트리의 지름
트리의 지름이란, 트리에 있는 노드 두 개의 거리 중 가장 먼 거리를 말한다. 트리는 사이클과 방향이 없는 그래프이기 때문에, 두 노드 간 경로는 항상 한 가지만 존재한다. 이 때 가장 긴 경로에 포함된 두 노드를 수평으로 두면 트리의 모든 노드들이 이 두 노드를 지름의 끝 점으로 하는 원 안에 들어가기 때문에, 트리의 가장 긴 경로를 “지름”이라고 하는 것이다.
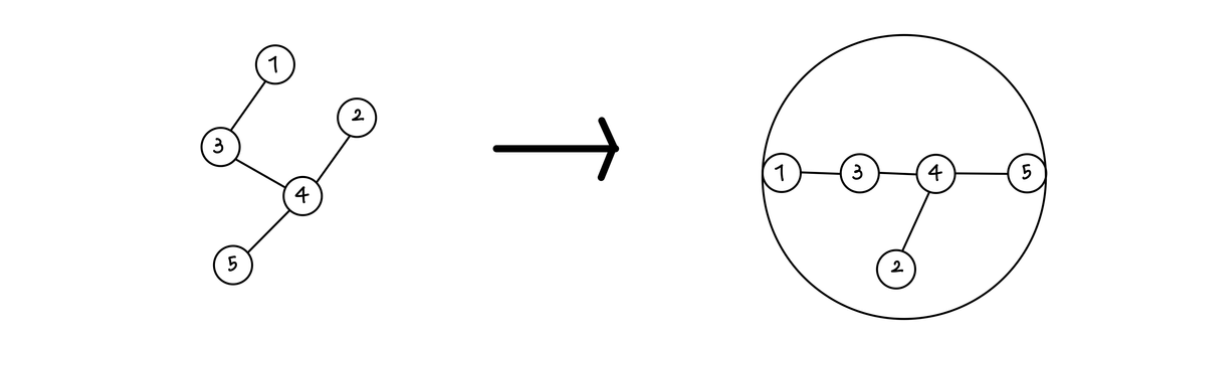
트리의 지름을 찾는 알고리즘
트리의 지름은 DFS또는 BFS를 이용해 구할 수 있다. 전체적인 알고리즘의 흐름은 다음과 같다.
- 임의의 정점에서 가장 먼 정점 찾기
- 1번에서 찾은 정점에서 가장 먼 정점 찾기
이 때 1번에서 찾은 정점과 2번에서 찾은 정점 사이의 거리가 바로 트리의 지름이 된다. 탐색을 총 두 번 실행하게 되므로, 트리의 정점이 개라고 했을 때 시간복잡도는 이다.
간단한 증명
그런데 임의의 정점에서 가장 먼 정점을 찾고, 그 정점에서 가장 먼 정점이 어떻게 항상 트리의 지름이 될 수 있을까? 위 알고리즘에 따르면, 트리에 있는 두 개의 경로만으로 트리의 지름을 찾아낼 수 있는 것이다. 이 알고리즘이 어떻게 성립되는지 몇 가지 상황을 가정해서 알아보자.
우선 트리에 있는 두 가지 경로를 가정해보자. 하나는 임의의 정점과 또 다른 임의의 정점 사이의 경로이고, 하나는 트리의 지름이 되는 경로이다.
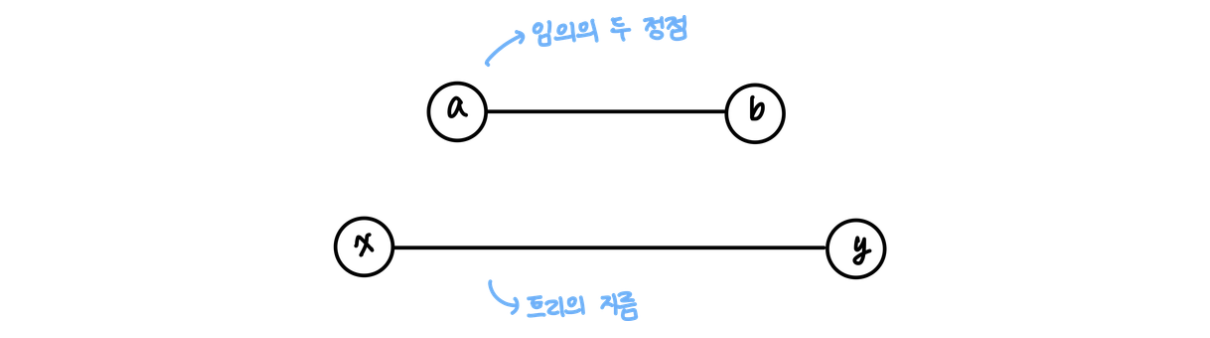
이 때 임의의 정점 에서 가장 먼 정점은 임의의 정점 임을 가정한다.
