
💼개요
킥보드, 자동차 등 공유경제의 범위가 넓어지고 있지만 현재까지는 보유 자산 관리에 많은 인력이 소모되고 있다.
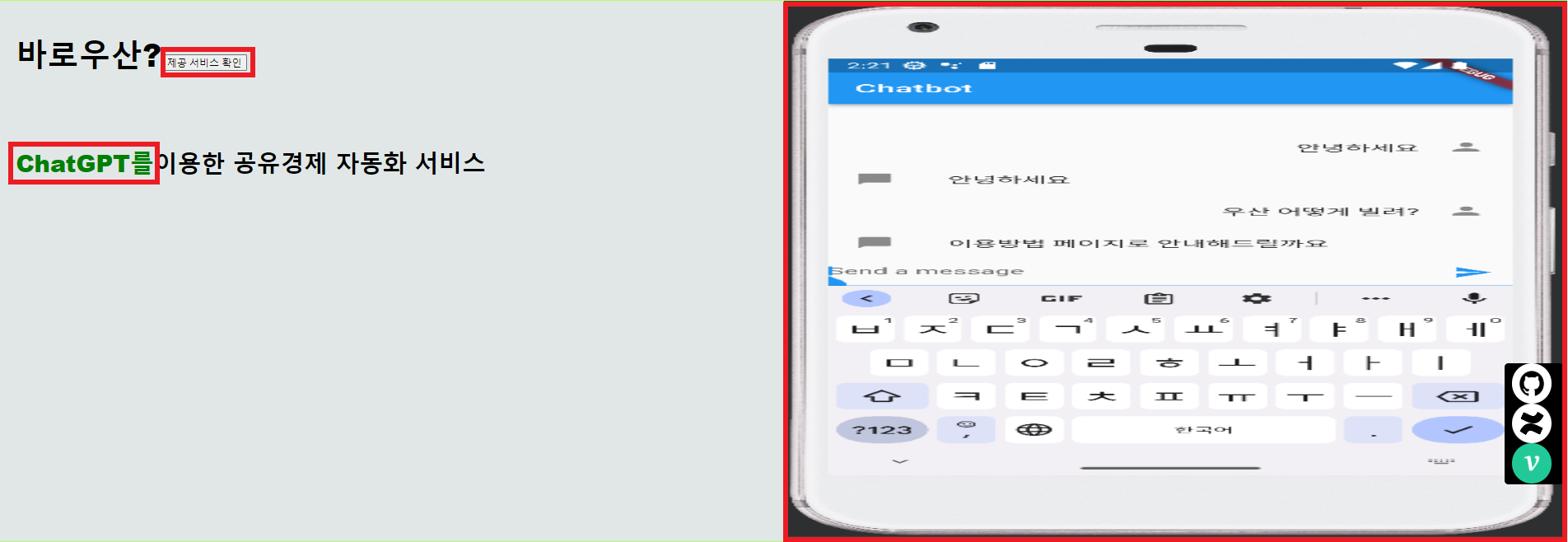
바로우산은 공유경제 대상이 우산이라는 가정하에 최근 주목 받는 ChatGPT, 객체인식, 수요예측 인공지능을 융합해 보유 자산을 관리할 수 있도록 이식한 공유경제 자동화 서비스다.
👨💻 참여자
 |  |  |
|---|---|---|
박성배 | 박하연 | 이강산 |
| Github Velog | Github | Github |
💳 주요 기능
- YOLOv5를 통한 자산 파손 여부 인식
- ChatGPT를 통한 이용자 안내
- Keras를 사용한 인공지능으로 지역에 따른 서비스 수요 예측
📝 프로젝트 진행 기록
- Confluence에 작성 (연동과정은 서비스형 AI 구축에 정리)
- Github
📚 기술 스택 및 툴
- Ptyhon 3.9
- FastAPI
- AWS
- Vue.js
- Keras
- Pytorch
- Flutter
- Github
- Jira
- Confluence
- Slack
📋RFP(예시)
1. 사업안내
1.1 개요
| 항목 | 내용 |
|---|---|
| 사업기간 | 공유경제 기반 우산 대여 서비스 |
| 사업비 | 금 100,000,000원 (VAT 포함) |
| 도메인 | www.borrow-san.shop |
1.2 사업 목적
갑작스런 우천 시 저가우산(비닐 우산 등) 구매율이 증가하고 있다. 하지만, 높은 가격 대비 낮은 내구성을 가진 경우가 많다. 이로 인한 환경오염 문제를 개선하기 위해 불필요한 우산 구매 대신, 양질의 우산 대여를 장려하고자 이 사업을 계획했다.
1.3 사업 내용
-
우산과 우산 대여함, 사용자용 애플리케이션(이하 앱), 관리자용 웹 페이지(이하 서버)로 구성한다.
-
우산은 사용자의 안전을 고려하여 밝은 색(프레임과 천의 대비가 큰 제품)을 사용하며, 대여함은 종각역 8번 출구와 종각역 YMCA 건물 1층에 설치한다.
-
우산 손잡이의 QR과 대여함의 QR을 사용자가 카메라에 동시에 담았을 때 결제창이 출력된다.
-
사용자 앱은 가입이 필요하다. 앱을 실행시키면 출력되는 지도 위에 대여함의 위치와 잔여 우산 개수를 확인 할 수 있다. 결제 정보 작성 안내창은 가입 직후 권유한다.
-
대여 시, 사용자가 촬영하기 전에 예시 사진 및 촬영 가이드(밝기, 촬영 각도 등)를 띄운다. 사용자가 일일 대여료 1,000원과 보증금 5,000원을 합산한 6,000원을 결제하면 대여함의 잠금장치가 해제되며, 우산 사용이 가능해진다.
-
사용자가 파손 정도가 심한 우산을 대여했다면, 같은 대여함에서만 우산 교체(5분 제한)가 가능하다. 현재 대여함에 잔여 우산이 없는 경우에만 제한적으로 환불이 가능하다.
-
우산의 대여와 반납은 서로 다른 대여함에서도 가능하다. 반납 시에도 대여와 동일하게 대여함과 우산의 QR을 동시에 촬영해야 한다. 우산과 대여함의 QR코드가 서버로 전송되어 자동으로 앱 속 대여함의 우산 개수를 변경한다.
-
우산 반납 시에 사용자는 우산 내부의 프레임이 보이도록 사진을 촬영해야 한다. 우산의 파손 정도 파악을 위한 작업으로, 사용자의 사진 데이터가 즉시 서버로 전송되어 우산 상태를 확인 해 보증금 반환 정도를 결정한다.
-
파손으로 인해 보증금을 차감당한 사용자는 이의를 제기 할 수 있다. 이 때, 무분별한 파손 판단을 최소화 시키기 위해, 대여 즉시 고객에게 5분 내로 프레임을 포함한 사진 촬영을 권장하는 알림이 전송된다. 하지만 알림을 수신 받고도 사진을 촬영하지 않으면 이의 제기는 불가능하다.
-
반납된 우산이 파손률이 높은 우산인 경우 서버에 우산 상태 알림을 띄운다. 대여함 내부에 우산이 없거나, 너무 많은 경우에도 알림을 띄워 수동으로 수거 및 우산 개수 조정이 가능하도록 한다.
-
서버에서 대여함 별 매출과 총 매출(기간별) 확인이 가능하며, 대여 및 반납 비율을 토대로 대여함 별 권장 우산 개수를 계산한다.
📃데이터 수집
1. 대여함 설치 장소 추천용 데이터 수집(git-hub 링크 참고)
-
시간대 별 유동 인구
-
자치구 별 거주 인구
-
지하철 자치구 별 하차 인원
-
유사 모델(따릉이) 대여소 자료
2. 대여함 우산 개수 추천용 데이터 수집(git-hub 링크 참고)
-
유사 모델(따릉이) 일 강수량 별 이용 자료
-
유사 모델(따릉이) 월 별 이용 자료
3. 데이터 정형화
-
데이터 정형화에 Pandas, Numpy를 사용한다.
-
코드와 명칭이 함께 작성되거나, 명칭 속성이 사용 된 데이터는 파일에서 명칭 속성을 제거해 코드만 남기고, 코드와 명칭 속성만 존재하는 새로운 파일을 만든다.
4. 객체 인식 모델 학습용 데이터 수집
-
객체 인식을 위한 학습 용 이미지는 구글에서 크롤링 해 사용한다.
-
학습을 위해 수집해야 할 데이터는 우산, 우산이 아닌 사물, 사람의 손이다.
-
한 검색어 당 수집하는 이미지 개수가 200개 이상이면 정확도가 떨어지기 때문에, 각 언어 별(ko, en, jp 등 10개 언어)로 검색한 이미지를 수집한다.
📁데이터 베이스 구상
1. ERD 구성
- 운영 시 수집 될 데이터를 보관 할 저장소를 구축한다.
1.1 1차
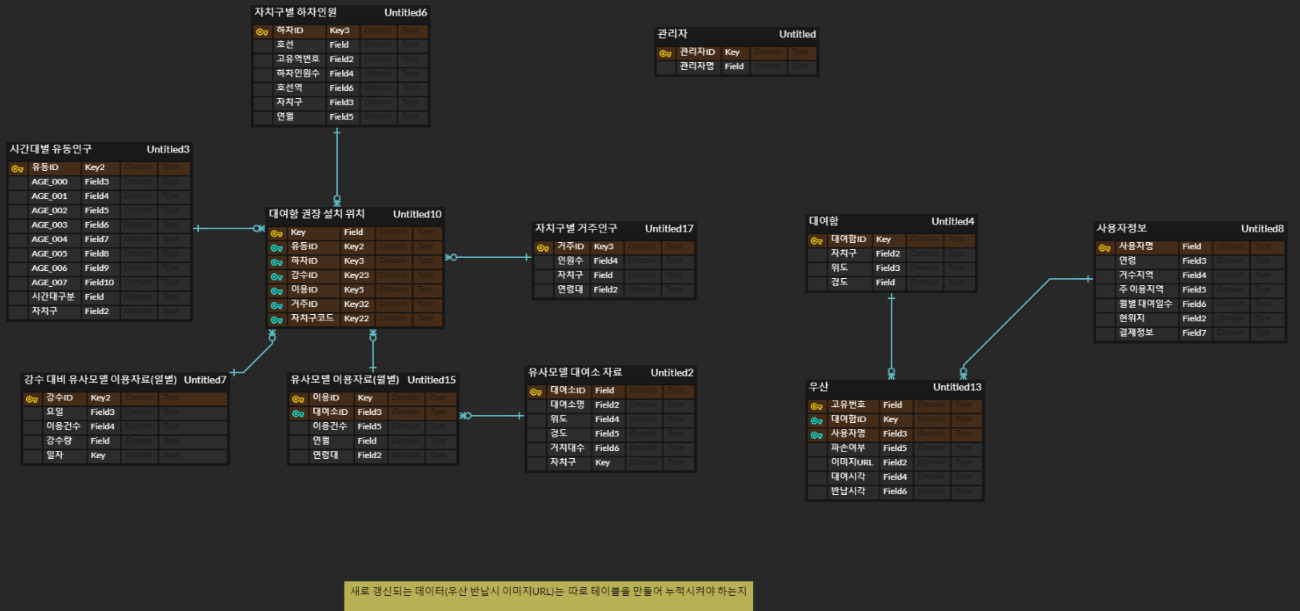
1.2 2차
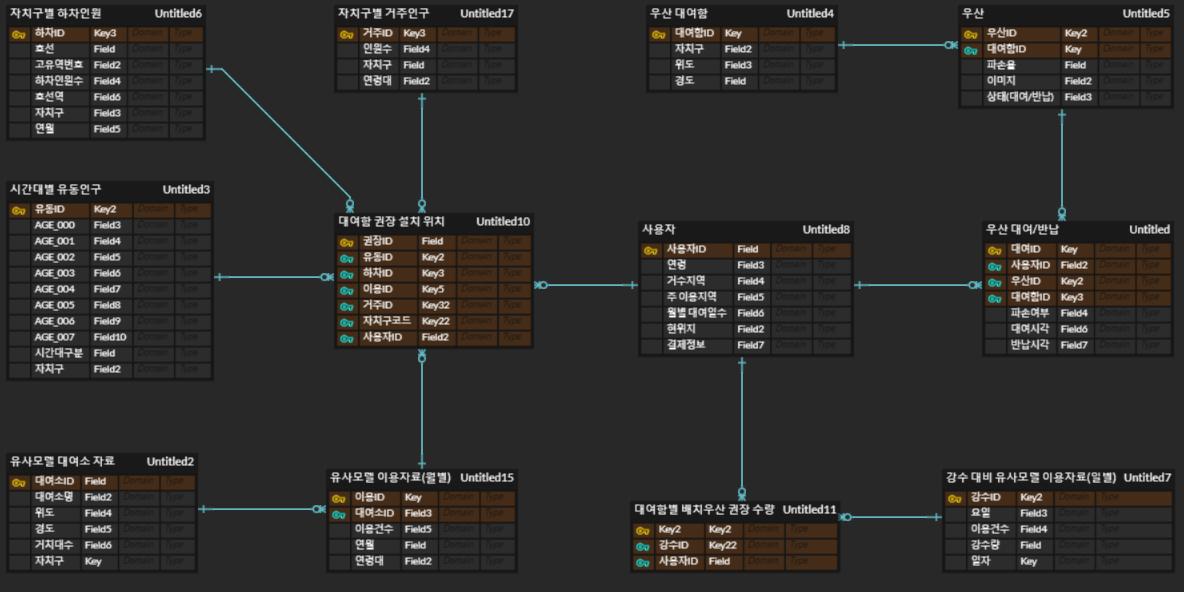
변경사항
- 사용자엔티티와 우산엔티티는 다대다 관계이므로 크로스엔티티를 추가해 역정규화
- 우산 파손여부 외에 파손율 변수 추가
- 대여함 설치위치와 관련된 데이터들과 우산 배치개수와 관련된 데이터로 분리
1.3 3차
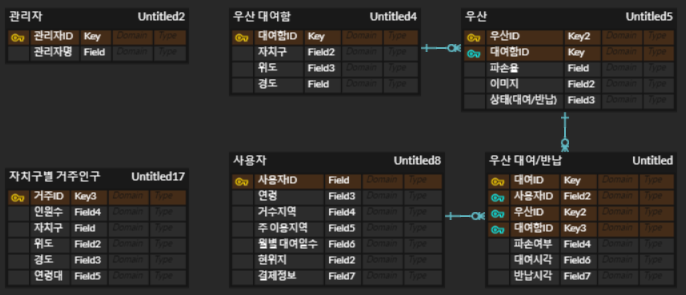
변경사항
- 필요이상으로 많은 테이블이 만들어져서 테이블 종류를 제한
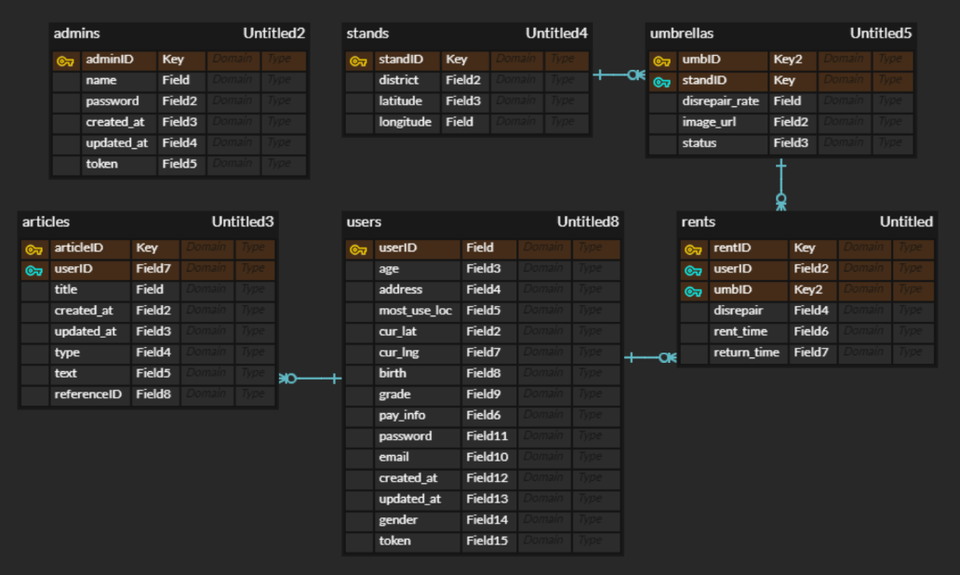
1.4 최종 ERD
변경사항
- 사용자 엔티티 필드 중 위치를 위도/경도로 구분하고 비밀번호 필드 추가
- 게시판(boards)엔티티를 추가
- 프런트와 필드명 일치 검토 필요하다.
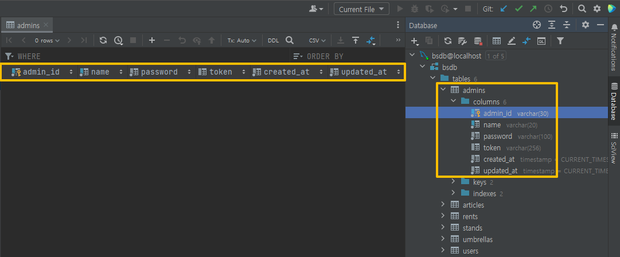
- 테이블은 관리자, 우산, 대여함, 대여 일지, 사용자, 게시판의 총 6개로 분류한다.
각 테이블의 세부 내용
관리자
관리자ID, 이름, 비밀번호, 가입 일자, 수정 일자, 토큰
모든 테이블에 접근 권한이 있다.
우산
- 우산ID, 파손율, 이미지, 상태
- 외래 키로 대여함 테이블의 대여함ID를 받는다.
대여함- 대여함ID, 자치구, 위도, 경도
대여 일지- 대여ID, 파손 여부, 대여 시각, 반납 시각
- 외래 키로 우산 테이블의 우산ID와 사용자 테이블의 사용자ID를 받는다.
사용자- 사용자ID, 연령, 거주 지역, 주 이용 지역, 현 위치 위도, 현 위치 경도, 생년월일, - 등급, 결제정보, 비밀번호, 이메일, 가입 일자, 정보 수정 일자, 성별, 토큰
게시판- 게시 글ID, 제목, 작성 일자, 수정 일자, 유형, 내용, 원 글ID
- 외래 키로 사용자 테이블의 사용자ID를 받는다.
2. FastAPI 데이터 베이스 구축
-
ERD 구성을 바탕으로 각 테이블과 컬럼을 코드로 생성한다.
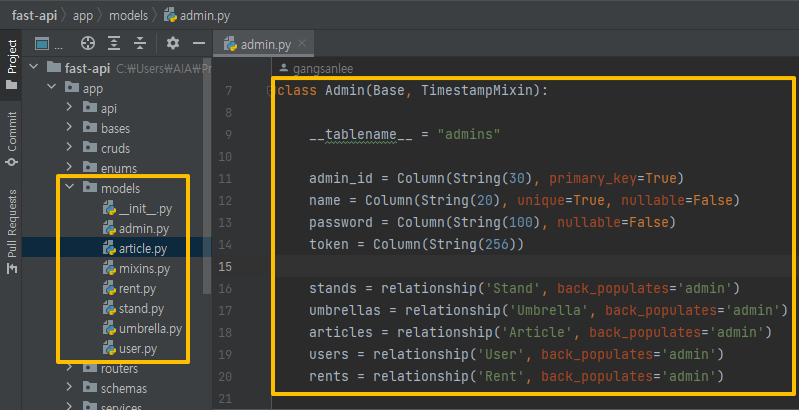
-
Docker 를 사용하기 때문에 Docker compose up 명령어 입력 시 테이블이 자동으로 생성된다.
