N+1 문제란?
연관 관계(Join)에서 발생하는 문제로 연관 관계가 설정된 Entity를 조회할 경우에 조회된 데이터 갯수만큼 연관관계의 조회 쿼리가 추가적으로 발생해 데이터를 읽어옵니다.
이를 N+1 문제라고 합니다.
N+1 문제 예제
ERD
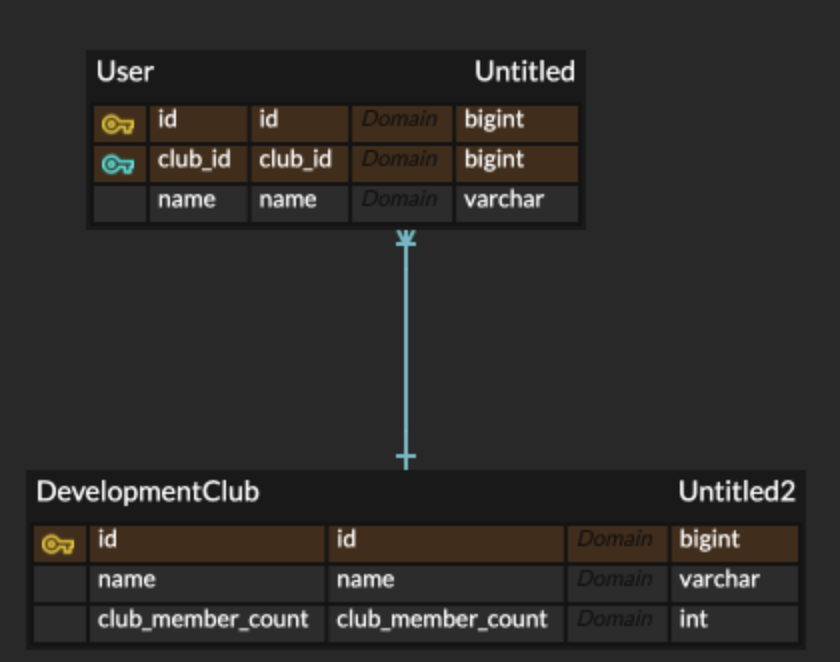
Entity
@Entity
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Table(name = "tb_user")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToOne(fetch = FetchType.EAGER) // 즉시 로딩
@JoinColumn(name = "club_id", nullable = false)
private DevelopmentClub developmentClub;
}
@Entity
@AllArgsConstructor
@NoArgsConstructor
@Table(name = "tb_development_club")
public class DevelopmentClub {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private Integer clubMemberCount;
@OneToMany(fetch = FetchType.EAGER)
private List<User> users = new ArrayList<>();
@Builder
public DevelopmentClub(String name, Integer clubMemberCount) {
this.name = name;
this.clubMemberCount = clubMemberCount;
}
}N+1 문제 발생 테스트 코드
@Test
public void JPATest() {
// given
DevelopmentClub developmentClub = DevelopmentClub.builder()
.name("GDSC").clubMemberCount(32)
.build();
User user = User.builder()
.name("홍길동").developmentClub(developmentClub)
.build();
User user2 = User.builder()
.name("홍길동2").developmentClub(developmentClub)
.build();
developmentClubRepository.save(developmentClub);
