Pod에서 replicas 을 설정해서 여러개 띄어두는 상황이 있는데
각각의 Pod들이 개별 볼륨을 가져야 되는 상황이 생겼습니다.
(Logstash, Filebeat 같은 서비스들)
그래서 이걸 어떻게 할까 계속 생각하다가
다행히도 StatefulSet 라는 Resource가 있더라고요?
그래서 어차피 사용해야하니 자세히 공부해보았습니다.
Stateful
일단 먼저 실제 K8S Resource를 설명하기 전에
Stateful 라는 개념부터 알아보려고 합니다.
Stateless Application
말그대로 상태저장이 필요하지 않은 어플리케이션을 뜻 합니다.
어플리케이션은 처리와 응답을 할 뿐이지 요청이 들어온 상태를 저장하고 있지는 않습니다.
또한 분산 환경에서 특정 Application이 죽어도 복제본이 그 역할을 그대로 수행할 수 있는 장점도 있습니다.
대표적인 예로 Nginx 가 있습니다.
프로토콜로는 UDP, HTTP가 있겠네요.
Stateful Application
이번에는 상태저장을 하는 어플리케이션인데요
무엇을 상태저장을 하는걸까요? 되게 다양하겠지만
대표적으로 클라이언트의 요청을 저장하게 되고
다음 요청이 왔을 때도 이전 요청에 대한 상태를 알 수 있는 것을 말합니다.
대표적인 예로 데이터베이스, 서버의 세션 이 있습니다.
프로토콜로는 TCP (3-way handshaking)이 있습니다.
K8S StatefulSet
쿠버네티스에서는 Pod별로 각각 다른 스토리지를 사용해 다른 상태를 유지하기 위해 StatefulSet 라는 resource를 제공합니다.
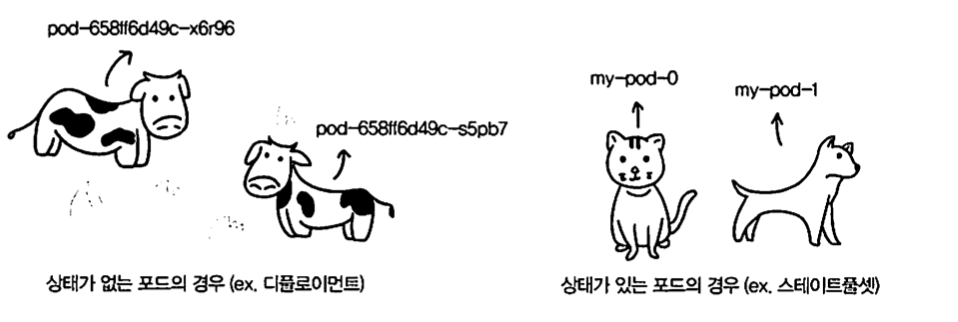
replicas2개 이상 구성 시 개별 Pod는 복제본이 아닌 별도 Pod 개념입니다.
특징
-
Pod 생성 시 순차적으로 생성이 이루어집니다.
-
Pod가 사용할 스토리지는 PVC를 통해서만 가능합니다.
(근데 보통 중요 데이터는 PVC 통해서 연결하니까 크게 문제되지는 않겠네요) -
Pod가 죽을 시 동일 파드 생성 후 기존 PVC와 연결합니다.
-
StatefulSet resource를 제거하거나 Pod를 제거해도 볼륨은 삭제되지 않습니다.
- 단 해당 볼륨이 데이터 가공 과정을 해야하는 성격을 띄었을 경우 Pod를 할당해주지 못하기 때문에 해당 볼륨에 들어있는 데이터에 대한 후속 처리가 필수적으로 필요합니다. 안그러면 데이터 손실로 이어지니까요
-
Headless Service 필요
- StatefulSet은 Pod 별로 개별 구분이 가능해야 하며 service 이름으로 pod 별 접근이 가능해야 하기 때문에 필수적으로 필요합니다. (기존 service는 여러 pod에 랜덤으로 전달하기 때문)
-
파드 이름 규칙 : {StatefulSet이름}-{번호}
- ex)
mysts-0
- ex)
-
Pod Dns 주소 : {Pod_Name}.{Governing_Service_Domain}.{Namespace}.svc.cluster.local
- ex)
mysts-0.test-app-svc.test(svc.cluster.local은 생략 가능합니다.)
- ex)
Yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: test-app
spec:
selector:
matchLabels:
app: test-app
serviceName: test-app-svc
replicas: 2
template:
metadata:
labels:
app: test-app
spec:
containers:
- name: test-app
image: docker.io/test:1234
ports:
- containerPort: 8080yaml 파일 작성법은 일반 Deployment나 ReplicaSet 이랑 비슷합니다.
Scale Out 시 주의점
Scale Out 시에는 PV는 당연히 살아있겠지만 올린 Pod가 logstash 같은 성격을 띄고 있다면
Pod와 연결이 안된 PV는 영원히 처리가 안된 상태로 남아있을 것이고 이거는 즉 데이터 유실로 연결될 것 입니다.
그렇기 때문에 Scale Out 시 바로 Pod를 제거하는 것이 아니라 Service에서 Scale Out을 진행할 Pod를 제외시키고 해당 Pod가 PV에 담겨져 있는 데이터 처리를 전부 다 완료하면
그때 Pod를 제거하는게 더 좋지않을까? 라고 생각합니다.
느낀 점
쿠버네티스를 파면 팔수록 진짜 새로운게 나오는 느낌이긴 합니다...
api-resource만 검색해도 엄청 많이 나오니까...
그래도 재미는 있네요
점점 인프라쪽으로 빠지는 기분이 ㅋㅋㅋㅋㅋㅋㅋ
요즘 공부한게 한두개가 아닌데 다 쓸까 하다가 너무 많아서... 안쓴게 너무 많기도 하네요...
조만간 SpringBoot Actuator 를 활용해서 웜업 단계 구성도 공부해보려고 합니다.
참고