💻웹 제작
프론트엔드 희망하는 팀원이 따로 없고 앱 위주의 서비스이기 때문에 가벼운 랜딩 페이지로 제작
1. 웹 목업 제작
- Balsamiq mockups을 사용해 작업을 진행한다.
- 웹은 고객이 보는 서비스 소개 페이지와, 관리자가 보는 관리자 페이지 2개로 구분된다.
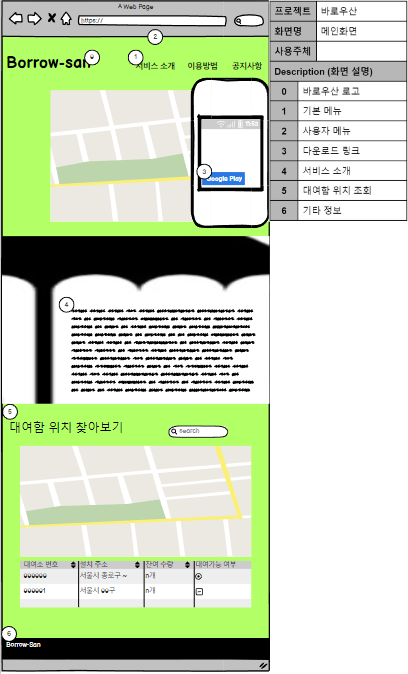
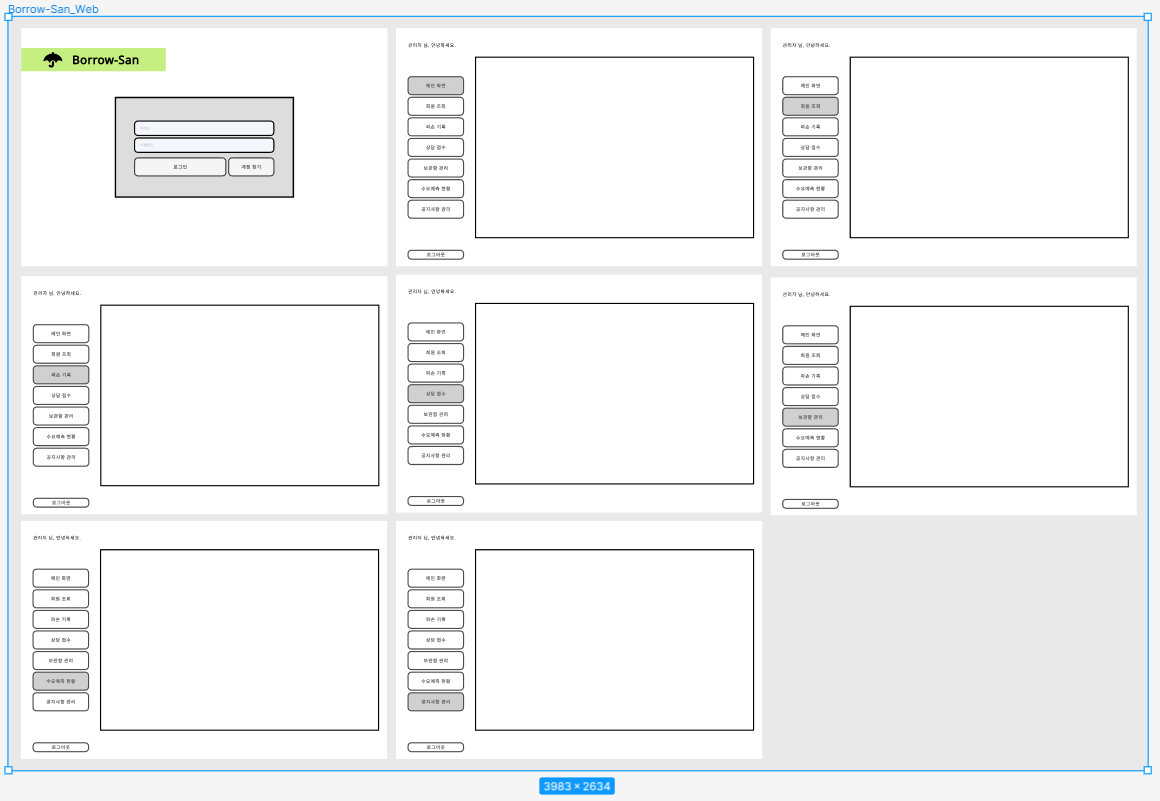
1.1 Figma 제작
- 목업에서 사용 가능한 HTML 코드를 추출하기 위해 Figma를 사용했다.
- 관리자 페이지는 로그인 창과 관리 창으로 구성되며, 관리창은 네비게이터 버튼만 클릭하면 내부 화면이 바뀌는 형태로 구성한다.
2. 랜딩 페이지
2.1 초안

2.1.1 제작 중 추가 내용
- 랜딩페이지에서 깃허브 등 상세 링크로 이동할 때 새 화면이 랜딩페이지의 창에서 열려서 열람에 불편을 끼침
target="_blank"를 태그에 추가해서 해결
2.1.2 보완사항
- 서비스 소개 항목 벨로그 게시물로 교체
- 미구현 항목 제거

3. 관리자 페이지
pass
4. CURD 분석
| 관리자 | 게시글 | 대여 기록 | 보관함 | 우산 | 사용자 | |
|---|---|---|---|---|---|---|
| 회원 탈퇴 | C | |||||
| 회원 정보 변경 | D | |||||
| 관리자 생성 | C | U | ||||
| 관리자 삭제 | D | |||||
| 로그인 & 로그아웃 | U | U | ||||
| 신규 우산 등록 | U | C | ||||
| 우산 대여 | C | U | U | R | ||
| 우산 반납 | U | U | U | R | ||
| 우산 정보 조회 & 변경 | U,R | U | ||||
| 대여 기록 삭제 | C | U,R | U,R | R | ||
| 신규 보관함 추가 | C | U,R | ||||
| 보관함 삭제 | D | U, R | ||||
| 보관함 정보 변경 | U | |||||
| 보관함 조회 | R | R | ||||
| 게시글 작성 | R | C | R | R | ||
| 게시글 답변 | R | C, U | R | R | ||
| 게시글 삭제 | R | D | R |
📱앱 제작
1. Flutter 작업 시작
- Figma 디자인에 따른 모바일 어플리케이션 페이지 및 레이아웃 Flutter로 구현
1.1 페이지
| 네비게이션바(임시) | 시작화면 | 로그인 |
|---|---|---|
 |  |  |
| 회원가입 | 로딩화면 | 메인 화면 (대여 전) |
|---|---|---|
 |  |  |
| QR 스캔 | 오류보고 | 메뉴 |
|---|---|---|
 |  |  |
| 사용자 프로필 | 결제 정보 | 이용 방법 | 문의 내역 |
|---|---|---|---|
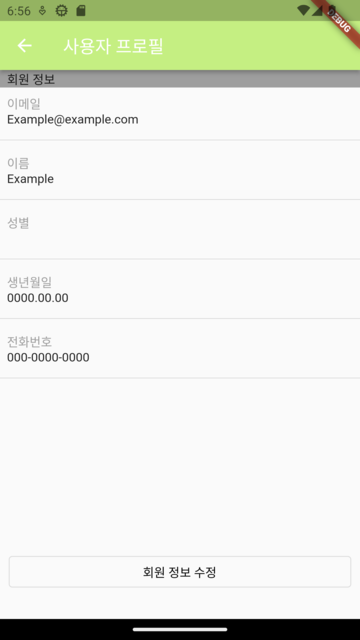 | 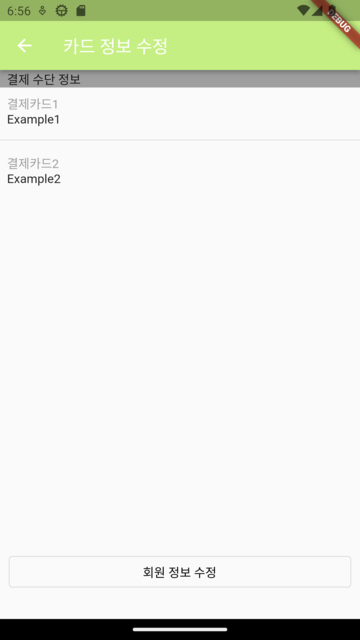 | 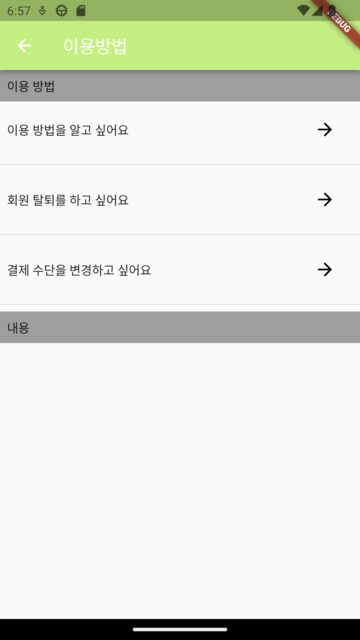 | 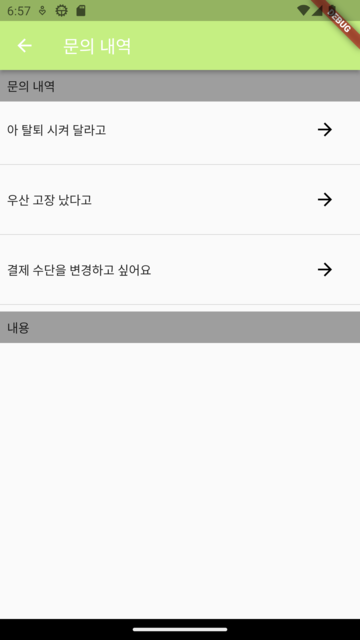 |
추후 작업 요망
- 챗봇 기능 추가 시 챗봇 위젯 구현 필요
- 위젯간 데이터 전송 및 상태 관리
- API 를 통한 request 및 response 처리
2. 기능 구현
2.1 앱 로그인 및 로그아웃 기능 구현
- REST API를 이용해 fastAPI 서버와 로그인 기능을 연동할 수 있는지 테스트 해보고자 한다.
- 서버는 POST 방식으로 user_email과 password 키값을 가지는 JSON을 보내면 해당 Token을 똑같은 JSON형태로 돌려준다.
소스코드
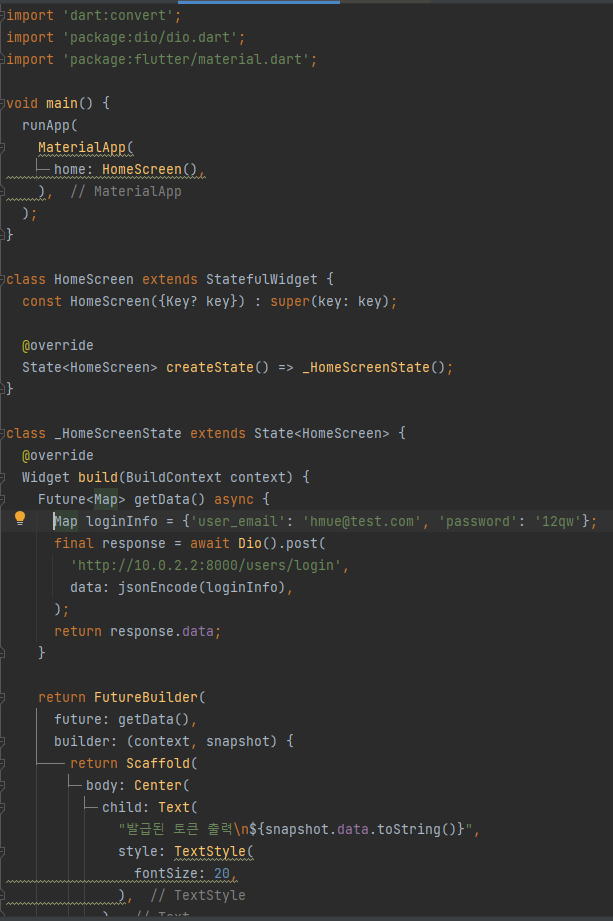
에러 발생
INFO: 172.18.0.1:50394 - "POST /users/login HTTP/1.1" 422 Unprocessable Entity - 원인 : 데이터를 JSON 형태로 Post 하지 않아서 생긴 문제다. jsonEncode 함수에 Map 형태의 값을 넣어 보내도록 한다.

-화면을 통해 발급받은 토큰을 확인했다.
만들어놓은 레이아웃에 적용시킨 소스 코드
import 'dart:convert';import 'package:dio/dio.dart';import 'package:flutter/material.dart';import 'package:flutter_project/const/constants.dart';import 'package:flutter_project/screen/1_start.dart';import 'package:flutter_project/screen/3_signup.dart';import 'package:flutter_project/widgets/basic_button.dart';import 'package:flutter_project/widgets/input_box.dart';import 'package:flutter_project/widgets/logo.dart';class Login extends StatefulWidget {
Login({super.key}); @override State<Login> createState() => _LoginState();}
class _LoginState extends State<Login> {
String user_email = ''; String password = ''; bool logoAppear = true; @override Widget build(BuildContext context) {
final bottomInset = MediaQuery.of(context).viewInsets.bottom; return Scaffold(
appBar: AppBar(
title: Text("로그인"), ), backgroundColor: MAIN_COLOR, body: Padding(
padding: const EdgeInsets.symmetric(horizontal: 10.0), child: Container(
width: MediaQuery.of(context).size.width, child: Column(
mainAxisAlignment: MainAxisAlignment.center, crossAxisAlignment: CrossAxisAlignment.stretch, children: [
showLogo(), InputBox(
hintText: "아이디", onTap: () {
setState(() {
logoAppear = false; }); }, onChanged: (String value) {
user_email = value; }, ), SizedBox(
height: 10.0, ), InputBox(
hintText: "비밀번호", onTap: () {
setState(() {
logoAppear = false; }); }, onChanged: (String value) {
password = value; }, ), Row(
children: [
Checkbox(value: false, onChanged: (value) {}), Text('자동 로그인'), ], ), SizedBox(
height: 30.0, ), Row(
mainAxisAlignment: MainAxisAlignment.center, children: [
Expanded(
child: BasicButton(
buttonTitle: "로그인", onPressed: () {
postLoginInfo(); print('##### 토큰 정보 : ${postLoginInfo().toString()} #####'); }, ), ), SizedBox(
width: 10.0, ), Expanded(
child: BasicButton(
buttonTitle: "계정 찾기", onPressed: () => Navigator.push(
context, MaterialPageRoute(
builder: (context) => Start(), ), ), ), ), ], ), BasicButton(
buttonTitle: "회원가입", onPressed: () => Navigator.push(
context, MaterialPageRoute(
builder: (context) => SignUp(), ), ), ), ], ), ), ), ); }
Widget showLogo() {
if (logoAppear) {
return Column(
children: [
Logo(), SizedBox(
height: 50.0, ), ], ); } else {
return SizedBox(
height: 20.0, ); }
}
Future<Map> postLoginInfo() async {
Map loginInfo = {
'user_email': user_email, 'password': password, }; print('##### loginInfoMap is ${loginInfo} #####'); final response = await Dio().post(
'http://10.0.2.2:8000/users/login', data: jsonEncode(loginInfo), ); return response.data; }
}- 이메일과 비밀번호의 초기값이 onChanged 함수를 통해 TextFieldForm의 값으로 변경되어 저장된다.
2023.02.28. 로그인, 로그아웃 구현 마무리 작업
- TextFormField 위젯의 onChanged 함수를 이용하면 이메일과 비밀번호를 작성하는 중에도 상태가 변경되어 상태관리가 어려워진다.
- 대안으로 onSaved 함수를 이용해 값을 저장하고 TextFormField 위젯을 Form 위젯으로 감싸 GlobalKey() 클래스를 이용해 저장된 값들을 관리한다.
- Dio를 이용해 응답받은 토큰은 FlutterSecureStorage 라이브러리를 이용해 값을 저장, 로그아웃에 이용한다.
- showDialog함수를 이용해 로그인 성공, 실패시 알림창이 뜨게하고 알림창을 확인했을 때 Navigator를 이용해 알맞은 스크린으로 이동하도록 한다.
- obscureText 기능을 통해 비밀번호 입력 시 “*”기호로 보이게 한다.
2.2 앱 로그인 및 로그아웃 기능구현 상세
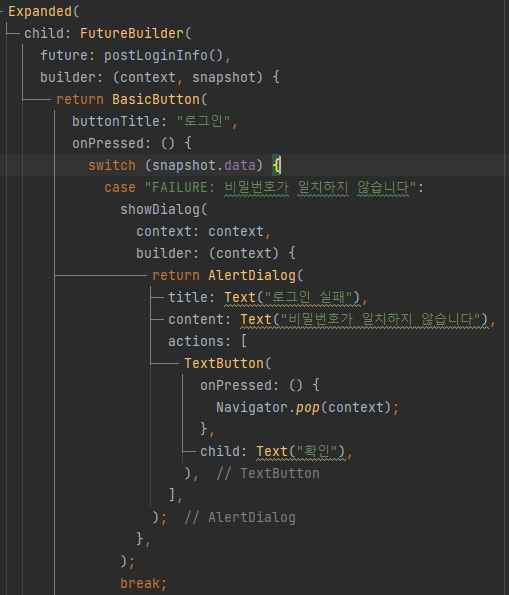
- 로그인 성공 혹은 실패 시 API의 응답 데이터가 FutureBuilder의 snapshot에 저장된다. 저장된 데이터의 경우의 수만큼 switch문으로 코드를 작성한다.
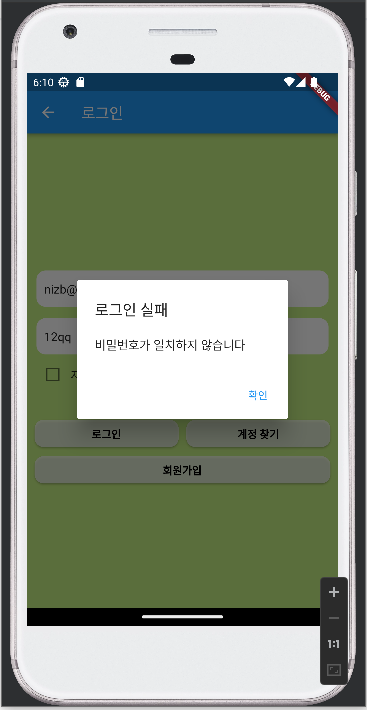
- 비밀번호가 일치하지 않았을 경우
| 소스코드 | 화면 |
|---|---|
 |  |
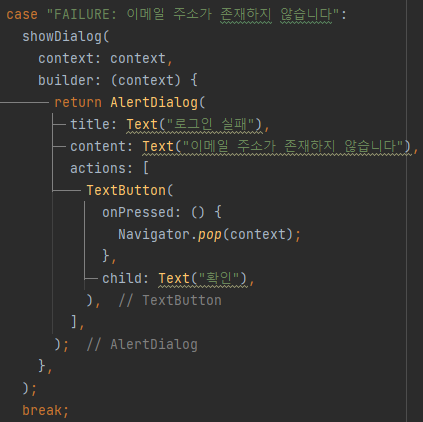
- 아이디가 일치하지 않았을 경우
| 소스코드 | 화면 |
|---|---|
 | 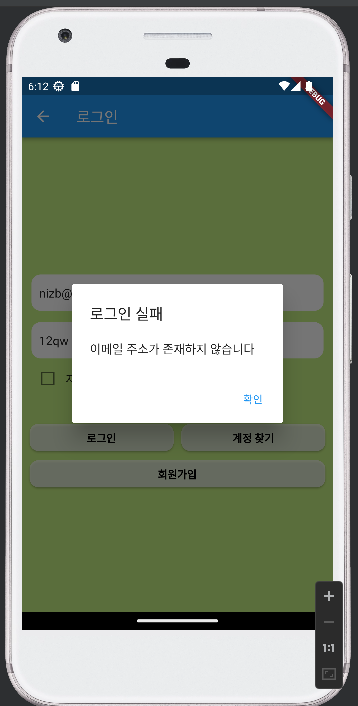 |
- 로그인에 성공했을 경우
| 소스코드 | 화면 |
|---|---|
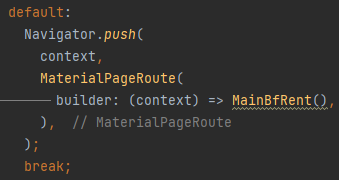 | 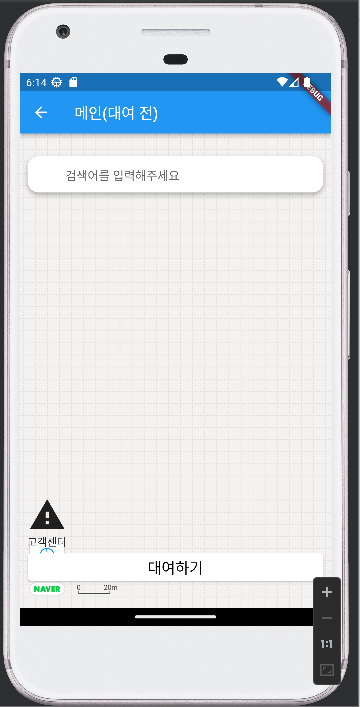 |
2.3 앱 회원가입 기능 구현
- 우선 회원가입에 필수 정보인 “이메일”과 “비밀번호”, “비밀번호 재입력” TextFieldForm 을 만든다
- “비밀번호 재입력” 칸을 이용해 비밀번호를 정확히 입력했는지 검증한다.
