260', populationDF)
prediction('11290', populationDF)
prediction('11305', populationDF)
prediction('11320', populationDF)
prediction('11350', populationDF)
prediction('11380', populationDF)
populationDF.to_csv(r"C:\Users\Desktop\3학년\AI\생활인구\predictedPopulation.csv", index=False)Prophet은 시계열을 ds로, 예측하고자 하는 값을 y로 넣어주어야 한다. make_future_dataframe은 예측 날짜 구간을 설정한다. 우리는 periods=72, freq='d'로 설정하여, 1일을 간격으로 데이터를 생성하였다. predict는 신뢰 구간을 포함하여 예측을 실행한다. yhat이 실제 예측 결과이며, yhat_lower는 예측의 최소값, yhat_upper는 예측의 최대값을 뜻한다. 우리의 경우, yhat값만을 추출하여 새로운 csv파일에 저장해주었다.
유동인구 예측값이 담긴 csv 파일을 DB에 저장하도록 하자. 여기서 우리는 mysql을 사용하였다.
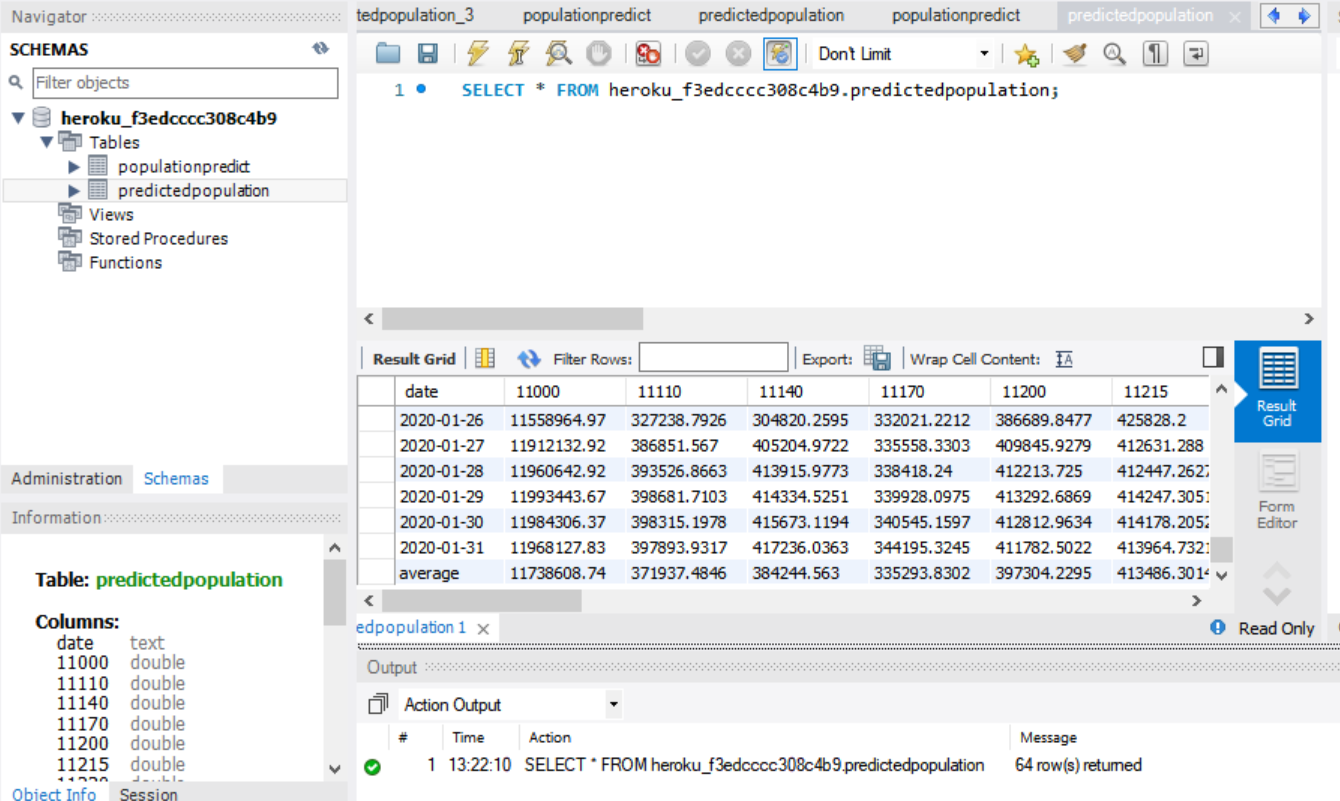
이제 우리는 DB 내의 데이터를 사용할 것이다. Python과 DB를 연결하기 위해서는 pymysql 라이브러리를 설치하고 import 해야한다. pymysql.connect() 메소드를 사용하여 mysql에 연결이 가능하며 이때 접속할 mysql server의 주소, 접속할 mysql server의 포트 넘버, mysql의 ID와 password, 접속할 DB가 필요하다. 접속이 완료된 후에는 cursor() 메소드를 통해 cursor 객체를 가져와야 한다. 이후 execute() 메소드를 사용하여 sql 명령을 DB에 전송할 수 있다.
import pymysql
def predicted_pop(gu, date):
conn = pymysql.connect(host=호스트주소, port=포트넘버, user = 유저명, password=패스워드, db = DB명, charset = 'utf8')
curs = conn.cursor(pymysql.cursors.DictCursor)
curs1 = conn.cursor(pymysql.cursors.DictCursor)
sql = "SELECT `%s` FROM predict_population.predictedpopulation_3 WHERE date = '%s';"%(gu,date)
sql1 = "SELECT `%s` FROM predict_population.predictedpopulation_3 WHERE date = 'average';"%(gu)
curs.execute(sql)
rows = curs.fetchall()
pop = int(rows[0][gu])
curs1.execute(sql1)
rows1 = curs1.fetchall()
avg = int(rows1[0][gu])
if pop>(avg*1.01):
return "many"
elif pop<(avg*0.99):
return "less"
else:
return "similar"