userRepository.save(user);
userRepository.save(user2);
developmentClub.getUsers().add(user);
developmentClub.getUsers().add(user2);
developmentClubRepository.save(developmentClub);
// when
List<DevelopmentClub> clubs = developmentClubRepository.findAll();
}N+1 문제 발생
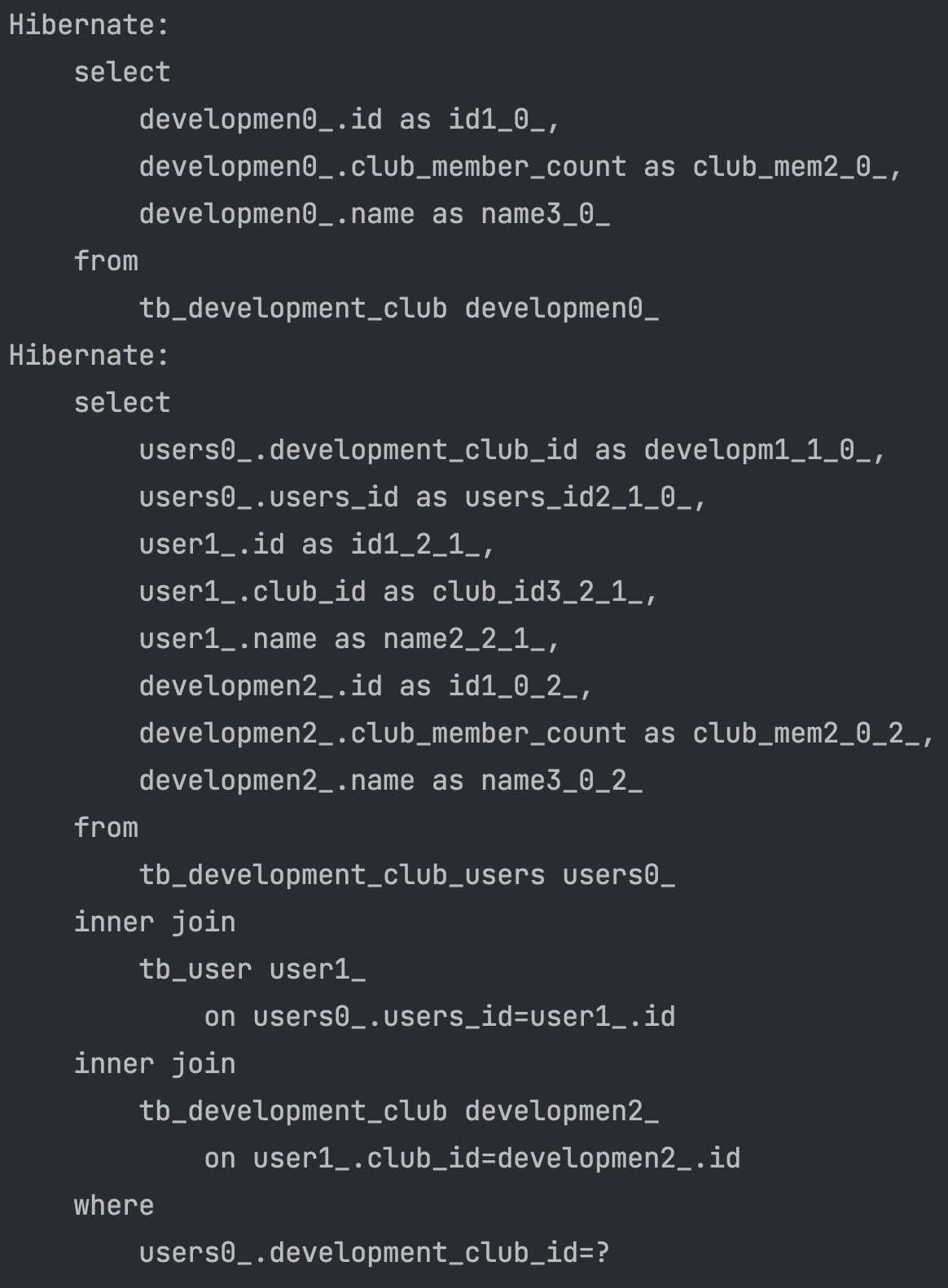
나는 findAll를 한번만 했을 뿐인데 User를 불러오는 쿼리가 하나가 더 추가가 되었네요?
지금은 DevelopmentClub 하나라서 그렇지 여러개 였으면 진짜 끔찍할 것 같습니다.
아 FetchType.EAGER 라서 그런 것은 아니고 FetchType.LAZY 이어도 users를 사용할때 결국 N+1 문제가 발생합니다.
N+1 발생 이유
아니.... 굳이 이런 쿼리문을 발생시키는 이유가 뭘까요?
-
JpaRepository에 정의되어 있는 인터페이스 메서드를 실행하면 JPA는 메서드 이름을 기반으로 JPQL을 생성 및 실행을 하게 됩니다.
-
JPQL은 Entity와 필드 이름을 가지고 쿼리를 하게 되는데 JPQL은
findAll()이란 메소드를 수행하였을 때 해당 Entity만을 조회하는select * from tb_development_club쿼리를 실행하게 되는 것 입니다. -
JPQL 입장에서는 연관관계를 무시하고 해당 Entity 기준으로 쿼리를 조회하기 때문입니다. 그렇기 때문에 연관된 Entity 데이터가 필요한 경우, FetchType으로 명시한 시점에 조회를 쿼리를 별도로 발생하게 됩니다.
즉 JpaRepository 사용의 편리함을 제공하는 대가로 발생하는 문제였던 것입니다.
해결 방법
Fetch Join
public interface DevelopmentClubRepository extends JpaRepository<DevelopmentClub, Long> {
@Query("select dc from DevelopmentClub dc join fetch dc.users")
List<DevelopmentClub> findAllFetchJoin();
}해당 JPQL을 작성한 findAll를 작성하여 해당 메소드를 사용해 findAll을 하였습니다.