- 이메일, 비밀번호가 null값이 아니고 비밀번호와 재입력 비밀번호가 일치하면 Dio 라이브러리를 통해 서버에 이메일과 비밀번호 값을 JSON 형태로 보낸다.
- 서버에서 응답받은 값 (null, 회원가입성공, 회원가입실패, 이미 존재하는 이메일) 에 따라 Dialog를 보여준다.
- 회원가입이 완료되면 Dialog의 ‘확인’버튼을 누르고 로그인 페이지로 이동한다.
2.4 앱(안드로이드) 지도 기능 구현
flutter_naver_map 플러그인을 통해 지도 위에 우산 대여함의 위치를 마킹하고 우산 대여함 아이콘을 클릭하면 우산 대여 화면으로 넘어가도록 한다.
네이버 API 사용 방법
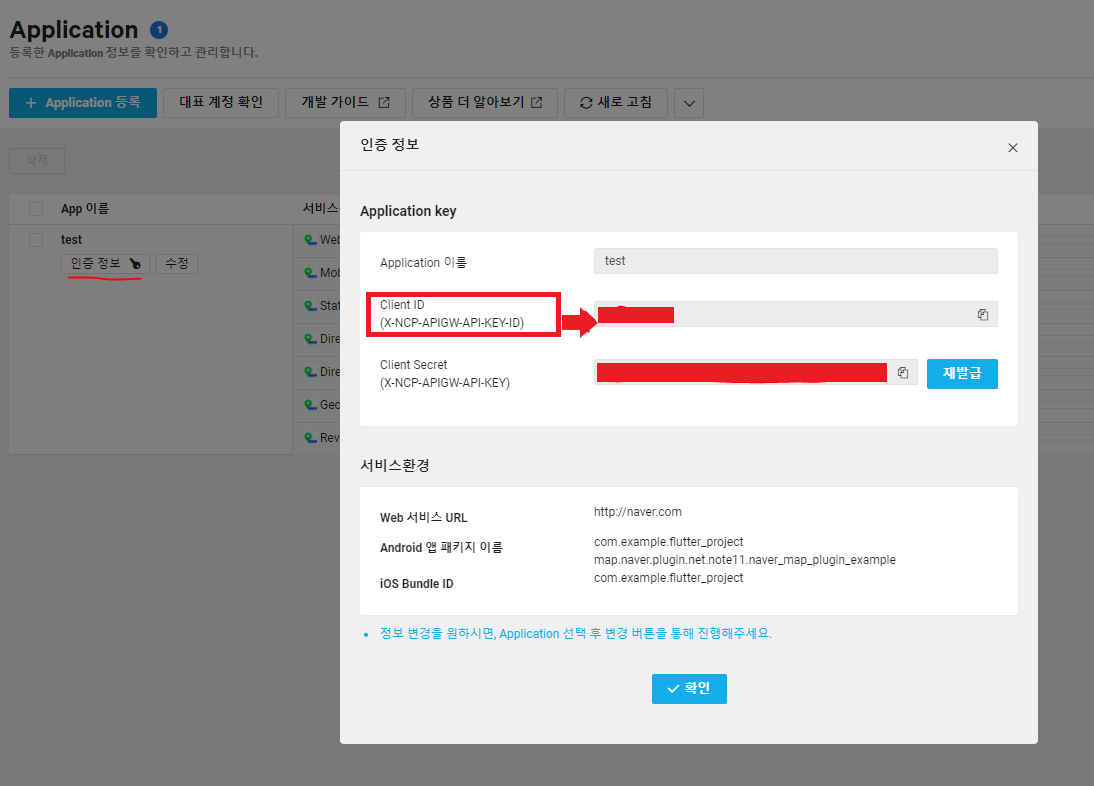
- 네이버 클라우드 콘솔에 접속해 지도 API Key를 발급받는다.
- 현재 진행 중인 플러터 프로젝트 명을 그대로 입력한다.
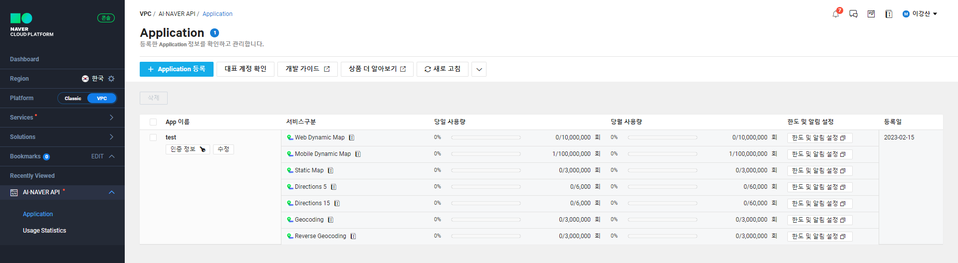
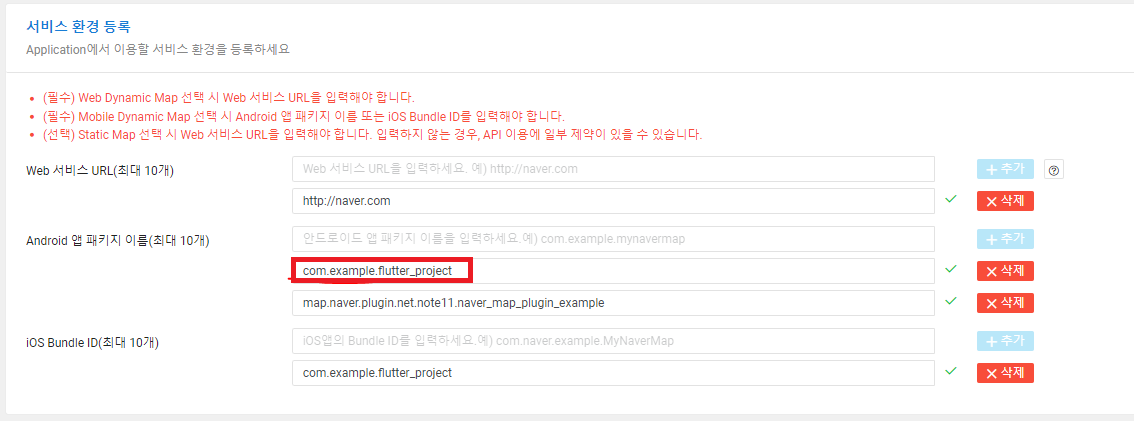
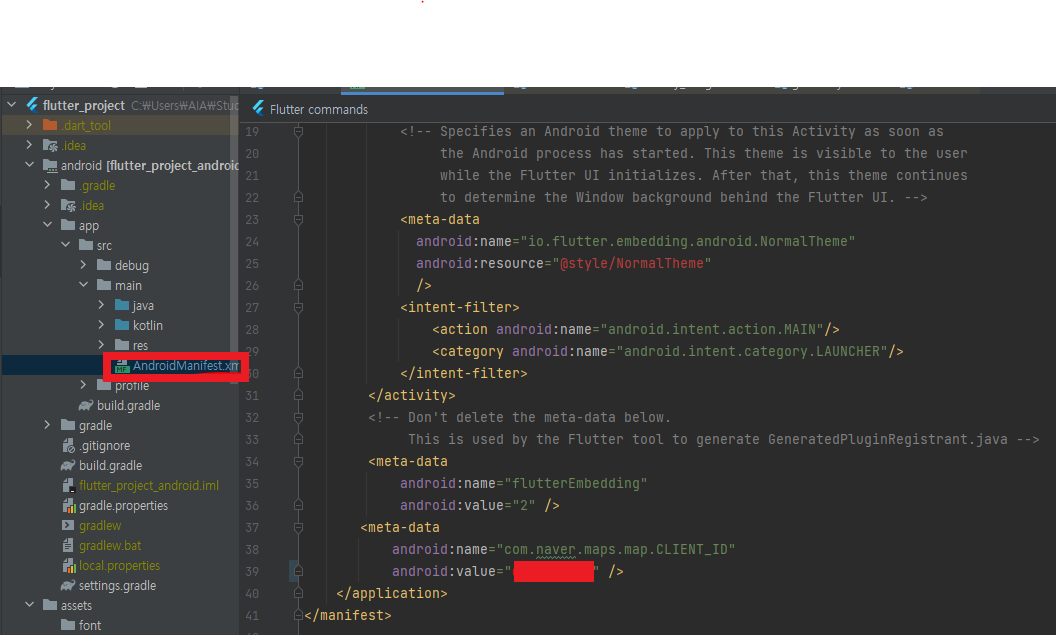
- 클라이언트ID를 진행중인 프로젝트의 AndroidManifest.xml 파일에 입력한다.
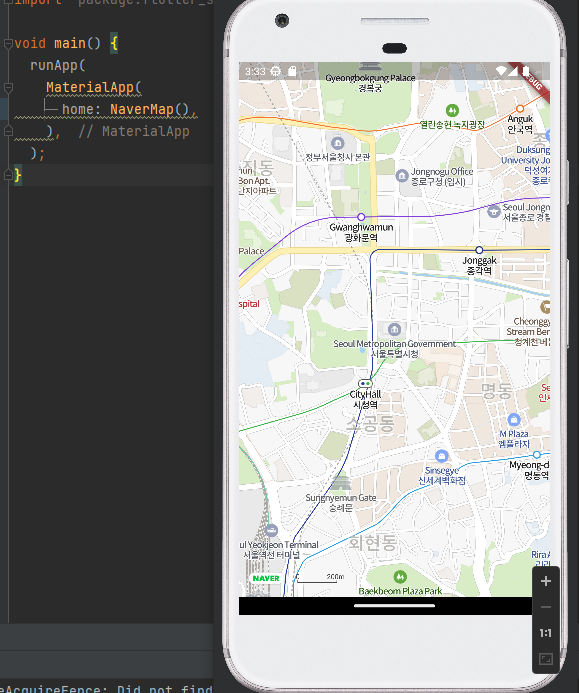
- 에뮬레이터를 통해 이상없이 나오는지 확인한다.
2.4.1 우산대여함 위치에 마킹하기
-
initialCameraPosition키를 통해 지도를 켰을 때 처음 위치를 설정한다. -
초기 위치는 우선 우산대여함 위치와 동일하게 설정한다.
-
markers키를 통해 마커를 입력한다. -
마커 아이콘은 assets 디렉토리에 있는 우산이미지를 이용하였다.
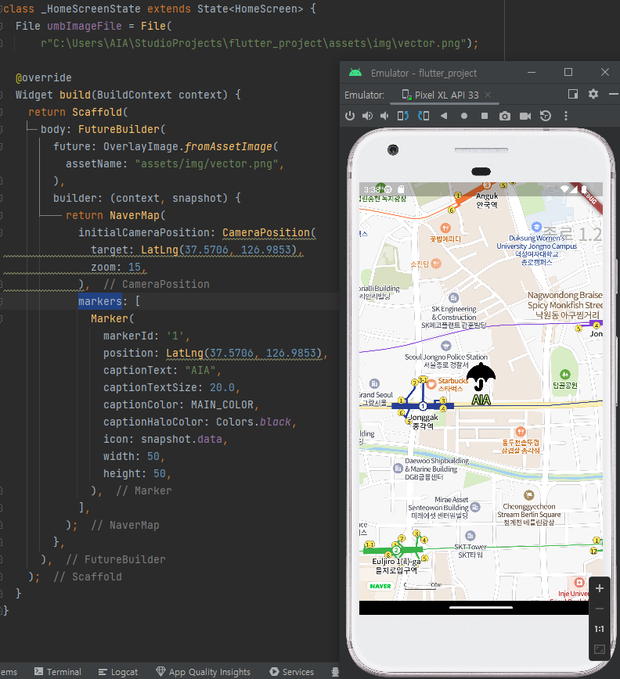
-
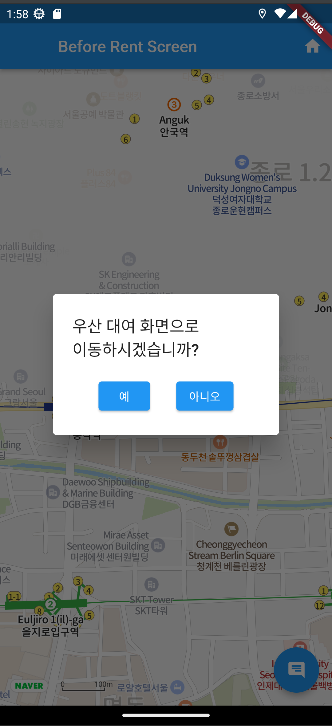
우산 아이콘을 클릭시 우산 대여 혹은 반납 페이지로 이동할 수 있는 네비게이션 창이 실행된다
Marker(
markerId: '1',
position: LatLng(standLatitude, standLongitude),
icon: snapshot.data,
width: 32,
height: 32,
onMarkerTab: (marker, iconSize) {
showDialog(
context: context,
builder: (context) {
return AlertDialog(
title: Text("우산 대여 화면으로\n이동하시겠습니까?"),
content: Row(
mainAxisAlignment:
MainAxisAlignment.spaceEvenly,
children: [
ElevatedButton(
onPressed: () {
Navigator.of(context).push(
MaterialPageRoute(
builder: (context) =>
RentScreen(),
),
);
},
child: Text("예"),
),
ElevatedButton(
onPressed: () {
Navigator.of(context).pop();
},
child: Text("아니오"),
),
],
),
);
},
);
},
),
2.4.2 사용자 현재 위치 표시
- geolocator 패키지를 사용
dependencies:
geolocator: ^9.0.2- flutter pub get 명령어로 dependency를 적용
import 'package:geolocator/geolocator.dart';
Future<String> checkLocationPermission() async {
final isLocationEnabled = await Geolocator.isLocationServiceEnabled();
if (!isLocationEnabled) {
return "위치 서비스를 활성화해주세요.";
}
LocationPermission checkedPermission = await Geolocator.checkPermission();
if (checkedPermission == LocationPermission.denied) {
checkedPermission = await Geolocator.requestPermission();
if (checkedPermission == LocationPermission.denied) {
return "위치 권한을 허가해주세요.";
}
}
if (checkedPermission == LocationPermission.deniedForever) {
return "앱의 위치 권한을 설정에서 허가해주세요.";
}
return "위치 권한이 허가 되었습니다.";
}class BeforeRentScreen extends StatefulWidget {
const BeforeRentScreen({Key? key}) : super(key: key);
@override
State<BeforeRentScreen> createState() => _BeforeRentScreenState();
}
class _BeforeRentScreenState extends State<BeforeRentScreen> {
final standLatitude = 37.5706;
final standLongitude = 126.9853;
@override
Widget build(BuildContext context) {
return WillPopScope(
onWillPop: () {
return Future(() => false);
},
child: Scaffold(
appBar: AppBar(
title: Text("Before Rent Screen"),
leading: Container(),
// 배포 시 홈버튼 삭제
actions: [homeButton(context)],
),
body: Stack(
children: [
FutureBuilder<String>(
future: checkLocationPermission(),
builder: (context, snapshot) {
if (snapshot.hasData &&
snapshot.connectionState == ConnectionState.waiting) {
return Center(
child: CircularProgressIndicator(),
);
}
if (snapshot.data == '위치 권한이 허가 되었습니다.') {
return FutureBuilder(
future: OverlayImage.fromAssetImage(
assetName: 'assets/images/umb_icon.png',
),
builder: (context, snapshot) {
return NaverMap( ...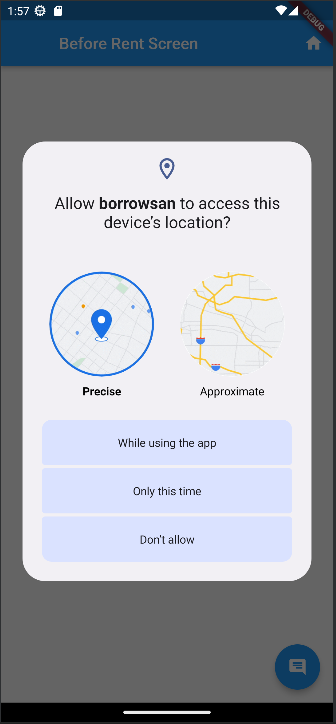
2.5 앱 게시판 기능 구현
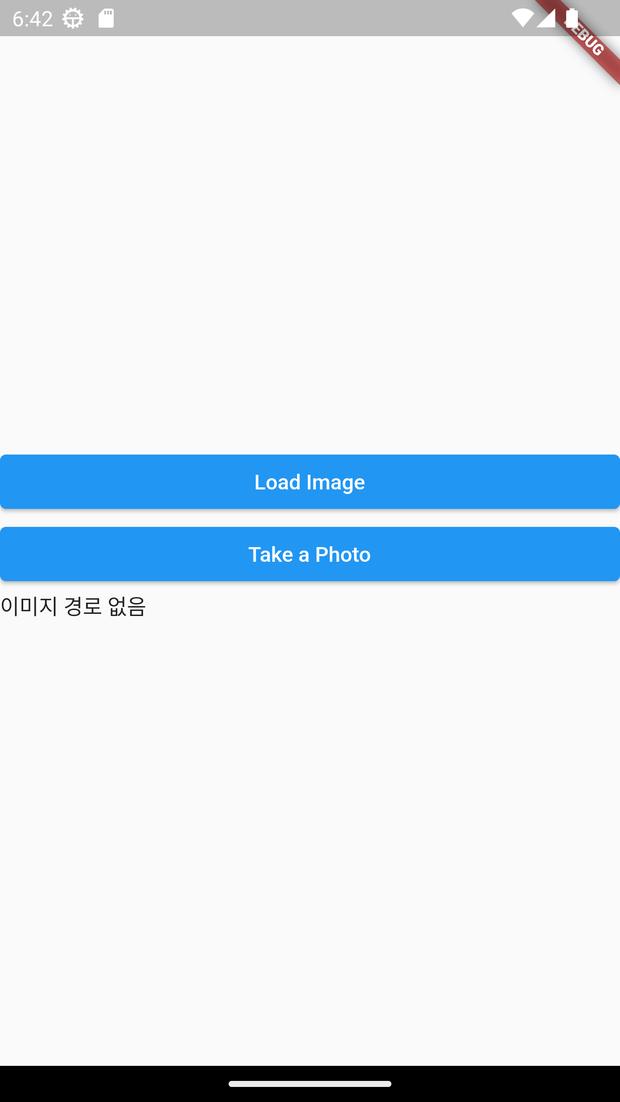
- 게시글 작성 시 첨부파일 업로드 테스트
- image_picker 패키지를 사용해 갤러리 혹은 카메라로 사진을 불러온다.
