Warm-Up
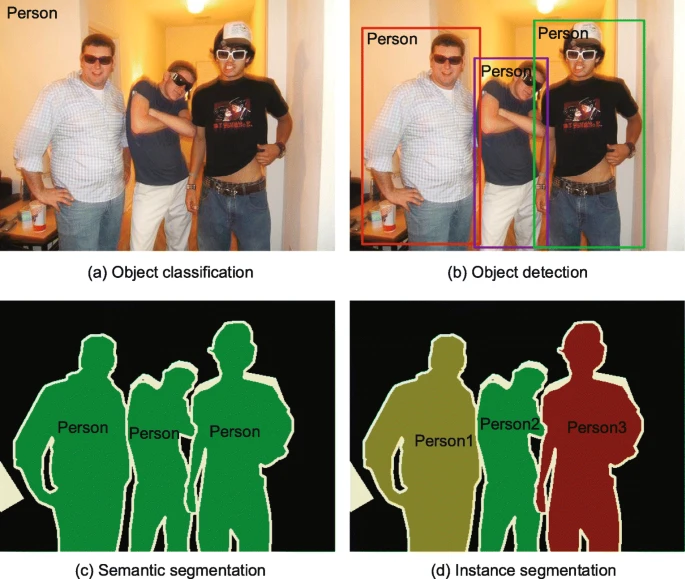
Object Detection을 이해하기 전에 classification / Detection / segmentation 을 명확히 구분할 필요가 있다.
- (a) Object Classification은 이미지에서 객체의 범주를 식별
- (b) Object Detection는 Object의 category를 식별해야 할 뿐만 아니라 직사각형 Bounding Box가 있는 Object를 찾아야함
- (c) Semantic segmentation은 각 픽셀의 category를 예측하기만 하면 되며 object instances를 구분할 필요가 없음
- (d) Instance segmentation은 각 픽셀과 Object instance의 category를 모두 예측해야 함
Paper & Article
Object Detection이 그 동안 발전해온 방향을 보기 좋게 정리해둔 survey 가 많다. 아래를 참고 할 것.
- Object Detection in 20 Years: A Survey (19.05.16)
https://arxiv.org/pdf/1905.05055.pdf - Recent advances in deep learning for object detection (20.07.05)
https://www.sciencedirect.com/science/article/pii/S0925231220301430 - A review of object detection based on deep learning (20.06.12)
https://link.springer.com/content/pdf/10.1007/s11042-020-08976-6.pdf
https://link.springer.com/article/10.1007/s11042-020-08976-6 - Investigations of Object Detection in Images/Videos Using Various Deep Learning Techniques and Embedded Platforms—A Comprehensive Review (20.04.15)