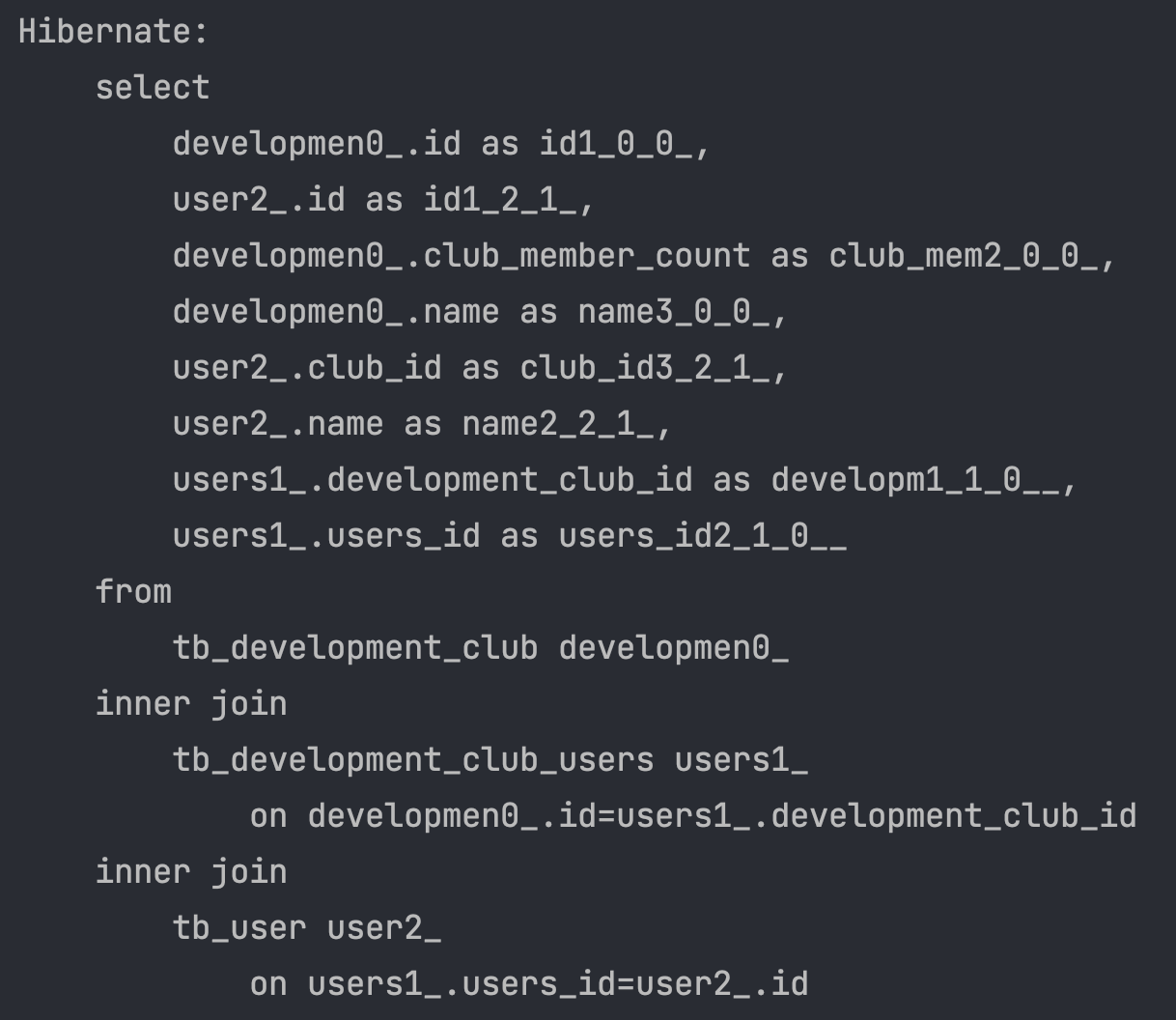
한번의 쿼리로 해결되는 모습을 확인하였습니다.
가장 간단한 해결법이네요. 역시 직접 쿼리작성은 언제나 옳습니다.
하지만 해당 방식은 주의사항이 존재합니다.
-
연관관계를 설정해놓은 FetchType을 사용할 수 없다는 것입니다.
Fetch Join 시 조회 시점에 모든 연관 관계의 데이터를 가져오기 때문에 FetchType의 설정이 무의미합니다. (사실상FetchType.EAGER인듯) -
페이징 쿼리를 사용할 수 없습니다. 하나의 쿼리문으로 가져오다 보니 페이징 단위로 데이터를 가져오는것이 불가능합니다.