소스코드 :
import 'dart:io';
import 'package:dio/dio.dart';
import 'package:flutter/material.dart';
import 'package:image_picker/image_picker.dart';
void main() {
runApp(
MaterialApp(
home: HomeScreen(),
),
);
}
class HomeScreen extends StatefulWidget {
const HomeScreen({Key? key}) : super(key: key);
@override
State<HomeScreen> createState() => _HomeScreenState();
}
class _HomeScreenState extends State<HomeScreen> {
String? imagePath;
XFile? tokenPthoto;
@override
Widget build(BuildContext context) {
return Scaffold(
body: Column(
mainAxisAlignment: MainAxisAlignment.center,
crossAxisAlignment: CrossAxisAlignment.stretch,
children: [
ElevatedButton(
onPressed: () async {
final image =
await ImagePicker().pickImage(source: ImageSource.gallery);
print(image);
},
child: Text("Load Image"),
),
ElevatedButton(
onPressed: () async {
final image = await ImagePicker().pickImage(
source: ImageSource.camera,
maxHeight: 100,
maxWidth: 100,
imageQuality: 30,
);
print("이미지 경로 : ${image!.path}");
print("이미지 경로 타입 : ${image.path.runtimeType}");
setState(() {
imagePath = image.path;
tokenPthoto = image;
});
},
child: Text("Take a Photo"),
),
previewPhoto(),
],
),
);
}
Widget previewPhoto() {
if (imagePath == null) {
return Container(
child: Text("이미지 경로 없음"),
);
} else {
return Column(
children: [
Text("이미지 경로 : $imagePath"),
Image.file(
File(imagePath!),
width: 200,
height: 200,
),
],
);
}
}
}| 첫 화면 | 이미지 선택 화면 | 이미지 로드 완료 |
|---|---|---|
 |  | 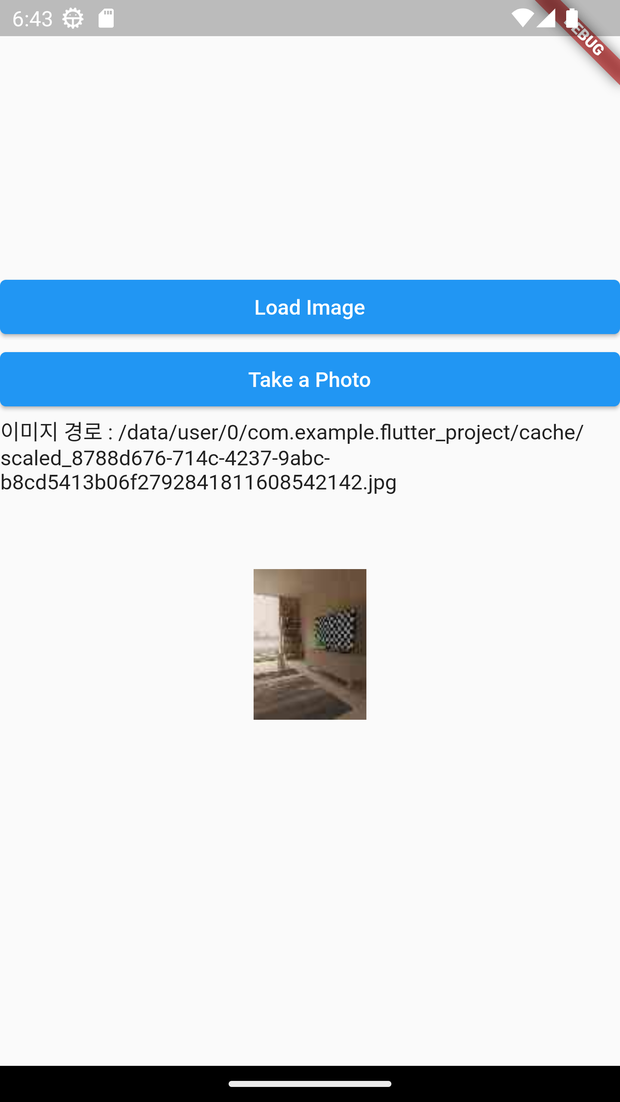 |
- 촬영한 데이터 (혹은 불러온 데이터)를 서버에 전송한다.
- Dio 패키지의 post 함수를 사용한다.
2.6 앱 챗봇 기능 구현
챗봇 응답 서버와 통신 가능 테스트
- http 패키지의 post 메서드를 이용해 서버의 챗봇 인공지능 모델과 통신한다.
- ListView builder를 이용해 사용자와 챗봇의 메세지를 화면에 나타낸다.
- 소스코드 :
챗봇 응답 서버와 통신 가능 테스트
http 패키지의 post 메서드를 이용해 서버의 챗봇 인공지능 모델과 통신한다.
ListView builder를 이용해 사용자와 챗봇의 메세지를 화면에 나타낸다.
소스코드 : - 에뮬레이터 화면
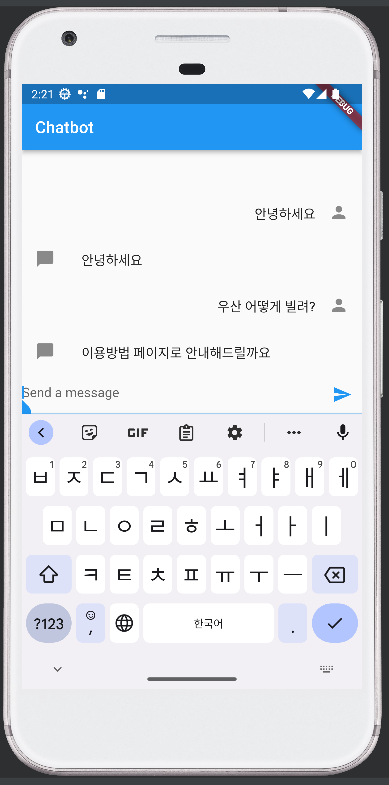
2.7 QR코드 인식
- QR code scanner 패키지를 pub.dev 에서 가져온다
dependencies:
qr_code_scanner: ^1.0.1- QR코드 인식에 성공하는 순간 우산 내부 사진을 캡쳐하기 위해 Screenshot 패키지를 pub.dev 에서 가져온다
dependencies:
screenshot: ^1.3.0- flutter pub dev 명령어로 depndency를 적용
- class의 속성으로 screenshot의 controller, qrview의 controller, qrcode, 캡쳐 시 QR 가이드라인을 제거하기 위해 boolean값을 생성
class RentScreen extends StatefulWidget {
const RentScreen({Key? key}) : super(key: key);
@override
State<RentScreen> createState() => _RentScreenState();
}
class _RentScreenState extends State<RentScreen> {
final screenshotController = ScreenshotController();
String? qrCode;
QRViewController? controller;
final GlobalKey qrKey = GlobalKey(debugLabel: 'QR');
bool removeQrScannerOverlayShape = false;
@override
Widget build(BuildContext context) {
double deviceWidth = MediaQuery.of(context).size.width;
return Scaffold( ... 생략 ...- 캡쳐하는 범위는 QRView 위젯 전체이므로 Screenshot 위젯으로 QRView 위젯을 감싼다. QRcode 스캔에 성공하면 카메라를 멈추고 Screenshot의 캡쳐 기능이 발동하도록 코딩한다. 캡쳐에 성공하면 API서버에 발송할지 여부를 묻는 다이얼로그가 뜨고 승인하면 서버에서 QR코드를 매치하고 커스텀한 YOLOv5를 이용해 우산의 고장 여부를 판별
... 생략 ...
return Scaffold(
appBar: AppBar(
title: Text("Rent Screen"),
actions: [
homeButton(context)
],
leading: IconButton(
icon: Icon(Icons.arrow_back),
onPressed: () {
Navigator.of(context).push(
MaterialPageRoute(
builder: (context) => BeforeRentScreen(),
),
);
},
),
),
body: Screenshot(
controller: screenshotController,
child: QRView(
key: qrKey,
overlay: renderQrScannerOverlayShape(deviceWidth),
onQRViewCreated: (controller) {
controller.scannedDataStream.listen(
(scanData) {
if (scanData.code == null) {
return;
} else {
qrCode = scanData.code;
setState(
() {
removeQrScannerOverlayShape = true;
},
);
controller.pauseCamera().then(
(_) async {
final capturedImg = await screenshotController.capture();
showDialog(
context: context,
builder: (context) {
return AlertDialog(
title: Image.memory(
capturedImg!,
width: deviceWidth * 0.75,
height: deviceWidth * 0.75,
),
actions: [
ElevatedButton(
onPressed: () {
setState(
() {
removeQrScannerOverlayShape = false;
},
);
Navigator.pop(context);
controller.resumeCamera();
},
child: Text("다시 스캔"),
),
FutureBuilder(
future:
FlutterSecureStorage().read(key: "token"),
builder: (context, snapshot) {
return ElevatedButton(
child: Text("대여"),
onPressed: () async {
await Dio()
.post(
'$API_DOMAIN/flutter/rent',
data: jsonEncode(
{
"token": snapshot.data,
"qr_code": qrCode,
},
),
)
.then(
(value) {
if (value.data['msg'] == null) {
showDialog(
context: context,
builder: (context) {
return AlertDialog(
title:
Text("서버와 통신에 실패하였습니다"),
actions: [
ElevatedButton(
child: Text("확인"),
onPressed: () {
Navigator.of(context)
.pop();
},
),
],
);
},
);
} else if (value.data['msg'] ==
"대여 성공") {
showDialog(
context: context,
builder: (context) {
return AlertDialog(
title: Text("대여 성공했습니다"),
actions: [
ElevatedButton(
child: Text("확인"),
onPressed: () {
Navigator.of(context)
.push(
MaterialPageRoute(
builder: (context) =>
AfterRentScreen(),
),
);
},
),
],
);
},
);
} else if (value.data['msg'] ==
"대여 실패") {
showDialog(
context: context,
builder: (context) {
return AlertDialog(
title: Text("대여 실패했습니다"),
actions: <Widget>[
ElevatedButton(
child: Text("확인"),
onPressed: () {
Navigator.of(context)
.push(
MaterialPageRoute(
builder: (context) =>
RentScreen(),
),
);
},
),
], // add this
);
},
);
}
},
);
},
);
},
),
],
);
},
);
},
);
}
},
);
},
),
),
);- 캡쳐 시 QR코드 가이드라인이 보이지 않도록 하기 위해
renderQrScannerOverlayShape을 추가
... 생략 ...
QrScannerOverlayShape renderQrScannerOverlayShape(deviceWidth) {
if (removeQrScannerOverlayShape == false) {
return QrScannerOverlayShape(
borderColor: Colors.red,
borderRadius: 5,
borderLength: 15,
borderWidth: 5,
cutOutSize: deviceWidth * 0.2,
);
} else {
return QrScannerOverlayShape(
overlayColor: Colors.black.withOpacity(0.0),
);
}
}
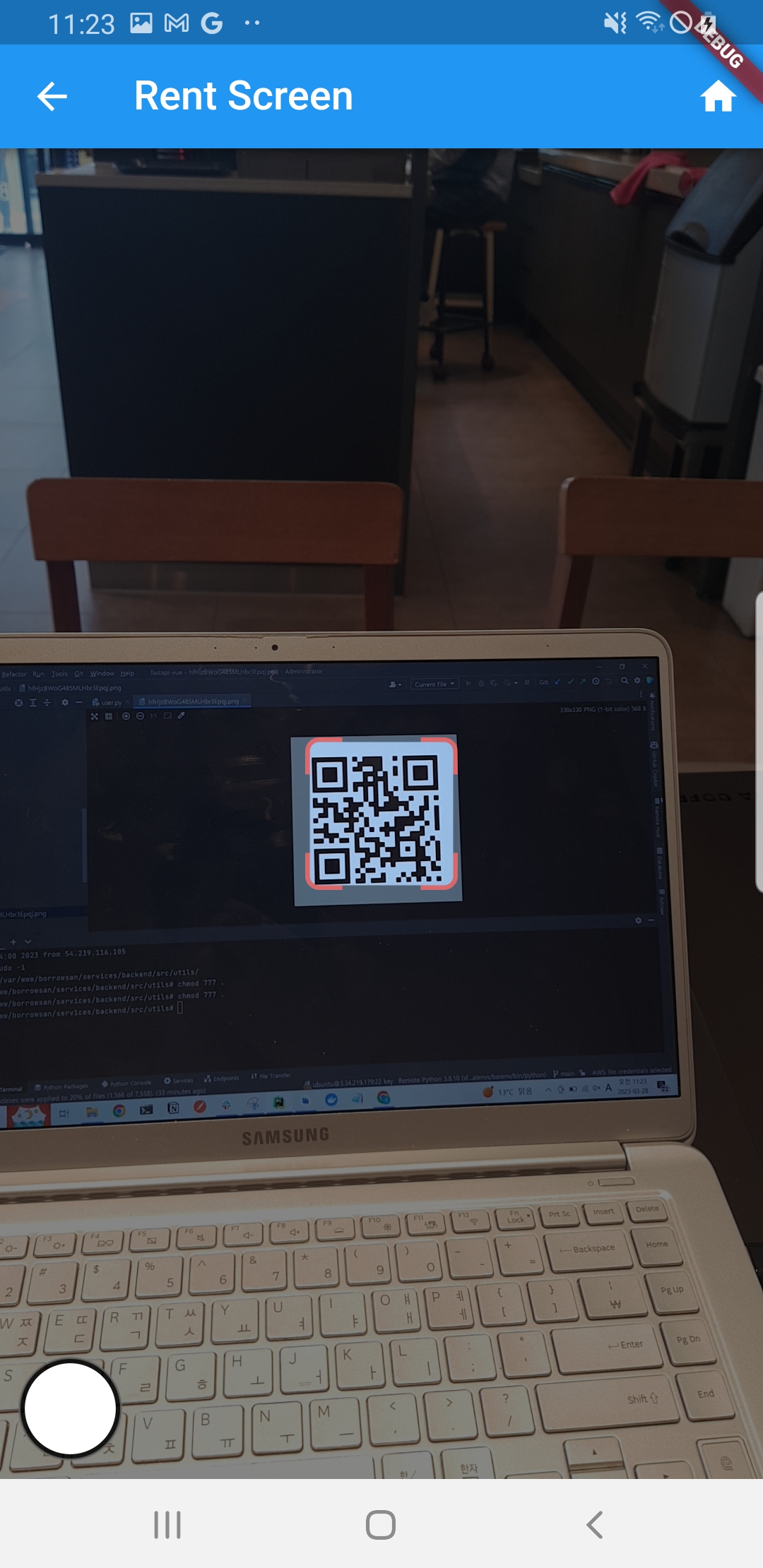
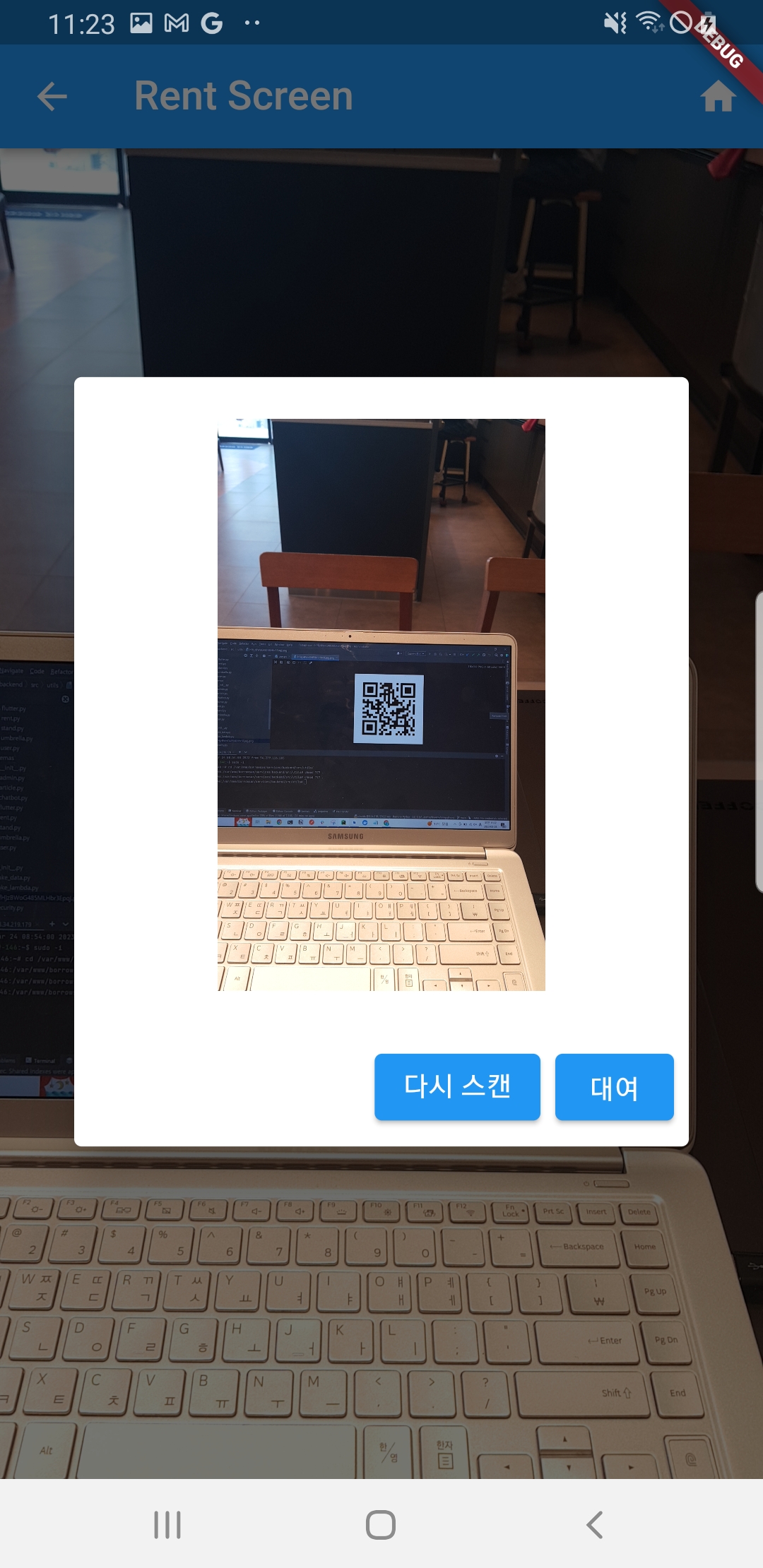
2.8 학습한 모델 실행
소스코드
import 'dart:convert'; import 'package:dio/dio.dart'; import 'package:flutter/material.dart'; import 'package:flutter_secure_storage/flutter_secure_storage.dart'; import 'package:qr_code_scanner/qr_code_scanner.dart'; import 'package:screenshot/screenshot.dart'; import '../const/constant.dart'; class ReturnScreen extends StatefulWidget { const ReturnScreen({Key? key}) : super(key: key); @override State<ReturnScreen> createState() => _ReturnScreenState(); } class _ReturnScreenState extends State<ReturnScreen> { final screenshotController = ScreenshotController(); String? qrCode; QRViewController? controller; final GlobalKey qrKey = GlobalKey(debugLabel: 'QR'); bool removeQrScannerOverlayShape = false; @override Widget build(BuildContext context) { double deviceWidth = MediaQuery.of(context).size.width; return Scaffold( appBar: AppBar( title: Text("Return Screen"), ), body: Screenshot( controller: screenshotController, child: QRView( key: qrKey, overlay: renderQrScannerOverlayShape(deviceWidth), onQRViewCreated: (controller) { controller.scannedDataStream.listen( (scanData) { if (scanData.code == null) { return; } else { qrCode = scanData.code; setState(() { removeQrScannerOverlayShape = true; }); controller.pauseCamera().then( (_) async { final capturedImg = await screenshotController.capture( pixelRatio: 0.50, ); showDialog( context: context, builder: (context) { return AlertDialog( title: Column( children: [ Image.memory(capturedImg!, width: deviceWidth * 0.75, height: deviceWidth * 0.75), Text(qrCode!), Row( children: [ ElevatedButton( onPressed: () { setState( () { removeQrScannerOverlayShape = false; }, ); Navigator.pop(context); controller.resumeCamera(); }, child: Text("다시 스캔"), ), FutureBuilder( future: FlutterSecureStorage() .read(key: "token"), builder: (context, snapshot) { return ElevatedButton( onPressed: () async { var response = await Dio().post( '$API_DOMAIN/flutter/return', data: jsonEncode( { "token": snapshot.data, "qr_code": qrCode, "image": capturedImg, }, ), ); print( "response : ${response.toString()}"); Navigator.of(context).pop(); }, child: Text("반납"), ); }, ), ], ), ], ), ); }, ); }, ); } }, ); }, ), ), ); } QrScannerOverlayShape renderQrScannerOverlayShape(deviceWidth) { if (removeQrScannerOverlayShape == false) { return QrScannerOverlayShape( borderColor: Colors.red, borderRadius: 5, borderLength: 15, borderWidth: 5, cutOutSize: deviceWidth * 0.2, ); } else { return QrScannerOverlayShape( overlayColor: Colors.black.withOpacity(0.0), ); } } }