https://www.mdpi.com/2076-3417/10/9/3280/htm
Object Detection Milestones


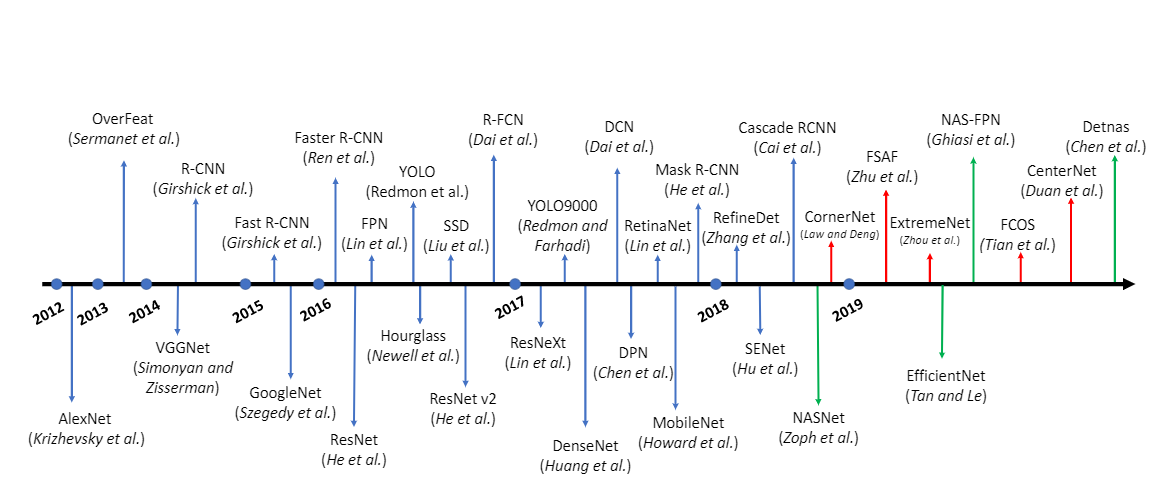
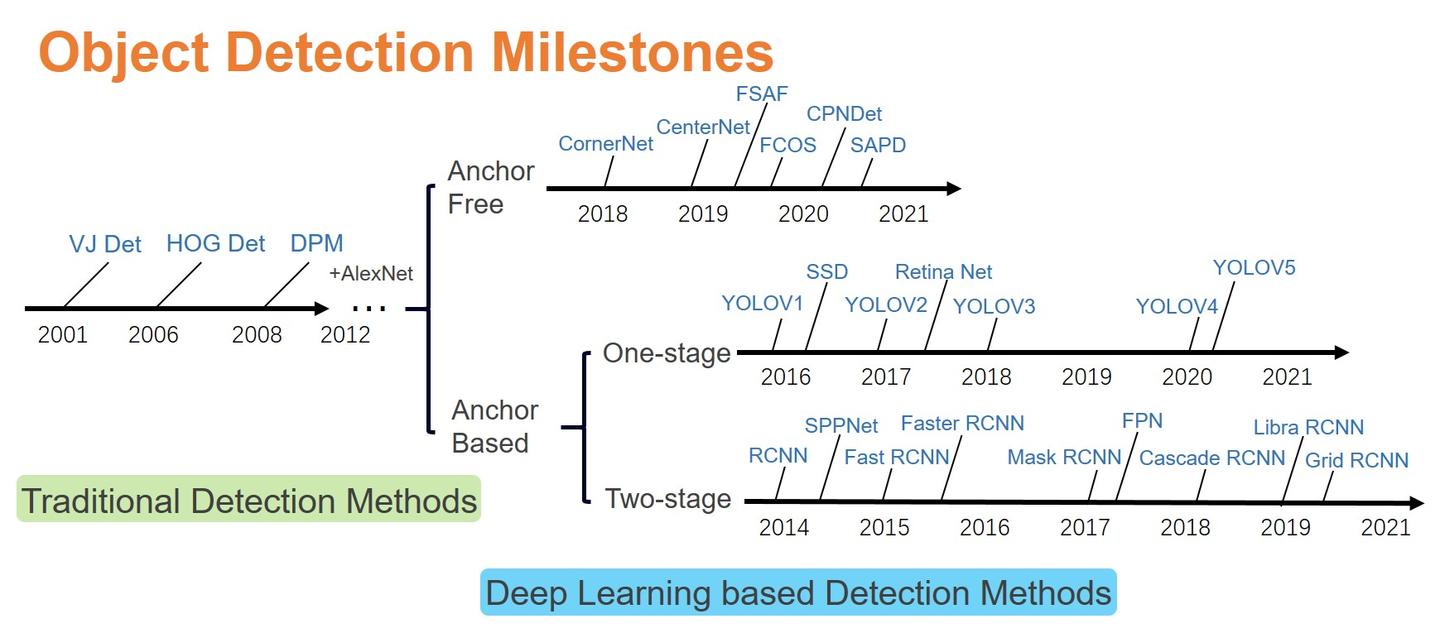
Object Detection 방식 구분
Object Detection(이하 OD)의 Milestone을 보면 크게 Traditional Detection과 Deep Learning Based Detection 으로 나뉜다. Deep Learning Based Detection은 Anchor Free와 Anchor Based로 나누고 다시 Anchor Based에서 One-stage와 Two-stage로 나뉘게 된다.
- Object Detection
- Traditional Detection methods (~2012)
- Deep Learning Based Detection methods (2012~)
- Anchor Based (2012~)
- One-stage
- Two-stage
- Anchor Free (2018~)
- Anchor Based (2012~)
18년 이후 Anchor Free 가 issue되지 않았을 시기의 Object Detection는 Anchor Based 가 주를 이루었고 보통 OD method 방식이 one-stage 인지 two-stage인지만 구분하였다.
- Object Detection의 주요 구성 요소
- Region Proposal (영역 추정)
- Detection - Feature extraction and Network prediction
- Detection을 위한 DL 네트워크 구성
- other components
- IoU, NMS, mAP, Anchor box 등 Detection을 구성하는 components
Region Proposal과 Detection을 하나의 단계로 수행할지 두 단계로 수행하는지에 따라 One-stage Detector, Two-Stragy Detector로 구분된다.