Fetch Join은 페이징 쿼리가 필요없는 Entity에 사용해야겠습니다.
근데 그냥 궁금한건데 JPQL에서는 join fetch라는 서순인데 왜 Fetch Join이라고 부르는지 모르겠네요 (Join Fetch 아닌가?)
EntityGraph
@EntityGraph(attributePaths = "users")
@Query("select dc from DevelopmentClub dc")
List<Owner> findAllEntityGraph();@EntityGraph을 사용하여 findAll 메서드를 만들었습니다.
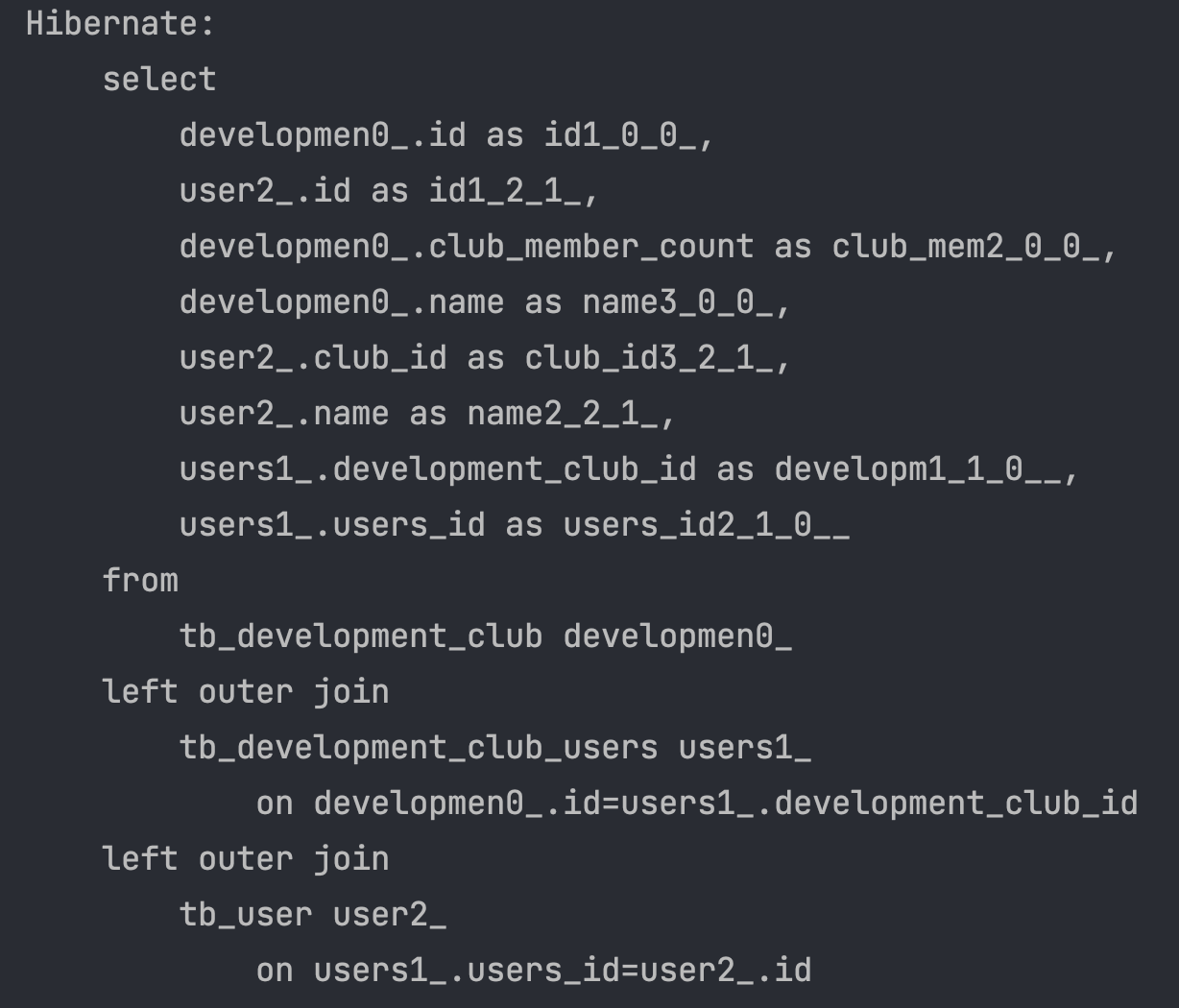
N+1 문제가 해결된 결과 자체는 동일하지만 Fetch Join과 달리 outer join이 적용된 모습입니다.