첫 번째 가정: 임의의 정점 또는 가 트리의 지름을 이루는 정점 또는 정점인 경우
만약 처음 선택한 정점이 트리의 지름을 이루는 정점이었을 경우엔 증명이 필요 없다. 정점이 정점이 된다면 정점은 필연적으로 정점이 되고, 반대의 경우도 마찬가지이기 때문이다. 따라서 알고리즘의 1번 순서와 2번 순서에서 동일한 경로를 탐색하게 된다.
두 번째 가정: 두 경로가 겹치는 경우(정점을 공유하는 경우)
다음 그림과 같이 두 경로 사이의 교차점을 라고 가정한 후, 각 거리에 대해 살펴보자.

앞서 정점 에서 가장 먼 정점은 이기 때문에, 이를 만족하기 위해서는 의 길이가 과 중 긴 길이와 동일해야 한다. 이는 가 트리의 지름을 이루는 정점 또는 가 되어야 한다는 뜻이므로, 결국 첫 번째 가정의 상황과 동일해진다.
세 번째 가정: 두 경로가 겹치지 않는 경우(정점을 공유하지 않는 경우)
다음과 같이 두 경로가 트리 내에서 어떠한 정점을 공유하지 않는 경우도 가정해보자.
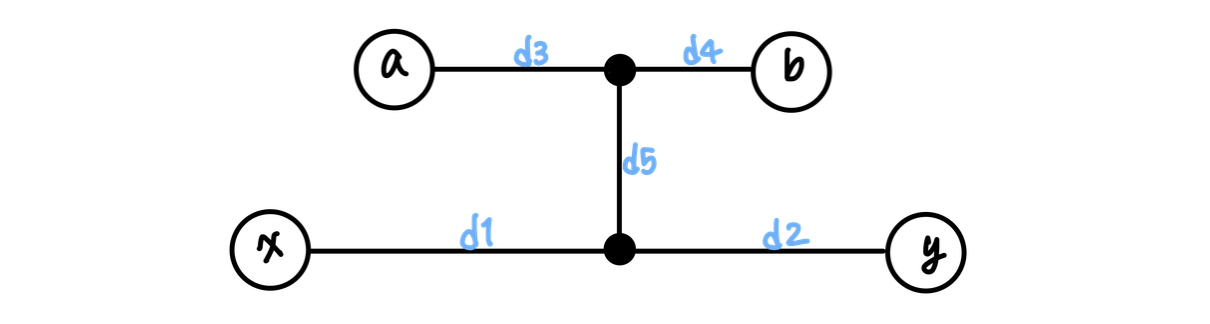
마찬가지로 정점 에서 가장 먼 정점이 정점이 되기 위해서는 가 성립해야 한다. 또한 이 가정이 성립되려면 과 가 동일한 경우도 성립해야 하는데, 이는 정점 가 정점 또는 와 동일할 수 있음을 의미한다. 즉, 긴밀히 따지면 실제로 성립할 수 없는 가정이 된다.
따라서 위의 여러 상황들을 가정해보면, 처음 언급한 알고리즘이 항상 트리의 지름을 찾음을 알 수 있다.
연습하기
이를 구현해볼 수 있는 문제는 대표적으로 백준 1967. 트리의 지름이 있다. 앞서 언급한 알고리즘의 흐름을 구현하면 되는데, 보통 DFS 또는 BFS를 활용하여 구현하게 된다. 아래는 DFS를 이용해 구현한 예제 코드이다.
import java.io.*;
import java.util.*;
public class Main {
static int N;
static Node target; //v에는 도착점 노드, w에는 지름 저장
static boolean[] visit;
static ArrayList<Node>[] tree;
static void find(int tmp, int dist) {
if(dist>target.w) {
target = new Node(tmp, dist);
}
for(Node next: tree[tmp]) {
if(visit[next.v]) continue;
visit[next.v] = true;
find(next.v, dist+next.w);
}
}
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
N = Integer.parseInt(br.readLine());
if(N==1) {
System.out.println(0);
return;
}
tree = new ArrayList[N+1];
for(int i=1;i<=N;i++) {
tree[i] = new ArrayList<>();
}
StringTokenizer st;
for(int i=1;i<N;i++) {
st = new StringTokenizer(br.readLine());
int from = Integer.parseInt(st.nextToken());
int to = Integer.parseInt(st.nextToken());
int w = Integer.parseInt(st.nextToken());
tree[from].add(new Node(to, w));
tree[to].add(new Node(from, w));
} //end input
target = new Node(0,0);
//1. 아무 정점에서 가장 먼 정점 찾기
visit = new boolean[N+1];
visit[1] = true;
find(1, 0);
//2. 트리의 지름 찾기
visit = new boolean[N+1];
visit[target.v] = true;
find(target.v, 0);
System.out.println(target.w);
}
static class Node {
int v,w;
public Node(int v, int w) {
this.v = v;
this.w = w;
}
}
}