Traditional Detection
Traditional Detection은 Sliding Window 방식을 사용한다. Sliding Window 방식이라 Window를 좌측 상단에서부터 우측 하단으로 이동하면서 Object를 Detection하는 방식이다. 다양한 형태의 Window를 각각 Sliding 시키는 방식이기 때문에 Window Scale은 고정하고 Scale을 변경한 여러 이미지를 사용하는 방식이다. 여기서 발생하는 문제는 Object가 없는 영역도 무조건 Sliding하여야 하며 여러 형태의 Window와 여러 Scale을 가진 이미지를 SCAN해서 검출해야 하므로 수행 시간이 오래 걸리고 검출 성능이 상대적으로 낮다는데 있다. 많은 이미지에서는 Object가 없는 영역, 즉 배경이 대부분인 경우가 많다.
- Traditional Detection methods (~2012)
- Sliding window 방식 사용 (window를 좌상단에서 우하단으로 이동하며 detection)
- 다양한 형태의 window를 sliding시키는 방식
- window Scale 고정 + Scale 변경한 여러 이미지 사용
- 단점
- Object가 없는 영역도 무조건 Sliding하여야 함 -> 속도↓ detection 성능↓
- 여러 형태의 Window와 여러 Scale을 가진 이미지를 SCAN해서 검출해야 함 -> 속도↓ detection 성능↓
Anchor Based > Two-stage Detector

...
RCNN -> Fast RCNN
Anchor Based > One-stage Detector

Region Proposal과 Detection을 한방에 수행하는 방식.
- Detection 수행속도를 크게 향상
- Detection 정확도가 떨어지는 편
- Anchor 박스가 학습을 통해 얻는 정보
- Anchor 박스와 겹치는 Feature Map 영역의 오브젝트 클래스 분류,
- Ground Truth BOX 위치를 예측할 수 있도록 수정된 좌표,
- 개별 Anchor Box별로 Detection하려는 Object 유형, Softmax값, 수정 좌표값
SSD는 Training 시 Matching전략을 사용하는데, Matching 전략이란 Bounding Box와 겹치는 IOU가 0.5이상인 Default(Anchor) Box들의 Classification과 Bounding box Regression을 최적화하는 학습을 수행한다.
-
SSD : Multi Scale Feature Layer와 Default (Anchor) Box의 결합
-
YOLO(You Only Look Once)
- YOLO는 V1에서 Faster R-CNN(VGG16)보다 3배 빠름
- V2에서는 수행시간과 성능을 개선
- V3에서는 수행시간은 조금 느려졌으나 성능이 대폭 개선
Anchor Free
기존의 SSD와 같은 single-shot detector들의 경우 Anchor 기반으로 Detecting을 하지만 이러한 Anchor 기반의 Detecting 방식에는 2가지의 한계가 있다.
관련 paper를 참고 할 것.
[CVPR2019] Feature Selective Anchor-Free Module for Single-Shot Object Detection
1.heuristic-guide를 통한 feature selection (Anchor)
2.overlap-based anchor sampling
이런 문제를 FSAF(Feature-Selective-Anchor-Free)를 통해 해결될 수 있다. 하지만 Anchor - Free Module 은 기존의 Single Shot Detector들의 Anchor 방식을 완벽히 대체 할 수는 없다. 그러나 기존의 Anchor 방식으로 Detecting 한 object와는 또 다른 ojbect들을 찾아내는 강점이 있고 Anchor를 위해 개발자들이 heuristic하게 tuning을 해야하는 불편함을 줄이는데 기여한다.
해당 개념이 나올 당시에는 성능상의 weak point가 있었지만 최근 2~3년간 Anchor free방식은 빠르게 발전하여 Anchor 방식의 방법론과 견줄 정도로 좋은 성능의 수준으로 올라왔다.
- Anchor를 위한 heuristic-guide 가 필요 없음
- 학습의 편이
- general한 성능 확보 가능
- Anchor 방식에서 찾아내지 못하는 Object를 찾아내는 강점
관련 모델
- yolox (CVPR 2021)
- cornerNet
- ...
Object Detection - Terms
-
ROI (region of interest)
... -
Region proposal
RoI(region of interest) object가 존재할만한 관심있는 위치.
Region Proposal방식은 Object가 있을 만한 위치를 Image Crop과 Warp을 적용하여 2000개의 Region 영역을 Proposal 한다. 하지만 이 앞단에 중요한 역할을 하는 것이 바로 Selective Search기법을 활용한다는 것이다.
참고로 Sliding Window 방식 lagacy algorithm에서 사용했던 방식으로 Object Map의 많은 영역을 차지하는 Background까지 처리한다는 단점이 있음.
