요즘 데이터베이스 지식 관련해서 공부할 것들이 너무 많네요 ㅎㅎ
최근에 젤다 왕눈좀 하느라 공부 못했었는데 전부 깻으니 다시 공부에 집중해야겠습니다 ㅋㅋㅋ
이전 글 내용에서 이어지는 내용이긴한데
페이징 처리를 하는 방식 중 하나인 커버링 인덱스에 대해서 알아보려고 합니다.
커버링 인덱스
커버링 인덱스란, 쿼리를 충족시키는데 필요한 모든 데이터를 갖고 있는 인덱스를 말합니다.
인덱스는 데이터를 효율적으로 탐색하는 방법입니다. 인덱스를 사용해 조회하게 되면 실제 데이터까지 접근할 필요가 없습니다. 즉, 인덱스는 조회 성능을 향상 시킵니다.
(이전 B트리 글을 확인하면 왜 인덱스가 효율적인지 알 수 있습니다.)
- 쿼리를 충족시킨다 :
SELECT, WHERE, ORDER BY, LIMIT, GROUP BY등에서 사용되는 모든 컬럼이 인덱스 컬럼 안에 다 포함되는 경우입니다.
하지만 이렇게 이론을 공부해도 제 머리속으로는 이해가 안되더라고요
그래서 실제로 쿼리로 커버링 인덱스가 무엇인지 확인해 보겠습니다.
예시
select * from user
where id = 1;
해당 쿼리의 실행계획은 위에와 같습니다.
-
selected_type :
SIMPLE-> UNION이나 서브쿼리가 없는 단순 Select -
type : ref 조인을 할때 PK 혹은 Unique Key가 아닌 Key로 매핑된 경우.
여기서는 단일 테이블 조회이기 때문에 동등 조건으로 검색할 경우를 가리킴 -
key : 쿼리에 사용된 인덱스, 여기서는 PK를 사용했기 때문에 PRIMARY로 나왔습니다.
-
ref : const 비교 조건으로 어떤 값이 사용되었는지 나타냄.
여기서는 상수인 1이 사용되어서 const로 나왔습니다. -
extra : 빈값일 경우 일반적인 쿼리
그럼 다시 쿼리문을 변경하여 실행계획을 살펴보겠습니다.
select id from user
where id = 1;
Extra 값이 빈값에서 Using index로 바뀐 것을 확인할 수 있습니다.
이 쿼리는 인덱스에 포함된 컬럼 (id) 만으로 쿼리가 생성 가능하니 커버링 인덱스가 사용 된 것입니다.
즉 쿼리에 나타난 모든~~ 컬럼이 인덱스 이기 때문에 커버링 인덱스가 적용이 된 것이죠.
GROUP BY
예시에서는 WHERE 쿼리만 살펴보았는데 GROUP BY에서도 어떻게 커버링 인덱스가 적용되는 지 조건들을 알아보겠습니다.
인덱스 컬럼이 a, b, c라고 가정할 때 GROUP BY 인덱스 조건들을 확인해보겠습니다.
GROUP BY 인덱스 조건
- 인덱스 컬럼과 GROUP BY에 명시하는 컬럼의 순서는 동일해야 됩니다.
GROUP BY a, c, b # 인덱스 적용 X
GROUP BY a, b, c # 인덱스 적용 O- 인덱스 컬럼 중 뒤에 있는 컬럼은 GROUP BY에 명시하지 않아도 됩니다.
- 인덱스 컬럼 중 앞에 있는 컬럼은 GROUP BY에 명시해야 됩니다.
GROUP BY a # 인덱스 적용 O
GROUP BY a,b # 인덱스 적용 O- 인덱스에 없는 컬럼을 GROUP BY에 명시하면 안됩니다.
GROUP BY a, b, c, d # 인덱스 적용 X- WHERE + GROUP BY가 함께 사용되면, WHERE에 있는 컬럼은 GROUP BY에 없어도 됩니다.
WHERE a = 1
GROUP BY b, c # 인덱스 적용 O
WHERE a = 1 and b = '홍길동'
GROUP BY c # 인덱스 적용 O페이징
인덱스 추가 설정 쿼리
# 인덱스 추가
create index TEST_INDEX ON user (nickname);일반 페이징 쿼리
select * from user
where nickname like '%길%'
limit 0, 10;커버링 인덱스 페이징 쿼리
select a.* from (
select id from user
where nickname like '%길%'
limit 0, 10
) b
join user a on a.id = b.id;
# 커버링 인덱스 방식으로 인덱스 컬럼 정보만 얻어오고
# 이를 바탕으로 전체 데이터 조회결과
일반 페이징 쿼리

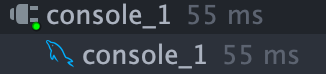
커버링 인덱스 페이징 쿼리

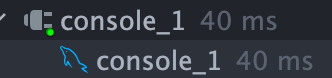
데이터가 워낙 작아서 저정도 차이면 의미가 없긴 한데
그래도 커버링 인덱스 적용 한 것이 더 빠르게 나타났습니다.
데이터의 양이 커지면 커질수록 이 차이는 훨씬 더 드라마틱하게 나타날 것 입니다.
장점
-
DB Optimizer가 멋대로 PK를 활용한 조회 작동을 Index를 활용하도록 조회 시킬 수 있습니다.
- JPA 또는 동적쿼리에서 Index 안타는 경우 진짜 많아요!!
-
대용량 데이터 조회 시 엄청난 속도
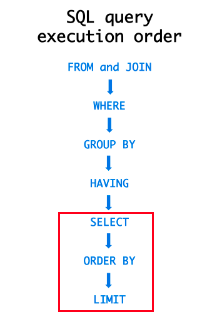
위의 그림은 SQL이 실행되는 순서입니다. FROM ~ JOIN부터 HAVING까지는 Index를 활용할 수 있지만 SELECT ~ LIMIT 부분에는 실제 데이터 블록을 조회해야 합니다.
단계를 보면 SELECT가 먼저 조회되기 때문에 아무래도 LIMIT 부분에서 부하가 걸릴 수밖에 없습니다.
즉, LIMIT 처리가 되면 필요 없을 수 있는 데이터까지 전부 포함한 전체 데이터의 전체 컬럼을 Index와 비교해가면서 읽어서 로드해야 합니다.
하지만 커버링 인덱스는 모든 쿼리가 Index를 활용하게 됩니다.
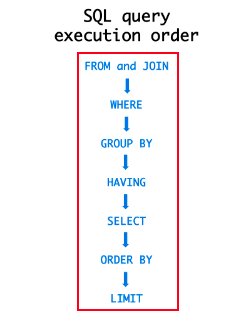
단점이라면 이후에 JOIN으로 원하는 데이터 컬럼을 불러와야 된다는 점?
후속쿼리도 PK로 비교하기 때문에 성능적으로 괜찮을 것 같습니다.
조회성능이 너무 좋기 때문에 대용량 데이터에 사용하면 적합하겠네요.
느낀 점
인덱스라는 개념에 대해서 좀 더 확실하게 이해한 것 같고
공부하기 전에는 몰랐는데 쿼리가 어떻게 데이터를 가져오는 지 명확하게 이해가 되가는 것 같네요.
앞으로는 쿼리문을 볼 때 데이터를 어떻게 가져오는 지 머릿속에서 그려질 것 같습니다.
참조