Fetch Join 과 EntityGraph 중복 방지
위에 올렸던 테스트 코드와 동일하게 DevelopmentClub Entity를 한개만 추가하고
findAllFetchJoin()을 실행하였는데...
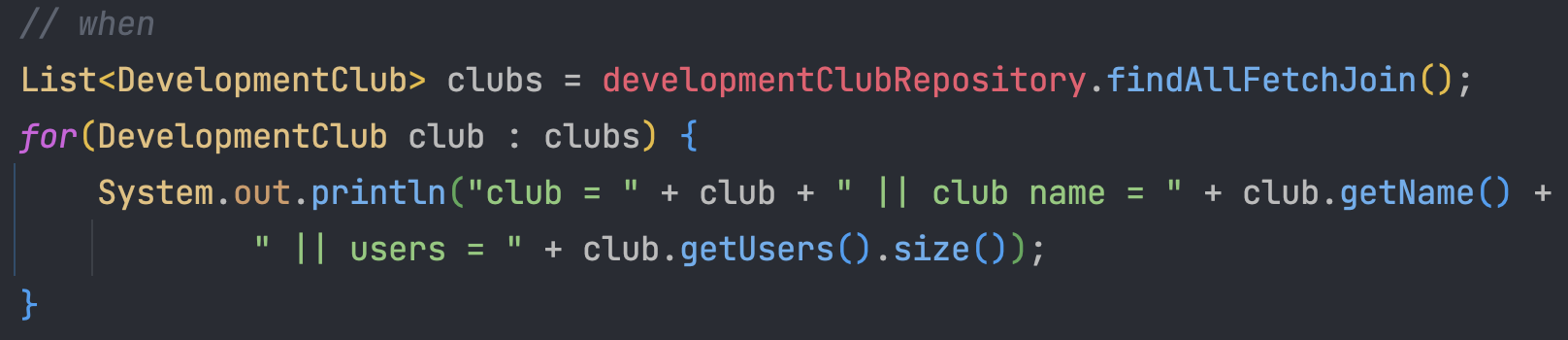

너 왜 중복이야???
놀랍게도 중복이 되어서 결과가 나와버렸습니다.
한번 SQL 관점으로 생각을 해보았습니다. 그랬더니 밑에와 같은 결과가 나오게 되더라고요
| dc.id | dc.name | u.user |
|---|---|---|
| 1 | GDSC | 홍길동 |
| 1 | GDSC | 홍길동2 |
아............ 내가 Join 시 중복을 간과했구나.....
JPQL은 이거 자동으로 중복제거 안해주나 보네..... (진짜 SQL 마렵다 ㅋㅋㅋㅋㅋㅋㅋㅋ)
중복을 해결할 수 있는 문제는 2가지 정도 있습니다.
// 변경 전
public interface DevelopmentClubRepository extends JpaRepository<DevelopmentClub, Long> {
@Query("select dc from DevelopmentClub dc join fetch dc.users")
List<DevelopmentClub> findAllFetchJoin();
}
// 첫번째 방법
public interface DevelopmentClubRepository extends JpaRepository<DevelopmentClub, Long> {
// List -> Set으로 변경!
@Query("select dc from DevelopmentClub dc join fetch dc.users")
Set<DevelopmentClub> findAllFetchJoin();
}
// 두번째 방법
public interface DevelopmentClubRepository extends JpaRepository<DevelopmentClub, Long> {
// distinct 사용
@Query("select distinct dc from DevelopmentClub dc join fetch dc.users")
List<DevelopmentClub> findAllFetchJoin();
}첫번째 방법은 중복을 제거할수있는 자료구조인 Set을 사용해서 중복을 제거하는 방법입니다.
두번째 방법은 중복 제거하는 distinct 사용하는 것입니다.
둘다 밑에와 같이 정상적으로 중복 제거 한 것을 볼 수 있습니다.

기타 해결 방법
- FetchMode.SUBSELECT
- BatchSize
- QueryBuilder (ex: Mybatis, QueryDSL, JOOQ, JDBC Template)
느낀 점
기존에 개발을 하면서 JpaRepository의 편리함에만 기대서 무지성으로 개발을 한게 너무나도 부끄럽네요.............
앞으로는 JpaRepository을 사용하게 된다면 JPQL 최적화 를 유심히 고려해보도록 하겠습니다.
이러한 N+1 문제, 그리고 제가 개발하면서 JPA, JPQL의 불편함을 느끼면서
QueryDSL을 너무나도 사용하고 싶은 욕구가 생기게 되었습니다.
그래서 추후 프로젝트에는 QueryDSL을 공부해서 적용을 해야겠습니다.