구현된 화면

결과
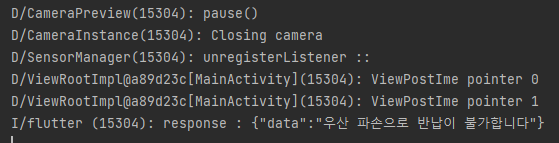
- 로컬에서는 우산을 인식한 모델이 앱에서는 우산인식을 못하는 문제 발생
대안
- 우산 내부 인식이 부족하다고 생각해서 파손 여부 판단에 필요한 우산 내부 이미지를 늘려서 재학습
- 리턴된 값 확인
백엔드
아직 정리내용 없음 #!!!👾인공지능 모델링
1. YOLOv5를 이용한 파손 여부 확인
1.1 전처리
1.1.1 train.py에서 실행하기 위해 사용할 데이터를 가져올 yaml 파일을 생성
path: C:\Users\AIA\PycharmProjects\yolov5\dataset
train: train\images
val: valid\images
nc: 1
names:
0: 'umbrella'1.1.2 기본 Dataset에서 학습 시킬 대상을 가진 데이터만 남기고 나머지 데이터 삭제
train_label_list = glob('C:/Users/AIA/PycharmProjects/datasets/umb/train/labels/*.txt')
for path in train_label_list:
print(path)
f = open(path, "rt")
umbrella = []
for line in f:
if line.startswith("76"): #76은 name class에서 'umbrella'를 갖는 인덱스값
umbrella.append(line)
f.close()
if len(umbrella) == 0 : #우산이 없으면 삭제한다
os.remove(path)
os.remove(path.replace(".txt", ".jpg").replace("labels","images"))
else :
f2 = open(path, 'wt')
for p in umbrella:
f2.write(p.replace("76","0",1))
f2.close()| 실행 전 | 실행 후 |
|---|---|
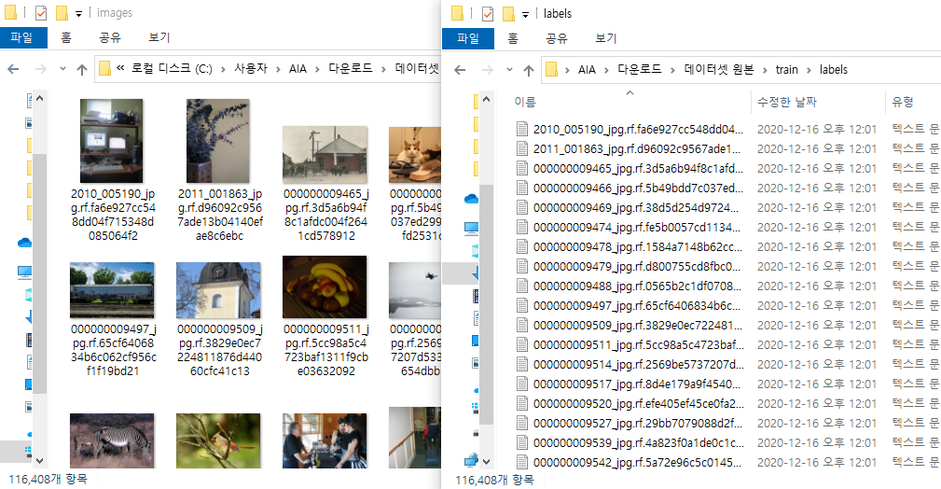 | 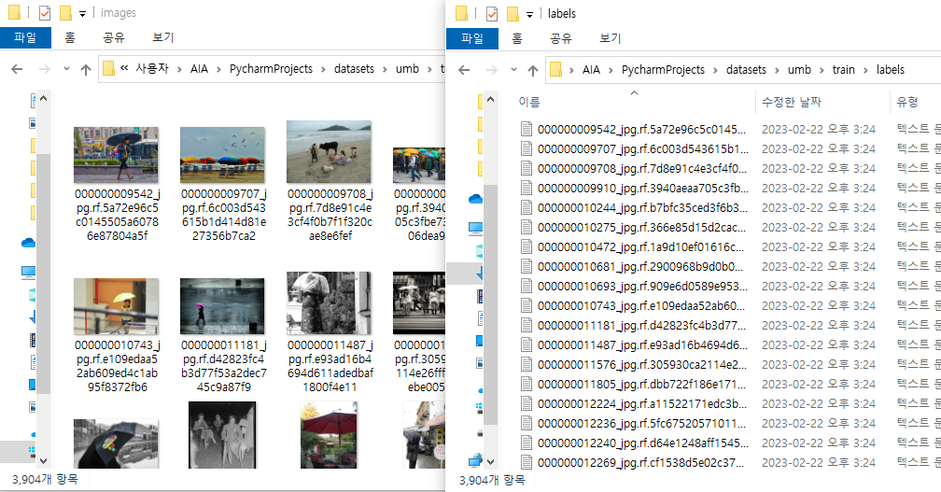 |
| images : 116,408 / labels : 116,408 | images : 3,904/ labels : 3,904 |
1.2 전체 사물 중 우산만 인식
- 학습한 .pt 파일을 실행한 결과
 |  |
|---|
목적인 우산 자체는 인식을 했으나 우산이 아닌 것까지 우산으로 인식하는 문제 발생
- 원인?
- Confidence Threshold가 0.25로 낮아서 발생한 문제
- 아래 설명에서 알 수 있듯이 이 값이 너무 낮으면 자신감 넘치는 상대의 말은 무조건 믿는 것처럼 정확도가 낮은 결과를 받게된다.Confidence Threshold?
- 말 그대로 Confidence에 대한 신뢰도로 Confidence가 일정 수준에 미달이면 버리게 하는 수준이다 .
- 단, 이 값이 너무 높으면 작은 차이로도 인식에 문제가 생기기 때문에 중간점을 잘 잡아야 한다.
- 해결
- Confidence Threshold의 값을 0.4정도로 설정해서 정확도가 낮은 박스를 사용하지 않게 했다.
1.3 우산의 파손 여부 인식
1.3.1 이미지 크롤링
- 우산 파손여부 인식을 위해 기본 데이터셋에 없는 파손된 우산 이미지와 라벨이 필요
- 크롤링 결과로 나온 이미지들에 라벨링 작업 시행
1.3.2 1차 시도
- 파손 데이터의 양이 너무 적고 각 파손된 형태가 제각각이기 때문에 정사 우산과 파손 우산을 구분하지 못함
-파손 데이터를 추가하고 epoch 50으로 실행한 결과


이제는 우산과 파손을 잘 잡지만 아직도 이상한 곳에서 우산을 인식한다… 이건 우산관련 데이터를 늘리는 방법이 최선이라고 생각한다.
1.3.3 2차 시도
- 2차 학습에서 사용한 데이터셋에서 데이터량을 늘려서 학습
- 구글 이미지 크롤링으로 검색된 파손된 우산 이미지를 모두 모아서 크롤링으로는 우리가 원하는 데이터를 더 구할 수 없으니 다음 단계에서는 직접 데이터셋을 늘리는 방식을 찾아야 한다

이전 시도보다는 높은 정확도를 가지게 됐다.
2. KoGPT2를 이용한 Borrow-San 서비스 챗봇
2.1 전처리
import math
import numpy as np
import pandas as pd
import random
import re
import torch
import urllib.request
from torch.utils.data import DataLoader, Dataset
from transformers import PreTrainedTokenizerFast
import urllib.request
Chatbot_Data = pd.read_csv("./data/BorrowChatData.csv")
# Test 용으로 300개 데이터만 처리한다.
Chatbot_Data = Chatbot_Data[:300]
Chatbot_Data.head()
Q_TKN = "<usr>"
A_TKN = "<sys>"
BOS = "</s>"
EOS = "</s>"
SENT = '<unused1>'
PAD = "<pad>"
MASK = "<unused0>"
# 허깅페이스 transformers 에 등록된 사전 학습된 koGTP2 토크나이저를 가져온다.
koGPT2_TOKENIZER = PreTrainedTokenizerFast.from_pretrained("skt/kogpt2-base-v2", bos_token=BOS, eos_token=EOS, unk_token="<unk>", pad_token=PAD, mask_token=MASK,)
class ChatbotDataset(Dataset):
def __init__(self, chats, max_len=40): # 데이터셋의 전처리를 해주는 부분
self._data = chats
self.max_len = max_len
self.q_token = Q_TKN
self.a_token = A_TKN
self.sent_token = SENT
self.eos = EOS
self.mask = MASK
self.tokenizer = koGPT2_TOKENIZER
def __len__(self): # chatbotdata 의 길이를 리턴
return len(self._data)
def __getitem__(self, idx): # 챗봇 데이터를 차례차례 DataLoader로 넘겨주는 메서드
turn = self._data.iloc[idx]
q = turn["Q"] # 질문을 가져온다.
q = re.sub(r"([?.!,])", r" ", q) # 구둣점들을 제거한다.
a = turn["A"] # 답변을 가져온다.
a = re.sub(r"([?.!,])", r" ", a) # 구둣점들을 제거한다.
q_toked = self.tokenizer.tokenize(self.q_token + q + self.sent_token)
q_len = len(q_toked)
a_toked = self.tokenizer.tokenize(self.a_token + a + self.eos)
a_len = len(a_toked)
#질문의 길이가 최대길이보다 크면
if q_len > self.max_len:
a_len = self.max_len - q_len #답변의 길이를 최대길이 - 질문길이
if a_len <= 0: #질문의 길이가 너무 길어 질문만으로 최대 길이를 초과 한다면
q_toked = q_toked[-(int(self.max_len / 2)) :] #질문길이를 최대길이의 반으로
q_len = len(q_toked)
a_len = self.max_len - q_len #답변의 길이를 최대길이 - 질문길이
a_toked = a_toked[:a_len]
a_len = len(a_toked)
#질문의 길이 + 답변의 길이가 최대길이보다 크면
if q_len + a_len > self.max_len:
a_len = self.max_len - q_len #답변의 길이를 최대길이 - 질문길이
if a_len <= 0: #질문의 길이가 너무 길어 질문만으로 최대 길이를 초과 한다면
q_toked = q_toked[-(int(self.max_len / 2)) :] #질문길이를 최대길이의 반으로
q_len = len(q_toked)
a_len = self.max_len - q_len #답변의 길이를 최대길이 - 질문길이
a_toked = a_toked[:a_len]
a_len = len(a_toked)
# 답변 labels = [mask, mask, ...., mask, ..., <bos>,..답변.. <eos>, <pad>....]
labels = [self.mask,] * q_len + a_toked[1:]
# mask = 질문길이 0 + 답변길이 1 + 나머지 0
mask = [0] * q_len + [1] * a_len + [0] * (self.max_len - q_len - a_len)
# 답변 labels을 index 로 만든다.
labels_ids = self.tokenizer.convert_tokens_to_ids(labels)
# 최대길이만큼 PADDING
while len(labels_ids) < self.max_len:
labels_ids += [self.tokenizer.pad_token_id]
# 질문 + 답변을 index 로 만든다.
token_ids = self.tokenizer.convert_tokens_to_ids(q_toked + a_toked)
# 최대길이만큼 PADDING
while len(token_ids) < self.max_len:
token_ids += [self.tokenizer.pad_token_id]
#질문+답변, 마스크, 답변
return (token_ids, np.array(mask), labels_ids)
def collate_batch(batch):
data = [item[0] for item in batch]
mask = [item[1] for item in batch]
label = [item[2] for item in batch]
return torch.LongTensor(data), torch.LongTensor(mask), torch.LongTensor(label)
train_set = ChatbotDataset(Chatbot_Data, max_len=40)
#윈도우 환경에서 num_workers 는 무조건 0으로 지정, 리눅스에서는 2
train_dataloader = DataLoader(train_set, batch_size=32, num_workers=0, shuffle=True, collate_fn=collate_batch,)
# 결과 확인
print("start")
for batch_idx, samples in enumerate(train_dataloader):
token_ids, mask, label = samples
print("token_ids ====> ", token_ids)
print("mask =====> ", mask)
print("label =====> ", label)
print("end")2.2 학습
import torch
from torch.utils.data import DataLoader
from transformers import PreTrainedTokenizerFast, GPT2LMHeadModel
from ChatbotDataset import ChatbotDataset, Chatbot_Data, collate_batch
Q_TKN = "<usr>"
A_TKN = "<sys>"
BOS = '</s>'
EOS = '</s>'
MASK = '<unused0>'
SENT = '<unused1>'
PAD = '<pad>'
koGPT2_TOKENIZER = PreTrainedTokenizerFast.from_pretrained("skt/kogpt2-base-v2",
bos_token=BOS, eos_token=EOS, unk_token='<unk>',
pad_token=PAD, mask_token=MASK)
model = GPT2LMHeadModel.from_pretrained('skt/kogpt2-base-v2')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_set = ChatbotDataset(Chatbot_Data, max_len=40)
#윈도우 환경에서 num_workers 는 무조건 0으로 지정, 리눅스에서는 2
train_dataloader = DataLoader(train_set, batch_size=32, num_workers=0, shuffle=True, collate_fn=collate_batch,)
model.to(device)
model.train()
learning_rate = 3e-5
criterion = torch.nn.CrossEntropyLoss(reduction="none")
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
epoch = 10
Sneg = -1e18
print ("start")
for epoch in range(epoch):
for batch_idx, samples in enumerate(train_dataloader):
optimizer.zero_grad()
token_ids, mask, label = samples
token_ids = token_ids.to('cuda')
mask = mask.to('cuda')
label = label.to('cuda')
out = model(token_ids)
out = out.logits #Returns a new tensor with the logit of the elements of input
mask_3d = mask.unsqueeze(dim=2).repeat_interleave(repeats=out.shape[2], dim=2)
mask_out = torch.where(mask_3d == 1, out, Sneg * torch.ones_like(out))
loss = criterion(mask_out.transpose(2, 1), label)
# 평균 loss 만들기 avg_loss[0] / avg_loss[1] <- loss 정규화
avg_loss = loss.sum() / mask.sum()
avg_loss.backward()
# 학습 끝
optimizer.step()
print ("end")
with torch.no_grad():
while 1:
q = input("user > ").strip()
if q == "quit":
break
a = ""
while 1:
input_ids = torch.LongTensor(koGPT2_TOKENIZER.encode(Q_TKN + q + SENT + A_TKN + a)).unsqueeze(dim=0)
model = model.to('cpu')
pred = model(input_ids)
pred = pred.logits
gen = koGPT2_TOKENIZER.convert_ids_to_tokens(torch.argmax(pred, dim=-1).squeeze().numpy().tolist())[-1]
if gen == EOS:
break
a += gen.replace("▁", " ")
print("Chatbot > {}".format(a.strip()))가장 많이 사용되는 송영숙님의 깃허브에 있는 챗봇 데이터셋을 참고해서 프로젝트 시나리오를 추가
메타데이터는 사용자 입력, 원하는 대답, 내용 분류된다
2.2.1 1차 시도
서비스 시나리오를 구상해서 약 100개의 대화 유형을 데이터셋으로 만들어 학습
-
결과
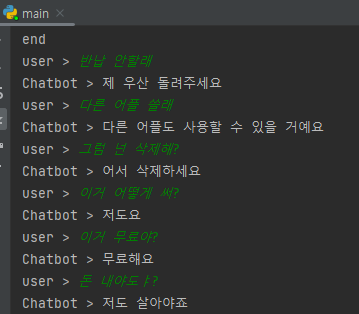
-
고정된 답변만 가능하고 그마저도 틀리는 경우가 발생
-
서비스 이외의 대답은 불가
대안 :
송영숙님의 데이터셋을 추가해서 대화 가능한 범위 확대
2.2.2 2차 시도
- 1차 시도의 대안으로 데이터셋을 추가해서 학습
- 결과
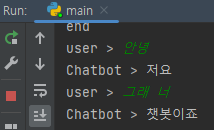
- 대화 가능범위는 늘었지만 알아듣지 못한다
원인 :
기존 데이터셋에 내용 분류에 해당하는 값들을 넣어주지 않아서 생긴 문제
대안 :
내용 분류에 해당하는 값으로 서비스 관련(3)을 추가했다.