Sliding window -> Selective Search -> Region proposl Network (RPN)
- Selective Search
Selective Search기법이란 Region Proposal의 대표 방법으로써 원본 이미지로부터 최초 Segmentation을 수행하고 이를 통해 후보 Object를 추출하는 기법이다. 이를 통해 빠른 Detection과 높은 Recall 예측 성능을 동시에 만족하는 Algorithm 기법이다. 이는 Color, 무늬(Texture), 크기(Size), 형태(Shape)에 따라 유사한 Region을 계층적 그룹핑 방법으로 계산하는 기법이다. Selective Search는 최초에는 Pixel Intensity 기반의 Graph-based Segment 기법에 따라 Over Segmentation을 수행한다.
- IoU (Intersection over Union)
IoU = 교집합 영역 넓이 / 합집합 영역 넓이
보통 IoU threashold는 0.5로 설정하는 경우가 적지 않으며, overlapping되는 영역이 50%가 되는 영역이 생각하던 것과 많이 다를 수 있으니 아래를 참고하자.
IOU 활용의 예는 R-CNN 내에서 ground truth와 proposed region 사이의 IoU 값을 계산해 0.5 이상인 경우
해당 region을 객체로 바라보고 ground truth와 같은 class로 labelling을 한다.


- mAP (Mean Average Precision)
Object detection에서는 모델의 성능(정확도)을 주로 Mean average precision(mAP)를 통해 확인.
mAP가 높을수록 정확하고, 작을수록 부정확.
precision-recall 그래프는 어떤 알고리즘의 성능을 전반적으로 파악하기에는 좋으나 서로 다른 두 알고리즘의 성능을 정량적(quantitatively) 비교하기에는 불편한 점이 있다. 그래서 나온 개념이 Average precision이다. Average precision은 인식 알고리즘의 성능을 하나의 값으로 표현한 것으로서 precision-recall 그래프에서 그래프 선 아래 쪽의 면적으로 계산된다. Average precision이 높으면 높을수록 그 알고리즘의 성능이 전체적으로 우수하다는 의미이다. 컴퓨터 비전 분야에서 물체인식 알고리즘의 성능은 대부분 Average precision으로 평가한다.
컴퓨터 비전 분야에서 물체 검출 및 이미지 분류 알고리즘의 성능은 대부분 이 AP로 평가한다. 물체 클래스가 여러 개인 경우 각 클래스당 AP를 구한 다음에 그것을 모두 합한 다음에 물체 클래스의 개수로 나눠줌으로 알고리즘의 성능을 평가한다. 이것을 mAP(mean average precision)라고 한다.
-
NMS (Non Maximum Suppression)
.png)
OD에서는 하나의 인스턴스에 하나의 bounding box가 적용되어야 함. 따라서 여러개의 bounding box가 겹쳐 있는 경우 하나로 합치는 방법이 필요. 이때 NMS를 사용됨. 자잘한 bounding box를 지워버림. (IoU가 특정 threshold 이상인 중복 box 제거) -
Hard negative mining
hard negative 는 실제로는 negative 인데 positive 라고 잘못 예측하기 쉬운 데이터.
easy negative 는 실제로 negative 이고 예측도 negative 라고 잘 나오는 예측이 쉬운 데이터.
hard negative mining 는 hard negative 데이터를 (학습데이터로 사용하기 위해) 모으는(mining) 것이다.
hard negative mining 으로 얻은 데이터를 원래의 데이터에 추가해서 재학습하면 false positive 오류에 강해진다.
주요 모델
- OD 주요모델 정리한 블로그1 (갈아먹는 머신러닝)
https://yeomko.tistory.com/category/%EA%B0%88%EC%95%84%EB%A8%B9%EB%8A%94%20Object%20Detection- R-CNN
- Spatial Pyramid Pooling Network
- Fast R-CNN
- Faster R-CNN
- Yolo
- SSD
- FPN (Feature Pyramid Network)
- Yolo v2, Yolo9000
- yolo v3
- DETR : End-to-end방식의 Transformers를 통한 object detection
https://keyog.tistory.com/32
OD Framework
- mmDetection
- Detectron2
- Facebook AI.
- https://github.com/facebookresearch/detectron2
- Tensorflow Object Detection API & tensorflow hub
- Darknet
- yolo v4를 사용할 수 있다.
- https://pjreddie.com/darknet/
Object Detection - Category sheet
- Object detection dict

ref
- https://arxiv.org/pdf/1905.05055.pdf
- https://www.sciencedirect.com/science/article/pii/S0925231220301430
- https://link.springer.com/article/10.1007/s11042-020-08976-6
- https://www.mdpi.com/2076-3417/10/9/3280/htm
- https://hugrypiggykim.com/2020/07/19/object-detection%EC%9D%98-%EB%B3%80%EC%B2%9C%EC%82%AC-%EB%85%BC%EB%AC%B8-review/
- https://ballentain.tistory.com/12