대안 적용 후
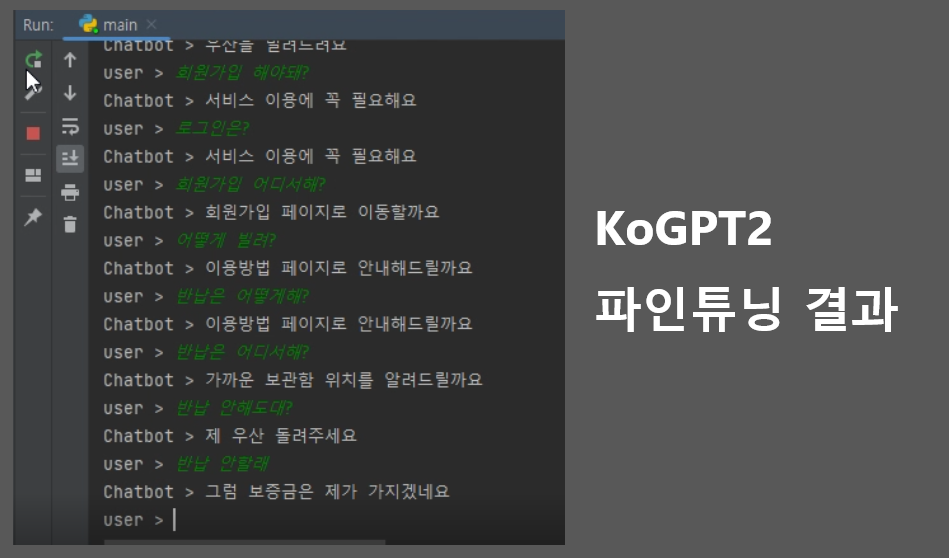
2.3 ChatGPT3로 변경
ChatGPT3 출시로 기존에 있던 KoGPT2를 파인튜닝하는 방식보다 더 쉽게 좋은 성능을 낼 수 있어서 ChatGPT3를 사용한 서비스용 챗봇으로 변경
2.3.1 준비(API키)
- OpenAI에서 회원가입 후 진행
- API키 가져오기
- API키 생성
2.3.2 코드 작성
openAI 설치
터미널에서 아래 명령어 입력으로 설치
pip install openaiAPI 호출
import pandas as pd
import openai
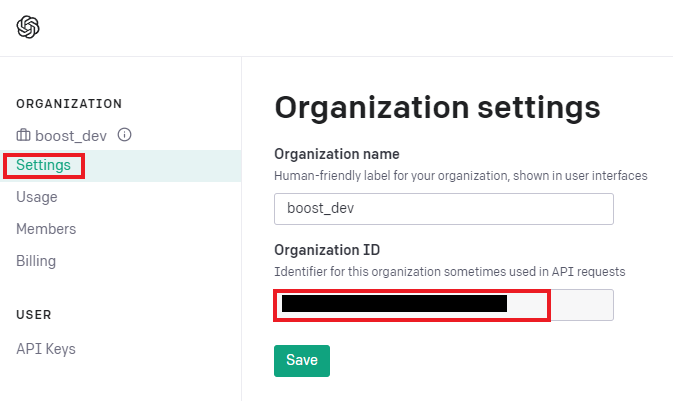
openai.organization = "Organization 키를 입력"
openai.api_key = "발급받은 API 키를 입력."- Organization 키 확인
코드 설명
def get_openai_response(prompt, print_output=False): completions = openai.Completion.create( engine='text-davinci-003', # Determines the quality, speed, and cost. temperature=0.5, # Level of creativity in the response prompt=prompt, # What the user typed in max_tokens=3072, # Maximum tokens in the prompt AND response n=1, # The number of completions to generate stop=None, # An optional setting to control response generation ) # Displaying the output can be helpful if things go wrong if print_output: print(completions) # Return the first choice's text return completions.choices[0].text
| 코드 | 기능 |
|---|---|
| get_openai_response | ChatGPT API의 응답을 반환하는 함수 |
| prompt를 request로 요청 | completions에 JSON 형태의 response가 API를 통해 반환 |
| return completions.choices[0].text | completions에서 사용자가 원하는 GPT 언어모델의 응답을 추출해서 반환 |
코드 설명
def split_script_1000(script): split_script = script.split('. ') # split_script = script.splitlines() result = [] counter = 0 tmp = '' for i in split_script: tmp += i counter += len(i) if counter > 1000: result.append(tmp) tmp = '' counter = 0 return result
코드 기능 split_script_1000 함수 입력된 str 형태의 스크립트를 ". " 기준으로 분할해서 result에는 ". "로 분할된 스크립트의 리스트가 반환
그냥 "."이 아닌 ". "로 분할하는 이유는 실수(1.1, 2.2, 3.3... etc)는 포함시키지 않기 위해
Main
# Let's get data
df = pd.read_csv('script.csv')
# Let's make prompt
prompt = 'Rewrite this script professionally and add subheadings No Titles No Introduction No Conclusion.'
# Algo to rewrite script
result_list = []
for ind, row in df.iterrows():
eng_result = ''
title = row['TITLE']
script = row['SCRIPT'].strip('\n')
split_script = split_script_1000(script)
for ss in split_script:
request = prompt + ss
response = get_openai_response(request)
eng_result += response
result_list.append({'title': title, 'eng': eng_result})
df_result = pd.DataFrame(result_list)
df_result.to_csv('rewrited_script.csv', mode='a', index=False, encoding='utf-8-sig')-
prompt는 "각각의 문단에 소제목을 달고 제목, 개요 및 결론을 내지 말고 이 글을 다시 써주세요."라는 요청에 1000자 단위로 분할된 스크립트를 추가해서 API를 호출한다.
-
script.csv의 형태는 다음과 같다.
- 엑셀로 열어보면 TITLE 칼럼과 SCRIPT칼럼을 가진 일반적인 데이터 프레임이다.
- TITLE에는 문서의 이름 SCRIPT에는 문서 내용을 써넣으면 된다.
결과는 rewrited_script.csv에 저장된다.prompt를 수정하여 API 결과에 따른 다양한 서비스를 만들 수 있다.
3. 수요예측 모델
3.1 1차
3.1.1 🧾전처리
공공데이터의 범위가 너무 넓어서 서비스 지역을 2호선에 한정하고 그에 따른 전처리 진행
# 역 이름순으로 정렬
data = self.passengers.sort_values(by='역명') # = station_location.sort_values(by='역명')
# 사용할 호선인 2호선만 추출
line2 = data[data["노선명"] == "2호선"]
print(line2)y값 생성
- 원본 데이터에서는 승차총승객수와 하차총승객수만 나와있어서 y값으로 사용할 컬럼이 없는 상태이므로 각 일자별 승하차 변동을 나타내는 컬럼을 추가
for i, j in enumerate(data['승차총승객수']):
if i != 0:
on_rate.append(round((data['승차총승객수'][i] - data['승차총승객수'][i-1])/data['승차총승객수'][i-1]*100, 2))
off_rate.append(round((data['하차총승객수'][i] - data['하차총승객수'][i-1])/data['하차총승객수'][i-1]*100, 2))
else:
on_rate.append(0)
off_rate.append(0)
else:
pass
df_on = pd.DataFrame(on_rate, columns=['승차변동(%)'])
df_off = pd.DataFrame(off_rate, columns=['하차변동(%)'])
df = pd.concat([data, df_on, df_off], axis=1)
print(df)
df.to_csv(path_or_buf=f"./data/rate/{k}역.csv", index=False)
print(f"{k}역 저장 완료")
on_rate.clear()
off_rate.clear()전처리 과정에 역별로 csv파일을 분리하는 과정 추가
data = pd.read_csv('./data/sorted_subway.csv')
meta = self.count_index()
df_rows = []
# 역 이름별로 csv 파일 분리
for k in meta:
for i, j in enumerate(data['역명']):
if j == k:
df_rows.append(data.loc[i])
else:
pass
df = pd.DataFrame(df_rows, columns=['사용일자', '역명', '승차총승객수', '하차총승객수'])
df.to_csv(path_or_buf=f"{k}역.csv", index=False)
print(f"{k}역 저장 완료")
df_rows.clear()역별 csv로 변경한 이후 아래 코드로 y값 생성
meta = self.count_index()
on_rate = []
off_rate = []
for k in meta:
data = pd.read_csv(f'./data/save/{k}역.csv')
for i, j in enumerate(data['승차총승객수']):
if i != 0:
on_rate.append(round((data['승차총승객수'][i] - data['승차총승객수'][i-1])/data['승차총승객수'][i-1]*100, 2))
off_rate.append(round((data['하차총승객수'][i] - data['하차총승객수'][i-1])/data['하차총승객수'][i-1]*100, 2))
else:
on_rate.append(0)
off_rate.append(0)
else:
pass
df_on = pd.DataFrame(on_rate, columns=['승차변동(%)'])
df_off = pd.DataFrame(off_rate, columns=['하차변동(%)'])
df = pd.concat([data, df_on, df_off], axis=1)
print(df)
df.to_csv(path_or_buf=f"./data/rate/{k}역.csv", index=False)
print(f"{k}역 저장 완료")
on_rate.clear()
off_rate.clear()분할 및 y값 생성 결과
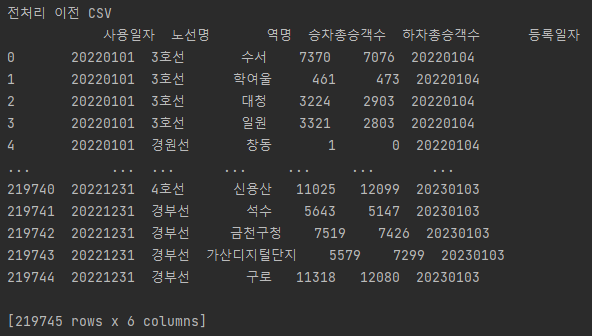
- 전처리 이전
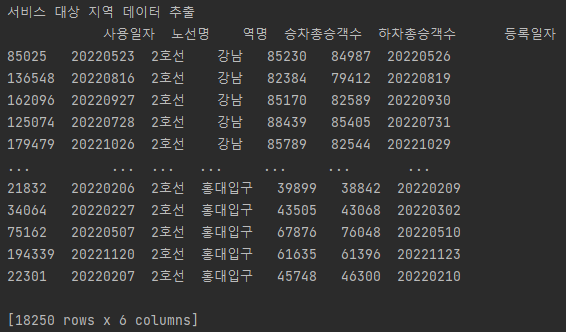
- 서비스 대상 지역 축소
- 각 역별 csv 생성
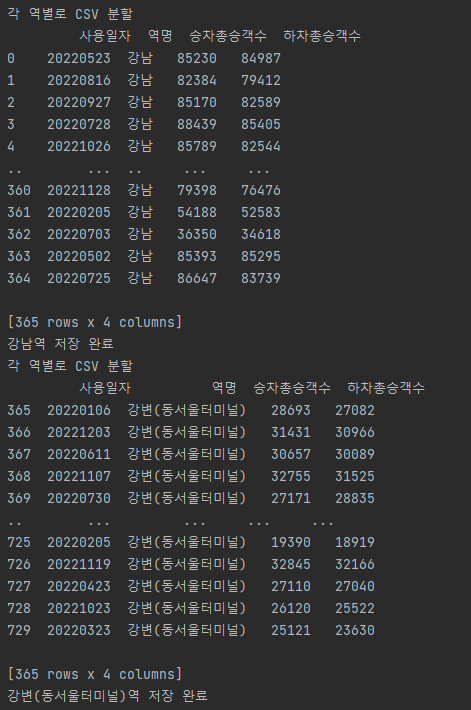
- y값인 승하차 승객수 변동 컬럼 추가
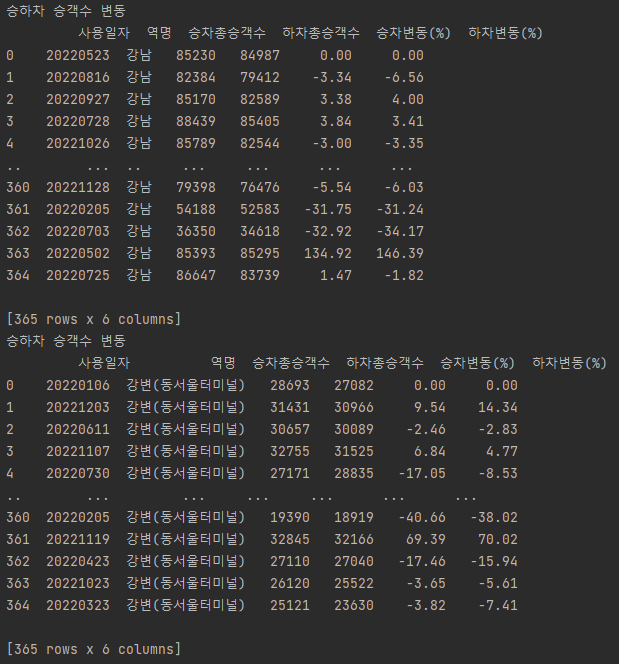
Min Max Scale
numerator = data - np.min(data, 0)
denominator = np.max(data, 0) - np.min(data, 0)
return numerator / (denominator + 1e-7) # 0으로 나누는 에러가 발생을 막기 위해 매우 작은 값(1e-7)을 더해서 나눈다
df = pd.read_csv('./data/rate/강남역.csv')
dfx = df[['사용일자', '승차총승객수', '하차총승객수']]
dfx = self.min_max_scaler(dfx)
dfy = df[['승차변동(%)']]
print(f'dfx : {dfx.head()}')
print(f'0~1 : {dfx.describe()}')
print(f'y : {dfy}')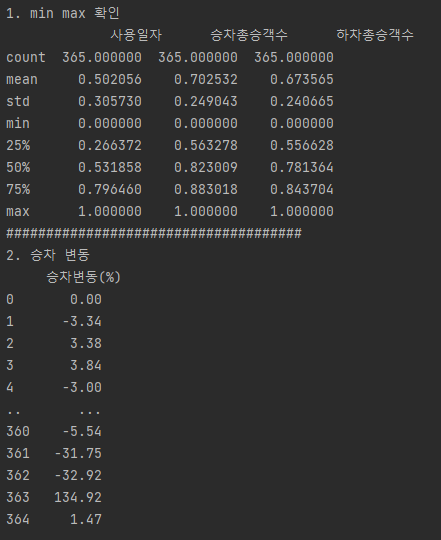
3.2 모델 생성
- 계획 : 각 역별로 일별 승하차총승객수를 바탕으로 하차총승객수를 예측한다
import gmaps
import keras
import pandas as pd
import numpy as np
from keras import Sequential
from keras.layers import Dropout, LSTM, Dense
from matplotlib import pyplot as plt
from preprocess import Preprocess
class Forecast_model():
def __init__(self):
pass
def model(self):
meta = Preprocess()
for k in meta.count_index():
df = pd.read_csv(f'./data/rate/{k}역.csv')
dfx = df[['사용일자', '승차총승객수', '하차총승객수']]
dfx = meta.min_max_scaler(dfx)
dfy = df[['하차변동(%)']]
print(f'1. min max 확인')
print(dfx.describe())
print('#####################################')
print('2. 하차 변동')
print(dfy)
X = dfx.values.tolist()
y = dfy.values.tolist()
window_size = 10
data_X = []
data_y = []
for i in range(len(y) - window_size):
_X = X[i: i + window_size] # 다음 날 종가(i+windows_size)는 포함되지 않음
_y = y[i + window_size] # 다음 날 종가
data_X.append(_X)
data_y.append(_y)
print(_X, "->", _y)
print(data_X[0])
print('전체 데이터의 크기 :')
print(len(data_X), len(data_y))
train_size = int(len(data_y) * 0.7)
train_X = np.array(data_X[0: train_size])
train_y = np.array(data_y[0: train_size])
test_size = len(data_y) - train_size
test_X = np.array(data_X[train_size: len(data_X)])
test_y = np.array(data_y[train_size: len(data_y)])
print('훈련 데이터의 크기 :', train_X.shape, train_y.shape)
print('테스트 데이터의 크기 :', test_X.shape, test_y.shape)
model = Sequential()
model.add(LSTM(units=20, activation='relu', return_sequences=True, input_shape=(10, 3))) #!!!ValueError: Input 0 of layer "sequential" is incompatible with the layer: expected shape=(None, 10, 4), found shape=(None, 10, 3)
model.add(Dropout(0.1))
model.add(LSTM(units=20, activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(units=1))
model.summary()
model.compile(optimizer='adam', loss='mean_squared_error')
model.fit(train_X, train_y, epochs=70, batch_size=30)
pred_y = model.predict(test_X)
plt.figure()
plt.plot(test_y, color='red', label='floating off')
plt.plot(pred_y, color='blue', label='pred off')
plt.title(f'{k} floating population', family='Malgun Gothic')
plt.xlabel('time')
plt.ylabel('off passengers')
plt.legend()
plt.show()
model.save(f'./model/{k}역_예측.h5')
if __name__ == '__main__':
Forecast_model().model()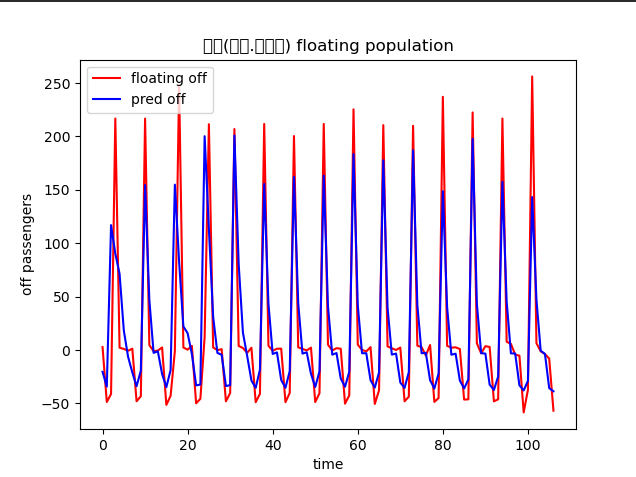
보완사항
각 역별로 모델을 만들고 같은 기간동안 지하철 승객 변동이 가장 심한 지역 위주로 지도에 나타내는게 기존의 계획이었으나 모든 역이 요일을 기준으로 거의 일정한 요동인구 변화를 나타내기 때문에 지하철을 이용한 승객 변화를 통해 학습한 모델의 메리트가 떨어진다.
대안
모든 역에 대한 수요예측 후 비교라는 초반의 방식을 버리고 하나의 역에 대한 작업 우선 진행
강남 하나만 집어서 날씨 등 다른 변수 추가 (2023-02-27)
3.2 2차(날씨 추가)
3.2.1 전처리
이전 단계에서 사용한 데이터셋에는 변수가 너무 적기 때문에 하나의 역을 정해서 강수 여부를 추가
import pandas as pd
class Weather():
def adding_y(self):
data = pd.read_csv('./data/rate/강남역.csv')
rain = pd.DataFrame(pd.read_csv('./data/extremum_20230306105846.csv', encoding= 'euc-kr')['일강수량(mm)'])
print(f'원본 인덱스 수 : {len(data.index)}')
print(f"강수량 인덱스 수 : {len(pd.read_csv('./data/extremum_20230306105846.csv', encoding= 'euc-kr').index)}")
rain_data = rain.rename(columns={'일강수량(mm)': '강수여부'})
add = []
for i in rain_data['강수여부']:
if i > 0.0:
add.append(i)
else:
add.append(i)
rain_add = pd.DataFrame(add, columns=['강수여부'])
df = pd.concat([data, rain_add], axis=1)
df.to_csv('./data/rain/강남역.csv')3.2.2 학습
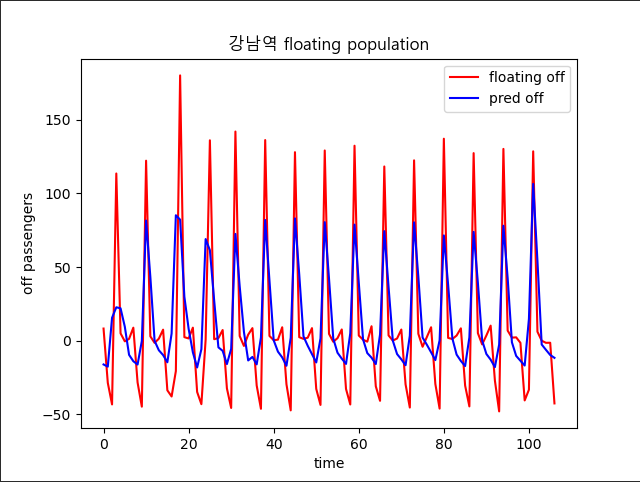
결과
- 서비스 항목인 우산과 비슷하게 날씨에 영향을 받는 상품의 수요 변화를 변수로 둘 필요가 있다
날씨 추가 후
😅 다시 생각해보니 날씨가 지하철을 이용량에 영향을 미치지 않고 이걸 뽑아내더라도 우산 대여와 관련이 없다
3.3 3차(따릉이 대여정보 추가)
예시 상품인 우산처럼 날씨의 영향을 많이 받으면서 수요의 증감이 우산 사용량과 반비례 관계를 가졌을 것이라고 예상되는 따릉이 대여기록을 추가
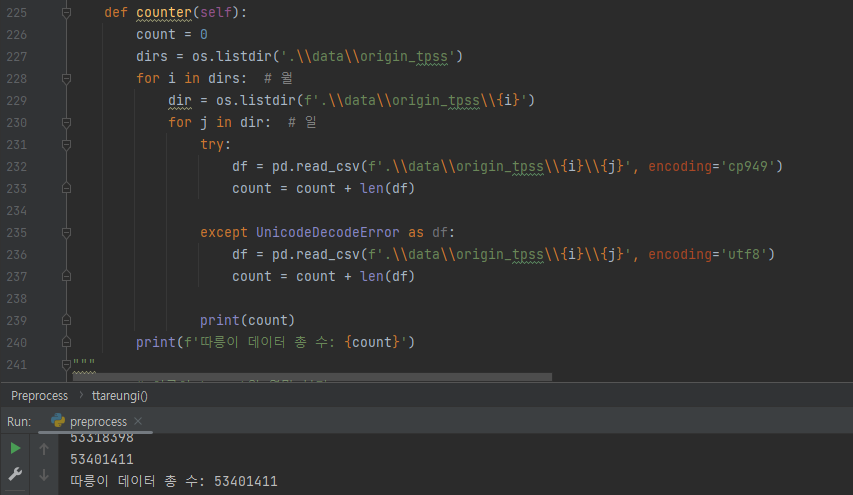
따릉이 데이터 수 : 53,401,411개
3.3.1 전처리
우산과 수요가 반비례하는 따릉이의 자료를 가져오고 y값을 승하차 변동률이 아니라 따릉이 대여량으로 바꾸기 위해 전처리 과정을 거침'
서울역 승하차정보 추출
- 서울역의 역별 승하차 정보와 따릉이 대여소 위치정보 간의 연결이 가장 수월하기 때문에 강남역을 대상으로 한 이전 전처리 결과를 버리고 서울역으로 다시 진행
data = self.passengers.sort_values(by='역명') # 역 이름별로 정렬
data = data[data["노선명"] == "1호선"] # 호선만 반환
data = data[data["역명"] == "서울역"] # 서울역만 반환
print(sorted_csv.isnull().sum()) # 널 체크
sorted_data = data.sort_values(by='사용일자')
print(sorted_data)
sorted_data.to_csv(f"{self.save_dir}/sorted_서울역.csv", index=False)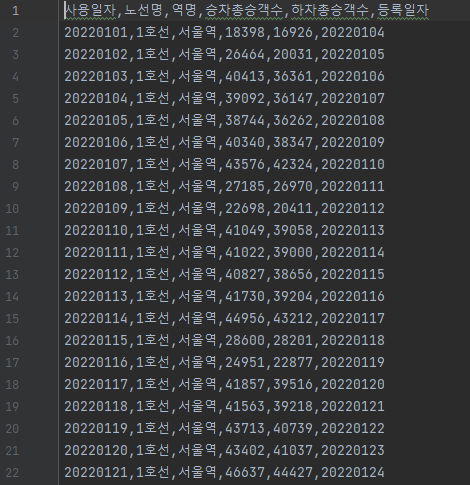
따릉이 대여량 추출
1년치 따릉이 대여정보가 하루를 기준으로 적게는 5만에서 20만개의 데이터가 모여있어서 전처리가 필수
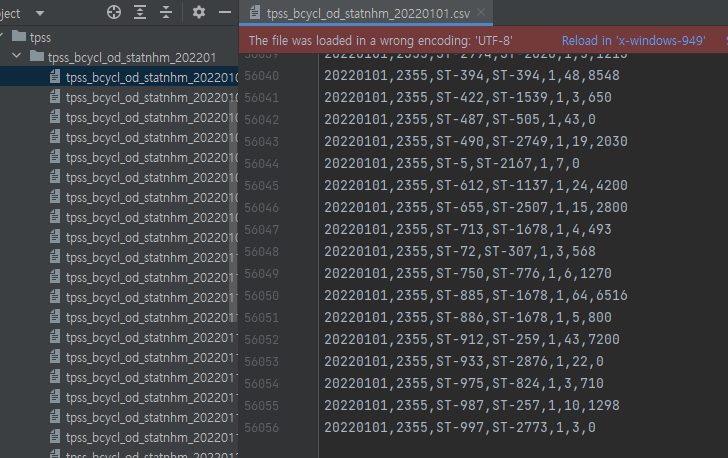
- 서울역 승하차 정보와 따릉이 대여량 join
data = self.passengers.sort_values(by='역명') # 역 이름별로 정렬
data = data[data["노선명"] == "1호선"] # 호선만 반환
data = data[data["역명"] == "서울역"] # 서울역만 반환
print(sorted_csv.isnull().sum()) # 널 체크
sorted_data = data.sort_values(by='사용일자')
print(sorted_data)
sorted_data.to_csv(f"{self.save_dir}/sorted_서울역.csv", index=False)
ttareungi = pd.read_csv(f"{self.save_dir}/서울역_따릉이_대여량.csv")
ttareungi = ttareungi['따릉이 대여량']
join_df = pd.concat([sorted_data, ttareungi], axis=1)
join_df.to_csv(f"{self.save_dir}/ttareungi_서울역.csv", index=False)- 365개의 csv 파일 중 일부 파일의 메타데이터, 인코딩 방식이 일치하지 않아서 에러 발생
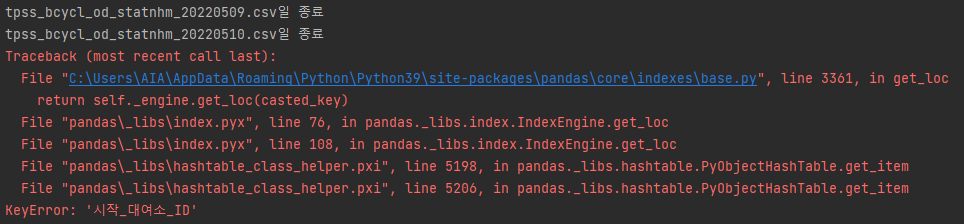
앞의 코드 앞에 아래 코드 추가
dirs = os.listdir('.\\data\\tpss') for i in dirs: # 월 dir = os.listdir(f'.\\data\\tpss\\{i}') for j in dir: # 일 try: df = pd.read_csv(f'.\\data\\tpss\\{i}\\{j}', encoding='cp949') if df.columns[2] != '시작_대여소_ID': df.rename(columns={df.columns[2]: '시작_대여소_ID'}, inplace=True) df.to_csv(f'.\\data\\tpss\\{i}\\{j}') except UnicodeDecodeError as df: df = pd.read_csv(f'.\\data\\tpss\\{i}\\{j}', encoding='utf8') if df.columns[2] != '시작_대여소_ID': df.rename(columns={df.columns[2]: '시작_대여소_ID'}, inplace=True) df.to_csv(f'.\\data\\tpss\\{i}\\{j}') print(f'{j}일 종료')
3.3.2 학습
결과
- epoch : 80
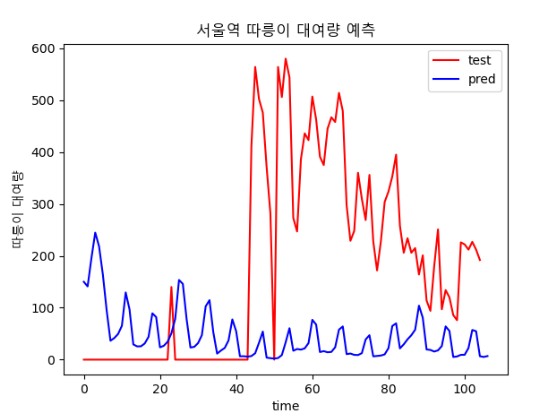
- epoch : 800
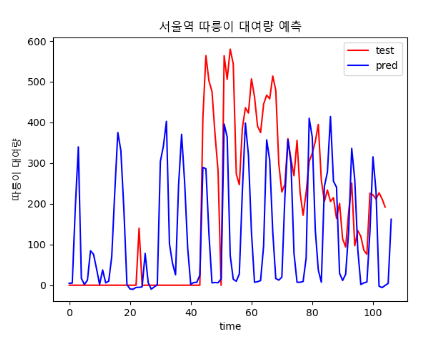
날씨 데이터가 빠진 채로 학습해서 그런거라고 생각된다
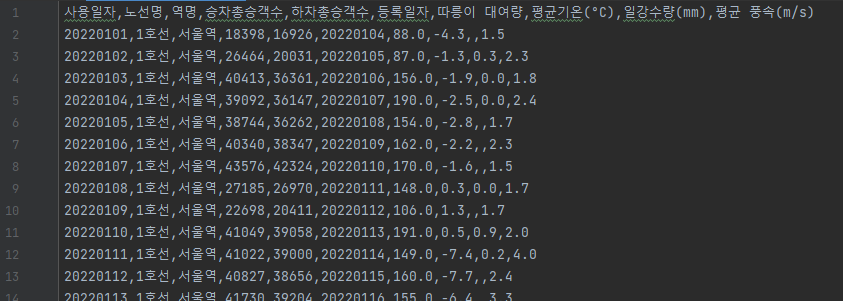
3.4 4차(기온, 풍속 추가)
3.4.1 전처리
- 3차 시기의 데이터에 기온, 풍속 등 변수 추가
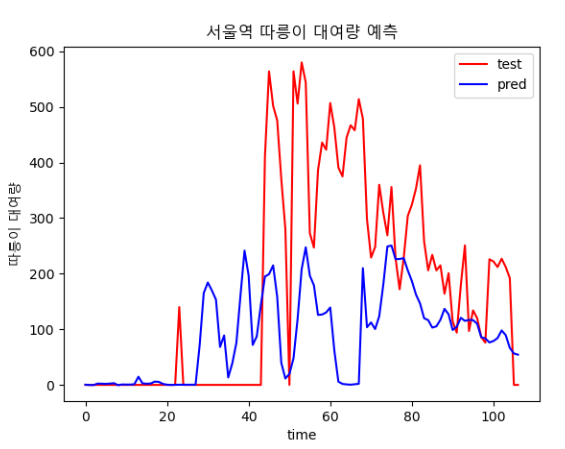
3.4.2 학습
결과
- 3차 시도 때보다는 loss가 감소했다
epoch, batch size에 따른 결과 비교
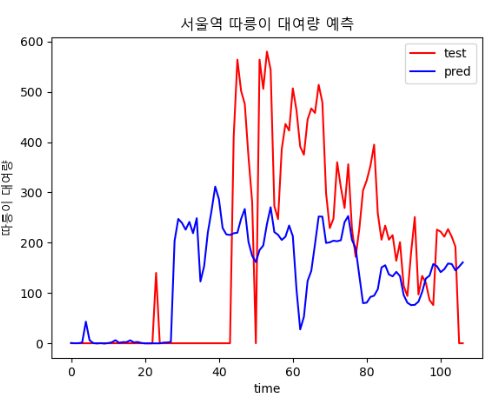
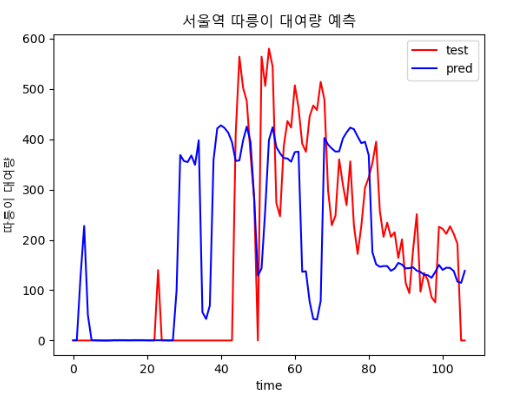
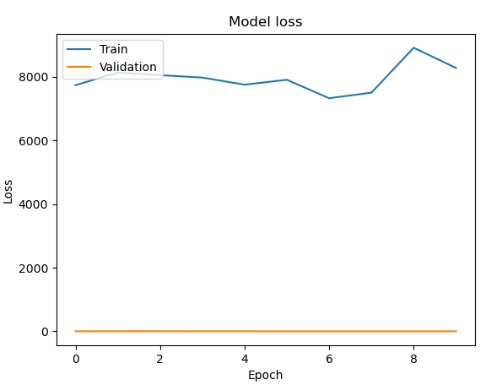
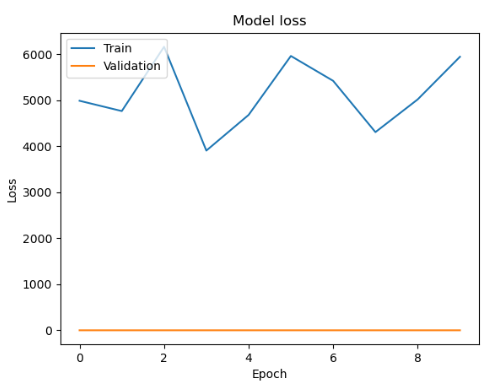
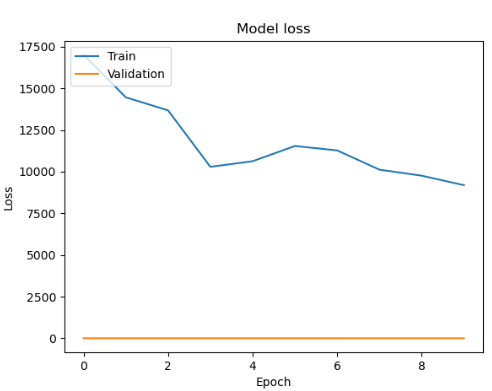
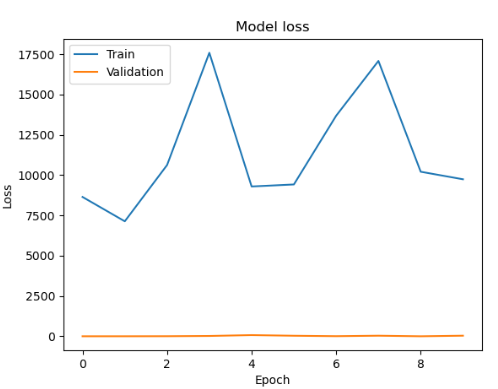
| epoch : 300, batch size : 20 | epoch : 400, batch size : 20 |
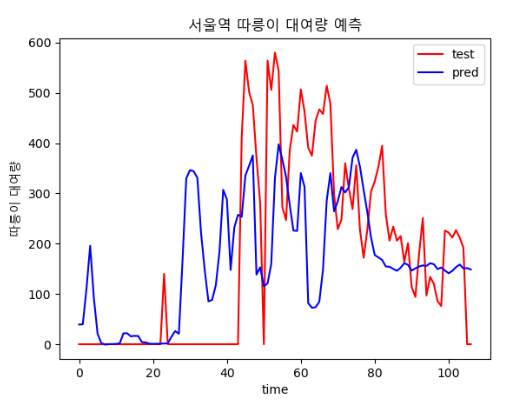 | 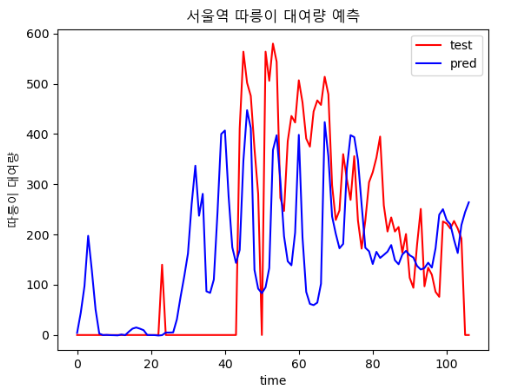 |
| epoch : 400, batch size : 30 | epoch : 500, batch size : 20 |
 |  |
| epoch : 600, batch size : 12 | epoch : 700, batch size : 30 |
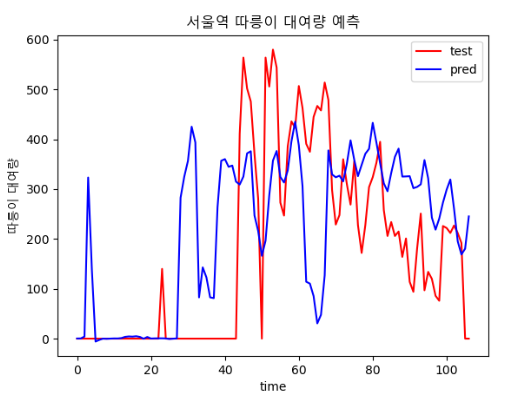 | 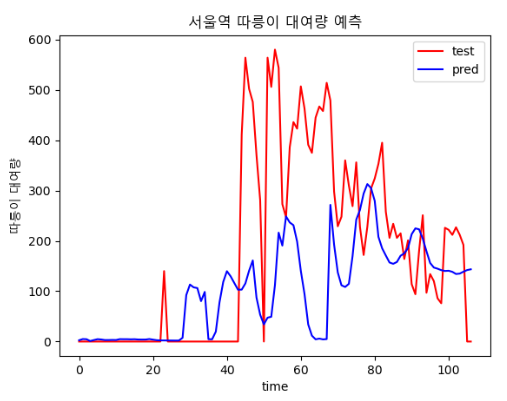 |
| epoch : 800, batch size : 15 | epoch : 4000, batch size : 64 |
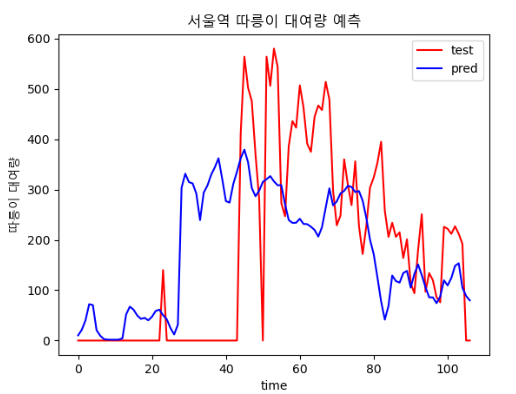 | 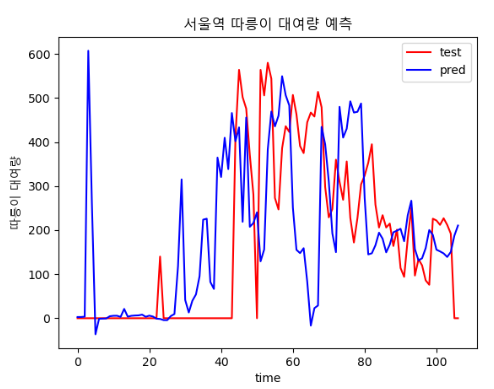 |
batch size
각 사이즈 테스트시 에포크는 1000
history = model.fit(train_X, train_y, batch_size=32, epochs=10, validation_split=0.2)
# 손실 그래프
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='upper left')
plt.show()
# 정확도 그래프
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='upper left')| 15 | 20 |
 |  |
| 30 | 64 |
 |  |
하나씩 찾아보기 힘들어졌다 한 번에 알아보자
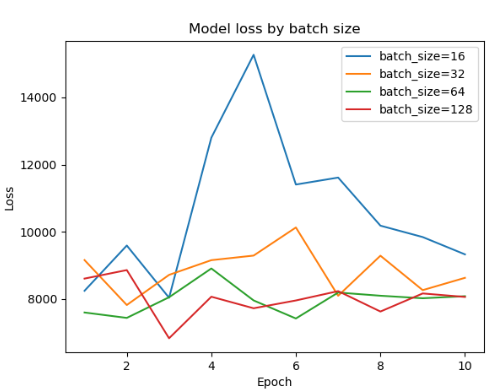
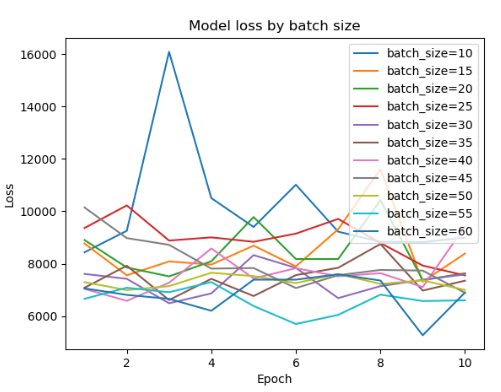
batch_sizes = [비교할 batch 사이즈들] losses = [] for batch_size in batch_sizes: history = model.fit(train_X, train_y, epochs=10, batch_size=batch_size, verbose=0) losses.append(history.history['loss']) for i in range(len(batch_sizes)): plt.plot(np.arange(1, 11), losses[i], label='batch_size=' + str(batch_sizes[i])) plt.title('Model loss by batch size') plt.ylabel('Loss') plt.xlabel('Epoch') plt.legend(loc='upper right') plt.show()
- 16 단위로 batch 사이즈 비교
- 5 단위로 비교
😨오류
FastAPI💨
1. Invalid argument(s) 'encoding' sent to create_engine()
🤔원인
기존까지 잘 작동되던 코드인데, 포맷 후 버전이 달라지면서 발생한 에러
😊해결
- 버전이 업그레이드 되면서 encoding을 명시하는 것이 레거시가 되었다.
- 위 코드에서 encoding=”utf-8” 부분만 지우면 해결 된다.

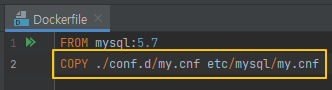
MySQL 로그인 시 my.cnf 파일 인식 불가
🤔원인
Dockerfile 에 my.cnf 경로를 지정하지 않아 발생한 오류
😊해결
- 사진과 같이 경로만 추가하면 해결
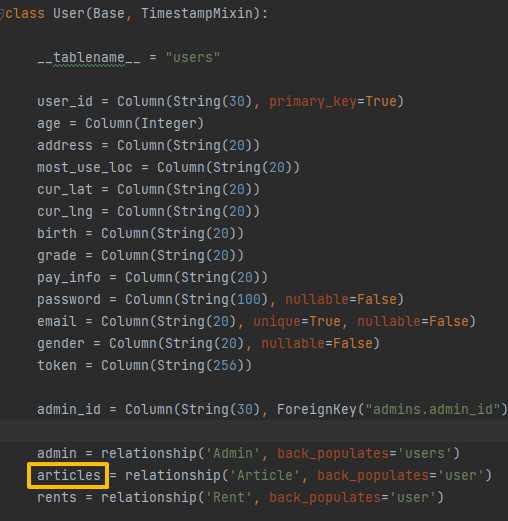
sqlalchemy.exc.InvalidRequestError: One or more mappers failed to initialize
🤔원인
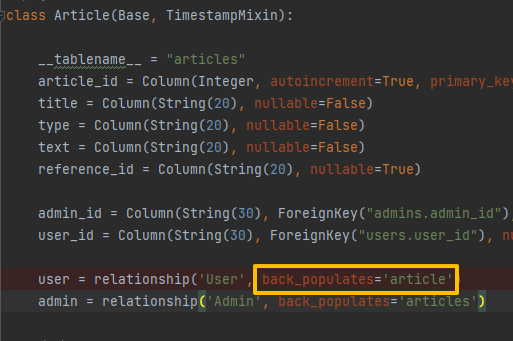
- Postman에서 값 전달 시 발생하는 에러
- Article 테이블의 back_populates에 적힌 속성 값과 User 테이블의 변수 명이 달라 발생하는 에러
😊해결
- 변수 명과 속성 값을 동일하게 변경하면 해결

Docker🐋
다른 컨테이너 실행 오류
🤔원인
git 업로드 시 생성되는 .idea 폴더와 충돌해 기존 컨테이너가 실행되어 발생하는 오류
😊해결
.idea 폴더 삭제 후 명령어를 재 실행하면 해결
DB 테이블 미 생성
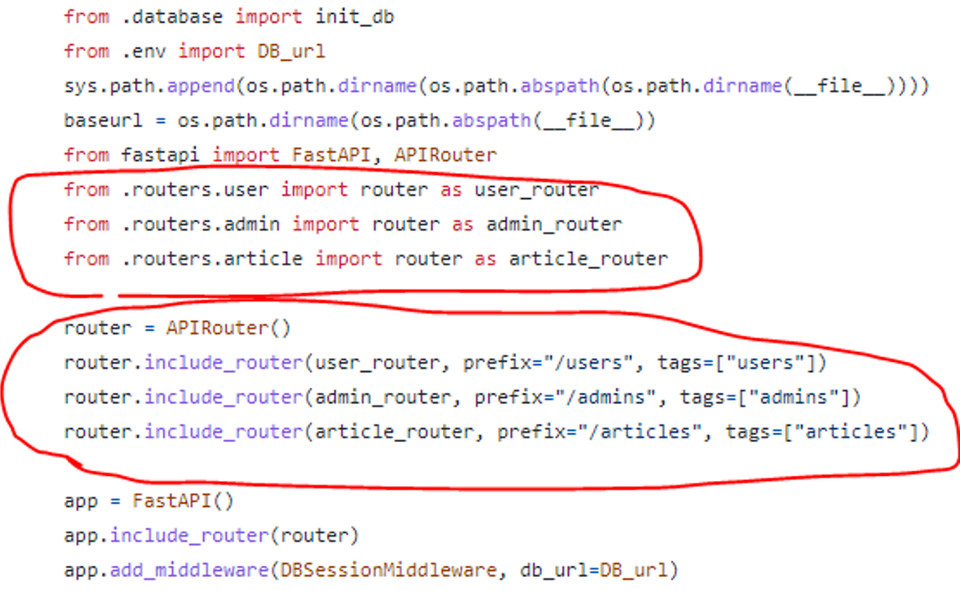
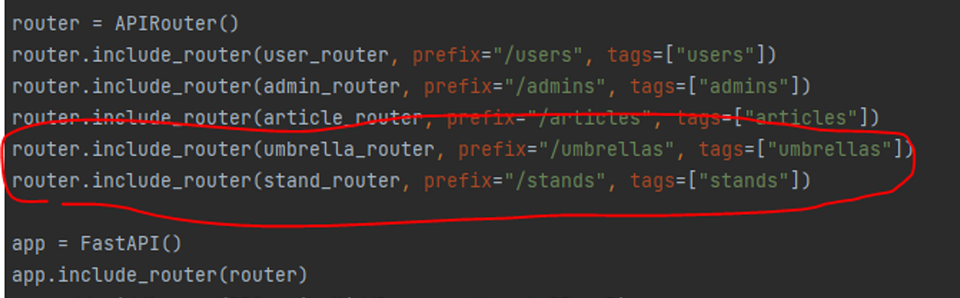
🤔원인
router 연결 코드가 제대로 입력되지 않은 경우 발생하는 에러
😊해결
- main.py → router(schema) → repository → model 순으로 router 연결이 되지 않은 부분이 있는지 확인하고, 빠진 부분에 추가로 코드를 입력하면 해결
- 이번에 발생한 에러는 main.py 에 umbrella, stand의 연결 코드가 없어서 발생
- umbrella, stand 연결 코드를 추가한 뒤 docker compose up 명령어를 다시 입력하면 테이블이 생성
Vue
Next.js
Unhandled Runtime Error
🤔원인
Table 내부 구조를 잘못 짜 발생한 오류
😊해결
<td>태그만 사용해 구성했던 테이블을<tr>태그 내부에<td>태그를 넣어 구성하자 해결
Flutter
SocketException: OS Error: Connection refused, errno = 111, address = localhost
🤔원인
실제 기기 테스트 시 HTTP 연결 문제
😊해결
- 핸드폰에게는 서버가 더이상 로컬호스트가 아니니 서버의 IP 주소를 입력해야 한다.
- ipconfig 명령어로 서버의 ip 주소를 찾아 Dio에 이용한다.
- 해결코드
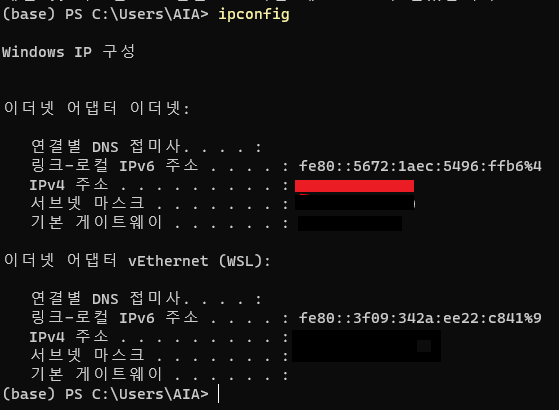
final response = await Dio().post(
// 로컬 애뮬레이터 주소
//'http://10.0.2.2:8000/users/login',
// 서버 IP 주소
'http://192.168.0.22:8000/users/login',
data: jsonEncode(loginInfo),
);YOLOv5
KeyError: 'path'
🤔원인
아래 코드를 추가해서 yaml 파일의 내용을 변경하는 과정에서 원래 있던 path:가 사라져서 발생한 문제
😊해결
yaml을 수정해주자
전처리 과정에서 한 개의 파일만 제거하고 다음 파일은 찾지 못하는 문제 발생
🤔발생 코드
train_label_list = glob('C:/Users/AIA/PycharmProjects/datasets/umb/train/labels/*.txt') for path in train_label_list: print(path) f = open(path, "rt") umbrella = [] for line in f: if line.startswith("76"): umbrella.append(line) f.close() if len(umbrella) == 0 : # person 이 없으면 삭제한다 os.remove(path) os.remove(path.replace(".txt", ".jpg").replace("/labels/","/images/")) else : f2 = open(path, 'wt') for p in umbrella: f2.write(p.replace("76","0",1)) f2.close()
😊해결
12번 라인의 replace("/labels/","/images/")를 replace("labels","images")로 바꿔서 다시 실행
전처리 후 학습시 nc 이외의 범위에서 키에러 발생
🤔원인
발생 당시 train과정에서는 전처리가 완료되어 모든 네임클래스가 0으로 정리된 파일을 사용했지만 valid 과정에서는 전처리가 제대로 이뤄지지 않은 파일이 적용돼서 발생한 문제
😊해결
- 에러지점 네임클래스 확인
- 0 이외의 다른 nc가 들어온걸 볼 수 있다
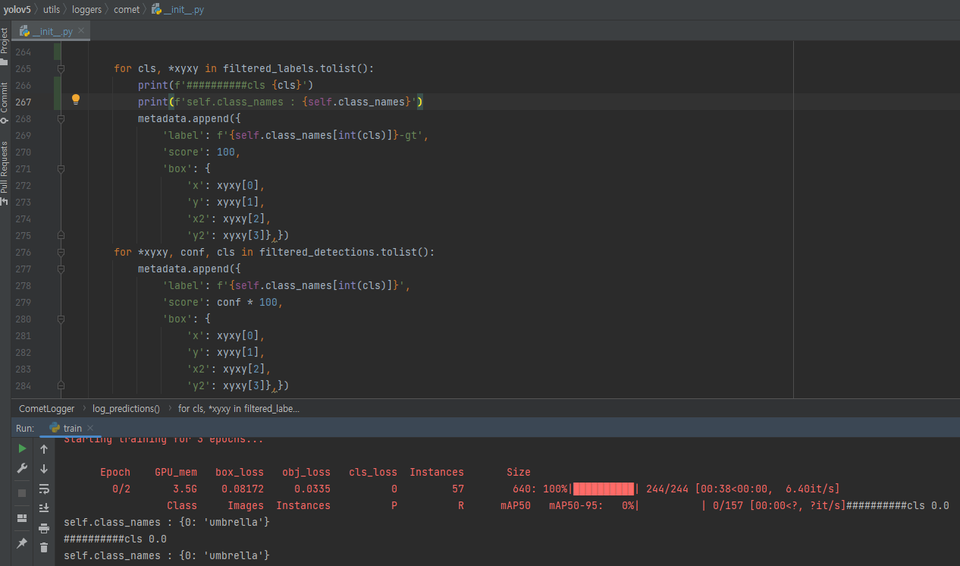
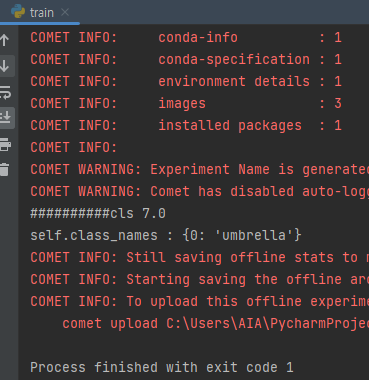
- 전처리 코드를 valid 폴더 내부에도 실행해준다
# 에러 발생 for cls, *xyxy in filtered_labels.tolist(): metadata.append({ 'label': f'{self.class_names[int(cls)]}-gt', # 변경 for cls, *xyxy in filtered_labels.tolist(): metadata.append({ 'label': f'{self.class_names}-gt',
KoGPT2
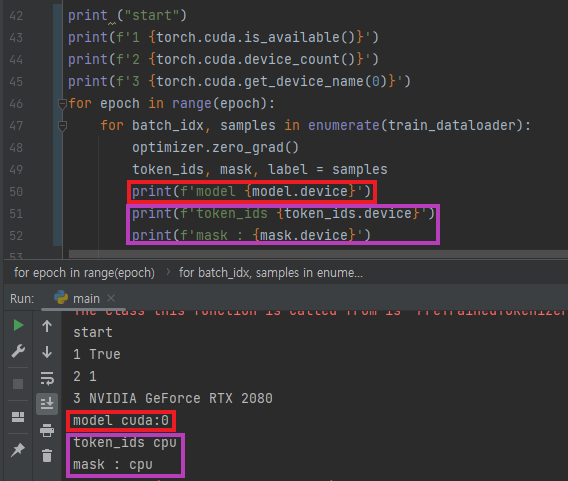
RuntimeError: Expected all tensors to be on the same device, but found at least two devices
🤔원인
텐서 별로 사용하는 디바이스가 달라서 발생
😊해결
- 사용중인 디바이스 확인
- model과 token_ids의 디바이스가 다른 것을 확인
- 동일한 디바이스를 사용하게 해서 해결
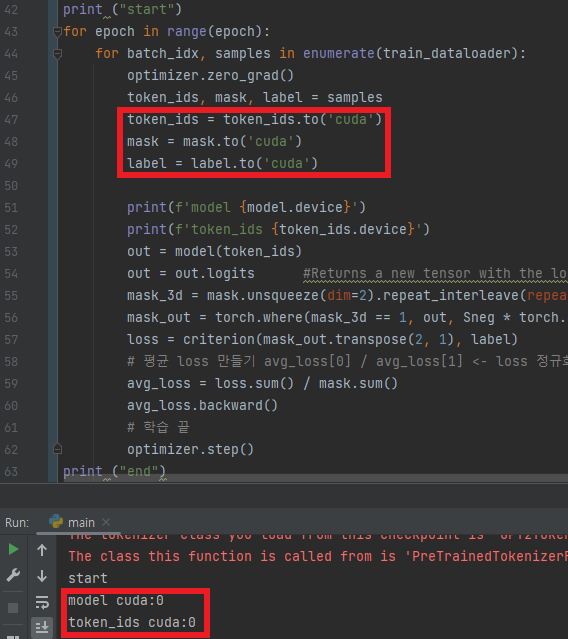
TypeError: can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.
🤔원인
GPU에 할당된 텐서를 넘파이 배열로 변환하려 해서 발생
😊해결
이전 에러 해결을 위해 CUDA로 사용중이던 텐서의 디바이스를 넘파이 배열 사용 전에 cpu로 바꾼다.
ValueError: Connection error, and we cannot find the requested files in the cached path. Please try again or make sure your Internet connection is on.
😊해결
재실행하면 된다
수요예측 모델
TypeError: numpy boolean subtract,
🤔원인
MinMaxScale 과정에서 String값을 가지는 컬럼까지 포함돼서 발생한 문제
😊해결
int값만 사용될 수 있도록 바꿔준다
전처리 과정중 키에러가 반복적으로 발생
🤔원인
전체 csv 파일 중 일부 파일의 메타데이터, 인코딩 방식이 일치하지 않아서 발생
😊해결
따로 정해진 방식은 없고 아래 코드를 통해 해결
- 이번 에러는 아래 코드로 해결했다
dirs = os.listdir('.\\data\\tpss') for i in dirs: # 월 dir = os.listdir(f'.\\data\\tpss\\{i}') for j in dir: # 일 try: df = pd.read_csv(f'.\\data\\tpss\\{i}\\{j}', encoding='cp949') if df.columns[2] != '시작_대여소_ID': df.rename(columns={df.columns[2]: '시작_대여소_ID'}, inplace=True) df.to_csv(f'.\\data\\tpss\\{i}\\{j}') except UnicodeDecodeError as df: df = pd.read_csv(f'.\\data\\tpss\\{i}\\{j}', encoding='utf8') if df.columns[2] != '시작_대여소_ID': df.rename(columns={df.columns[2]: '시작_대여소_ID'}, inplace=True) df.to_csv(f'.\\data\\tpss\\{i}\\{j}') print(f'{j}일 종료')
ValueError:

🤔원인
확인 결과 각 역 별로 csv파일을 나누는 과정에서 딱 역의 종류만큼 인덱스가 다른 것을 알 수 있다
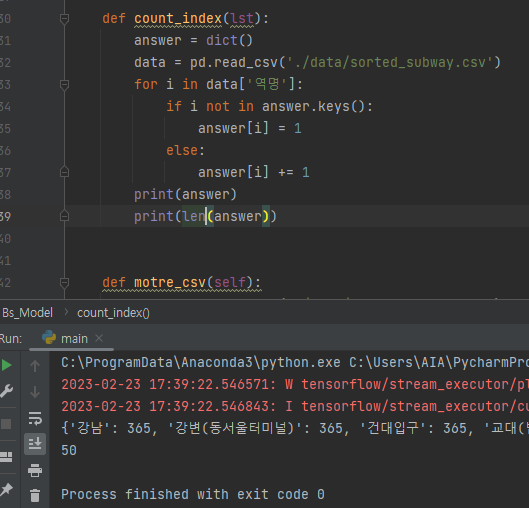
😊해결
모든 역을 한 번에 비교하기보다 각 역별 이동인구 변동율을 예측하고 이를 비교하는 방향으로 변경
npm run serve 실행시 noscript만 나오는 경우

🤔원인
발생 당시 main.js의 내용은 아래처럼 작성됐는데import { createApp } from 'vue' import App from './App.vue' import { router } from '@/router/index'
createApp(App).use(router).mount('#src')
여기서 createApp() 메소드는 인자로 전달된 DOM element를 찾아, 해당 DOM element를 Vue 인스턴스에 마운트(Mount)한다. 위에서 DOM element로 전달된 #src가 잘못된 선택자라서 발생한 문제다.
> 😊해결
- 원래는 default인 #src가 맞는 인자지만 이번 프로젝트에서는 App.vue를 통해 전달된 파일들을 보여주는 형태라서 #src를 #app으로 변경해줘야 한다.
